Recognition: unknown
ChatGPT as a Time Capsule: The Limits of Price Discovery
Pith reviewed 2026-05-08 12:55 UTC · model grok-4.3
The pith
Frozen LLM checkpoints extract outlook scores from past public text that predict future analyst revisions, target prices, and stock returns after standard valuation controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Frozen large language model checkpoints serve as compressed representations of public textual information at specific past dates; when prompted to produce sector-neutral outlook scores for equities, these scores are positively associated with future analyst revisions, target-price changes, and one-month cross-sectional returns in regressions that control for contemporaneous market-implied valuations and standard factors.
What carries the argument
The LLM outlook score, obtained by prompting each frozen checkpoint on firm-related public text to produce a forward-looking assessment that is then normalized within sectors.
If this is right
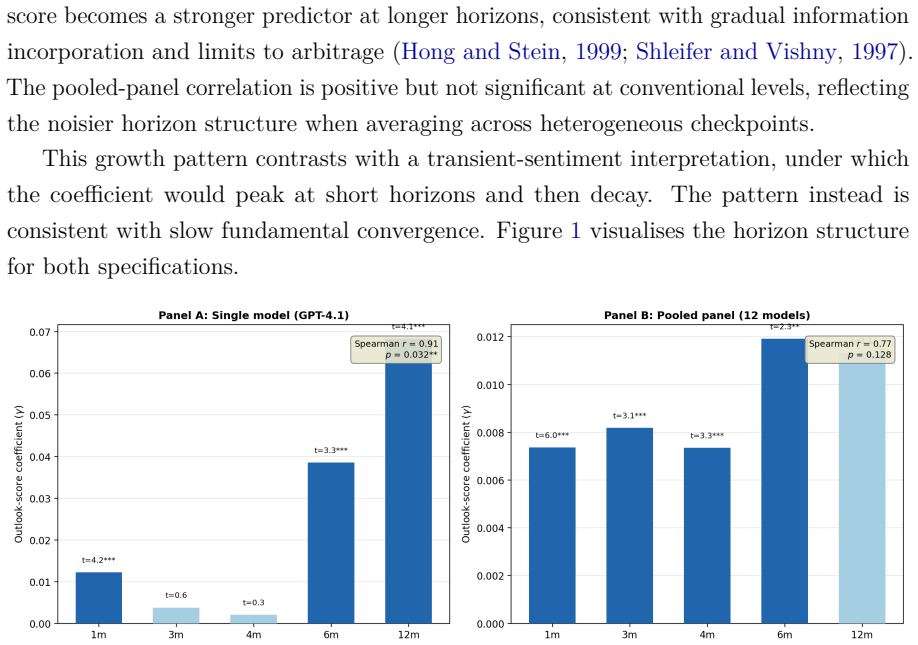
- The association with returns strengthens at longer horizons even after an intermediate dip.
- The signal is larger for high-analyst-coverage firms, consistent with the bottleneck being the cost of synthesizing many documents.
- LLM checkpoints can serve as objective, time-stamped summaries of the public textual record for testing information aggregation.
- Standard valuation measures leave measurable qualitative text information unpriced.
Where Pith is reading between the lines
- Markets may systematically underweight qualitative signals that require reading across many scattered sources.
