Recognition: unknown
Variance Is Not Importance: Structural Analysis of Transformer Compressibility Across Model Scales
Pith reviewed 2026-05-10 01:39 UTC · model grok-4.3
The pith
High-variance activation directions in transformers carry almost no predictive signal, so projecting them away preserves function while linear replacement of the final block delivers 34x compression at modest perplexity cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Canonical correlation analysis reveals that high-variance activation directions are approximately 96 percent uncorrelated with predictive directions, so subspace projection can retain over 90 percent of variance while degrading perplexity. Linear fits to block outputs reach R-squared values of 0.17 in the first block of Mistral 7B and rise to 0.93 in the final block when the input distribution matches the original training distribution. This conditional linearity permits direct replacement of the last block by a linear map, producing 34 times compression at a 1.71 perplexity increase, whereas multi-block replacement collapses because each substitution alters the distribution seen by later un
What carries the argument
Conditional block linearity measured by R-squared of a linear map fitted to block outputs under the correct upstream activation distribution, which strengthens with depth and isolates the final block as compressible without upstream change.
If this is right
- Single-block linear replacement on the final Mistral 7B block yields 34 times compression with a 1.71 perplexity increase.
- Multi-block replacement fails from residual error accumulation and distribution shift induced in downstream layers.
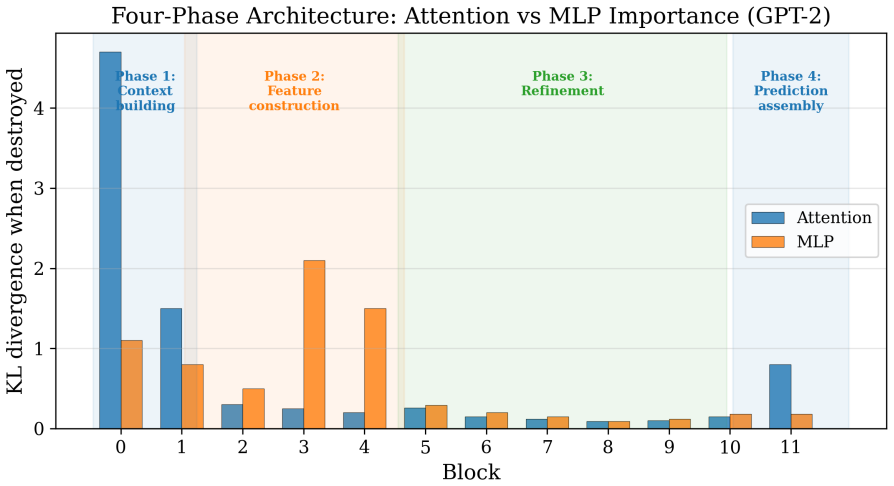
- Linearity rises steadily with depth, separating early nonlinear feature construction from late linear refinement.
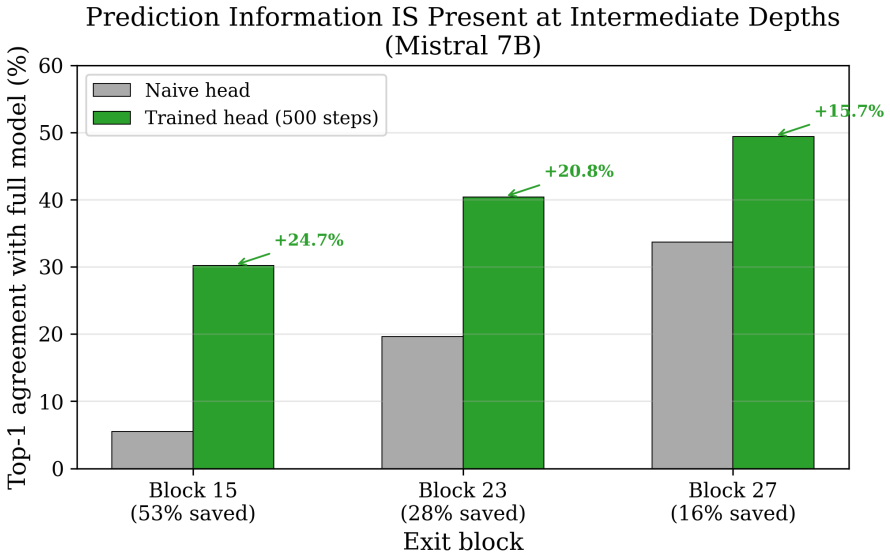
- Roughly 30 percent of tokens are computationally easy, as confirmed by exit-head and KL-divergence measurements.
