Recognition: unknown
HardNet++: Nonlinear Constraint Enforcement in Neural Networks
Pith reviewed 2026-05-10 03:40 UTC · model grok-4.3
The pith
HardNet++ enforces linear and nonlinear equality and inequality constraints in neural network outputs to arbitrary tolerance using iterative damped local linearizations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HardNet++ is a constraint-enforcement method that simultaneously satisfies linear and nonlinear equality and inequality constraints by iteratively adjusting the network output via damped local linearizations. Each iteration is differentiable, admitting an end-to-end training framework where the constraint satisfaction layer is active during training. Under certain regularity conditions, this procedure can enforce nonlinear constraint satisfaction to arbitrary tolerance. In a learning-for-optimization context applied to model predictive control with nonlinear state constraints, it achieves tight constraint adherence without loss of optimality.
What carries the argument
Iterative adjustment of network outputs via damped local linearizations of the constraints, integrated as a differentiable layer.
Load-bearing premise
The constraints and network must satisfy regularity conditions that ensure the damped linearization iterations converge to the desired tolerance.
What would settle it
A specific nonlinear constraint satisfying the regularity conditions for which the iterative procedure fails to reduce the violation below a given threshold after a large number of iterations.
Figures


read the original abstract
Enforcing constraint satisfaction in neural network outputs is critical for safety, reliability, and physical fidelity in many control and decision-making applications. While soft-constrained methods penalize constraint violations during training, they do not guarantee constraint adherence during inference. Other approaches guarantee constraint satisfaction via specific parameterizations or a projection layer, but are tailored to specific forms (e.g., linear constraints), limiting their utility in other general problem settings. Many real-world problems of interest are nonlinear, motivating the development of methods that can enforce general nonlinear constraints. To this end, we introduce HardNet++, a constraint-enforcement method that simultaneously satisfies linear and nonlinear equality and inequality constraints. Our approach iteratively adjusts the network output via damped local linearizations. Each iteration is differentiable, admitting an end-to-end training framework, where the constraint satisfaction layer is active during training. We show that under certain regularity conditions, this procedure can enforce nonlinear constraint satisfaction to arbitrary tolerance. Finally, we demonstrate tight constraint adherence without loss of optimality in a learning-for-optimization context, where we apply this method to a model predictive control problem with nonlinear state constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HardNet++, a constraint-enforcement method that iteratively adjusts neural network outputs via damped local linearizations to simultaneously satisfy linear and nonlinear equality and inequality constraints. It claims that under certain regularity conditions the procedure achieves nonlinear constraint satisfaction to arbitrary tolerance, that each iteration remains differentiable to support end-to-end training, and that the approach yields tight constraint adherence without loss of optimality when applied to a model-predictive-control problem with nonlinear state constraints.
Significance. If the convergence guarantee and differentiability property can be stated with explicit, verifiable conditions and confirmed on the MPC example, the work would provide a useful general-purpose layer for hard nonlinear constraints in safety-critical learning-for-control settings. The constructive iterative formulation and the emphasis on end-to-end differentiability are constructive strengths; however, the current absence of enumerated regularity conditions and supporting quantitative evidence limits the immediate significance.
major comments (3)
- [Abstract] Abstract: the central claim that the damped local-linearization iteration enforces general nonlinear equality/inequality constraints to arbitrary tolerance is conditioned on unspecified “regularity conditions.” No statement of constraint qualification, Jacobian Lipschitz bounds, or second-order sufficiency is supplied, nor is it shown that the MPC nonlinear state constraints satisfy them; local linearization schemes are known to diverge or require iteration counts that grow with curvature precisely when these conditions fail.
- [Theoretical section] Theoretical section (method and convergence analysis): the assertion that every iteration remains differentiable (necessary for back-propagation through the constraint layer) presupposes that the active-set mapping induced by the inequalities is locally constant. Any active-set switch at the fixed point renders the overall map non-differentiable; this case is not analyzed or excluded.
