Recognition: unknown
Generating Synthetic Malware Samples Using Generative AI
Pith reviewed 2026-05-09 21:45 UTC · model grok-4.3
The pith
Diffusion-based synthetic malware samples improve classification of minor classes by up to 60 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Decomposing malware binaries into mnemonic opcode sequences allows natural language processing to extract contextual meaning from malware features. Generative models including GANs and a modified diffusion model are then trained on these sequences to produce synthetic samples. Augmenting the imbalanced training dataset with these synthetics, especially from the diffusion model, significantly boosts classification performance for minor classes by up to 60% on average and achieves an overall accuracy of 96%, representing an 8% improvement.
What carries the argument
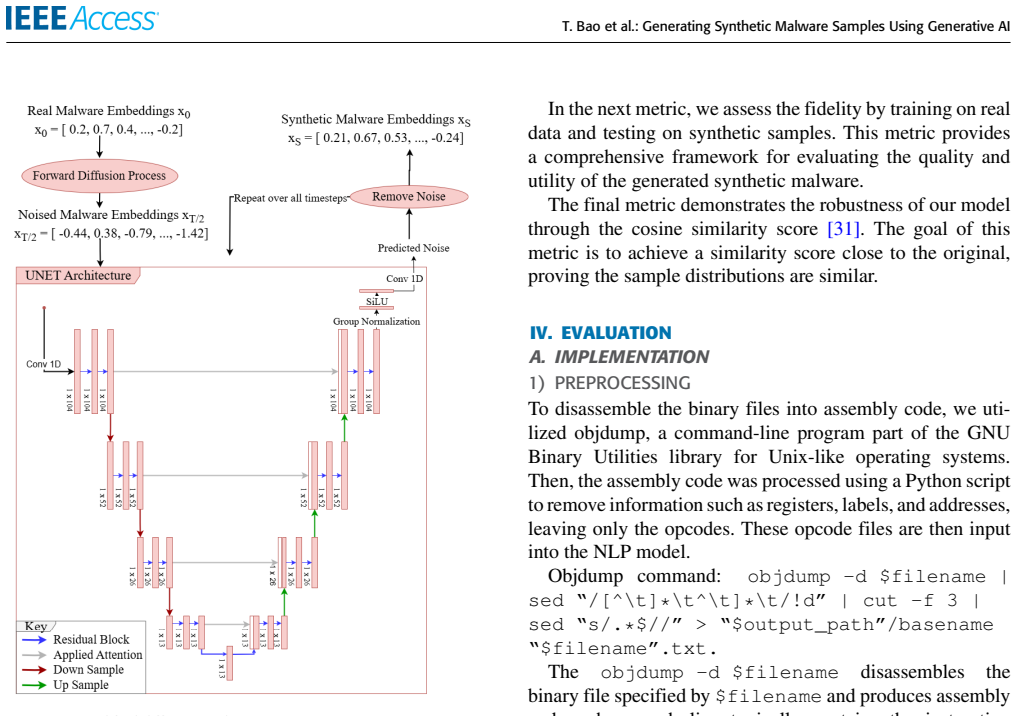
Modified diffusion model generating synthetic mnemonic opcode sequences from malware binaries after NLP-based feature extraction for data augmentation in classification tasks.
Load-bearing premise
The synthetic opcode sequences generated by the models are distributionally similar to real malware opcodes and help the classifier generalize rather than overfit to artificial patterns.
What would settle it
If a classifier trained on the augmented dataset shows no improvement in accuracy when tested exclusively on newly collected, previously unseen real malware samples from rare families.
Figures






read the original abstract
Malware attacks have a significant negative impact on organizations of varied scales in the field of cybersecurity. Recently, malware researchers have increasingly turned to machine learning techniques to combat sophisticated obfuscation methods used in malware. However, collecting a diverse set of malware samples with various obfuscation techniques is challenging and often takes years, especially for newly developed malware. This issue is further compounded by a well-known limitation of machine learning models: their poor performance when training data is scarce. In this paper, we propose a new system for generating synthetic malware samples to augment imbalanced malware dataset. Our approach decomposes malware binary samples into mnemonic opcode sequences, leveraging natural language processing to extract contextual meaning behind malware opcode features to aid the learning of generative AI (GenAI) employed in this paper, Generative Adversarial Networks (GAN), Wasserstein Generative Adversarial Networks with Gradient Penalty (WGAN-GP), and a modified Diffusion model. The experiment results show that augmenting training data with Diffusion-based synthetic data significantly improves classification performance for minor classes by up to 60% on average. This enhancement ultimately leads to an overall malware classification performance of 96%, an 8% improvement. These findings demonstrate the high quality and fidelity of the synthetic data, its robustness, and its potential applications in malware analysis. Specifically, synthetic malware data proves effective in improving the classification of minor malware classes and detection rates, even though the size of known malware data is significantly small.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes decomposing malware binaries into mnemonic opcode sequences, applying NLP techniques for contextual feature extraction, and training GAN, WGAN-GP, and a modified diffusion model to generate synthetic samples for augmenting imbalanced malware datasets. The central empirical claim is that diffusion-based augmentation improves classification performance for minor classes by up to 60% on average, yielding 96% overall accuracy (an 8% gain) and demonstrating the high quality and fidelity of the synthetic data.
