Recognition: unknown
Differentiable Conformal Training for LLM Reasoning Factuality
Pith reviewed 2026-05-10 01:35 UTC · model grok-4.3
The pith
A differentiable relaxation of coherent factuality lets LLMs retain up to 141 percent more true claims in reasoning while keeping statistical error guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Differentiable Coherent Factuality (DCF) is a fully differentiable relaxation of the non-differentiable Coherent Factuality algorithm that enables learning improved scorers while provably recovering the original conformal coverage guarantees for outputs represented as dependency graphs.
What carries the argument
The differentiable relaxation of the non-differentiable scoring step in Coherent Factuality, which converts the joint validation over claim-ancestor graphs into a form that supports gradient-based optimization.
Load-bearing premise
The differentiable relaxation of the scoring step provably preserves the original conformal coverage guarantees for arbitrary dependency graphs.
What would settle it
An experiment in which a scorer trained with DCF is applied to a fresh calibration set of LLM reasoning outputs and produces an empirical hallucination rate that exceeds the user-specified threshold (for example, more than 10 percent errors when calibrated for 10 percent).
Figures







read the original abstract
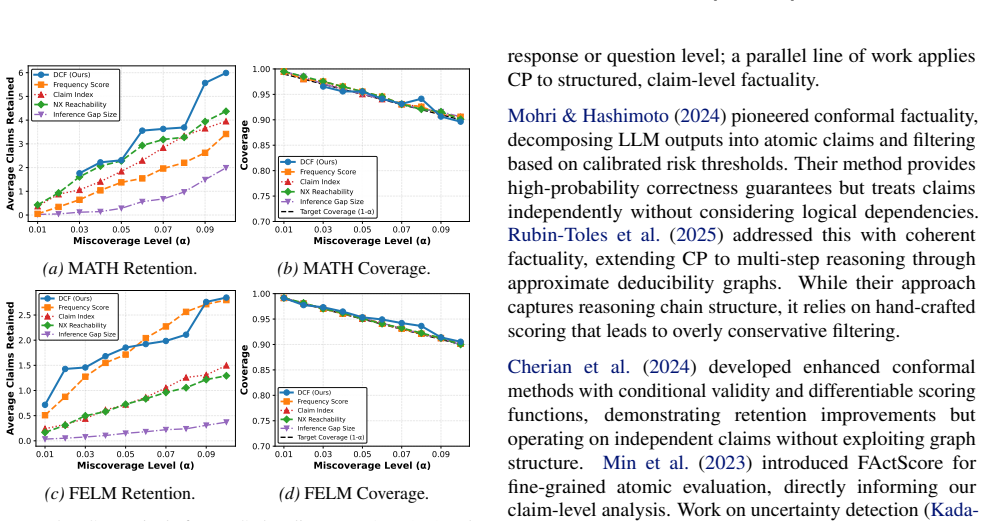
Large Language Models (LLMs) frequently hallucinate, limiting their reliability in critical applications. Conformal Prediction (CP) addresses this by calibrating error rates on held-out data to provide statistically valid confidence guarantees. Recent work extends CP to LLM factuality to filter out risky claims, ensuring that hallucination rates remain below a user-specified level (e.g., 10%). While prior methods treat claims independently, Coherent Factuality extends to multi-step reasoning by representing outputs as dependency graphs and jointly validating claims with their logical ancestors. A key limitation is that Coherent Factuality is not differentiable, requiring hand-crafted scorers that at high reliability levels remove nearly 60% of true claims. We introduce Differentiable Coherent Factuality (DCF), a fully differentiable relaxation that enables learning improved scorers while provably recovering the original algorithm's guarantees. Experiments on two benchmark reasoning datasets demonstrate DCF achieves up to 141% improvement in claim retention while maintaining reliability guarantees, representing a significant step towards reliable conformal LLM systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Differentiable Coherent Factuality (DCF) as a fully differentiable relaxation of Coherent Factuality, which extends conformal prediction to multi-step LLM reasoning via dependency graphs of claims and ancestors. The central claim is that DCF enables end-to-end learning of improved scorers while provably recovering the original method's marginal coverage guarantees (P(error) ≤ α), with experiments on two reasoning benchmarks showing up to 141% gains in claim retention at fixed reliability levels.
Significance. If the provable recovery holds under the stated conditions, the work would meaningfully advance trainable conformal methods for LLM factuality by removing the need for hand-crafted scorers that discard many true claims. The empirical retention improvements, if robustly measured against appropriate baselines, indicate practical utility for reliable multi-step reasoning systems.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the claim that the differentiable relaxation 'provably recovering the original algorithm's guarantees' for arbitrary dependency graphs is load-bearing but unsupported by any theorem statement, proof sketch, or explicit conditions (e.g., acyclicity, bounded depth, or conservative bound on the surrogate); without this, the 'maintaining reliability guarantees' assertion cannot be verified and risks being invalidated by a relaxation that loosens coverage.
