Recognition: unknown
MGDA-Decoupled: Geometry-Aware Multi-Objective Optimisation for DPO-based LLM Alignment
Pith reviewed 2026-05-10 01:33 UTC · model grok-4.3
The pith
MGDA-Decoupled finds a shared descent direction that accounts for each alignment objective's convergence speed in DPO-based LLM training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MGDA-Decoupled is a decoupled variant of the multiple gradient descent algorithm that, within the DPO loss, identifies a common parameter-space direction by explicitly incorporating each objective's individual gradient geometry and convergence dynamics, thereby avoiding the procedural unfairness of fixed scalarization.
What carries the argument
MGDA-Decoupled, which computes a shared descent direction by decoupling and accounting for each objective's convergence rate in the DPO training loop.
Load-bearing premise
That explicitly accounting for each objective's convergence dynamics through a geometry-aware shared descent direction produces more equitable trade-offs and superior win rates than fixed scalarization, without introducing new biases or requiring unstated components.
What would settle it
On the UltraFeedback dataset, a head-to-head run in which MGDA-Decoupled does not produce higher win rates than standard scalarized DPO, either overall or on individual objectives such as truthfulness.
Figures


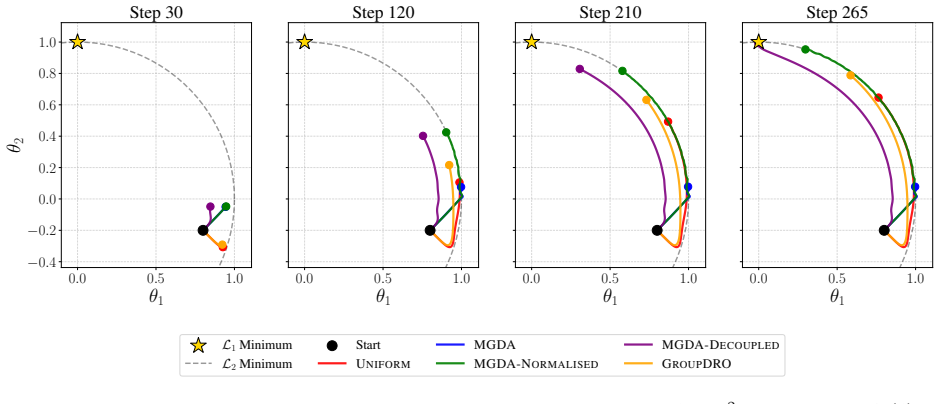
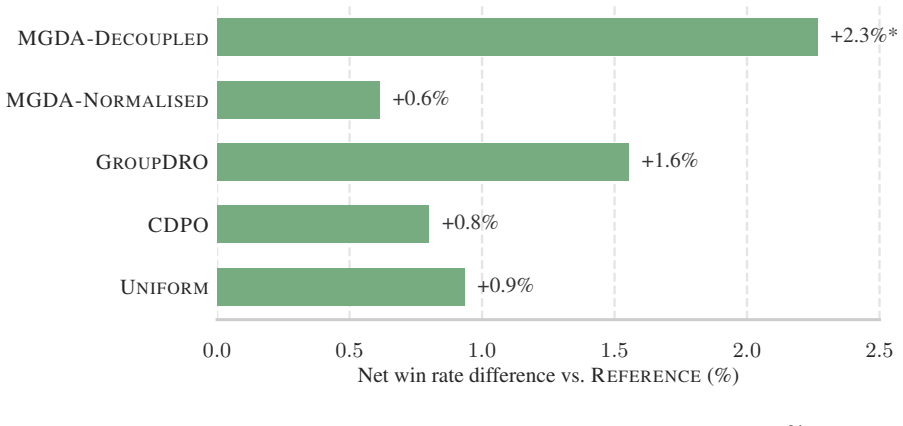
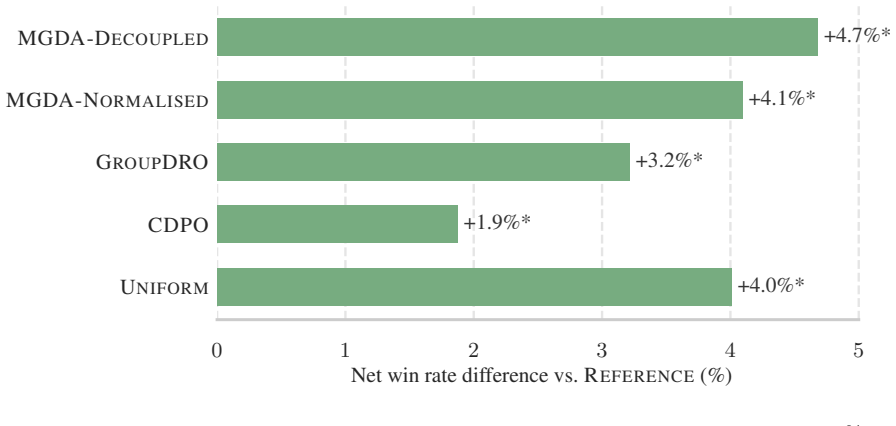
read the original abstract
Aligning large language models (LLMs) to desirable human values requires balancing multiple, potentially conflicting objectives such as helpfulness, truthfulness, and harmlessness, which presents a multi-objective optimisation challenge. Most alignment pipelines rely on a fixed scalarisation of these objectives, which can introduce procedural unfairness by systematically under-weighting harder-to-optimise or minority objectives. To promote more equitable trade-offs, we introduce MGDA-Decoupled, a geometry-based multi-objective optimisation algorithm that finds a shared descent direction while explicitly accounting for each objective's convergence dynamics. In contrast to prior methods that depend on reinforcement learning (e.g., GAPO) or explicit reward models (e.g., MODPO), our approach operates entirely within the lightweight Direct Preference Optimisation (DPO) paradigm. Experiments on the UltraFeedback dataset show that geometry-aware methods -- and MGDA-Decoupled in particular -- achieve the highest win rates against golden responses, both overall and per objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MGDA-Decoupled, a geometry-aware multi-objective optimization algorithm for Direct Preference Optimization (DPO) in