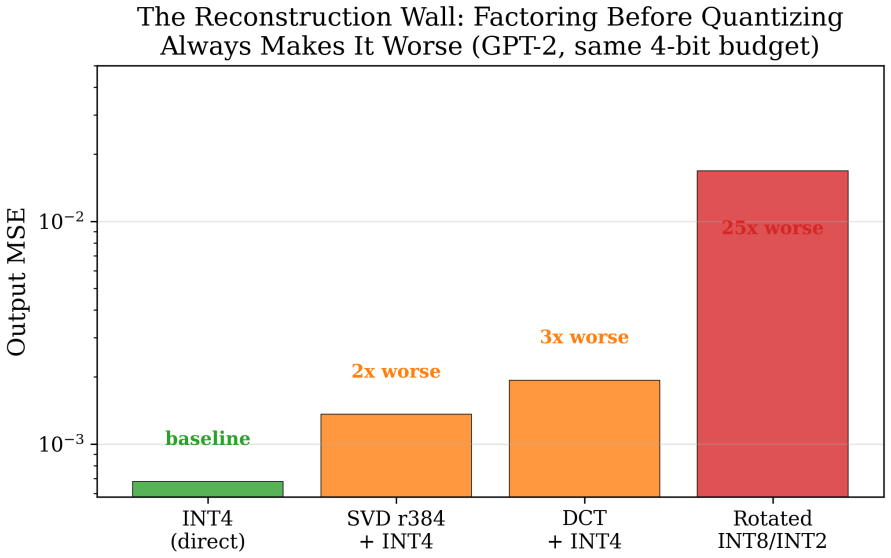
- Weight-factorization and quantization methods amplify errors through cross terms, making direct quantization superior.
Where Pith is reading between the lines
- Compression strategies should target deeper layers where linearity is reliable without requiring upstream adjustments.
- The separation of early nonlinear and late linear stages suggests per-token adaptive routing may outperform any static post-training scheme.
- The same variance-uncorrelation pattern could be tested on task-specific fine-tuned models to see whether predictive directions remain stable.
- If the depth-wise linearity trend generalizes, it would imply that progressive linearization is a structural feature of stacked transformers rather than an artifact of these two models.
Load-bearing premise
The linearity measured on GPT-2 and Mistral 7B and the lack of correlation between variance and predictive directions will hold for other models and data distributions.
What would settle it
Canonical correlation coefficients above 0.2 between high-variance principal components and changes in next-token logits on a new model such as Llama 3 would falsify the variance-is-not-importance claim.
Figures







read the original abstract
We present a systematic empirical study of transformer compression through over 40 experiments on GPT-2 (124M parameters) and Mistral 7B (7.24B parameters). Our analysis covers spectral compression, block-level function replacement, rotation-based quantization, activation geometry, and adaptive early exit. We identify five structural properties relevant to compression. (1) Variance is not importance: high-variance activation directions are approximately 96 percent uncorrelated with predictive directions (measured via CCA), and projecting onto these subspaces preserves over 90 percent of variance while degrading perplexity. (2) Block linearity is conditional: transformer blocks are approximately linear (R^2 ~ 0.95 on GPT-2, 0.93 on Mistral block 31) only under the correct upstream distribution; modifying earlier blocks induces distribution shift that degrades downstream approximations. (3) The reconstruction wall: approaches that factor weights into quantized components amplify errors through cross-terms, making direct quantization strictly superior. (4) Linearity increases with depth: Mistral 7B exhibits a progression from R^2 = 0.17 (block 0) to R^2 = 0.93 (block 31), indicating a division between nonlinear feature construction and linear refinement. (5) Approximately 30 percent of tokens are computationally easy, confirmed via exit heads and KL divergence sensitivity. We demonstrate that single-block linear replacement achieves 34x compression with a 1.71 perplexity increase on the final block of Mistral 7B, while multi-block replacement fails due to residual error accumulation and distribution shift. These findings suggest fundamental limits to static post-training compression and motivate adaptive, per-token computation as a more effective direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a systematic empirical investigation into the compressibility of transformer models, based on more than 40 experiments conducted on GPT-2 (124M parameters) and Mistral 7B (7.24B parameters). Through analyses of spectral compression, block-level function replacement, quantization, activation geometry, and early exiting, the authors identify five key structural properties: variance in activations is largely uncorrelated with predictive importance (96% via CCA), block linearity is conditional on maintaining the upstream distribution, weight factorization leads to a 'reconstruction wall', linearity increases with model depth, and approximately 30% of tokens require less computation. They further show that replacing the final block of Mistral 7B with a linear approximation yields 34x compression at the cost of a 1.71 increase in perplexity, whereas extending this to multiple blocks leads to failure from error accumulation and distribution shift. The work concludes by advocating for adaptive, per-token computation over static compression techniques.
