Recognition: unknown
Fine-Tuning Regimes Define Distinct Continual Learning Problems
Pith reviewed 2026-05-09 22:59 UTC · model grok-4.3
The pith
The relative ranking of continual learning methods is not preserved when the trainable depth of the fine-tuning regime changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
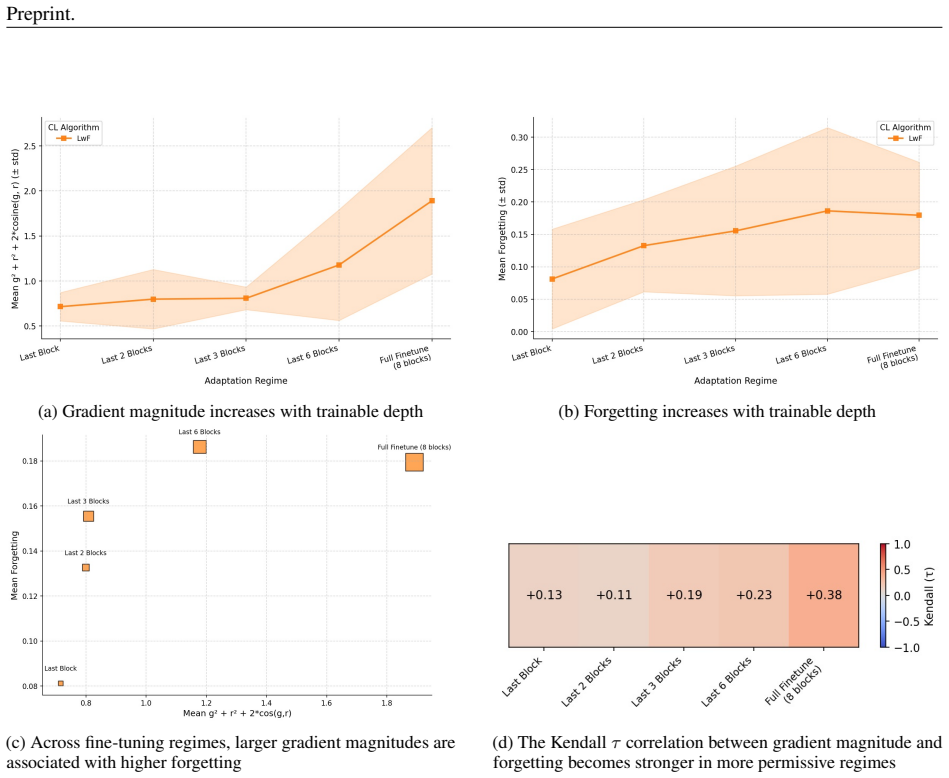
Adaptation regimes formalized as projected optimization over fixed trainable subspaces cause the relative ranking of methods to shift, as deeper regimes produce larger update magnitudes, higher forgetting rates, and a tighter link between the two.
What carries the argument
Projected optimization over fixed trainable subspaces, which changes the effective update signal for current-task fitting and knowledge preservation.
If this is right
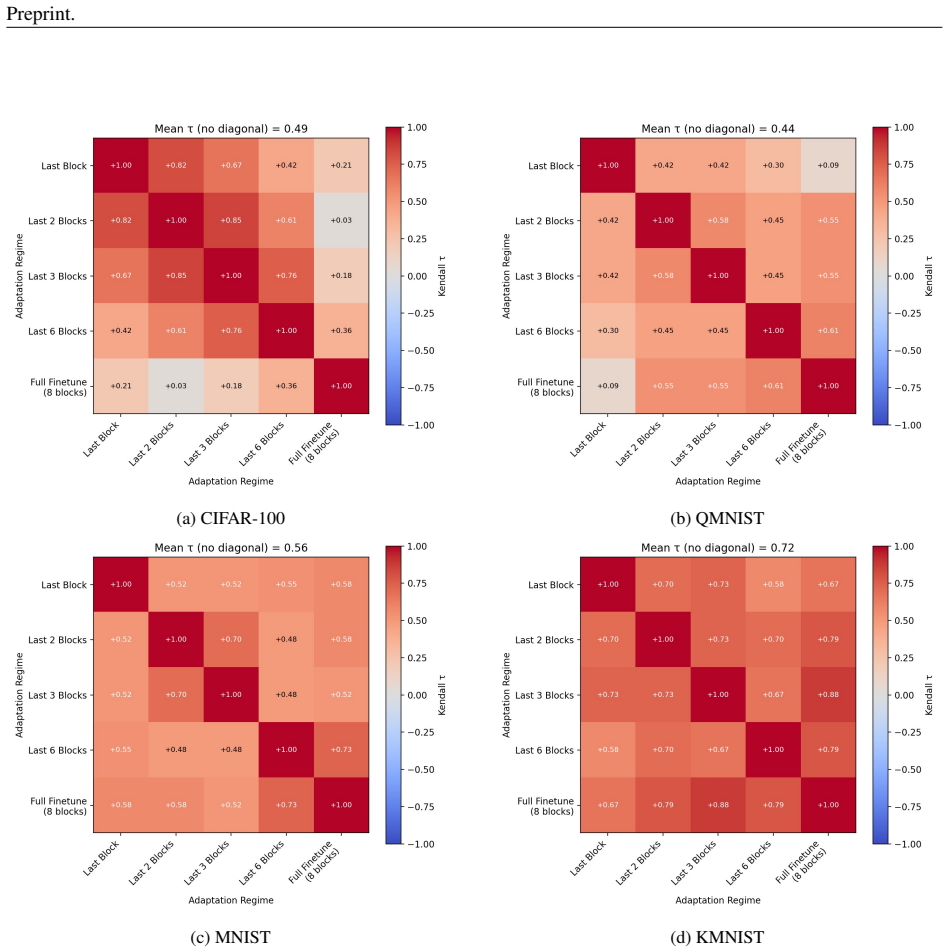
- Relative rankings of methods such as online EWC, LwF, SI, and GEM are not consistent across the five trainable depth regimes.