LLM alignment. It claims to compute a shared descent direction that explicitly accounts for per-objective convergence dynamics, thereby avoiding the procedural unfairness of fixed scalarization among conflicting objectives such as helpfulness, truthfulness, and harmlessness. The method is presented as operating entirely within the lightweight DPO paradigm without reinforcement learning or explicit reward models. Experiments on the UltraFeedback dataset are reported to demonstrate that geometry-aware approaches, and MGDA-Decoupled in particular, attain the highest win rates against golden responses both overall and per objective.
Significance. If the reported win-rate advantages are shown through ablations to arise specifically from the geometry-aware shared descent construction rather than ancillary implementation choices, the work would provide a computationally efficient route to more equitable multi-objective alignment within existing DPO pipelines. This addresses a practical gap between scalarized DPO and heavier RL-based alternatives.
major comments (2)
- [Experiments] The experimental evaluation does not include ablation studies that isolate the MGDA geometry component (shared descent direction accounting for convergence dynamics) from other potential differences in loss weighting, reference-model handling, or per-objective preference sampling. Without such isolation, the causal attribution of the UltraFeedback win-rate gains to the proposed geometry-aware mechanism remains untested.
- [Method] The method section provides no explicit derivation, pseudocode, or comparison to standard MGDA showing how the decoupled treatment of convergence dynamics is implemented and why it differs from fixed scalarization in a way that guarantees equitable trade-offs.
minor comments (1)
- [Abstract] The abstract asserts superior performance on UltraFeedback but omits any mention of baseline methods, statistical significance testing, or variance across runs, which would strengthen the presentation of the empirical claims.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments. We agree that additional details and experiments will strengthen the manuscript and address the concerns raised. We respond to each major comment below and commit to the indicated revisions.
read point-by-point responses
-
Referee: [Experiments] The experimental evaluation does not include ablation studies that isolate the MGDA geometry component (shared descent direction accounting for convergence dynamics) from other potential differences in loss weighting, reference-model handling, or per-objective preference sampling. Without such isolation, the causal attribution of the UltraFeedback win-rate gains to the proposed geometry-aware mechanism remains untested.