Significance. If these empirical observations prove robust, the manuscript offers significant value by delineating practical boundaries for post-training compression methods in large language models. The explicit quantification of effects—such as R² values for linearity, CCA correlations, and specific perplexity deltas—provides actionable insights that distinguish between viable (single-block linear replacement) and non-viable (multi-block or variance-based) approaches. This empirical grounding, free of circular derivations, complements theoretical work on model efficiency and could steer research toward hybrid adaptive architectures. The scale of the experimental campaign is a notable strength.
major comments (2)
- [Experimental Setup] The manuscript reports quantitative results from over 40 experiments but the methods and experimental setup lack sufficient detail on the precise token distributions or datasets used for fitting linear approximations and computing R²/CCA metrics, the number of samples or runs, and any controls for randomness or statistical significance. This directly affects verifiability of the five structural properties, including the reported R² ~ 0.95 on GPT-2 and ~0.93 on Mistral block 31, as well as the 96% CCA uncorrelation.
- [Multi-block Replacement Analysis] The central demonstration that multi-block linear replacement fails due to residual error accumulation and distribution shift (while single-block succeeds) is load-bearing for the recommendation against static multi-block compression. However, without ablations that isolate distribution shift (e.g., by providing oracle upstream activations or using teacher-forcing during replacement), alternative explanations such as simple compounding of approximation errors cannot be ruled out.
minor comments (3)
- The observation that linearity increases with depth (R² from 0.17 at block 0 to 0.93 at block 31 in Mistral 7B) would be clearer if accompanied by a table or plot listing R² values for all intermediate blocks rather than only the endpoints.
- [Abstract] The claim that 'approximately 30 percent of tokens are computationally easy' should explicitly define the KL divergence threshold or exit criterion used to arrive at this percentage, as small changes in the threshold could alter the reported fraction substantially.
- Figure captions and legends for activation geometry or linearity plots should include axis labels, units, and any error bars or confidence intervals from multiple runs to improve interpretability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive major comments. We address each point below and will revise the manuscript to improve experimental transparency and analytical rigor.
read point-by-point responses
-
Referee: [Experimental Setup] The manuscript reports quantitative results from over 40 experiments but the methods and experimental setup lack sufficient detail on the precise token distributions or datasets used for fitting linear approximations and computing R²/CCA metrics, the number of samples or runs, and any controls for randomness or statistical significance. This directly affects verifiability of the five structural properties, including the reported R² ~ 0.95 on GPT-2 and ~0.93 on Mistral block 31, as well as the 96% CCA uncorrelation.
Authors: We thank the referee for highlighting the need for greater experimental detail to support verifiability. While the manuscript summarizes the campaign of over 40 experiments, it does not provide the requested granular information on token distributions, sample sizes, or statistical controls. In the revised manuscript we will expand the experimental setup section to specify the precise token distributions and datasets used for fitting linear approximations and computing the R²/CCA metrics, the number of samples and runs, and the controls for randomness and statistical significance. These additions will directly substantiate the reported quantitative results. revision: yes
-
Referee: [Multi-block Replacement Analysis] The central demonstration that multi-block linear replacement fails due to residual error accumulation and distribution shift (while single-block succeeds) is load-bearing for the recommendation against static multi-block compression. However, without ablations that isolate distribution shift (e.g., by providing oracle upstream activations or using teacher-forcing during replacement), alternative explanations such as simple compounding of approximation errors cannot be ruled out.