- [§4] §4 (experiments): the reported 141% improvement in claim retention lacks specification of exact baselines (including the original non-differentiable Coherent Factuality), run-to-run variance, precise definition of 'claim retention,' and calibration/test split details; these omissions make it impossible to assess whether the gains preserve the marginal guarantee or merely trade coverage for retention.
minor comments (2)
- The abstract refers to 'two benchmark reasoning datasets' without naming them or providing links; this should be stated explicitly for reproducibility.
- Notation for the dependency graph and the non-differentiable scoring operator should be introduced with a small example figure to clarify the relaxation target.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where the manuscript can be strengthened for clarity and rigor. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the claim that the differentiable relaxation 'provably recovering the original algorithm's guarantees' for arbitrary dependency graphs is load-bearing but unsupported by any theorem statement, proof sketch, or explicit conditions (e.g., acyclicity, bounded depth, or conservative bound on the surrogate); without this, the 'maintaining reliability guarantees' assertion cannot be verified and risks being invalidated by a relaxation that loosens coverage.
Authors: We agree that an explicit theorem and proof sketch are needed to substantiate the recovery of guarantees. The current manuscript states the recovery property but does not include a formal statement or conditions. In the revision, we will add a theorem in §3 specifying the required assumptions (acyclicity of the dependency graph, bounded depth, and conservative surrogate bound) under which DCF recovers the marginal coverage P(error) ≤ α of the original Coherent Factuality method. A proof sketch will demonstrate that the differentiable relaxation preserves the guarantee without loosening coverage. revision: yes
-
Referee: [§4] §4 (experiments): the reported 141% improvement in claim retention lacks specification of exact baselines (including the original non-differentiable Coherent Factuality), run-to-run variance, precise definition of 'claim retention,' and calibration/test split details; these omissions make it impossible to assess whether the gains preserve the marginal guarantee or merely trade coverage for retention.
Authors: We acknowledge these omissions hinder assessment of the results. The 141% figure is relative to the original non-differentiable Coherent Factuality baseline, but this and other details were not sufficiently explicit. In the revised §4, we will add: explicit inclusion of the original Coherent Factuality as baseline, standard deviations across runs for variance, a precise definition of claim retention (proportion of true claims retained post-filtering at fixed α), and full details on calibration/test splits. These will confirm the gains preserve marginal coverage. revision: yes
Circularity Check
No circularity in the derivation chain
full rationale
The paper claims DCF is a differentiable relaxation that provably recovers the original Coherent Factuality coverage guarantees while enabling learned scorers. No equations, fitted parameters, or self-citations are exhibited that reduce the claimed guarantees or the 141% retention improvement to a definition or input by construction. The preservation of marginal coverage P(error) ≤ α is asserted as following from the relaxation of the non-differentiable scoring step over dependency graphs, but this is presented as an independent property inherited from the prior (external) conformal method rather than a self-referential fit or renaming. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rina Foygel Barber, Emmanuel J Candes, Aaditya Ramdas, and Ryan J Tibshirani
URL https://openreview.net/forum? id=33XGfHLtZg. Angelopoulos, A. N., Bates, S., Cand `es, E. J., Jordan, M. I., and Lei, L. Learn then test: Calibrating pre- dictive algorithms to achieve risk control.The Annals of Applied Statistics, 19(2):1641 – 1662, 2025. doi: 10.1214/24-AOAS1998. URL https://doi.org/ 10.1214/24-AOAS1998. Azaria, A. and Mitchell, T. ...
-
[2]
findings-emnlp.68/
URL https://aclanthology.org/2023. findings-emnlp.68/. Chen, S., Zhao, Y ., Zhang, J., Chern, I.-C., Gao, S., Liu, P., and He, J. FELM: Benchmarking factuality eval- uation of large language models. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https: //openreview.net/forum?id=jSO7Vgolc6. Che...
2023
-
[3]
In: Vlachos, A., Augen- stein, I
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ 0d441de75945e5acbc865406fc9a2559-Paper. pdf. Grover, A., Wang, E., Zweig, A., and Ermon, S. Stochastic optimization of sorting networks via continuous relax- ations. InInternational Conference on Learning Rep- resentations, 2019. URL https://openreview. net/forum?id=H1eSS3CcKX. Hendrycks, D....
-
[4]
cc/paper_files/paper/2019/file/ 5103c3584b063c431bd1268e9b5e76fb-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ 5103c3584b063c431bd1268e9b5e76fb-Paper. pdf. Rubin-Toles, M., Gambhir, M., Ramji, K., Roth, A., and Goel, S. Conformal language model reasoning with co- herent factuality. InThe Thirteenth International Confer- ence on Learning Representations, 2025. URL https: //openreview.net/forum?id=AJpU...
