Recognition: unknown
Unsupervised Confidence Calibration for Reasoning LLMs from a Single Generation
Pith reviewed 2026-05-10 03:10 UTC · model grok-4.3
The pith
Reasoning LLMs can be calibrated for confidence from a single generation by distilling self-consistency signals learned offline from unlabeled data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a method for unsupervised confidence calibration of reasoning LLMs when only a single generation is available at inference time. Our approach uses offline sampling on unlabeled data to derive a self-consistency-based proxy target, then distills this signal into a lightweight deployment-time confidence predictor. In a broad evaluation across 5 math and question-answering tasks using 9 reasoning models, our method substantially outperforms baselines, including under distribution shift, and improves downstream performance in selective prediction and simulated downstream decision-making.
What carries the argument
A lightweight confidence predictor trained on self-consistency scores computed from multiple offline generations on unlabeled data.
If this is right
- The calibrated confidence scores enable higher accuracy in selective prediction by rejecting low-confidence answers.
- Downstream simulated decision tasks that rely on uncertainty estimates show measurable performance gains.
- The improvements hold when the distribution of inputs at test time differs from the unlabeled data used for training.
- The method outperforms both supervised calibration approaches and other unsupervised baselines across multiple models and tasks.
Where Pith is reading between the lines
- The technique could support calibration in settings where labels are unavailable due to cost or privacy constraints.
- Self-consistency signals might be combined with other unsupervised cues such as output entropy to strengthen the proxy target.
- The same offline-to-single-generation distillation pattern could apply to non-reasoning generative tasks like code or dialogue.
- Wider adoption might reduce reliance on repeated sampling at inference time, lowering compute costs in production systems.
Load-bearing premise
The self-consistency signal derived from offline multi-sample generations on unlabeled data serves as a valid proxy target for true calibration that transfers to single-generation inference.
What would settle it
On a held-out set with ground-truth labels, the distilled confidence scores show zero or negative correlation with actual answer correctness, or selective prediction using these scores fails to raise accuracy at fixed coverage levels compared with uncalibrated baselines.
Figures

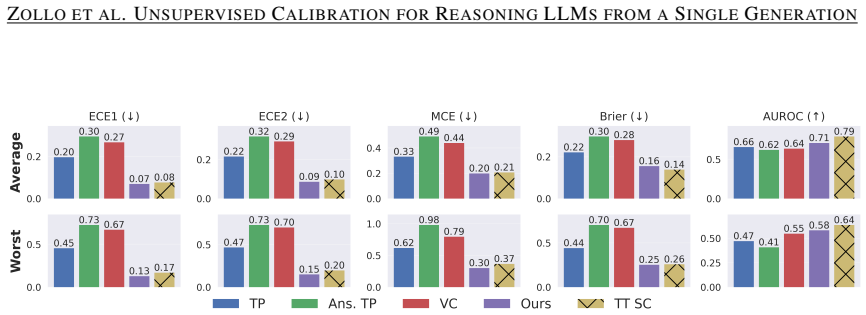





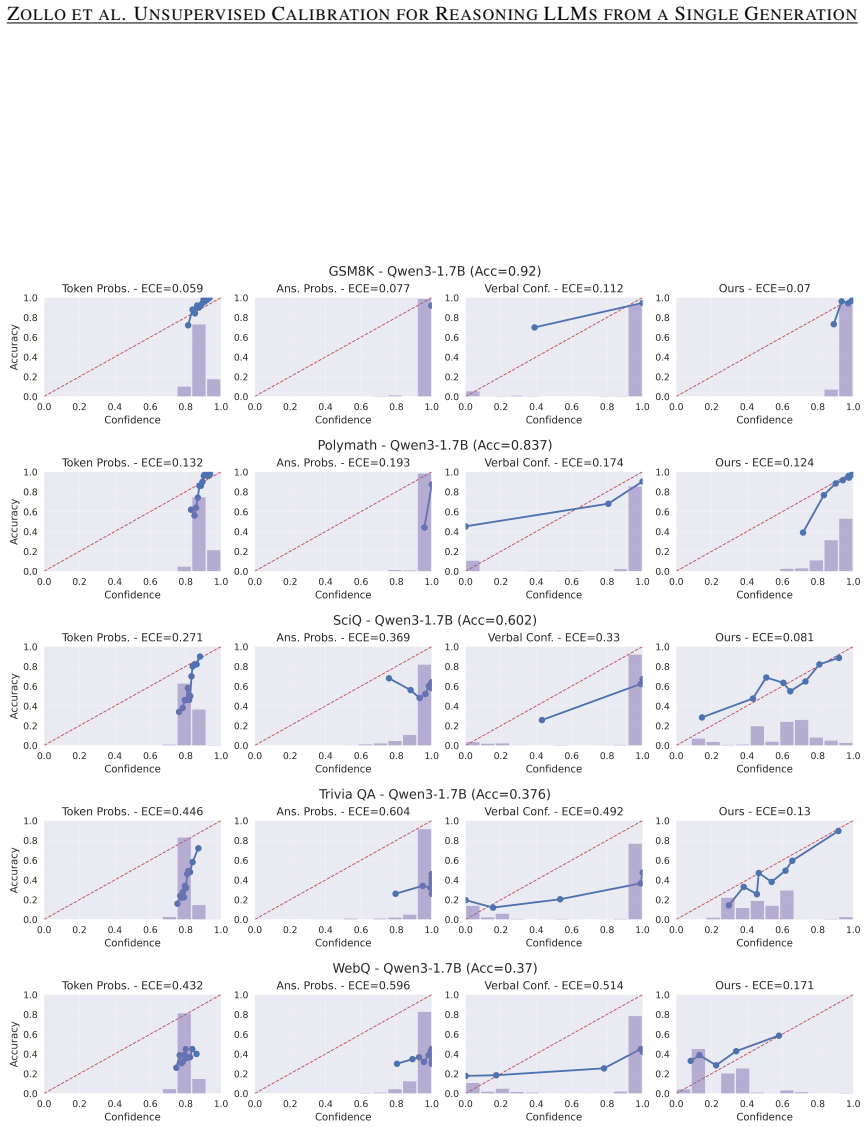