- Deeper regimes produce larger update magnitudes and higher forgetting.
- The correlation between update magnitude and forgetting strengthens in deeper regimes.
- Comparative conclusions about continual learning methods depend on the chosen fine-tuning regime.
Where Pith is reading between the lines
- Standard CL benchmarks may need to treat trainable depth as an explicit experimental factor rather than a fixed default.
- Method design could benefit from explicit robustness testing across multiple adaptation depths.
- The observed link between update size and forgetting in deeper regimes suggests potential for new regularization strategies tuned to regime depth.
Load-bearing premise
That differences in method rankings across regimes are driven by the choice of trainable depth rather than other unstated implementation details.
What would settle it
An experiment repeating the exact setup across the same five regimes where method rankings remain identical would falsify the central claim.
Figures

read the original abstract
Continual learning (CL) studies how models acquire tasks sequentially while retaining previously learned knowledge. Despite substantial progress in benchmarking CL methods, comparative evaluations typically keep the fine-tuning regime fixed. In this paper, we argue that the fine-tuning regime, defined by the trainable parameter subspace, is itself a key evaluation variable. We formalize adaptation regimes as projected optimization over fixed trainable subspaces, showing that changing the trainable depth alters the effective update signal through which both current task fitting and knowledge preservation operate. This analysis motivates the hypothesis that method comparisons need not be invariant across regimes. We test this hypothesis in task incremental CL, five trainable depth regimes, and four standard methods: online EWC, LwF, SI, and GEM. Across five benchmark datasets, namely MNIST, Fashion MNIST, KMNIST, QMNIST, and CIFAR-100, and across 11 task orders per dataset, we find that the relative ranking of methods is not consistently preserved across regimes. We further show that deeper adaptation regimes are associated with larger update magnitudes, higher forgetting, and a stronger relationship between the two. These results show that comparative conclusions in CL can depend strongly on the chosen fine-tuning regime, motivating regime-aware evaluation protocols that treat trainable depth as an explicit experimental factor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fine-tuning regimes in continual learning—defined by the trainable parameter subspace (specifically trainable depth)—constitute distinct problems. It formalizes regimes as projected optimization over fixed subspaces, which alters effective update signals for task fitting and knowledge retention. Empirically, across five datasets (MNIST, Fashion MNIST, KMNIST, QMNIST, CIFAR-100), 11 task orders per dataset, and five depth regimes, the relative rankings of online EWC, LwF, SI, and GEM are not preserved; deeper regimes also show larger update magnitudes, higher forgetting, and stronger correlation between them. This motivates regime-aware evaluation protocols.
Significance. If the central empirical pattern holds after controlling for confounds, the result is significant for the CL field: it challenges the implicit assumption that method comparisons are regime-invariant and shows that benchmark conclusions can depend on the chosen trainable subspace. The broad evaluation (five datasets, 11 orders) provides a reasonably strong empirical basis and gives credit to the authors for testing the hypothesis at scale rather than on a single benchmark. This could shift evaluation practices toward treating trainable depth as an explicit factor, affecting both method development and reproducibility.
major comments (2)
- Methods section: the central claim that ranking changes are driven by trainable depth regimes (rather than implementation artifacts) requires that hyperparameters (learning rates, regularization coefficients for the EWC penalty, LwF distillation loss, SI, and GEM) were either re-tuned per regime or explicitly held fixed with justification. The manuscript notes larger update magnitudes in deeper regimes; if hyperparameters were not adjusted, the observed ranking flips could arise from mismatched optimization strength rather than the projected subspace itself. An explicit statement or ablation on hyperparameter protocol is load-bearing for the hypothesis.