Authors: We agree that the current experiments do not isolate the geometry-aware shared descent construction from ancillary implementation choices. In the revised manuscript we will add targeted ablation studies that hold loss weighting, reference-model handling, and per-objective preference sampling fixed while varying only the optimization geometry (comparing MGDA-Decoupled against standard MGDA and scalarized DPO). These ablations will directly test whether the reported win-rate improvements arise from the decoupled treatment of convergence dynamics. revision: yes
-
Referee: [Method] The method section provides no explicit derivation, pseudocode, or comparison to standard MGDA showing how the decoupled treatment of convergence dynamics is implemented and why it differs from fixed scalarization in a way that guarantees equitable trade-offs.
Authors: We acknowledge that the method section currently lacks an explicit derivation, pseudocode, and a direct comparison to standard MGDA. In the revision we will insert a step-by-step derivation of the MGDA-Decoupled update rule that shows how per-objective convergence dynamics are incorporated into the shared descent direction. We will also provide algorithm pseudocode and a concise theoretical comparison to both standard MGDA and fixed scalarization, clarifying the mechanism that promotes equitable trade-offs without additional RL or reward models. revision: yes
Circularity Check
No circularity: MGDA-Decoupled defined from DPO primitives without reduction to inputs or self-citations.
full rationale
The paper presents MGDA-Decoupled as an explicit algorithmic extension of standard DPO that computes a shared descent direction while tracking per-objective convergence geometry. This construction is introduced directly from the multi-objective optimization literature and the DPO loss formulation, without any fitted parameters being relabeled as predictions, without self-definitional loops in the equations, and without load-bearing self-citations that substitute for independent justification. Experiments are performed on the public UltraFeedback dataset with reported win rates against baselines; these empirical comparisons do not feed back into the derivation. No ansatz is smuggled via citation, no uniqueness theorem is invoked from prior author work, and no known result is merely renamed. The derivation chain therefore remains self-contained and externally verifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[4]
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, J \' e r \' e my Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, Tony Tong Wang, Samuel Marks, Charbel - Rapha \" e l S \' e gerie, Micah Carroll, Andi Peng, Phillip J. K. Christoffersen, Mehul Damani, Stewart Slocum, Usman Anwar, Anand Siththaranjan, M...
2023
-
[5]
Bedi, and Mengdi Wang
Souradip Chakraborty, Jiahao Qiu, Hui Yuan, Alec Koppel, Dinesh Manocha, Furong Huang, Amrit S. Bedi, and Mengdi Wang. Maxmin-rlhf: Alignment with diverse human preferences. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?id=8tzjEMF0Vq
2024
-
[7]
Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks
Zhao Chen, Vijay Badrinarayanan, Chen - Yu Lee, and Andrew Rabinovich. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. In Jennifer G. Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsm \" a ssan, Stockholm, Sweden, July 10-15, 2018 , volume 8...
2018
-
[8]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, editors, Advances in Neural Information Processing Systems 30: Annual Conference on Neural ...
2017
-
[10]
Multi-objective optimisation using evolutionary algorithms: an introduction
Kalyanmoy Deb. Multi-objective optimisation using evolutionary algorithms: an introduction. In Multi-objective evolutionary optimisation for product design and manufacturing, pages 3--34. Springer, 2011
2011
-
[16]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings , 2015. URL http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Statistical significance tests for machine translation evaluation
Philipp Koehn. Statistical significance tests for machine translation evaluation. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing , EMNLP 2004, A meeting of SIGDAT, a Special Interest Group of the ACL, held in conjunction with ACL 2004, 25-26 July 2004, Barcelona, Spain , pages 388--395. ACL , 2004. URL https://ac...
2004
-
[19]
Gradient-adaptive policy optimization: Towards multi-objective alignment of large language models
Chengao Li, Hanyu Zhang, Yunkun Xu, Hongyan Xue, Xiang Ao, and Qing He. Gradient-adaptive policy optimization: Towards multi-objective alignment of large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1...
