Recognition: unknown
FairTree: Subgroup Fairness Auditing of Machine Learning Models with Bias-Variance Decomposition
Pith reviewed 2026-05-10 03:28 UTC · model grok-4.3
The pith
FairTree audits machine learning subgroup fairness by decomposing performance disparities into bias and variance without discretizing features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FairTree adapts psychometric invariance testing to machine learning performance metrics, allowing direct handling of continuous, categorical, and ordinal features without discretization and decomposing observed disparities into bias and variance to categorize changes in algorithm performance across subgroups. Two variants are proposed and tested: a permutation approach and a fluctuation test. Simulations demonstrate satisfactory false-positive control for both, with the fluctuation test showing relatively higher power, and the method is illustrated on the UCI Adult Census dataset to provide a flexible statistical framework for fairness evaluation.
What carries the argument
FairTree algorithm, which applies invariance testing with bias-variance decomposition to identify and categorize subgroup performance differences in machine learning models.
If this is right
- Auditing can proceed directly on continuous features instead of requiring discretization that loses resolution.
- Performance changes across subgroups can be categorized as bias-driven or variance-driven to guide specific fixes.
- The framework applies to relatively small datasets across a wide range of machine learning applications.
- Evaluation moves beyond aggregate loss functions to statistical subgroup analysis for fairness.
Where Pith is reading between the lines
- Similar decomposition could be tested on other ML tasks such as regression or ranking to see if bias-variance splits reveal patterns not visible in standard fairness metrics.
- The two algorithm variants might be compared in deployment settings to determine when permutation or fluctuation testing is preferable for ongoing monitoring.
- If the categorization proves stable, it could inform data collection priorities by highlighting whether more samples or different features would reduce specific disparities.
Load-bearing premise
The bias-variance decomposition and invariance testing framework can be directly adapted to machine learning performance metrics for subgroup auditing without introducing artifacts or losing statistical validity.
What would settle it
A controlled simulation or dataset with known, injected subgroup performance differences where FairTree either fails to detect them or misclassifies the source as bias versus variance would show the adaptation does not hold.
Figures


read the original abstract
The evaluation of machine learning models typically relies mainly on performance metrics based on loss functions, which risk to overlook changes in performance in relevant subgroups. Auditing tools such as SliceFinder and SliceLine were proposed to detect such groups, but usually have conceptual disadvantages, such as the inability to directly address continuous covariates. In this paper, we introduce FairTree, a novel algorithm adapted from psychometric invariance testing. Unlike SliceFinder and related algorithms, FairTree directly handles continuous, categorical, and ordinal features without discretization. It further decomposes performance disparities into systematic bias and variance, allowing a categorization of changes in algorithm performance. We propose and evaluate two variations of the algorithm: a permutation-based approach, which is conceptually closer to SliceFinder, and a fluctuation test. Through simulation studies that include a direct comparison with SliceLine, we demonstrate that both approaches have a satisfactory rate of false-positive results, but that the fluctuation approach has relatively higher power. We further illustrate the method on the UCI Adult Census dataset. The proposed algorithms provide a flexible framework for the statistical evaluation of the performance and aspects of fairness of machine learning models in a wide range of applications even in relatively small data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FairTree, an algorithm for subgroup fairness auditing of ML models adapted from psychometric invariance testing. It directly processes continuous, categorical, and ordinal features without discretization, decomposes performance disparities into systematic bias and variance components for categorization, and offers two variants (permutation-based and fluctuation test). Simulations (including direct comparison to SliceLine) report satisfactory false-positive rates with higher power for the fluctuation approach; the method is illustrated on the UCI Adult dataset, positioning it as a flexible framework for statistical evaluation of model performance and fairness even with small data.
Significance. If the adaptation holds, FairTree offers a statistically interpretable auditing tool that addresses key limitations of SliceFinder/SliceLine (discretization requirements) while adding bias-variance attribution of disparities. The reported simulation properties and real-data illustration indicate potential for broader applicability in fairness auditing, particularly where subgroup sizes are modest and features are mixed-type.
major comments (3)
- [Simulation studies] Simulation studies: the claim of satisfactory false-positive rates and higher power for the fluctuation test rests on simulations that may not sufficiently stress the distributional mismatch between psychometric assumptions (continuous indicators, specific forms) and bounded/discrete ML metrics (accuracy, loss) on finite, imbalanced subgroups after tree partitioning; without explicit checks on type-I error under these conditions, the transfer of asymptotic justification and exchangeability remains unverified.
- [Methods] Methods (fluctuation test and permutation approach): the bias-variance decomposition of performance disparities is presented as directly transferable, but the paper does not provide a derivation or counter-example showing that the decomposition preserves its interpretation and statistical validity when applied to non-continuous, bounded subgroup metrics; this is load-bearing for the categorization of changes in algorithm performance.
- [Simulation studies] Comparison with SliceLine: the direct simulation comparison reports higher power for FairTree's fluctuation approach, but lacks detail on exact subgroup sizes, metric distributions, and whether the tree-induced dependence was accounted for in power calculations; this weakens the claim of superiority for practical auditing.
minor comments (2)
- [Abstract] Abstract: the phrasing 'risk to overlook' is grammatically imprecise and should be revised to 'risk overlooking' for clarity.