Significance. If the synthetic opcode sequences prove distributionally faithful to real malware and the reported gains hold under rigorous held-out evaluation with proper baselines, the approach could help mitigate data scarcity and class imbalance in ML-based malware detection. The comparison across multiple generative models is a strength, but the current evidence rests entirely on downstream classifier performance without independent fidelity checks.
major comments (3)
- Abstract: The reported improvements (60% average lift on minor classes, 96% overall accuracy, 8% gain) provide no information on baseline classifier performance, the cross-validation or train/test split strategy, or confirmation that the test set consists exclusively of held-out real malware samples. These details are load-bearing for interpreting whether the gains reflect improved generalization rather than evaluation artifacts.
- Experimental Results: Performance lift after augmentation is presented as evidence of synthetic data fidelity, yet no direct quantitative diagnostics are reported (e.g., n-gram KL divergence, embedding-space MMD, or accuracy of a real-vs-synthetic sequence discriminator). This leaves open the possibility that the classifier exploits repetitive patterns or generative artifacts correlated with minority labels in the particular split.
- Methodology: The modifications to the diffusion model, the precise tokenization and embedding procedure for opcode sequences, and the architecture of the downstream classifier are described at a high level only. No ablation studies isolate the contribution of each generative approach or validate that synthetic samples do not systematically differ from real malware in ways that affect generalization.
minor comments (3)
- Define 'minor classes' quantitatively (e.g., by sample count threshold) and report per-class metrics such as F1-score or precision-recall curves rather than aggregate accuracy alone.
- Include a limitations section discussing potential failure modes, such as mode collapse in the generative models or sensitivity to opcode extraction choices.
- Add citations to prior work on opcode-sequence malware classification and sequence generative models to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We have addressed each of the major comments point by point and made revisions to the paper to enhance the clarity and completeness of the experimental details and methodology.
read point-by-point responses
-
Referee: Abstract: The reported improvements (60% average lift on minor classes, 96% overall accuracy, 8% gain) provide no information on baseline classifier performance, the cross-validation or train/test split strategy, or confirmation that the test set consists exclusively of held-out real malware samples. These details are load-bearing for interpreting whether the gains reflect improved generalization rather than evaluation artifacts.
Authors: We agree that the abstract would benefit from additional context on the experimental protocol. We have revised the abstract to include references to the baseline performance, the train/test split and cross-validation strategy, and confirmation that the test set uses only held-out real malware samples. A more detailed description of the evaluation setup has also been added to the Experiments section of the revised manuscript. revision: yes
-
Referee: Experimental Results: Performance lift after augmentation is presented as evidence of synthetic data fidelity, yet no direct quantitative diagnostics are reported (e.g., n-gram KL divergence, embedding-space MMD, or accuracy of a real-vs-synthetic sequence discriminator). This leaves open the possibility that the classifier exploits repetitive patterns or generative artifacts correlated with minority labels in the particular split.
Authors: The referee is correct that downstream classification performance is an indirect indicator of synthetic data quality. To strengthen the manuscript, we have added direct fidelity metrics in the revised version, including n-gram KL divergence, embedding space MMD, and the accuracy of a discriminator trained to distinguish real from synthetic opcode sequences. These additions provide independent validation of the synthetic data's fidelity and help mitigate concerns about potential artifacts. revision: yes
-
Referee: Methodology: The modifications to the diffusion model, the precise tokenization and embedding procedure for opcode sequences, and the architecture of the downstream classifier are described at a high level only. No ablation studies isolate the contribution of each generative approach or validate that synthetic samples do not systematically differ from real malware in ways that affect generalization.
Authors: We acknowledge that the original descriptions were high-level and that ablation studies would be valuable. In the revised manuscript, we have provided more detailed descriptions of the tokenization and embedding process, the specific modifications made to the diffusion model, and the architecture of the downstream classifier. We have also included ablation studies comparing the different generative models (GAN, WGAN-GP, and diffusion) and additional experiments to verify that the synthetic samples do not introduce systematic differences that could impact generalization. revision: yes
Circularity Check
No significant circularity; empirical augmentation gains are externally measured
full rationale
The paper trains GAN/WGAN-GP and diffusion models on real opcode sequences extracted from malware binaries, generates synthetic sequences, augments the training set, and reports classifier accuracy on held-out real test malware. The 60% minor-class and 8% overall gains are downstream empirical outcomes of this pipeline rather than re-expressions of the generator's fitted parameters or training distribution by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to force the result; the fidelity claim rests on the observed accuracy lift, which could have failed if the synthetics were unrealistic. This is a standard data-augmentation experiment whose success is falsifiable against external test data.