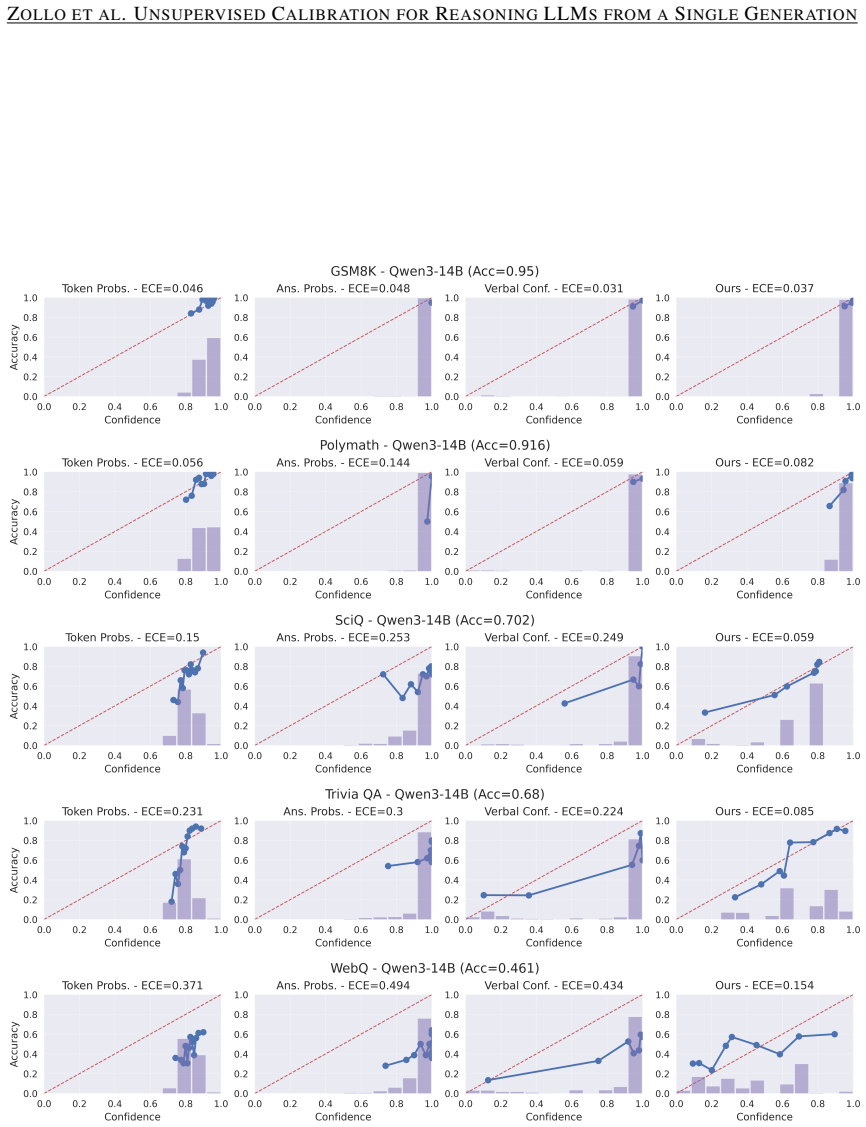



read the original abstract
Reasoning language models can solve increasingly complex tasks, but struggle to produce the calibrated confidence estimates necessary for reliable deployment. Existing calibration methods usually depend on labels or repeated sampling at inference time, making them impractical in many settings. We introduce a method for unsupervised confidence calibration of reasoning LLMs when only a single generation is available at inference time. Our approach uses offline sampling on unlabeled data to derive a self-consistency-based proxy target, then distills this signal into a lightweight deployment-time confidence predictor. In a broad evaluation across 5 math and question-answering tasks using 9 reasoning models, our method substantially outperforms baselines, including under distribution shift, and improves downstream performance in selective prediction and simulated downstream decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an unsupervised method for confidence calibration in reasoning LLMs that requires only a single generation at inference time. Offline multi-sample generations on unlabeled data are used to compute self-consistency scores as a proxy target for correctness; these scores are then distilled into a lightweight predictor that produces calibrated confidence estimates from a single forward pass. The approach is evaluated across 5 math and QA tasks and 9 models, with claims of substantial outperformance versus baselines (including under distribution shift) and downstream gains in selective prediction and simulated decision-making tasks.
Significance. If the central claims hold, the work would be significant for practical deployment of reasoning LLMs in label-free or single-sample settings, where existing calibration techniques are often infeasible. The distillation step that transfers the offline self-consistency signal to single-generation inference addresses a clear usability gap, and the reported robustness under distribution shift plus downstream task improvements would strengthen the case for unsupervised calibration in real-world applications.
major comments (3)
- [§3] §3 (Method): The self-consistency proxy derived from offline multi-sample generations is treated as a reliable surrogate for P(correct), but the manuscript does not report direct evidence (e.g., correlation with ground-truth accuracy or ECE on held-out labeled data) that this proxy tracks true correctness when models produce consistently incorrect answers across samples. This is load-bearing for the transfer claim to single-generation inference.