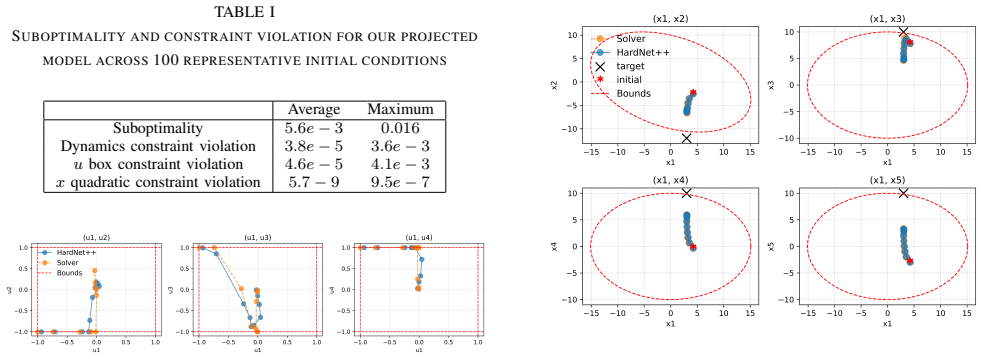
- [Experiments] MPC demonstration: the claim of “tight constraint adherence without loss of optimality” is presented without quantitative metrics (maximum violation norm, iteration count distribution, or comparison against soft-penalty or projection baselines), leaving the practical realization of the arbitrary-tolerance guarantee unsupported.
minor comments (2)
- [Method] The notation for the damping factor and the linearization point in the iterative update rule should be defined once and used consistently to avoid ambiguity.
- [Introduction] Related-work discussion would benefit from explicit comparison to recent differentiable-optimization layers that also handle nonlinear inequalities.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of clarity, rigor, and empirical support that we will address in revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the damped local-linearization iteration enforces general nonlinear equality/inequality constraints to arbitrary tolerance is conditioned on unspecified “regularity conditions.” No statement of constraint qualification, Jacobian Lipschitz bounds, or second-order sufficiency is supplied, nor is it shown that the MPC nonlinear state constraints satisfy them; local linearization schemes are known to diverge or require iteration counts that grow with curvature precisely when these conditions fail.
Authors: We agree that the regularity conditions should be stated explicitly rather than left implicit. In the revised manuscript we will add a dedicated paragraph in the theoretical section that lists the precise assumptions required for the convergence result: a linear independence constraint qualification (LICQ) at the solution, a uniform bound on the Lipschitz constant of the constraint Jacobians, and second-order sufficient conditions for the underlying nonlinear program. We will also verify these conditions for the specific nonlinear state constraints used in the MPC example by stating the constraint functions and confirming that the qualification holds along the demonstrated trajectories. This will make the claim verifiable and will explicitly note the regimes in which divergence or slow convergence can occur. revision: yes
-
Referee: [Theoretical section] Theoretical section (method and convergence analysis): the assertion that every iteration remains differentiable (necessary for back-propagation through the constraint layer) presupposes that the active-set mapping induced by the inequalities is locally constant. Any active-set switch at the fixed point renders the overall map non-differentiable; this case is not analyzed or excluded.
Authors: The referee correctly points out that differentiability of the overall map requires the active-set mapping to be locally constant. Our current proof sketch implicitly relies on this property (via the implicit-function theorem applied to the KKT system of the linearized subproblem). In the revision we will state this assumption explicitly, note that it holds under strict complementarity or when the solution lies in the interior of an active-set region, and acknowledge that an active-set switch at the fixed point can produce a non-differentiable point. We will add a short discussion of practical implications for back-propagation (subgradient selection or smoothing) and will report that, in the MPC experiments, active-set changes were not observed once the iteration converged. A full characterization of the non-differentiable set is left for future work. revision: partial
-
Referee: [Experiments] MPC demonstration: the claim of “tight constraint adherence without loss of optimality” is presented without quantitative metrics (maximum violation norm, iteration count distribution, or comparison against soft-penalty or projection baselines), leaving the practical realization of the arbitrary-tolerance guarantee unsupported.
Authors: We accept that the experimental presentation would be strengthened by quantitative metrics. In the revised manuscript we will augment the MPC section with (i) the maximum constraint-violation norm across all test trajectories and time steps, (ii) histograms of the number of iterations required to reach successive tolerances, and (iii) direct numerical comparisons against a soft-penalty baseline and a projection-based method, reporting both constraint satisfaction and objective value. These additions will provide concrete evidence for the claimed tight adherence and absence of optimality loss. revision: yes
Circularity Check
No circularity: constructive iterative procedure with external regularity conditions
full rationale
The paper presents HardNet++ as an explicit algorithmic procedure: repeated damped local-linearization updates applied to the network output. The central guarantee ('enforce nonlinear constraint satisfaction to arbitrary tolerance') is explicitly conditioned on unspecified 'regularity conditions' rather than derived by re-arranging or fitting the inputs themselves. No equations reduce a claimed prediction to a fitted parameter, no self-citation is invoked as a uniqueness theorem, and no ansatz is smuggled in. The derivation chain therefore remains non-circular; the result is a proposed constructive method whose correctness depends on external assumptions that are not tautological with the method definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The constraints and network outputs satisfy certain regularity conditions allowing the iterative procedure to enforce satisfaction to arbitrary tolerance.