Axiom & Free-Parameter Ledger
free parameters (1)
- GAN/WGAN-GP/Diffusion hyperparameters
axioms (2)
- domain assumption Opcode sequences extracted from binaries are sufficient to represent the behavioral semantics needed for both generation and downstream classification.
- ad hoc to paper Synthetic samples drawn from the learned distribution do not systematically differ from real malware in ways that would degrade classifier generalization.
Reference graph
Works this paper leans on
-
[1]
Accessed: Aug
What is Malware?-Definition and Examples. Accessed: Aug. 14,
-
[2]
Available: https://www.cisco.com/site/us/en/learn/topics/ security/what-is-malware.html
[Online]. Available: https://www.cisco.com/site/us/en/learn/topics/ security/what-is-malware.html
-
[3]
Idika and A
N. Idika and A. Mathur, ‘‘A survey of malware detection techniques,’’ Purdue Univ., West Lafayette, IN, USA, Tech. Rep., 2007
2007
- [4]
-
[5]
Number of Malware Attacks Per Year 2023
(2023). Number of Malware Attacks Per Year 2023. [Online]. Available: https://www.statista.com/statistics/873097/malware-attacks-per-year- worldwide/
2023
-
[6]
K. Radhakrishnan, R. R. Menon, and H. V . Nath, ‘‘A survey of zero- day malware attacks and its detection methodology,’’ in Proc. IEEE Region 10 Conf. (TENCON), Oct. 2019, pp. 533–539. [Online]. Available: https://ieeexplore.ieee.org/document/8929620/?arnumber=8929620
- [7]
-
[8]
A. S. Kale, V . Pandya, F. Di Troia, and M. Stamp, ‘‘Malware classification with Word2 V ec, HMM2 V ec, BERT, and ELMo,’’ J. Comput. Virol. Hacking Techn., vol. 19, no. 1, pp. 1–16, Apr. 2022, doi: 10.1007/s11416- 022-00424-3
-
[9]
Q. D. Tran and F. D. Troia, ‘‘Word embeddings for fake malware generation,’’ inProc. Silicon V alley Cybersecur . Conf., Cham, Switzerland, L. Bathen, G. Saldamli, X. Sun, T. H. Austin, and A. J. Nelson, Eds., Springer, Aug. 2022, pp. 22–37
2022
-
[10]
Trehan and F
H. Trehan and F. D. Troia, ‘‘Fake malware generation using HMM and GAN,’’ in Proc. Silicon V alley Cybersecur . Conf., S.-Y . Chang, L. Bathen, F. Di Troia, T. H. Austin, and A. J. Nelson, Eds., Jan. 2022, pp. 3–21
2022
-
[11]
Dhanasekar, F
D. Dhanasekar, F. Di Troia, K. Potika, and M. Stamp, ‘‘Detecting encrypted and polymorphic malware using hidden Markov models: An artificial intelligence approach,’’ in Guide to Vulnerability Analysis for Computer Networks and Systems. Cham, Switzerland: Springer, 2018, pp. 281–299. VOLUME 13, 2025 59735 T. Bao et al.: Generating Synthetic Malware Samples...