- [Abstract] The abstract states that simulations demonstrate 'satisfactory rate of false-positive results' but does not report the exact rates, sample sizes, or number of replications; adding these would improve reproducibility.
Simulated Author's Rebuttal
We are grateful to the referee for their detailed and insightful comments. These points highlight important aspects of statistical validity and transparency that we will address to strengthen the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: Simulation studies: the claim of satisfactory false-positive rates and higher power for the fluctuation test rests on simulations that may not sufficiently stress the distributional mismatch between psychometric assumptions (continuous indicators, specific forms) and bounded/discrete ML metrics (accuracy, loss) on finite, imbalanced subgroups after tree partitioning; without explicit checks on type-I error under these conditions, the transfer of asymptotic justification and exchangeability remains unverified.
Authors: We appreciate the referee's concern about potential mismatches between the original psychometric assumptions and the properties of ML performance metrics. Our existing simulations incorporated bounded metrics (accuracy, loss) on imbalanced subgroups, but we agree that more explicit type-I error verification under tree-partitioned conditions would provide stronger evidence. In the revised manuscript we will add targeted simulation scenarios that directly assess false-positive rates for discrete/bounded metrics across a range of subgroup sizes and imbalance levels, including checks on exchangeability after partitioning. revision: yes
-
Referee: Methods (fluctuation test and permutation approach): the bias-variance decomposition of performance disparities is presented as directly transferable, but the paper does not provide a derivation or counter-example showing that the decomposition preserves its interpretation and statistical validity when applied to non-continuous, bounded subgroup metrics; this is load-bearing for the categorization of changes in algorithm performance.
Authors: The referee correctly identifies that the manuscript does not include an explicit derivation of the bias-variance decomposition for non-continuous, bounded metrics. Although the underlying permutation and fluctuation procedures are non-parametric, we acknowledge that a formal justification is needed to support the categorization of performance changes. We will add a new subsection that derives the decomposition for general (including bounded) performance metrics and provide a counter-example together with simulation validation demonstrating that the bias and variance interpretations remain intact. revision: yes
-
Referee: Comparison with SliceLine: the direct simulation comparison reports higher power for FairTree's fluctuation approach, but lacks detail on exact subgroup sizes, metric distributions, and whether the tree-induced dependence was accounted for in power calculations; this weakens the claim of superiority for practical auditing.
Authors: We thank the referee for highlighting the need for greater detail in the simulation comparison. In the revised manuscript we will expand the relevant section and supplementary material to report the precise subgroup sizes, the distributions of the performance metrics, and the manner in which tree-induced dependence was incorporated into the power calculations. Reproducible code and additional tables will be provided to allow independent verification. revision: yes
Circularity Check
No circularity; algorithm proposal evaluated on independent simulations and external dataset
full rationale
The paper introduces FairTree as a new adaptation of psychometric invariance testing and bias-variance decomposition for ML subgroup auditing. It handles features without discretization, proposes permutation and fluctuation variants, and evaluates false-positive rates and power via simulations (with direct comparison to SliceLine) plus the independent UCI Adult dataset. No load-bearing steps reduce to self-citations, fitted parameters renamed as predictions, or self-definitional loops; the central claims rest on the proposed method's behavior on held-out data rather than internal re-derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Psychometric invariance testing and bias-variance decomposition can be directly adapted to evaluate machine learning model performance disparities across subgroups for fairness purposes.
Reference graph
Works this paper leans on
-
[1]
Barry Becker and Ron Kohavi. 1996. Adult Data Set. UCI Machine Learning Repository. DOI: https://doi.org/10.24432/C5XW20
-
[2]
Selmer Bringsjord and Bettina Schimanski. 2003. What is artificial intelligence? psychometric AI as an answer. InProceedings of the 18th International Joint Conference on Artificial Intelligence(Acapulco, Mexico)(IJCAI’03). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 887–893
2003
-
[3]
Ángel Alexander Cabrera, Will Epperson, Fred Hohman, Minsuk Kahng, Jamie Morgenstern, and Duen Horng Chau. 2019. FAIRVIS: Visual Analytics for Discovering Intersectional Bias in Machine Learning. In2019 IEEE Conference on Visual Analytics Science and Technology (V AST). IEEE, 46–56. doi:10.1109/vast47406.2019.8986948
- [4]
- [5]
-
[6]
Yeounoh Chung, Tim Kraska, Neoklis Polyzotis, Ki Hyun Tae, and Steven Euijong Whang. 2019. Slice Finder: Automated Data Slicing for Model Validation. In2019 IEEE 35th International Conference on Data Engineering (ICDE). IEEE, Piscataway, NJ, 1550–1553. doi:10.1109/ICDE.2019.00139
- [7]
-
[8]
Michael Kearns, Seth Neel, Aaron Roth, and Zhiwei Steven Wu. 2018. Preventing Fairness Gerrymandering: Auditing and Learning for Subgroup Fairness. InProceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 80), Jennifer Dy and Andreas Krause (Eds.). PMLR, 2564–2572. https://proceedings.mlr.press...