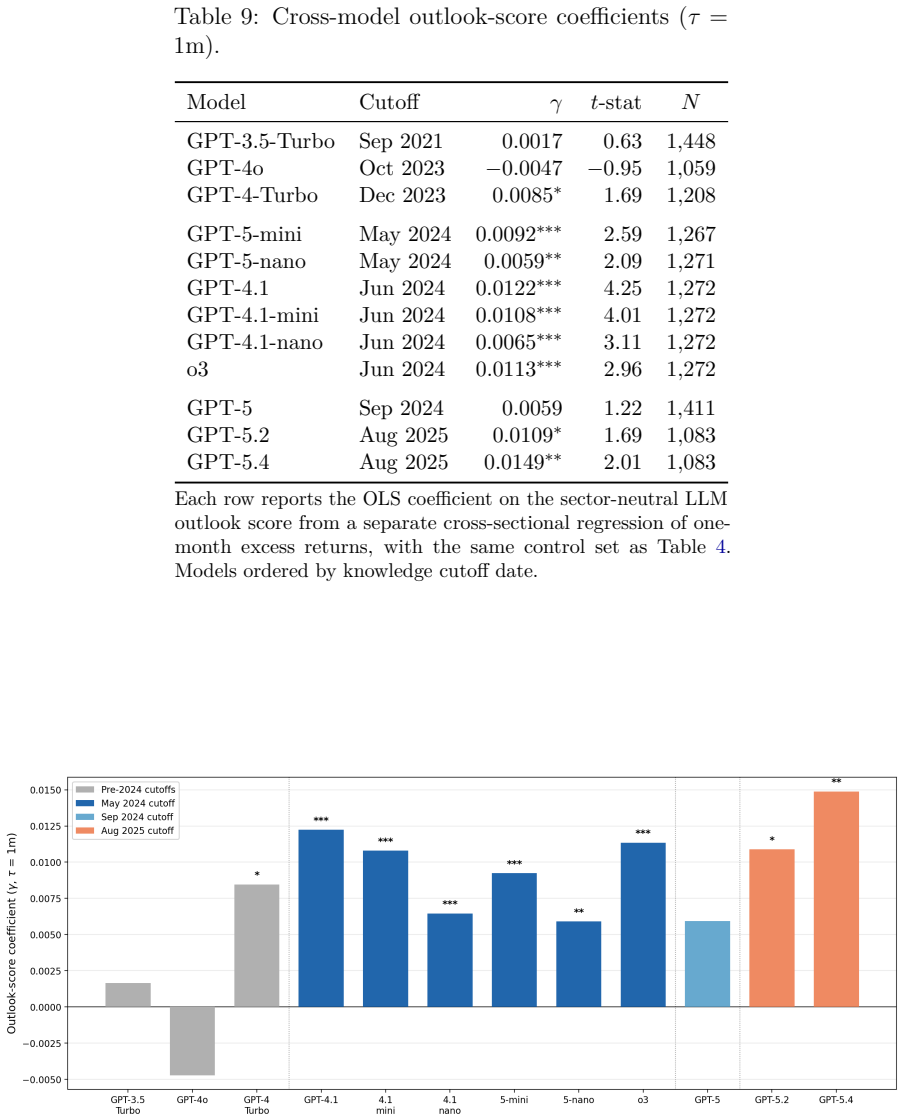
- Repeating the exercise with non-OpenAI models or older checkpoints could test whether the result depends on specific training data or architecture.
- If aggregation costs are the limit, improvements in LLM summarization might gradually reduce the observed predictability.
Load-bearing premise
The outlook scores capture genuine incremental qualitative information from the public record that markets have not yet fully incorporated, rather than arising from prompting choices or data-construction decisions.
What would settle it
Finding that the predictive coefficients become statistically insignificant when the same analysis is repeated with model snapshots whose cutoffs fall after the forecast return window.
Figures
read the original abstract
Frozen large language model (LLM) checkpoints extract information from pre-cutoff public text that is associated with future fundamentals and equity returns beyond standard contemporaneous valuation measures. Because each frozen checkpoint has a fixed knowledge cutoff, it can be interpreted as a compressed representation of publicly available textual information at a given point in time. We treat twelve OpenAI snapshots spanning 2021-2025 as time-stamped summaries of the public textual record and extract a sector-neutral LLM outlook score for roughly 7,000 U.S. equities per cross-section. The outlook score is positively associated with analyst revisions, target-price changes and one-month cross-sectional returns in both Fama-MacBeth regressions and pooled panels with model fixed effects (t = 6.02), after direct controls for market-implied valuation and standard factors. Predictability broadly increases with the return horizon, despite a non-monotonic intermediate dip, and, in the pooled panel, is stronger for firms with high analyst coverage, consistent with the view that the bottleneck is not investor inattention but the cost of aggregating dispersed qualitative information across many documents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript treats twelve frozen OpenAI LLM checkpoints (2021-2025) as time-stamped compressions of public textual information. For each cross-section it extracts a sector-neutral outlook score across roughly 7,000 U.S. equities and shows that these scores are positively associated with subsequent analyst revisions, target-price changes, and one-month cross-sectional returns. The associations survive Fama-MacBeth regressions and pooled panels with model fixed effects (t = 6.02) after direct controls for market-implied valuation and standard factors. Predictability rises with horizon (with a non-monotonic dip) and is stronger among high-analyst-coverage firms, which the authors interpret as evidence that aggregation costs, rather than inattention, limit price discovery.
