Recognition: unknown
Forget, Then Recall: Learnable Compression and Selective Unfolding via Gist Sparse Attention
Pith reviewed 2026-05-10 00:30 UTC · model grok-4.3
The pith
Interleaved gist tokens compress context into learnable summaries that route sparse attention and then selectively unfold raw chunks for detail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
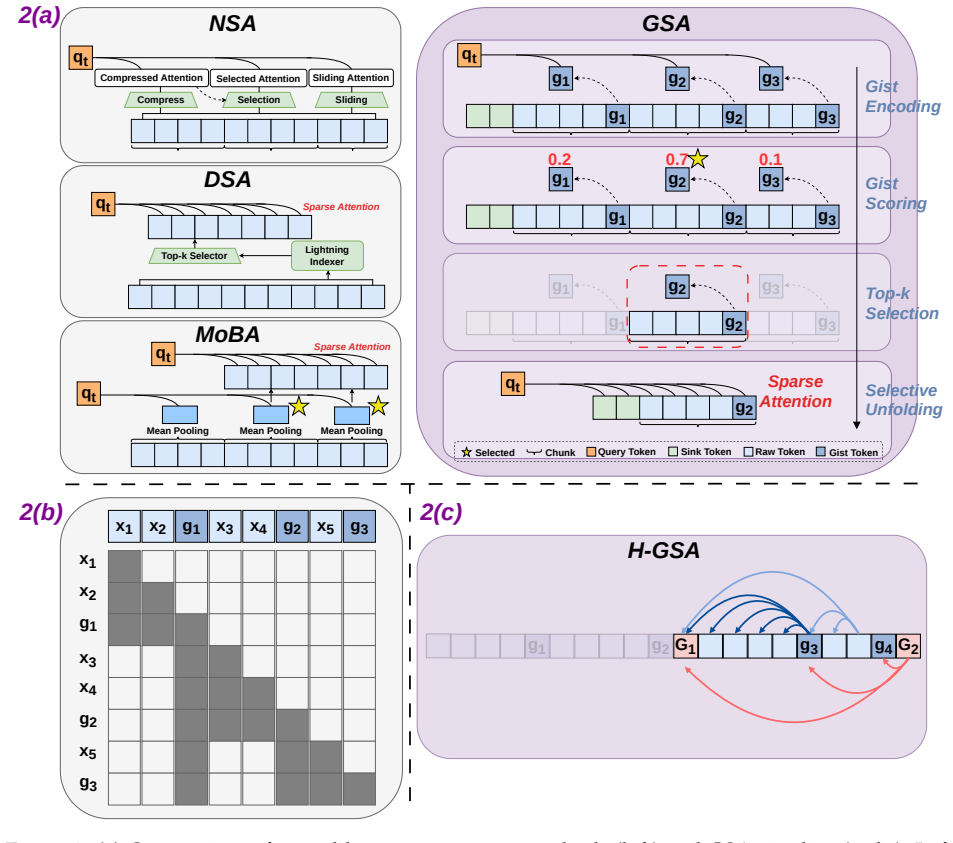
Gist compression tokens interleaved in the input learn compact summaries of raw token sets and double as routing signals for sparse attention. The resulting selective unfolding mechanism first reduces the context to these gists, selects the most relevant ones, and restores the matching raw chunks so that attention can operate on them in detail. The process runs inside the standard training loop without architecture changes, supports recursive gist-of-gist construction for multi-resolution access, and yields logarithmic per-step decoding cost while delivering higher accuracy than prior compression or inference-only sparse methods on LongBench and RAG at 8× to 32× compression.
What carries the argument
Gist Sparse Attention (GSA), in which interleaved learnable gist tokens serve both as context compressors and as routing signals that trigger selective restoration of raw token chunks for targeted full attention.
If this is right
- End-to-end training becomes possible without any external retrieval module or fixed index.
- Recursive gist-of-gist layers produce multi-resolution context access with logarithmic per-step cost.
- The same trained model works across compression ratios from 8× to 32× while beating both compression-only and inference-time sparse baselines.
- No changes to the underlying transformer architecture are required.
- Global compact representations coexist with on-demand fine-grained evidence inside a single forward pass.
Where Pith is reading between the lines
- The routing role of gist tokens might let models dynamically adjust effective context length per layer or per task without retraining.
- The forget-then-recall pattern could transfer to other sequence models such as state-space or linear-attention architectures.
- Hierarchical gists open a route to training regimes that explicitly optimize for different levels of abstraction at different depths.
- If gist quality scales with model size, the approach may reduce the need for ever-larger KV caches in deployed long-context systems.
Load-bearing premise
That the gist tokens retain enough information so that later selective unfolding can reliably recover the critical raw details needed for accurate answers.
What would settle it
An ablation that removes the unfolding step and measures whether task accuracy on LongBench long-context retrieval and multi-hop questions falls to the level of pure compression baselines at the same ratio.