2025
-
[22]
Conflict-averse gradient descent for multi-task learning
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-averse gradient descent for multi-task learning. In Marc'Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors, Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, Neur...
2021
-
[23]
Amopo: Adaptive multi-objective preference optimization without reward models and reference models
Qi Liu, Jingqing Ruan, Hao Li, Haodong Zhao, Desheng Wang, Jiansong Chen, Guanglu Wan, Xunliang Cai, Zhi Zheng, and Tong Xu. Amopo: Adaptive multi-objective preference optimization without reward models and reference models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computation...
2025
-
[25]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human fee...
2022
-
[26]
Introduction to optimization
Boris T Polyak. Introduction to optimization. optimization software. Inc., Publications Division, New York, 1 0 (32): 0 1, 1987
1987
-
[27]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference ...
2023
-
[28]
Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards
Alexandre Ram \' e , Guillaume Couairon, Corentin Dancette, Jean - Baptiste Gaya, Mustafa Shukor, Laure Soulier, and Matthieu Cord. Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural ...
2023
-
[31]
Multi-task learning as multi-objective optimization
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicol \` o Cesa - Bianchi, and Roman Garnett, editors, Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 201...
2018
-
[34]
Smith, Mari Ostendorf, and Hannaneh Hajishirzi
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, and Hannaneh Hajishirzi. Fine-grained human feedback gives better rewards for language model training. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing...
2023
-
[36]
Metaaligner: Towards generalizable multi-objective alignment of language models
Kailai Yang, Zhiwei Liu, Qianqian Xie, Jimin Huang, Tianlin Zhang, and Sophia Ananiadou. Metaaligner: Towards generalizable multi-objective alignment of language models. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors, Advances in Neural Information Processing Systems 38: Annual C...
2024
-
[37]
Rewards-in-context: Multi-objective alignment of foundation models with dynamic preference adjustment
Rui Yang, Xiaoman Pan, Feng Luo, Shuang Qiu, Han Zhong, Dong Yu, and Jianshu Chen. Rewards-in-context: Multi-objective alignment of foundation models with dynamic preference adjustment. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net, 2024 b . URL https://openreview.net/forum?id=QLcBzRI3V3
2024
-
[38]
Gradient surgery for multi-task learning
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning. In Hugo Larochelle, Marc'Aurelio Ranzato, Raia Hadsell, Maria - Florina Balcan, and Hsuan - Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2...
2020
-
[39]
Yao, Wenpin Tang, and Sambit Sahu
Hanyang Zhao, Genta Indra Winata, Anirban Das, Shi - Xiong Zhang, David D. Yao, Wenpin Tang, and Sambit Sahu. Rainbowpo: A unified framework for combining improvements in preference optimization. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025. URL https://openreview.ne...
2025
-
[40]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei - Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural...
2023
-
[41]
Panacea: Pareto alignment via preference adaptation for llms
Yifan Zhong, Chengdong Ma, Xiaoyuan Zhang, Ziran Yang, Haojun Chen, Qingfu Zhang, Siyuan Qi, and Yaodong Yang. Panacea: Pareto alignment via preference adaptation for llms. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors, Advances in Neural Information Processing Systems 38: Annua...