2019
-
[5]
Su, J., Luo, J., Wang, H., and Cheng, L
URL https://openreview.net/forum? id=t8O-4LKFVx. Su, J., Luo, J., Wang, H., and Cheng, L. Api is enough: Conformal prediction for large language models with- out logit-access, 2024. URL https://arxiv.org/ abs/2403.01216. V ovk, V ., Gammerman, A., and Shafer, G.Algorithmic learning in a random world. Springer, 2005. Wang, X., Wei, J., Schuurmans, D., Le, ...
-
[6]
Let10 w(unnorm) τ = exp(β·τ)·σ τα−τ− √τz τz . Then: {v∈V|lim Tp→0+ lim β→∞ lim τz→0+ qv ∈[0.5,1]}=U filtered,(20) whereU filtered is the CF prediction.11 Settingτ z =T ab p ,β= 1/T a p fora >0,b >2yields single-limit convergence. Proof.For simplicity of notation letT=T p andˆτα =τ α. Since lim T→0 + pv,τ = 1forr v < τ 1 2 forr v =τ 0forr v > τ ,(21)...
-
[7]
The Eiffel Tower is330m tall, located inBerlin, and wascompleted in 1889
LLM Output “The Eiffel Tower is330m tall, located inBerlin, and wascompleted in 1889.” decompose − − − − − − →
-
[8]
Score Claims v1: Height is 330m r1 = 0.2 v2: Located in Berlin r2 = 0.9 v3: Completed in 1889 r3 = 0.1 filter − − →
-
[9]
An LLM response is decomposed into atomic subclaims, each assigned a risk score
Threshold v1: Height is 330m v2: Located in Berlin v3: Completed in 1889ˆτα = 0.5(calibrated via CP) Figure 7.LLM conformal factuality. An LLM response is decomposed into atomic subclaims, each assigned a risk score. The threshold ˆτα is calibrated via CP to guarantee a 1−α factuality rate. Claims exceeding this threshold are removed (e.g., the hallucinat...
-
[10]
For each fold, train the learned logistic claim scorer on the training set
-
[11]
Compute calibration quantiles for both learned and baseline methods
-
[12]
Generate prediction sets for the test examples using both methods
-
[13]
retained
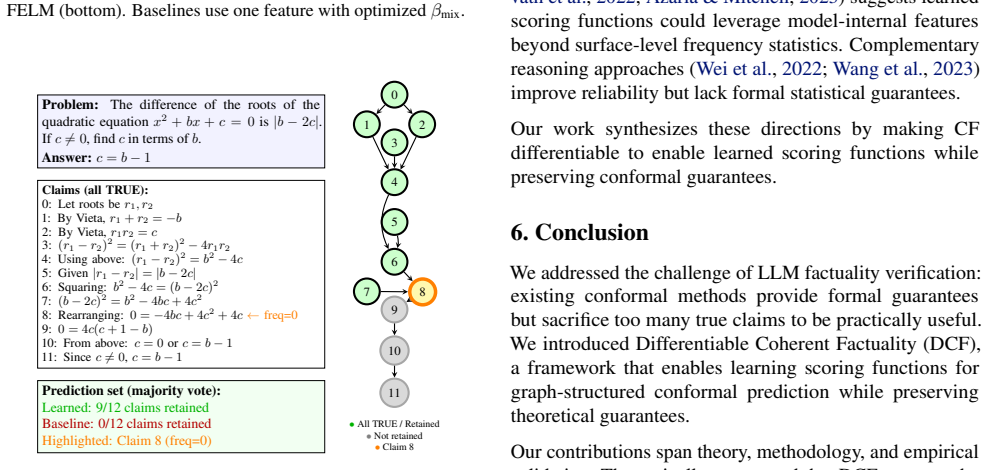
Record which claims are retained in each fold’s prediction set Baseline Configuration.The frequency-based CF baseline uses βmix optimized per- α via grid search over {0.0,0.1, . . . ,1.0}. Atα= 0.06, the optimal value isβ mix = 0.4(see Table 9). Majority Voting.For visualization, we use majority voting across folds: a claim is considered “retained” if it ...