Figures



read the original abstract
Scaling large language models to long contexts is challenging due to the quadratic computational cost of full attention. Mitigation approaches include KV-cache selection or compression techniques. We instead provide an effective and end-to-end learnable bridge between the two without requiring architecture modification. In particular, our key insight is that interleaved gist compression tokens -- which provide a learnable summary of sets of raw tokens -- can serve as routing signals for sparse attention. Building on this, we introduce selective unfolding via GSA, which first compresses the context into gist tokens, then selects the most relevant gists, and subsequently restores the corresponding raw chunks for detailed attention. This yields a simple coarse-to-fine mechanism that combines compact global representations with targeted access to fine-grained evidence. We further incorporate this process directly into training in an end-to-end fashion, avoiding the need for external retrieval modules. In addition, we extend the framework hierarchically via recursive gist-of-gist construction, enabling multi-resolution context access with logarithmic per-step decoding complexity. Empirical results on LongBench and RAG benchmarks demonstrate that our method consistently outperforms other compression baselines as well as inference-time sparse attention methods across compression ratios from $8\times$ to $32\times$. The code is available at: https://github.com/yuzhenmao/gist-sparse-attention/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Gist Sparse Attention (GSA), an end-to-end trainable method that interleaves learnable gist compression tokens to produce compact context summaries. These tokens serve as routing signals to select relevant gists for sparse attention, followed by selective unfolding to restore and attend to the corresponding raw token chunks in a coarse-to-fine manner. The framework is extended hierarchically with recursive gist-of-gist tokens for multi-resolution access and logarithmic decoding complexity. Empirical results claim consistent outperformance over compression baselines and inference-time sparse attention methods on LongBench and RAG benchmarks at 8×–32× compression ratios, without external retrieval modules.
Significance. If the central empirical claims hold under rigorous controls, the work provides a practical learnable bridge between compression and sparse attention for long-context LLMs, potentially reducing quadratic costs while preserving performance. Strengths include the end-to-end training formulation, hierarchical extension, and public code release, which support reproducibility. The approach could influence efficient inference designs if the routing and unfolding mechanism proves robust across tasks.
major comments (3)
- [§4] §4 (Experiments): The reported outperformance on LongBench and RAG lacks details on experimental controls such as number of random seeds, standard deviations across runs, or statistical significance tests (e.g., paired t-tests). This is load-bearing for the claim of 'consistent' gains at 8×–32× ratios, as small effect sizes or high variance could undermine comparisons to baselines.
- [§3.2] §3.2 (Selective Unfolding): The description of how gist tokens enable routing while allowing recovery of task-critical details via unfolding is not supported by an ablation isolating the information retention (e.g., comparing performance when unfolding is disabled or when gist placement is non-interleaved). This directly tests the load-bearing assumption that compression does not erase evidence needed for downstream recovery.
- [Table 3] Table 3 (Ablation studies): No results are shown for the hierarchical gist-of-gist extension's contribution independent of the base GSA mechanism; without this, the logarithmic complexity claim and multi-resolution benefit cannot be isolated from the core compression-routing pipeline.
minor comments (2)
- [§3.1] Notation in §3.1: The definition of gist token insertion (e.g., how many per chunk) uses inconsistent symbols across equations; standardize to improve clarity.
- [Figure 2] Figure 2: The diagram of the coarse-to-fine pipeline would benefit from explicit arrows indicating the end-to-end gradient flow during training.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with clarifications and commit to revisions that strengthen the empirical support and ablations in the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The reported outperformance on LongBench and RAG lacks details on experimental controls such as number of random seeds, standard deviations across runs, or statistical significance tests (e.g., paired t-tests). This is load-bearing for the claim of 'consistent' gains at 8×–32× ratios, as small effect sizes or high variance could undermine comparisons to baselines.
Authors: We agree that reporting additional statistical controls would improve the robustness of our claims. In the revised manuscript, we will explicitly state that all experiments were run with 3 random seeds, report mean performance with standard deviations in the LongBench and RAG tables, and include paired t-test p-values comparing GSA to the strongest baselines at each compression ratio. These additions will directly address concerns about variance and consistency. revision: yes
-
Referee: [§3.2] §3.2 (Selective Unfolding): The description of how gist tokens enable routing while allowing recovery of task-critical details via unfolding is not supported by an ablation isolating the information retention (e.g., comparing performance when unfolding is disabled or when gist placement is non-interleaved). This directly tests the load-bearing assumption that compression does not erase evidence needed for downstream recovery.
Authors: We recognize the importance of isolating the contribution of selective unfolding. We will add a dedicated ablation in the revised version of §3.2 and Table 3 that compares full GSA against (i) a no-unfolding variant that attends only to gist tokens and (ii) a non-interleaved gist placement baseline. This will quantify the performance drop when raw-chunk recovery is disabled and thereby demonstrate that gist compression alone does not fully retain task-critical details. revision: yes
-
Referee: [Table 3] Table 3 (Ablation studies): No results are shown for the hierarchical gist-of-gist extension's contribution independent of the base GSA mechanism; without this, the logarithmic complexity claim and multi-resolution benefit cannot be isolated from the core compression-routing pipeline.