2024
-
[43]
Multi-objective evolutionary optimisation for product design and manufacturing , pages=
Multi-objective optimisation using evolutionary algorithms: an introduction , author=. Multi-objective evolutionary optimisation for product design and manufacturing , pages=. 2011 , publisher=
2011
-
[44]
Christiano and Jan Leike and Tom B
Paul F. Christiano and Jan Leike and Tom B. Brown and Miljan Martic and Shane Legg and Dario Amodei , editor =. Deep Reinforcement Learning from Human Preferences , booktitle =. 2017 , url =
2017
-
[45]
Manning and Stefano Ermon and Chelsea Finn , editor =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn , editor =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , booktitle =. 2023 , url =
2023
-
[46]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell and Yuntao Bai and Anna Chen and Dawn Drain and Deep Ganguli and Tom Henighan and Andy Jones and Nicholas Joseph and Benjamin Mann and Nova DasSarma and Nelson Elhage and Zac Hatfield. A General Language Assistant as a Laboratory for Alignment , journal =. 2021 , url =. 2112.00861 , timestamp =
work page internal anchor Pith review arXiv 2021
-
[47]
Zhanhui Zhou and Jie Liu and Jing Shao and Xiangyu Yue and Chao Yang and Wanli Ouyang and Yu Qiao , editor =. Beyond One-Preference-Fits-All Alignment: Multi-Objective Direct Preference Optimization , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-ACL.630 , timestamp =
-
[48]
Gradient-Adaptive Policy Optimization: Towards Multi-Objective Alignment of Large Language Models , booktitle =
Chengao Li and Hanyu Zhang and Yunkun Xu and Hongyan Xue and Xiang Ao and Qing He , editor =. Gradient-Adaptive Policy Optimization: Towards Multi-Objective Alignment of Large Language Models , booktitle =. 2025 , url =
2025
-
[49]
Smith and Mari Ostendorf and Hannaneh Hajishirzi , editor =
Zeqiu Wu and Yushi Hu and Weijia Shi and Nouha Dziri and Alane Suhr and Prithviraj Ammanabrolu and Noah A. Smith and Mari Ostendorf and Hannaneh Hajishirzi , editor =. Fine-Grained Human Feedback Gives Better Rewards for Language Model Training , booktitle =. 2023 , url =
2023
-
[50]
Jiahui Li and Hanlin Zhang and Fengda Zhang and Tai. Optimizing Language Models with Fair and Stable Reward Composition in Reinforcement Learning , booktitle =. 2024 , url =. doi:10.18653/V1/2024.EMNLP-MAIN.565 , timestamp =
-
[51]
Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler and Nisan Stiennon and Jeffrey Wu and Tom B. Brown and Alec Radford and Dario Amodei and Paul F. Christiano and Geoffrey Irving , title =. CoRR , volume =. 2019 , url =. 1909.08593 , timestamp =
work page internal anchor Pith review arXiv 2019
-
[52]
Haoxiang Wang and Yong Lin and Wei Xiong and Rui Yang and Shizhe Diao and Shuang Qiu and Han Zhao and Tong Zhang , editor =. Arithmetic Control of LLMs for Diverse User Preferences: Directional Preference Alignment with Multi-Objective Rewards , booktitle =. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.468 , timestamp =
-
[53]
Multiple-gradient Descent Algorithm for Pareto-Front Identification , booktitle =
Jean. Multiple-gradient Descent Algorithm for Pareto-Front Identification , booktitle =. 2014 , url =. doi:10.1007/978-94-017-9054-3\_3 , timestamp =
-
[54]
Enhanc- ing LLM safety via constrained direct preference op- timization
Zixuan Liu and Xiaolin Sun and Zizhan Zheng , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2403.02475 , eprinttype =. 2403.02475 , timestamp =
-
[55]
Gradient Surgery for Multi-Task Learning , booktitle =
Tianhe Yu and Saurabh Kumar and Abhishek Gupta and Sergey Levine and Karol Hausman and Chelsea Finn , editor =. Gradient Surgery for Multi-Task Learning , booktitle =. 2020 , url =
2020
-
[56]
Gradient-based multi-objective deep learning: Algorithms, theories, applications, and beyond
Weiyu Chen and Xiaoyuan Zhang and Baijiong Lin and Xi Lin and Han Zhao and Qingfu Zhang and James T. Kwok , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.10945 , eprinttype =. 2501.10945 , timestamp =
-
[57]
Mitigating the Alignment Tax of
Yong Lin and Hangyu Lin and Wei Xiong and Shizhe Diao and Jianmeng Liu and Jipeng Zhang and Rui Pan and Haoxiang Wang and Wenbin Hu and Hanning Zhang and Hanze Dong and Renjie Pi and Han Zhao and Nan Jiang and Heng Ji and Yuan Yao and Tong Zhang , editor =. Mitigating the Alignment Tax of. Proceedings of the 2024 Conference on Empirical Methods in Natural...