- [§4] §4 (Experiments): Standard calibration diagnostics such as Expected Calibration Error (ECE), Brier score, or reliability diagrams against ground-truth labels are not presented; only downstream selective-prediction and decision-making metrics are emphasized. Without these, it is unclear whether the distilled scores are calibrated or merely correlate with the proxy in ways that improve task-specific metrics.
- [§4.3] §4.3 (Distribution shift): The outperformance under distribution shift is claimed, but the evaluation does not include an ablation isolating whether the proxy remains valid when the offline unlabeled data and test distribution differ in ways that increase consistent errors (e.g., shared hallucinations).
minor comments (3)
- [Abstract] The abstract states outperformance but provides no quantitative metrics, baseline names, or effect sizes; these should be added for clarity.
- [§3] Notation for the distilled predictor and self-consistency computation should be unified across §3 and the appendix to avoid ambiguity in the distillation loss.
- [Figures] Figure 2 (or equivalent reliability plot) would benefit from error bars or multiple random seeds to show stability of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of validating the self-consistency proxy and calibration metrics. We address each major comment point-by-point below and outline targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method): The self-consistency proxy derived from offline multi-sample generations is treated as a reliable surrogate for P(correct), but the manuscript does not report direct evidence (e.g., correlation with ground-truth accuracy or ECE on held-out labeled data) that this proxy tracks true correctness when models produce consistently incorrect answers across samples. This is load-bearing for the transfer claim to single-generation inference.
Authors: We agree that explicit validation of the proxy's alignment with ground-truth correctness strengthens the transfer argument. Self-consistency is an established proxy for reasoning correctness (Wang et al., 2023), and our evaluations use labeled data for benchmarking. We will add a new analysis (e.g., scatter plots and correlation coefficients) showing the relationship between offline self-consistency scores and ground-truth accuracy on held-out labeled data, including subsets where models exhibit consistent errors. This will directly support the distillation claim. revision: yes
-
Referee: [§4] §4 (Experiments): Standard calibration diagnostics such as Expected Calibration Error (ECE), Brier score, or reliability diagrams against ground-truth labels are not presented; only downstream selective-prediction and decision-making metrics are emphasized. Without these, it is unclear whether the distilled scores are calibrated or merely correlate with the proxy in ways that improve task-specific metrics.