Reference graph
Works this paper leans on
-
[1]
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations,
M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations,” Journal of Computational Physics, vol. 378, pp. 686–707, 2019
2019
-
[2]
Y . Min and N. Azizan, “HardNet: Hard-constrained neural net- works with universal approximation guarantees,”arXiv preprint arXiv:2410.10807, 2024
-
[3]
Police: Provably optimal linear con- straint enforcement for deep neural networks,
R. Balestriero and Y . LeCun, “Police: Provably optimal linear con- straint enforcement for deep neural networks,” inICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[4]
Physics-informed neural net- works with hard linear equality constraints,
H. Chen, G. E. C. Flores, and C. Li, “Physics-informed neural net- works with hard linear equality constraints,”Computers & Chemical Engineering, vol. 189, p. 108764, 2024
2024
-
[5]
Eco: Energy-constrained operator learning for chaotic dynamics with boundedness guarantees,
A. Goertzen, S. Tang, and N. Azizan, “Eco: Energy-constrained operator learning for chaotic dynamics with boundedness guarantees,” arXiv preprint arXiv:2512.01984, 2025
-
[6]
P. D. Grontas, A. Terpin, E. C. Balta, R. D’Andrea, and J. Lygeros, “Πnet: Optimizing hard-constrained neural networks with orthogonal projection layers,” inProceedings of the International Conference on Learning Representations (ICLR), 2026, arXiv:2508.10480
-
[7]
LMI-Net: Linear Matrix Inequality--Constrained Neural Networks via Differentiable Projection Layers
S. Tang, A. Goertzen, and N. Azizan, “Lmi-net: Linear matrix inequality–constrained neural networks via differentiable projection layers,”arXiv preprint arXiv:2604.05374, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Approximating explicit model predictive control using constrained neural networks,
S. Chen, K. Saulnier, N. Atanasov, D. D. Lee, V . Kumar, G. J. Pappas, and M. Morari, “Approximating explicit model predictive control using constrained neural networks,” in2018 Annual American control conference (ACC). IEEE, 2018, pp. 1520–1527
2018
-
[9]
End-to-end learning for optimization via constraint-enforcing ap- proximators,
R. Cristian, P. Harsha, G. Perakis, B. L. Quanz, and I. Spantidakis, “End-to-end learning for optimization via constraint-enforcing ap- proximators,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 6, 2023, pp. 7253–7260
2023
-
[10]
ENFORCE: Nonlinear Constrained Learning with Adaptive-depth Neural Projection
G. Lastrucci and A. M. Schweidtmann, “Enforce: Nonlinear con- strained learning with adaptive-depth neural projection,”arXiv preprint arXiv:2502.06774, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
H. T. Nguyen and P. L. Donti, “Fsnet: Feasibility-seeking neural network for constrained optimization with guarantees,”arXiv preprint arXiv:2506.00362, 2025
-
[12]
A method for the solution of certain non-linear problems in least squares,
K. Levenberg, “A method for the solution of certain non-linear problems in least squares,”Quarterly of applied mathematics, vol. 2, no. 2, pp. 164–168, 1944
1944
-
[13]
Nesterov,Introductory lectures on convex optimization: A basic course
Y . Nesterov,Introductory lectures on convex optimization: A basic course. Springer Science & Business Media, 2013, vol. 87
2013
-
[14]
Gradient methods for the minimisation of functionals,
B. Polyak, “Gradient methods for the minimisation of functionals,” USSR Computational Mathematics and Mathematical Physics, vol. 3, no. 4, pp. 864–878, 1963
1963
-
[15]
Linear convergence of gra- dient and proximal-gradient methods under the polyak-łojasiewicz condition,
H. Karimi, J. Nutini, and M. Schmidt, “Linear convergence of gra- dient and proximal-gradient methods under the polyak-łojasiewicz condition,” inJoint European conference on machine learning and knowledge discovery in databases. Springer, 2016, pp. 795–811
2016
-
[16]
CVXPY: A Python-embedded modeling language for convex optimization,
S. Diamond and S. Boyd, “CVXPY: A Python-embedded modeling language for convex optimization,”Journal of Machine Learning Research, vol. 17, no. 83, pp. 1–5, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.