Significance. If the central empirical result is robust, the paper supplies a novel, temporally structured test of whether markets fully incorporate dispersed qualitative public information. The use of multiple frozen checkpoints provides a clean way to hold the information set fixed at different dates while varying the aggregator; the finding that predictability strengthens with analyst coverage supplies direct support for an aggregation-cost channel. These elements, together with the large cross-section and explicit valuation controls, make the work a useful contribution to the literature on information processing and limits to arbitrage.
major comments (2)
- [Section 3 (Methodology)] The description of the LLM prompting procedure (exact template, output parsing rule, temperature, and sector-neutralization method) is insufficiently detailed. Because the outlook score is the sole novel regressor, any systematic bias introduced by the chosen prompt framing or scale anchoring could generate the reported t = 6.02 coefficient independently of the underlying text content. The manuscript should report invariance checks under prompt rephrasing and alternative aggregation rules.
- [Section 4 (Results)] Table 2 and the associated Fama-MacBeth specifications report a t-statistic of 6.02 but do not list the full set of controls, the precise construction of the market-implied valuation measure, or any adjustment for multiple testing across horizons and sub-samples. Without these elements it is impossible to verify that the incremental predictive power is not an artifact of omitted variables or data-construction choices.
minor comments (2)
- [Abstract and Section 4] The abstract states that predictability 'broadly increases with the return horizon' yet notes a 'non-monotonic intermediate dip'; a figure or table showing the full term structure of coefficients would clarify this pattern.
- [Section 5 (Conclusion)] The paper would benefit from a short discussion of whether the results are sensitive to the choice of OpenAI checkpoints versus other LLM families, even if only as a robustness footnote.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to improve the transparency and robustness of our methodology and results presentation. We address each major comment in turn and will incorporate the suggested clarifications and checks into the revised manuscript.
read point-by-point responses
-
Referee: [Section 3 (Methodology)] The description of the LLM prompting procedure (exact template, output parsing rule, temperature, and sector-neutralization method) is insufficiently detailed. Because the outlook score is the sole novel regressor, any systematic bias introduced by the chosen prompt framing or scale anchoring could generate the reported t = 6.02 coefficient independently of the underlying text content. The manuscript should report invariance checks under prompt rephrasing and alternative aggregation rules.
Authors: We agree that greater detail on the prompting procedure is warranted to ensure reproducibility and to rule out prompt-specific artifacts. In the revised manuscript we will include the exact prompt template, the deterministic temperature setting of 0, the full output parsing rules, and a precise description of the sector-neutralization algorithm. We have already performed limited invariance tests with rephrased prompts and alternative aggregation (e.g., mean versus median outlook scores); these checks will be reported in a new appendix and confirm that the main coefficient remains positive and statistically significant. revision: yes
-
Referee: [Section 4 (Results)] Table 2 and the associated Fama-MacBeth specifications report a t-statistic of 6.02 but do not list the full set of controls, the precise construction of the market-implied valuation measure, or any adjustment for multiple testing across horizons and sub-samples. Without these elements it is impossible to verify that the incremental predictive power is not an artifact of omitted variables or data-construction choices.