Authors: The referee correctly notes that standard calibration metrics provide complementary evidence beyond downstream utility. While our primary emphasis is on label-free practical deployment and selective prediction gains, we will incorporate ECE, Brier scores, and reliability diagrams computed against ground-truth labels for our method versus baselines in the revised experiments section. These additions will clarify the calibration quality of the distilled single-generation predictor. revision: yes
-
Referee: [§4.3] §4.3 (Distribution shift): The outperformance under distribution shift is claimed, but the evaluation does not include an ablation isolating whether the proxy remains valid when the offline unlabeled data and test distribution differ in ways that increase consistent errors (e.g., shared hallucinations).
Authors: This is a substantive point about proxy robustness under shifts that amplify consistent errors. Our reported results demonstrate gains under the evaluated distribution shifts, but we did not include a dedicated ablation for extreme cases of shared hallucinations. We will add a limitations discussion and a targeted analysis (using existing data splits where possible) examining proxy validity in such scenarios, along with any observed degradation in the distilled predictor. revision: partial
Circularity Check
No significant circularity in the derivation chain.
full rationale
The paper derives a self-consistency proxy from independent offline multi-sample generations on unlabeled data, then trains a separate lightweight predictor to regress that proxy from single-generation features. This distillation does not reduce by construction to its own inputs, nor does it rename a fitted quantity as a prediction; the proxy target is computed externally via sampling and remains distinct from the deployed single-generation model. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are present in the provided description, and the central claim rests on empirical outperformance against baselines rather than definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-consistency across multiple generations serves as a reliable proxy for true answer correctness or calibration target.
Reference graph
Works this paper leans on
-
[1]
2023 , eprint=
Uncertainty in Natural Language Generation: From Theory to Applications , author=. 2023 , eprint=
2023
-
[2]
Glushkova, Taisiya and Zerva, Chrysoula and Rei, Ricardo and Martins, André F. T. , year=. Uncertainty-Aware Machine Translation Evaluation , url=. doi:10.18653/v1/2021.findings-emnlp.330 , booktitle=
-
[3]
2022 , eprint=
Disentangling Uncertainty in Machine Translation Evaluation , author=. 2022 , eprint=
2022
-
[4]
2020 , eprint=
Unsupervised Quality Estimation for Neural Machine Translation , author=. 2020 , eprint=
2020
-
[5]
2023 , eprint=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. 2023 , eprint=
2023
-
[6]
2021 , eprint=
Uncertainty Estimation in Autoregressive Structured Prediction , author=. 2021 , eprint=
2021
-
[7]
2023 , eprint=
Decomposing Uncertainty for Large Language Models through Input Clarification Ensembling , author=. 2023 , eprint=
2023
-
[8]
2023 , eprint=
DEUP: Direct Epistemic Uncertainty Prediction , author=. 2023 , eprint=
2023
-
[9]
2023 , eprint=
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models , author=. 2023 , eprint=
2023
-
[10]
2023 , eprint=
Prompting GPT-3 To Be Reliable , author=. 2023 , eprint=
2023
-
[11]
2023 , eprint=
Towards Reliable Misinformation Mitigation: Generalization, Uncertainty, and GPT-4 , author=. 2023 , eprint=
2023
-
[12]
Hüllermeier, Eyke and Waegeman, Willem , year=. Aleatoric and epistemic uncertainty in machine learning: an introduction to concepts and methods , volume=. Machine Learning , publisher=. doi:10.1007/s10994-021-05946-3 , number=
-
[13]
2023 , eprint=
Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach , author=. 2023 , eprint=
2023
-
[14]
2023 , eprint=
Fine-Tuning Language Models via Epistemic Neural Networks , author=. 2023 , eprint=
2023
-
[15]
2023 , eprint=
Do Large Language Models Know What They Don't Know? , author=. 2023 , eprint=
2023
-
[16]
2023 , eprint=
Quantifying Uncertainty in Answers from any Language Model and Enhancing their Trustworthiness , author=. 2023 , eprint=
2023
-
[17]
2023 , eprint=
Do Language Models Know When They're Hallucinating References? , author=. 2023 , eprint=
2023
-
[18]