- §3 (formalization): while the projected-optimization view is a useful lens, the paper does not derive a quantitative prediction for how the projection operator changes the relative weighting of current-task loss versus preservation terms across methods. Without this or a controlled simulation isolating the projection effect, the link between the formalization and the empirical ranking changes remains interpretive rather than predictive.
minor comments (2)
- The five specific trainable depth regimes (e.g., which layers or parameter subsets are frozen) should be defined with a table or explicit list in the main text rather than deferred to the appendix, as this is central to reproducibility.
- Figure captions reporting method rankings should include the exact number of runs, error bars, and any statistical test used to support claims of 'not consistently preserved'.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of our experimental design and theoretical framing. We address each major comment below and have made revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Methods section: the central claim that ranking changes are driven by trainable depth regimes (rather than implementation artifacts) requires that hyperparameters (learning rates, regularization coefficients for the EWC penalty, LwF distillation loss, SI, and GEM) were either re-tuned per regime or explicitly held fixed with justification. The manuscript notes larger update magnitudes in deeper regimes; if hyperparameters were not adjusted, the observed ranking flips could arise from mismatched optimization strength rather than the projected subspace itself. An explicit statement or ablation on hyperparameter protocol is load-bearing for the hypothesis.
Authors: We held all hyperparameters fixed across regimes precisely to isolate the effect of the trainable subspace projection. Re-tuning per regime would have introduced an additional confounding variable, making it impossible to attribute performance differences to the regime itself rather than to optimization strength. This protocol is now stated explicitly in the Methods section with justification, including a note that the larger update magnitudes observed in deeper regimes are a direct consequence of the projection (more parameters receive the full gradient signal) rather than a hyperparameter mismatch. We also added a brief discussion acknowledging that regime-specific tuning could be studied separately but would address a different question. revision: yes
-
Referee: §3 (formalization): while the projected-optimization view is a useful lens, the paper does not derive a quantitative prediction for how the projection operator changes the relative weighting of current-task loss versus preservation terms across methods. Without this or a controlled simulation isolating the projection effect, the link between the formalization and the empirical ranking changes remains interpretive rather than predictive.
Authors: The formalization in §3 is intended as a mechanistic lens rather than a closed-form predictor; deriving a general quantitative mapping from projection to loss weighting would require strong assumptions on the Hessian and loss geometry that do not hold uniformly across methods and datasets. We have revised §3 to include an expanded discussion of the expected directional effects on current-task versus preservation gradients under projection, and we added a controlled toy simulation in the appendix that isolates the projection operator on a quadratic objective to illustrate the altered effective updates. The primary support for the hypothesis remains the large-scale empirical evaluation across five datasets and 11 orders, which directly tests whether rankings are preserved. revision: partial
Circularity Check
No circularity: empirical hypothesis test on standard methods
full rationale
The paper defines adaptation regimes via projected optimization over trainable subspaces and analytically notes that depth changes alter update magnitudes and forgetting. It then states a hypothesis that method rankings need not be invariant and tests this directly via controlled experiments on five datasets, eleven task orders, and four standard CL methods (online EWC, LwF, SI, GEM). No step reduces a claimed prediction or uniqueness result to a fitted quantity defined inside the paper; no self-citation chain is invoked to justify the central claim; and the reported outcome (inconsistent rankings) is an observed empirical pattern rather than a quantity forced by the formalization itself. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Projected optimization over fixed trainable subspaces accurately models the effect of changing trainable depth
Reference graph
Works this paper leans on
-
[2]
Critical learning periods in deep neural networks,