2018
-
[12]
W. S. McCulloch and W. Pitts, ‘‘A logical calculus of the ideas immanent in nervous activity,’’ Bull. Math. Biophys., vol. 5, no. 4, pp. 115–133, Dec. 1943, doi: 10.1007/bf02478259
-
[13]
Jain, ‘‘Image-based malware classification with convolutional neu- ral networks and extreme learning machines,’’ Master’s Projects, San Jose, CA, USA, Tech
M. Jain, ‘‘Image-based malware classification with convolutional neu- ral networks and extreme learning machines,’’ Master’s Projects, San Jose, CA, USA, Tech. Rep. 900, 2019. [Online]. Available: https://scholarworks.sjsu.edu/etd/900
2019
-
[14]
R. Pascanu, J. W. Stokes, H. Sanossian, M. Marinescu, and A. Thomas, ‘‘Malware classification with recurrent networks,’’ in Proc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), Apr. 2015, pp. 1916–1920. [Online]. Available: https://ieeexplore. ieee.org/document/7178304/?arnumber=7178304
-
[15]
Alazab, S
M. Alazab, S. V enkataraman, and P . Watters, ‘‘Towards understanding malware behaviour by the extraction of API calls,’’ in Proc. 2nd Cybercrime Trustworthy Comput. Workshop, Jul. 2010, pp. 52–59
2010
-
[16]
R. Mehta, O. Jureč ková, and M. Stamp, ‘‘A natural language processing approach to malware classification,’’ J. Comput. Virol. Hacking Techn., vol. 20, no. 1, pp. 173–184, Oct. 2023, doi: 10.1007/s11416-023- 00506-w
-
[17]
M. Mimura and R. Ito, ‘‘Applying NLP techniques to malware detection in a practical environment,’’ Int. J. Inf. Secur ., vol. 21, no. 2, pp. 279–291, Apr. 2022, doi: 10.1007/s10207-021-00553-8
-
[18]
P . N. Y eboah and H. B. Baz Musah, ‘‘NLP technique for malware detection using 1D CNN fusion model,’’ Secur . Commun. Netw., vol. 2022, pp. 1–9, Jun. 2022. [Online]. Available: https://onlinelibrary.wiley.com/doi/abs/10.1155/2022/2957203
- [19]
-
[20]
A. Choi, A. Giang, S. Jumani, D. Luong, and F. Di Troia, ‘‘Synthetic malware using deep variational autoencoders and generative adversarial networks,’’ EAI Endorsed Trans. Internet Things, vol. 10, p. 1, Jul. 2024. [Online]. Available: https://publications. eai.eu/index.php/IoT/article/view/6566
2024
-
[21]
What does bert look at? an analysis of bert’s attention
K. Clark, U. Khandelwal, O. Levy, and C. D. Manning, ‘‘What does BERT look at? An analysis of BERT’s attention,’’ 2019, arXiv:1906.04341
-
[22]
Efficient Estimation of Word Representations in Vector Space
T. Mikolov, K. Chen, G. Corrado, and J. Dean, ‘‘Efficient estimation of word representations in vector space,’’ 2013, arXiv:1301.3781
work page internal anchor Pith review arXiv 2013
-
[23]
L. Breiman, ‘‘Random Forests,’’ Mach. Learn., vol. 45, no. 1, pp. 5–32, Oct. 2001, doi: 10.1023/A:1010933404324
-
[24]
C. Cortes and V . V apnik, ‘‘Support-vector networks,’’ Mach. Learn., vol. 20, no. 3, pp. 273–297, Sep. 1995, doi: 10.1007/bf00994018
-
[25]
A. Nappa, M. Z. Rafique, and J. Caballero, ‘‘The MALICIA dataset: Identification and analysis of drive-by download operations,’’ Int. J. Inf. Secur ., vol. 14, no. 1, pp. 15–33, Feb. 2015, doi: 10.1007/s10207-014- 0248-7
-
[26]
Accessed: Aug
VirusShare. Accessed: Aug. 14, 2024. [Online]. Available: https://www.virusshare.com/
2024
-
[27]
Generative adversarial networks,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, ‘‘Generative adversarial networks,’’ Commun. ACM, vol. 63, no. 11, pp. 139–144, Oct. 2020. [Online]. Available: https://dl.acm.org/doi/10.1145/3422622
-
[28]
Gulrajani, F
I. Gulrajani, F. Ahmed, M. Arjovsky, V . Dumoulin, and A. Courville, ‘‘Improved training of Wasserstein GANs,’’ in Proc. Adv. Neural Inf. Process. Syst., vol. 30, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., Dec. 2017, pp. 5769–5779. [Online]. Available: https://proceedings.neurips.cc/paper/paper/2017/...
2017
-
[29]
J. Ho, A. Jain, and P . Abbeel, ‘‘Denoising diffusion probabilistic models,’’ 2020, arXiv:2006.11239
work page internal anchor Pith review arXiv 2020
-
[30]
van der Maaten and G
L. van der Maaten and G. Hinton, ‘‘Visualizing data using t-SNE,’’ J. Mach. Learn. Res., vol. 9, pp. 2579–2605, Nov. 2008
2008
-
[31]
J. Sharma. (2023). Frechet Inception Distance (FID) for Evaluating GANs. [Online]. Available: https://medium.com/@jkumarsharma998/frechet- inception-distance-fid-for-evaluating-gans-7bb953ca2ed4
2023
-
[32]
A. R. Lahitani, A. E. Permanasari, and N. A. Setiawan, ‘‘Cosine similarity to determine similarity measure: Study case in online essay assessment,’’ in Proc. 4th Int. Conf. Cyber IT Service Manage., Apr. 2016, pp. 1–6. TIFFANY BAO is currently pursuing the bache- lor’s degree in mathematics and computer science with Boston University. Her research interes...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.