2022 , eprint=
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
2022
-
[19]
2022 , eprint=
Teaching Models to Express Their Uncertainty in Words , author=. 2022 , eprint=
2022
-
[20]
2023 , eprint=
Conformal Autoregressive Generation: Beam Search with Coverage Guarantees , author=. 2023 , eprint=
2023
-
[21]
2022 , eprint=
Confident Adaptive Language Modeling , author=. 2022 , eprint=
2022
-
[22]
2023 , eprint=
Conformal Language Modeling , author=. 2023 , eprint=
2023
-
[23]
2023 , eprint=
Prompt Risk Control: A Rigorous Framework for Responsible Deployment of Large Language Models , author=. 2023 , eprint=
2023
-
[24]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
A gentle introduction to conformal prediction and distribution-free uncertainty quantification , author=. arXiv:2107.07511 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
2022 , eprint=
Quantile Risk Control: A Flexible Framework for Bounding the Probability of High-Loss Predictions , author=. 2022 , eprint=
2022
-
[26]
2023 , eprint=
Distribution-Free Statistical Dispersion Control for Societal Applications , author=. 2023 , eprint=
2023
-
[27]
2023 , eprint=
Conformal Prediction with Large Language Models for Multi-Choice Question Answering , author=. 2023 , eprint=
2023
-
[28]
2023 , eprint=
Conformal Risk Control , author=. 2023 , eprint=
2023
-
[29]
Journal of Machine Learning Research , author =
A tutorial on conformal prediction , volume =. Journal of Machine Learning Research , author =. 2008 , pages =
2008
-
[30]
Defensive Forecasting for Linear Protocols , booktitle =
Vovk, Vladimir and Takemura, Akimichi and Shafer, Glenn , year =. Defensive Forecasting for Linear Protocols , booktitle =
-
[31]
Angelopoulos, Anastasios N. and Bates, Stephen and Cand. Learn Then. arXiv:2110.01052 , year=
-
[32]
2017 , eprint=
Selective Classification for Deep Neural Networks , author=. 2017 , eprint=
2017
-
[33]
2019 , eprint=
SelectiveNet: A Deep Neural Network with an Integrated Reject Option , author=. 2019 , eprint=
2019
-
[34]
Calibrated Selective Classification , publisher =
Fisch, Adam and Jaakkola, Tommi and Barzilay, Regina , keywords =. Calibrated Selective Classification , publisher =. 2022 , copyright =. doi:10.48550/ARXIV.2208.12084 , url =
-
[35]
Journal of Machine Learning Research , year =
Ran El-Yaniv and Yair Wiener , title =. Journal of Machine Learning Research , year =
-
[36]
2020 , eprint=
Selective Question Answering under Domain Shift , author=. 2020 , eprint=
2020
-
[37]
2024 , eprint=
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs , author=. 2024 , eprint=
2024
-
[38]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[39]
Transactions of the Association for Computational Linguistics , volume =
Jiang, Zhengbao and Araki, Jun and Ding, Haibo and Neubig, Graham. How Can We Know When Language Models Know? On the Calibration of Language Models for Question Answering. Transactions of the Association for Computational Linguistics. 2021. doi:10.1162/tacl_a_00407
-
[40]
2023 , eprint=
We're Afraid Language Models Aren't Modeling Ambiguity , author=. 2023 , eprint=
2023
-
[41]
2023 , eprint=
Selectively Answering Ambiguous Questions , author=. 2023 , eprint=
2023
-
[42]
2023 , eprint=
Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models , author=. 2023 , eprint=
2023
-
[43]
2022 , eprint=
Task Ambiguity in Humans and Language Models , author=. 2022 , eprint=
2022
-
[44]
2023 , eprint=
CLAM: Selective Clarification for Ambiguous Questions with Generative Language Models , author=. 2023 , eprint=
2023
-
[45]
2023 , eprint=
Why Did the Chicken Cross the Road? Rephrasing and Analyzing Ambiguous Questions in VQA , author=. 2023 , eprint=
2023
-
[46]
2022 , eprint=
Uncertainty Quantification with Pre-trained Language Models: A Large-Scale Empirical Analysis , author=. 2022 , eprint=
2022
-
[47]
The Eleventh International Conference on Learning Representations , year=
On Compositional Uncertainty Quantification for Seq2seq Graph Parsing , author=. The Eleventh International Conference on Learning Representations , year=
-
[48]
2023 , eprint=
Neural-Symbolic Inference for Robust Autoregressive Graph Parsing via Compositional Uncertainty Quantification , author=. 2023 , eprint=
2023
-
[49]
Proceedings of the 35th International Conference on Machine Learning , pages =
Analyzing Uncertainty in Neural Machine Translation , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[50]