Authors: We will expand the reporting as requested. The revised Table 2 will explicitly enumerate every control variable. We will add a dedicated paragraph in Section 3 describing the exact construction of the market-implied valuation measure (the residual from a cross-sectional regression of log market capitalization on log book equity, earnings, and other standard fundamentals). For multiple testing, the headline t = 6.02 is obtained from the single pooled panel specification with model fixed effects; we will note this and supply Bonferroni-adjusted p-values for the horizon-specific and sub-sample tests in the revised tables. revision: yes
Circularity Check
No circularity: empirical test of LLM-extracted scores via standard regressions
full rationale
The paper extracts sector-neutral outlook scores by applying fixed prompting to frozen pre-cutoff LLM checkpoints on public text, then estimates associations with future analyst revisions, target prices, and returns using Fama-MacBeth and fixed-effects regressions that include explicit controls for market valuation and standard factors. No equation or step defines the score in terms of the target returns or revisions, nor renames a fitted parameter as a prediction; the regressions test rather than construct the claimed incremental association. The procedure is independent of the outcome data by design, with no self-citation load-bearing the central result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S., Moskowitz, T
Asness, C. S., Moskowitz, T. J., and Pedersen, L. H. (2013). Value and momentum everywhere. The Journal of Finance , 68(3):929--985
2013
-
[2]
and Brown, P
Ball, R. and Brown, P. (1968). An empirical evaluation of accounting income numbers. Journal of Accounting Research , 6(2):159--178
1968
-
[3]
Barberis, N., Shleifer, A., and Vishny, R. (1998). A model of investor sentiment. Journal of Financial Economics , 49(3):307--343
1998
-
[4]
Bernard, V. L. and Thomas, J. K. (1989). Post-earnings-announcement drift: delayed price response or risk premium?. Journal of Accounting Research , 27:1--36
1989
-
[5]
C., Gelbach, J
Cameron, A. C., Gelbach, J. B., and Miller, D. L. (2008). Bootstrap-Based Improvements for Inference with Clustered Errors. The Review of Economics and Statistics , 90(3):414--427
2008
-
[6]
Cao, S., Jiang, W., Wang, J., and Yang, B. (2024). From man vs. machine to man+ machine: The art and AI of stock analyses. Journal of Financial Economics , 160:103910
2024
-
[7]
Da, Z., Engelberg, J., and Gao, P. (2011). In search of attention. The Journal of Finance , 66(5):1461--1499
2011
-
[8]
and Pollet, J
DellaVigna, S. and Pollet, J. M. (2009). Investor inattention and Friday earnings announcements. The Journal of Finance , 64(2):709--749
2009
-
[9]
Didisheim, A., Fraschini, M., and Somoza, L. (2025). AI's predictable memory in financial analysis. Economics Letters :112602
2025
-
[10]
Driscoll, J. C. and Kraay, A. C. (1998). Consistent covariance matrix estimation with spatially dependent panel data. The Review of Economics and Statistics , 80(4):549--560
1998
-
[11]
Easton, P. D. (2004). PE ratios, PEG ratios, and estimating the implied expected rate of return on equity capital. The Accounting Review , 79(1):73--95
2004
-
[12]
Fama, E. F. (1970). Efficient capital markets. The Journal of Finance , 25(2):383--417
1970
-
[13]
Fama, E. F. and MacBeth, J. D. (1973). Risk, return, and equilibrium: Empirical tests. Journal of Political Economy , 81(3):607--636
1973
-
[14]
Fama, E. F. and French, K. R. (1992). The cross-section of expected stock returns. The Journal of Finance , 47(2):427--465
1992
-
[15]
R., Lee, C
Gebhardt, W. R., Lee, C. M., and Swaminathan, B. (2001). Toward an implied cost of capital. Journal of Accounting Research , 39(1):135--176
2001
-
[16]
Grossman, S. J. and Stiglitz, J. E. (1980). On the impossibility of informationally efficient markets. The American Economic Review , 70(3):393--408
1980
-
[17]
and Teoh, S
Hirshleifer, D. and Teoh, S. H. (2003). Limited attention, information disclosure, and financial reporting. Journal of Accounting and Economics , 36(1-3):337--386