2018
- [9]
-
[10]
E. C. Merkle, J. Fan, and A. Zeileis. 2014. Testing for measurement invariance with respect to an ordinal variable.Psychometrika79, 4 (2014), 569–584. doi:10.1007/s11336-013-9376-7
-
[11]
E. C. Merkle and A. Zeileis. 2013. Tests of measurement invariance without subgroups: A generalization of classical methods.Psychometrika78, 1 (2013), 59–82. doi:10.1007/s11336-012-9302-4
-
[12]
R. E. Millsap. 1997. Invariance in measurement and prediction: Their relationship in the single-factor case.Psychological Methods2, 3 (1997), 248–260. doi:10.1037/1082-989X.2.3.248
-
[13]
R. E. Millsap. 2007. Invariance in Measurement and Prediction Revisited.Psychometrika72, 4 (2007), 461–473. doi:10.1007/s11336-007-9039-7
-
[14]
Svetlana Sagadeeva and Matthias Boehm. 2021. SliceLine: Fast, Linear-Algebra-based Slice Finding for ML Model Debugging. InProceedings of the 2021 International Conference on Management of Data(Virtual Event, China)(SIGMOD ’21). Association for Computing Machinery, New York, NY, USA, 2290–2299. doi:10.1145/3448016.3457323
- [15]
-
[16]
C. Strobl, J. Kopf, and A. Zeileis. 2015. Rasch trees: A new method for detecting differential item functioning in the Rasch model.Psychometrika80, 2 (2015), 289–316. doi:10.1007/s11336-013-9388-3
- [17]
- [18]
-
[19]
Shenkman, Jiang Bian, and Fei Wang
Jie Xu, Yunyu Xiao, Wendy Hui Wang, Yue Ning, Elizabeth A. Shenkman, Jiang Bian, and Fei Wang. 2022. Algorithmic fairness in computational medicine.eBioMedicine84 (2022), 104250. doi:10.1016/j.ebiom.2022.104250
-
[20]
A. Zeileis and K. Hornik. 2007. Generalized M-fluctuation tests for parameter instability.Statistica Neerlandica61, 4 (2007), 488–508. doi:10.1111/j.1467- 9574.2007.00371.x
-
[21]
Achim Zeileis, Torsten Hothorn, and Kurt Hornik. 2008. Model-Based Recursive Partitioning.Journal of Computational and Graphical Statistics17, 2 (2008), 492–514. arXiv:https://doi.org/10.1198/106186008X319331 doi:10.1198/106186008X319331
-
[22]
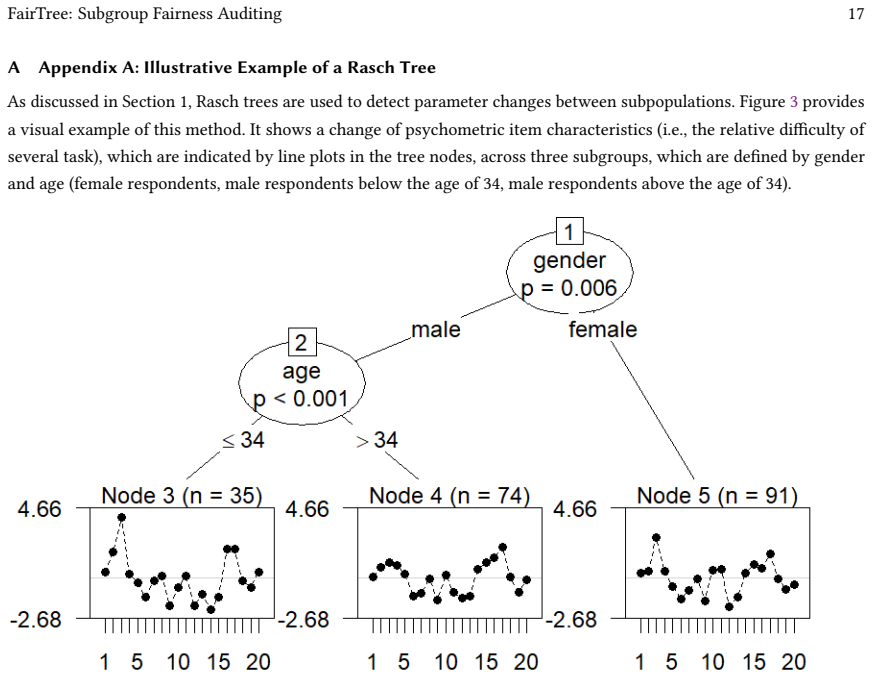
Yan Zhuang, Qi Liu, Zachary A. Pardos, Patrick C. Kyllonen, Jiyun Zu, Zhenya Huang, Shijin Wang, and Enhong Chen. 2025. Position: AI Evaluation Should Learn from How We Test Humans. arXiv:2306.10512 [cs.CL] https://arxiv.org/abs/2306.10512 Manuscript submitted to ACM FairTree: Subgroup Fairness Auditing 17 A Appendix A: Illustrative Example of a Rasch Tre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.