-
[58]
Multi-Task Learning as Multi-Objective Optimization , booktitle =
Ozan Sener and Vladlen Koltun , editor =. Multi-Task Learning as Multi-Objective Optimization , booktitle =. 2018 , url =
2018
-
[59]
RainbowPO:
Hanyang Zhao and Genta Indra Winata and Anirban Das and Shi. RainbowPO:. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[60]
Forty-first International Conference on Machine Learning,
Rui Yang and Xiaoman Pan and Feng Luo and Shuang Qiu and Han Zhong and Dong Yu and Jianshu Chen , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
2024
-
[61]
Robust Multi-Objective Preference Alignment with Online
Raghav Gupta and Ryan Sullivan and Yunxuan Li and Samrat Phatale and Abhinav Rastogi , editor =. Robust Multi-Objective Preference Alignment with Online. AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA,. 2025 , url =. doi:10.1609/AAAI.V39I26.34942 , timestamp =
-
[62]
The Thirteenth International Conference on Learning Representations,
Zhilin Wang and Alexander Bukharin and Olivier Delalleau and Daniel Egert and Gerald Shen and Jiaqi Zeng and Oleksii Kuchaiev and Yi Dong , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[63]
Ultrafeedback: Boosting language models with scaled ai feedback.arXiv preprint arXiv:2310.01377,
Ganqu Cui and Lifan Yuan and Ning Ding and Guanming Yao and Wei Zhu and Yuan Ni and Guotong Xie and Zhiyuan Liu and Maosong Sun , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.01377 , eprinttype =. 2310.01377 , timestamp =
-
[64]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =
Lianmin Zheng and Wei. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =. 2023 , url =
2023
-
[65]
Shiori Sagawa and Pang Wei Koh and Tatsunori B. Hashimoto and Percy Liang , title =. CoRR , volume =. 2019 , url =. 1911.08731 , timestamp =
work page internal anchor Pith review arXiv 2019
-
[66]
Gemma 2: Improving Open Language Models at a Practical Size
Morgane Rivi. Gemma 2: Improving Open Language Models at a Practical Size , journal =. 2024 , url =. doi:10.48550/ARXIV.2408.00118 , eprinttype =. 2408.00118 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2408.00118 2024
-
[67]
An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinl...
work page internal anchor Pith review doi:10.48550/arxiv.2501.15383 2025
-
[68]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai and Andy Jones and Kamal Ndousse and Amanda Askell and Anna Chen and Nova DasSarma and Dawn Drain and Stanislav Fort and Deep Ganguli and Tom Henighan and Nicholas Joseph and Saurav Kadavath and Jackson Kernion and Tom Conerly and Sheer El Showk and Nelson Elhage and Zac Hatfield. Training a Helpful and Harmless Assistant with Reinforcement Lea...
-
[69]
Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing ,
Philipp Koehn , title =. Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing ,. 2004 , url =
2004
-
[70]
Panacea: Pareto Alignment via Preference Adaptation for LLMs , booktitle =
Yifan Zhong and Chengdong Ma and Xiaoyuan Zhang and Ziran Yang and Haojun Chen and Qingfu Zhang and Siyuan Qi and Yaodong Yang , editor =. Panacea: Pareto Alignment via Preference Adaptation for LLMs , booktitle =. 2024 , url =
2024
-
[71]
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul F. Christiano and Jan Leike and Ryan Lowe , editor =...