Authors: We agree that the hierarchical extension requires a clearer isolated evaluation. In the revised Table 3 we will add a direct comparison of base GSA versus the full hierarchical GSA (with recursive gist-of-gist tokens) on the same LongBench subsets, reporting both accuracy and effective decoding complexity. This will separate the multi-resolution and logarithmic-complexity benefits from the core compression-routing pipeline. revision: yes
Circularity Check
No circularity; end-to-end trainable architecture with empirical validation
full rationale
The paper proposes an architectural primitive (interleaved gist tokens for compression and routing, followed by selective unfolding and hierarchical gist-of-gist extension) that is trained end-to-end without external modules. Performance claims rest on benchmark results (LongBench, RAG) rather than any derivation chain. No equations, fitted parameters, or self-citations are shown that reduce the central claims to inputs by construction. The method is self-contained and falsifiable via external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard transformer attention and KV-cache mechanisms remain unchanged outside the inserted gist tokens.
invented entities (2)
-
Gist compression tokens
no independent evidence
-
Gist-of-gist tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Learning to compress prompts with gist tokens , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
arXiv preprint arXiv:2509.15763 , year=
UniGist: Towards General and Hardware-aligned Sequence-level Long Context Compression , author=. arXiv preprint arXiv:2509.15763 , year=
-
[3]
Long context compression with activation beacon , author=. arXiv preprint arXiv:2401.03462 , year=
-
[4]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Adapting language models to compress contexts , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[5]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[6]
Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189,
Moba: Mixture of block attention for long-context llms , author=. arXiv preprint arXiv:2502.13189 , year=
-
[7]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Gqa: Training generalized multi-query transformer models from multi-head checkpoints , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[8]
Longlora: Efficient fine-tuning of long-context large language models , author=. arXiv preprint arXiv:2309.12307 , year=
-
[9]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[10]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
Findings of the association for computational linguistics: EMNLP 2022 , pages=
Booksum: A collection of datasets for long-form narrative summarization , author=. Findings of the association for computational linguistics: EMNLP 2022 , pages=
2022
-
[12]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Gated delta networks: Improving mamba2 with delta rule , author=. arXiv preprint arXiv:2412.06464 , year=
work page internal anchor Pith review arXiv
-
[13]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[14]
RedPajama: an Open Dataset for Training Large Language Models , author =
-
[15]
2023 , eprint=
Retentive Network: A Successor to Transformer for Large Language Models , author=. 2023 , eprint=
2023
-
[16]
Findings of the association for computational linguistics: EMNLP 2023 , pages=
Rwkv: Reinventing rnns for the transformer era , author=. Findings of the association for computational linguistics: EMNLP 2023 , pages=
2023
-
[17]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-time sequence modeling with selective state spaces. arXiv , author=. arXiv preprint arXiv:2312.00752 , volume=
work page internal anchor Pith review arXiv
-
[18]
Efficiently Modeling Long Sequences with Structured State Spaces
Efficiently modeling long sequences with structured state spaces , author=. arXiv preprint arXiv:2111.00396 , year=
work page internal anchor Pith review arXiv
-
[19]
International conference on machine learning , pages=
Transformers are rnns: Fast autoregressive transformers with linear attention , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[20]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[21]
2024 , month = sep, howpublished =
Llama 3.2: Revolutionizing edge AI and vision with open, customizable models , author =. 2024 , month = sep, howpublished =
2024
-
[22]
2024 , eprint=
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression , author=. 2024 , eprint=
2024
-
[23]
2024 , eprint=
Qwen2 Technical Report , author=. 2024 , eprint=
2024
-
[24]
arXiv preprint arXiv:2406.10774 , year=
Quest: Query-aware sparsity for efficient long-context llm inference , author=. arXiv preprint arXiv:2406.10774 , year=
-
[25]
arXiv preprint arXiv:2504.08934 , year=
Long context in-context compression by getting to the gist of gisting , author=. arXiv preprint arXiv:2504.08934 , year=
-
[26]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Repocoder: Repository-level code completion through iterative retrieval and generation , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[27]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Advances in Neural Information Processing Systems , volume=
Star: Bootstrapping reasoning with reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Kvlink: Accelerating large language models via efficient kv cache reuse , author=. arXiv preprint arXiv:2502.16002 , year=
-
[30]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Native sparse attention: Hardware-aligned and natively trainable sparse attention , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review arXiv
-
[32]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Efficient Streaming Language Models with Attention Sinks
Efficient streaming language models with attention sinks , author=. arXiv preprint arXiv:2309.17453 , year=
work page internal anchor Pith review arXiv
-
[35]
Longformer: The Long-Document Transformer
Longformer: The long-document transformer , author=. arXiv preprint arXiv:2004.05150 , year=
work page internal anchor Pith review arXiv 2004
-
[36]
Generating Long Sequences with Sparse Transformers
Generating long sequences with sparse transformers , author=. arXiv preprint arXiv:1904.10509 , year=
work page internal anchor Pith review arXiv 1904
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.