-
[14]
Collect SHAP values from all 40 models (each contributing up to 500 claim samples)
-
[15]
Pool all SHAP values per feature across models (∼20,000 values per feature)
-
[16]
Compute mean absolute SHAP value: importance i =mean(|SHAP i|)
-
[17]
Compute standard deviation to quantify variance across models
-
[18]
Results Table 15 shows the top 10 features by mean|SHAP|value
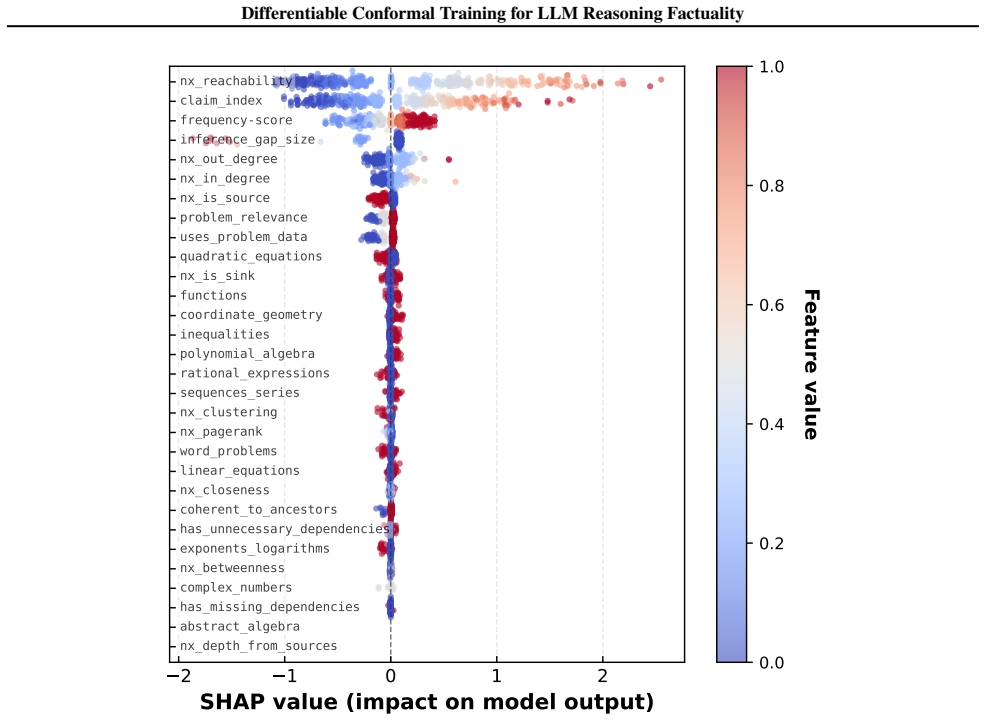
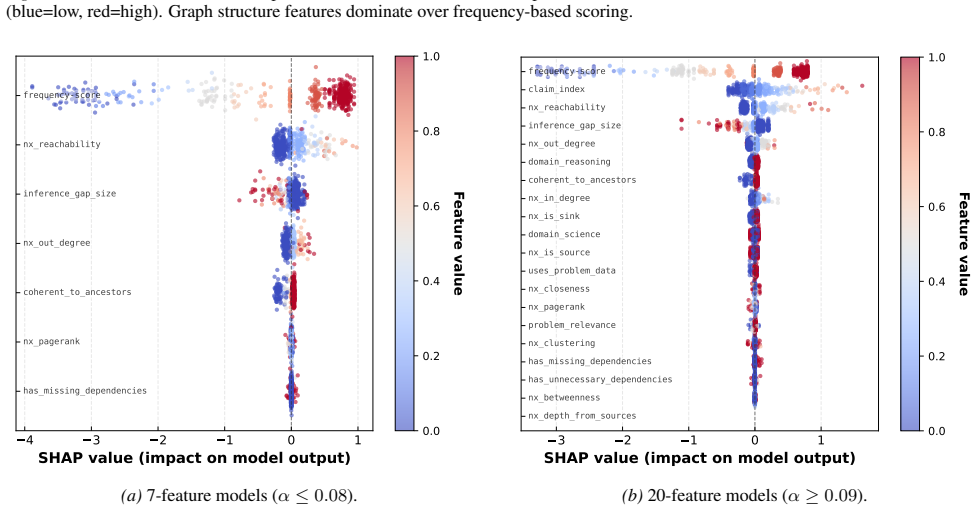
Rank features by mean importance G.2. Results Table 15 shows the top 10 features by mean|SHAP|value. Table 15.Top 10 features by SHAP importance aggregated across 40 models. Rank Feature Mean|SHAP|Std 1nx reachability0.602 0.428 2claim index0.445 0.303 3frequency-score0.180 0.126 4inference gap size0.124 0.248 5nx out degree0.060 0.081 6nx in degree0.038 ...
-
[19]
Collect scores from all 20 CV folds for both learned and baseline models
-
[20]
Apply z-score normalization pooled across both methods for comparability
-
[21]
Compute separation as: sep=µ true −µ false
-
[22]
Results Figure 11 shows the 2×2 comparison atα= 0.05
Compute Cohen’sdeffect size and distribution overlap H.2. Results Figure 11 shows the 2×2 comparison atα= 0.05. Table 16 shows separation metrics across allαvalues. Table 16.Score separation metrics across α values. DCF optimizes retention under coverage constraints, not separation directly, explaining the variability. αSeparation Ratio vs. Baseline Cohen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.