URLhttps://arxiv.org/abs/1711.08856. Magdalena Biesialska, Katarzyna Biesialska, and Marta R. Costa-jussà. Continual lifelong learning in natural language processing: A survey
-
[3]
Continual lifelong learning in natural language processing: A survey
URLhttps://arxiv.org/abs/2012.09823. Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Ales Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence,
-
[4]
URLhttps://doi.org/10.1109/TPAMI.2021.3057446. Itay Evron, E. Moroshko, G. Buzaglo, Maroun Khriesh, B. Marjieh, N. Srebro, and Daniel Soudry. Continual learning in linear classification on separable data. InInternational Conference on Machine Learning,
-
[5]
Sebastian Farquhar and Yarin Gal
URL https://arxiv.org/pdf/2306.03534.pdf. Sebastian Farquhar and Yarin Gal. Towards robust evaluations of continual learning
-
[6]
URL https://arxiv. org/abs/1805.09733. Ian J. Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio. An empirical investigation of catastrophic forgetting in gradient-based neural networks
-
[7]
Deep Residual Learning for Image Recognition
URL https://arxiv.org/abs/1512.03385. Yen-Chang Hsu, Yen-Yu Lin, Shih-Chieh Xu, Shao-Hua Sun, and Chu-Song Chen. Re-evaluating continual learning scenarios: A focus on class-incremental learning.arXiv preprint arXiv:1810.12488,
work page internal anchor Pith review arXiv
-
[8]
URL https://arxiv. org/abs/1810.12488. Maurice G. Kendall. A new measure of rank correlation.Biometrika, 30(1–2):81–93,
-
[9]
doi: 10.1093/biomet/30. 1-2.81. James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13):3521–3526,
-
[10]
doi: 10.1073/pnas.1611835114. URL https://doi.org/10.1073/pnas.1611835114. Tatsuya Konishi, M. Kurokawa, C. Ono, Zixuan Ke, Gyuhak Kim, and Bin Liu. Parameter-level soft-masking for continual learning.ArXiv, abs/2306.14775,
-
[11]
URLhttps://arxiv.org/abs/2202.10054. Zhizhong Li and Derek Hoiem. Learning without forgetting,
-
[12]
URL https://arxiv.org/abs/1606. 09282. Yan-Shuo Liang and Wu-Jun Li. Inflora: Interference-free low-rank adaptation for continual learning.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 23638–23647,
2024
-
[13]
URL https: //arxiv.org/abs/1706.08840. Michael McCloskey and Neal J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of Learning and Motivation, volume 24, pp. 109–165. Academic Press,
-
[14]
doi: 10.1016/S0079-7421(08)60536-8. URLhttps://doi.org/10.1016/S0079-7421(08)60536-8. German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Networks,
-
[15]
Real-time reinforcement learning by sequential actor-critics and experience replay
URL https://doi.org/10.1016/j.neunet. 2019.01.012. 10 Preprint. Maithra Raghu, Chiyuan Zhang, Jon Kleinberg, and Samy Bengio. Transfusion: Understanding transfer learning for medical imaging
-
[16]
arXiv preprint arXiv:1902.07208 , year=
URLhttps://arxiv.org/abs/1902.07208. Jonathan Schwarz, Wojciech M. Czarnecki, Jelena Luketina, A. Grabska-Barwinska, Y . Teh, Razvan Pascanu, and R. Hadsell. Progress & compress: A scalable framework for continual learning.ArXiv, abs/1805.06370,
-
[17]
URL https://api.semanticscholar.org/CorpusId:21718339. Tejas Srinivasan, Ting-Yun Chang, Leticia Pinto-Alva, Georgios Chochlakis, Mohammad Rostami, and Jesse Thomason. Climb: A continual learning benchmark for vision-and-language tasks.ArXiv, abs/2206.09059,
-
[18]
URL https://arxiv. org/abs/1904.07734. Mitchell Wortsman, Vivek Ramanujan, Rosanne Liu, Aniruddha Kembhavi, Mohammad Rastegari, Jason Yosinski, and Ali Farhadi. Supermasks in superposition. InAdvances in Neural Information Process- ing Systems, volume 33,
-
[19]
Maciej Wołczyk, Michał Zaj ˛ ac, Razvan Pascanu, Łukasz Kuci´nski, and Piotr Miło´s
URL https://proceedings.neurips.cc/paper/2020/hash/ ad1f8bb9b51f023cdc80cf94bb615aa9-Abstract.html. Maciej Wołczyk, Michał Zaj ˛ ac, Razvan Pascanu, Łukasz Kuci´nski, and Piotr Miło´s. Continual world: A robotic benchmark for continual reinforcement learning,
2020
-
[20]
Jaehong Yoon, Saehoon Kim, Eunho Yang, and Sung Ju Hwang
URLhttps://arxiv.org/abs/2105.10919. Jaehong Yoon, Saehoon Kim, Eunho Yang, and Sung Ju Hwang. Scalable and order-robust continual learning with additive parameter decomposition.arXiv: Learning,
- [21]
-
[22]
neurips.cc/paper/2014/hash/375c71349b295fbe2dcdca9206851369-Abstract.html
URL https://proceedings. neurips.cc/paper/2014/hash/375c71349b295fbe2dcdca9206851369-Abstract.html. Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence,
2014
-
[23]
URL https://arxiv.org/abs/1703.04200. 11 Preprint. APPENDIX A ADDITIONALTHEORETICALDETAILS For completeness, we restate the progress bound used in the main text. Progress bound under projected updates.Let θ+ =θ−ηP S∇Jt(θ),(8) where PS is the orthogonal projector associated with the fixed trainable subset S. Assume that Jt is L-smooth on a neighborhood con...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.