2020 , eprint=
Calibration of Pre-trained Transformers , author=. 2020 , eprint=
2020
-
[51]
2023 , eprint=
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback , author=. 2023 , eprint=
2023
-
[52]
2023 , eprint=
Calibrated Interpretation: Confidence Estimation in Semantic Parsing , author=. 2023 , eprint=
2023
-
[53]
2022 , eprint=
Calibrating Sequence likelihood Improves Conditional Language Generation , author=. 2022 , eprint=
2022
-
[54]
2022 , eprint=
Reducing conversational agents' overconfidence through linguistic calibration , author=. 2022 , eprint=
2022
-
[55]
Towards Collaborative Neural-Symbolic Graph Semantic Parsing via Uncertainty
Lin, Zi and Liu, Jeremiah Zhe and Shang, Jingbo. Towards Collaborative Neural-Symbolic Graph Semantic Parsing via Uncertainty. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.328
-
[56]
2023 , eprint=
Navigating the Grey Area: How Expressions of Uncertainty and Overconfidence Affect Language Models , author=. 2023 , eprint=
2023
-
[57]
2021 , eprint=
Calibrate Before Use: Improving Few-Shot Performance of Language Models , author=. 2021 , eprint=
2021
-
[58]
2023 , eprint=
The Confidence-Competence Gap in Large Language Models: A Cognitive Study , author=. 2023 , eprint=
2023
-
[59]
2017 , eprint=
On Calibration of Modern Neural Networks , author=. 2017 , eprint=
2017
-
[60]
2021 , eprint=
On Hallucination and Predictive Uncertainty in Conditional Language Generation , author=. 2021 , eprint=
2021
-
[61]
2023 , eprint=
Fine-tuning Language Models for Factuality , author=. 2023 , eprint=
2023
-
[62]
Minderer, Matthias and Djolonga, Josip and Romijnders, Rob and Hubis, Frances and Zhai, Xiaohua and Houlsby, Neil and Tran, Dustin and Lucic, Mario , keywords =. Revisiting the Calibration of Modern Neural Networks , publisher =. 2021 , copyright =. doi:10.48550/ARXIV.2106.07998 , url =
-
[63]
Rethinking Calibration of Deep Neural Networks: Do Not Be Afraid of Overconfidence , url =
Wang, Deng-Bao and Feng, Lei and Zhang, Min-Ling , booktitle =. Rethinking Calibration of Deep Neural Networks: Do Not Be Afraid of Overconfidence , url =
-
[64]
, biburl =
Platt, J. , biburl =. Advances in Large Margin Classifiers , keywords =
-
[65]
Obtaining Calibrated Probability Estimates from Decision Trees and Naive Bayesian Classifiers , volume =
Zadrozny, Bianca and Elkan, Charles , year =. Obtaining Calibrated Probability Estimates from Decision Trees and Naive Bayesian Classifiers , volume =
-
[66]
Journal of the American Statistical Association , volume =
Tilmann Gneiting and Adrian E Raftery , title =. Journal of the American Statistical Association , volume =. 2007 , publisher =
2007
-
[68]
2025 , eprint=
NVIDIA Nemotron 3: Efficient and Open Intelligence , author=. 2025 , eprint=
2025
-
[69]
2025 , eprint=
AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset , author=. 2025 , eprint=
2025
-
[70]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[71]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
To rely or not to rely? evaluating interventions for appropriate reliance on large language models , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
2025
-
[73]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[74]
2024 , eprint=
Calibrating Large Language Models Using Their Generations Only , author=. 2024 , eprint=
2024
-
[75]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Calibrating large language models with sample consistency , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[76]
2023 , eprint=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. 2023 , eprint=
2023
-
[77]
Obtaining Well Calibrated Probabilities Using Bayesian Binning , booktitle =
Naeini, Mahdi Pakdaman and Cooper, Gregory and Hauskrecht, Milos , year =. Obtaining Well Calibrated Probabilities Using Bayesian Binning , booktitle =
-
[78]
2020 , eprint=
Verified Uncertainty Calibration , author=. 2020 , eprint=
2020
-
[79]
1950 , journal =
Verification of Forecasts Expressed in Terms of Probability , author =. 1950 , journal =
1950
-
[80]
2023 , eprint=
Active Prompting with Chain-of-Thought for Large Language Models , author=. 2023 , eprint=
2023
-
[81]
2016 , eprint=
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning , author=. 2016 , eprint=
2016
-
[82]
2017 , eprint=
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles , author=. 2017 , eprint=
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.