2003
-
[18]
S., and Teoh, S
Hirshleifer, D., Lim, S. S., and Teoh, S. H. (2009). Driven to distraction: Extraneous events and underreaction to earnings news. The Journal of Finance , 64(5):2289--2325
2009
-
[19]
S., and Teoh, S
Hirshleifer, D., Lim, S. S., and Teoh, S. H. (2011). Limited investor attention and stock market misreactions to accounting information. The Review of Asset Pricing Studies , 1(1):35--73
2011
-
[20]
and Stein, J
Hong, H. and Stein, J. C. (1999). A unified theory of underreaction, momentum trading, and overreaction in asset markets. The Journal of Finance , 54(6):2143--2184
1999
-
[21]
Hong, H., Lim, T., and Stein, J. C. (2000). Bad news travels slowly: Size, analyst coverage, and the profitability of momentum strategies. The Journal of Finance , 55(1):265--295
2000
-
[22]
and Titman, S
Jegadeesh, N. and Titman, S. (1993). Returns to buying winners and selling losers: Implications for stock market efficiency. The Journal of Finance , 48(1):65--91
1993
- [23]
-
[24]
Lazaridou, A., Kuncoro, A., Gribovskaya, E., Agrawal, D., Liska, A., Terzi, T., Gimenez, M., de Masson d'Autume, C., Kocisky, T., Ruder, S., and et al. (2021). Mind the gap: Assessing temporal generalization in neural language models. Advances in Neural Information Processing Systems , 34:29348--29363
2021
-
[25]
Lehner, S. (2024). The Future of Accounting: AI-Driven Tone Manipulation in SEC Filings. Available at SSRN 4984337
2024
-
[26]
Liu, J., Nissim, D., and Thomas, J. (2002). Equity valuation using multiples. Journal of Accounting Research , 40(1):135--172
2002
-
[27]
Lopez-Lira, A. and Tang, Y. (2023). Can chatgpt forecast stock price movements? return predictability and large language models. arXiv preprint arXiv:2304.07619
- [28]
-
[29]
and McDonald, B
Loughran, T. and McDonald, B. (2011). When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks. The Journal of Finance , 66(1):35--65
2011
- [30]
-
[31]
McLean, R. D. and Pontiff, J. (2016). Does academic research destroy stock return predictability?. The Journal of Finance , 71(1):5--32
2016
-
[32]
Miller, B. P. (2010). The effects of reporting complexity on small and large investor trading. The Accounting Review , 85(6):2107--2143
2010
-
[33]
Novy-Marx, R. (2013). The other side of value: The gross profitability premium. Journal of Financial Economics , 108(1):1--28
2013
-
[34]
Rusticus, T. O. (2019). Market inefficiency and implied cost of capital models. Available at SSRN 1933713
2019
-
[35]
Schwert, G. W. (2003). Anomalies and market efficiency. Handbook of the Economics of Finance , 1:939--974
2003
-
[36]
Shiller, R. J. (2020). Narrative economics: How stories go viral and drive major economic events . Princeton University Press
2020
-
[37]
and Vishny, R
Shleifer, A. and Vishny, R. W. (1997). The limits of arbitrage. The Journal of Finance , 52(1):35--55
1997
-
[38]
Sims, C. A. (2003). Implications of rational inattention. Journal of Monetary Economics , 50(3):665--690
2003
-
[39]
Sloan, R. G. (1996). Do stock prices fully reflect information in accruals and cash flows about future earnings?. The Accounting Review :289--315
1996
-
[40]
Tetlock, P. C. (2007). Giving content to investor sentiment: The role of media in the stock market. The Journal of Finance , 62(3):1139--1168
2007
-
[41]
C., Saar-Tsechansky, M., and Macskassy, S
Tetlock, P. C., Saar-Tsechansky, M., and Macskassy, S. (2008). More than words: Quantifying language to measure firms' fundamentals. The Journal of Finance , 63(3):1437--1467
2008
-
[42]
H., Han, X., and Lopez-Lira, A
Van Binsbergen, J. H., Han, X., and Lopez-Lira, A. (2023). Man versus machine learning: The term structure of earnings expectations and conditional biases. The Review of Financial Studies , 36(6):2361--2396
2023
-
[43]
V., Zhou, D., and et al
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., and et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems , 35:24824--24837
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.