Authors: We agree that explicit ablations isolating distribution shift from error accumulation would strengthen the analysis. The manuscript shows that single-block replacement succeeds while multi-block replacement fails rapidly; this pattern aligns with both residual accumulation and the conditional linearity property (linearity holds only under the correct upstream distribution, with R² increasing from 0.17 to 0.93 with depth). We did not include oracle or teacher-forcing ablations in the original work. In the revision we will add a dedicated discussion paragraph on this distinction and, where computationally feasible, include a limited ablation using cached true activations or teacher-forcing for small numbers of blocks. This will refine the presentation but will not alter our conclusion against static multi-block compression. revision: partial
Circularity Check
No significant circularity; purely empirical study
full rationale
The paper conducts a systematic empirical analysis across >40 experiments on GPT-2 and Mistral 7B, reporting direct measurements such as R^2 linearity scores, CCA correlations (~96% uncorrelation), and compression outcomes (34x with +1.71 PPL). No derivation chain, first-principles predictions, or equations are present that reduce to fitted inputs or self-referential definitions. All five structural properties are observational results tied to the specific models, distributions, and experimental setups, with no self-citations, ansatzes, or uniqueness theorems invoked as load-bearing steps. The work is self-contained against external benchmarks and does not claim universal derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Frantar, E., et al. “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers.”arXiv:2210.17323, 2022
work page internal anchor Pith review arXiv 2022
-
[2]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Lin, J., et al. “AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration.”arXiv:2306.00978, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Spqr: A sparse-quantized representation for near-lossless llm weight compression,
Dettmers, T., et al. “SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression.”arXiv:2306.03078, 2023
-
[4]
Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks,
Tseng, A., et al. “QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks.”arXiv:2402.04396, 2024
-
[5]
Spinquant–llm quantization with learned rotations,
Liu, Z., et al. “SpinQuant: LLM Quantization with Learned Rotations.”arXiv:2405.16406, 2024
-
[6]
Mixed-Precision Quantization of Large Language Models
ResQ: “Mixed-Precision Quantization of Large Language Models.”arXiv:2412.14363, 2024
-
[7]
Your Transformer is Secretly Linear
Razzhigaev, A., et al. “Your Transformer is Secretly Linear.”arXiv:2405.12250, 2024
-
[8]
The unreasonable ineffectiveness of the deeper layers.arXiv preprint arXiv:2403.17887, 2024
Gromov, A., et al. “The Unreasonable Ineffectiveness of the Deeper Layers.” arXiv:2403.17887, 2024
-
[9]
ShortGPT: Layers in Large Language Models are More Redundant Than You Think
Men, X., et al. “ShortGPT: Layers in Large Language Models are More Redundant Than You Think.” 2024
2024
-
[10]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E., et al. “LoRA: Low-Rank Adaptation of Large Language Models.”arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Confident Adaptive Language Modeling
Schuster, T., et al. “Confident Adaptive Language Modeling.”NeurIPS, 2022
2022
-
[12]
Fast Inference from Transformers via Speculative Decoding
Leviathan, Y., et al. “Fast Inference from Transformers via Speculative Decoding.”ICML, 2023
2023
-
[13]
Dynamic Computing for Transformers
“Dynamic Computing for Transformers.”arXiv:2504.20922, 2025
-
[14]
Pointer Sentinel Mixture Models
Merity, S., et al. “Pointer Sentinel Mixture Models.”arXiv:1609.07843, 2016
work page internal anchor Pith review arXiv 2016
-
[15]
QLoRA: Efficient Finetuning of Quantized LLMs
Dettmers, T., et al. “QLoRA: Efficient Finetuning of Quantized LLMs.”NeurIPS, 2023
2023
-
[16]
Quantization Dominates Rank Reduction for KV-Cache Compression
Salfati, S. “Quantization Dominates Rank Reduction for KV-Cache Compression.”fraQtl AI Research, 2026
2026
-
[17]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Liu, Z., et al. “KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache.” arXiv:2402.02750, 2024
work page internal anchor Pith review arXiv 2024
-
[18]
MatryoshkaKV: Adaptive KV Compression via Trainable Orthogonal Projection
Yang, L., et al. “MatryoshkaKV: Adaptive KV Compression via Trainable Orthogonal Projection.”arXiv:2410.14731, 2024
-
[19]
KQ-SVD: Low-Rank Approximation of the KV Cache
Lesens, A., et al. “KQ-SVD: Low-Rank Approximation of the KV Cache.” arXiv:2512.05916, 2025. 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.