2022
-
[72]
Bedi and Mengdi Wang , title =
Souradip Chakraborty and Jiahao Qiu and Hui Yuan and Alec Koppel and Dinesh Manocha and Furong Huang and Amrit S. Bedi and Mengdi Wang , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
2024
-
[73]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , journal =
Stephen Casper and Xander Davies and Claudia Shi and Thomas Krendl Gilbert and J. Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , journal =. 2023 , url =
2023
-
[74]
Akhil Agnihotri and Rahul Jain and Deepak Ramachandran and Zheng Wen , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.10892 , eprinttype =. 2505.10892 , timestamp =
-
[75]
AMoPO: Adaptive Multi-objective Preference Optimization without Reward Models and Reference Models , booktitle =
Qi Liu and Jingqing Ruan and Hao Li and Haodong Zhao and Desheng Wang and Jiansong Chen and Guanglu Wan and Xunliang Cai and Zhi Zheng and Tong Xu , editor =. AMoPO: Adaptive Multi-objective Preference Optimization without Reward Models and Reference Models , booktitle =. 2025 , url =
2025
-
[76]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:. 3rd International Conference on Learning Representations,. 2015 , url =
2015
-
[77]
GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks , booktitle =
Zhao Chen and Vijay Badrinarayanan and Chen. GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks , booktitle =. 2018 , url =
2018
-
[78]
Rewarded soups: towards Pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards , booktitle =
Alexandre Ram. Rewarded soups: towards Pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards , booktitle =. 2023 , url =
2023
-
[79]
URLhttps://doi.org/10.18653/v1/2024.emnlp-main.85
Yiju Guo and Ganqu Cui and Lifan Yuan and Ning Ding and Zexu Sun and Bowen Sun and Huimin Chen and Ruobing Xie and Jie Zhou and Yankai Lin and Zhiyuan Liu and Maosong Sun , editor =. Controllable Preference Optimization: Toward Controllable Multi-Objective Alignment , booktitle =. 2024 , url =. doi:10.18653/V1/2024.EMNLP-MAIN.85 , timestamp =
-
[80]
MetaAligner: Towards Generalizable Multi-Objective Alignment of Language Models , booktitle =
Kailai Yang and Zhiwei Liu and Qianqian Xie and Jimin Huang and Tianlin Zhang and Sophia Ananiadou , editor =. MetaAligner: Towards Generalizable Multi-Objective Alignment of Language Models , booktitle =. 2024 , url =
2024
-
[81]
Geon. SafeDPO:. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.20065 , eprinttype =. 2505.20065 , timestamp =
-
[82]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton. Llama 2: Open Foundation and Fine-Tuned Chat Models , journal =. 2023 , url =. doi:10.48550/ARXIV.2307.09288 , eprinttype ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[83]
Conflict-Averse Gradient Descent for Multi-task learning , booktitle =
Bo Liu and Xingchao Liu and Xiaojie Jin and Peter Stone and Qiang Liu , editor =. Conflict-Averse Gradient Descent for Multi-task learning , booktitle =. 2021 , url =
2021
-
[84]
Claude Lemar. S. Boyd, L. Vandenberghe, Convex Optimization, Cambridge University Press, 2004 hardback,. Eur. J. Oper. Res. , volume =. 2006 , url =. doi:10.1016/J.EJOR.2005.02.002 , timestamp =
-
[85]
optimization software , author=
Introduction to optimization. optimization software , author=. Inc., Publications Division, New York , volume=
-
[86]
Aaron Hurst and Adam Lerer and Adam P. Goucher and Adam Perelman and Aditya Ramesh and Aidan Clark and AJ Ostrow and Akila Welihinda and Alan Hayes and Alec Radford and Aleksander Madry and Alex Baker. GPT-4o System Card , journal =. 2024 , url =. doi:10.48550/ARXIV.2410.21276 , eprinttype =. 2410.21276 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.21276 2024
-
[87]
Xuefei Ning and Zinan Lin and Zixuan Zhou and Huazhong Yang and Yu Wang , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2307.15337 , eprinttype =. 2307.15337 , timestamp =
-
[88]
Ziegler and Ryan Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul F
Nisan Stiennon and Long Ouyang and Jeffrey Wu and Daniel M. Ziegler and Ryan Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul F. Christiano , editor =. Learning to summarize with human feedback , booktitle =. 2020 , url =
2020
-
[89]
Taylor Sorensen and Liwei Jiang and Jena D. Hwang and Sydney Levine and Valentina Pyatkin and Peter West and Nouha Dziri and Ximing Lu and Kavel Rao and Chandra Bhagavatula and Maarten Sap and John Tasioulas and Yejin Choi , editor =. Value Kaleidoscope: Engaging. Thirty-Eighth. 2024 , url =. doi:10.1609/AAAI.V38I18.29970 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.