Recognition: unknown
JetSCI: A Hybrid JAX-PETSc Framework for Scalable Differentiable Simulation
Pith reviewed 2026-05-08 12:41 UTC · model grok-4.3
The pith
JetSCI merges JAX and PETSc to deliver scalable differentiable finite element simulations that outperform pure JAX code on heterogeneous micromechanics problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
JetSCI uses JAX for GPU-parallel differentiable discretizations of the governing equations and PETSc for the robust, scalable solution of the resulting linear and nonlinear systems on distributed-memory hardware, thereby unifying automatic differentiability with mature HPC capabilities for micromechanics problems.
What carries the argument
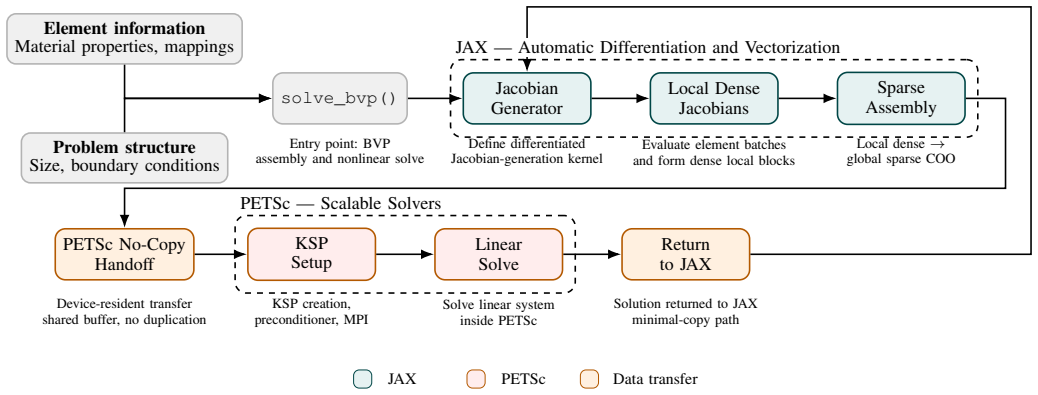
The JAX-PETSc interface that routes differentiable finite-element operators from JAX into PETSc's solvers while preserving end-to-end automatic differentiation and adding multilevel (GPU + MPI) parallelism.
If this is right
- Differentiable surrogate models and data-driven constitutive laws can now be trained inside large-scale, distributed finite-element workflows.
- Multilevel parallelism becomes available without rewriting existing JAX discretization code.
- Preconditioning and nonlinear solver strategies from PETSc become directly usable inside gradient-based optimization loops.
Where Pith is reading between the lines
- The same hybrid pattern could extend to other physics domains that combine local GPU kernels with global distributed solves, such as incompressible flow or structural dynamics.
- Users could embed learned constitutive relations directly into existing PETSc-based production codes with minimal additional coding.
- Performance gains may grow with problem size, suggesting JetSCI becomes more advantageous precisely when JAX-only codes hit memory or solver limits.
Load-bearing premise
The interface between JAX and PETSc preserves full automatic differentiability, scalability, and compatibility without introducing significant overhead for the targeted finite-element micromechanics discretizations.
What would settle it
Run the same heterogeneous micromechanics finite-element problem at increasing mesh sizes on a multi-node cluster; if JetSCI does not show lower wall-clock time or higher solution accuracy than an equivalent JAX-only implementation once the problem exceeds single-node memory, the performance claim does not hold.
Figures






read the original abstract
The rapid rise of scientific machine learning (SciML) has expanded the role of differentiable modeling, surrogate modeling, and data-driven constitutive laws in large-scale simulation. The JAX framework provides an attractive environment for these workflows through automatically differentiable programs, vectorization, GPU acceleration, and while enabling seamless learning of surrogate models. However, large-scale simulation still relies on mature HPC infrastructure. Libraries, such as PETSc, provide scalable MPI-based parallelism, robust linear and nonlinear solvers, and advanced preconditioning capabilities that remain difficult to reproduce in JAX-only workflows. We present JetSCI, a hybrid JAX-PETSc framework that unifies these complementary strengths. JetSCI uses JAX for GPU-parallel differentiable discretizations and PETSc for robust, scalable solution of the resulting systems on distributed-memory architectures, exposing multilevel parallelism through GPU acceleration within nodes and MPI parallelism across nodes. For finite element discretizations of heterogeneous micromechanics problems, JetSCI outperforms JAX-only implementations in efficiency and accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JetSCI, a hybrid JAX-PETSc framework that assigns GPU-parallel differentiable finite-element discretizations to JAX and scalable distributed linear/nonlinear solves to PETSc, claiming that the resulting multilevel parallelism yields better efficiency and accuracy than pure-JAX implementations for heterogeneous micromechanics problems.
Significance. If the hybrid coupling can be shown to preserve end-to-end automatic differentiability while delivering measurable gains in wall-clock time, memory, and solution accuracy on distributed architectures, the work would provide a practical bridge between the differentiable-programming ecosystem and mature HPC libraries, enabling larger-scale SciML workflows in micromechanics and related fields.
major comments (3)
- [Abstract] Abstract: the central claim that JetSCI 'outperforms JAX-only implementations in efficiency and accuracy' for finite-element discretizations of heterogeneous micromechanics problems is stated without any accompanying benchmarks, timing tables, error metrics, strong-scaling curves, or memory profiles; this absence leaves the empirical superiority unsupported.
- [Abstract / Introduction] The description of automatic differentiation through the PETSc solve step is absent; no custom vjp rules, adjoint formulations, checkpointing strategy, or data-movement overhead analysis between JAX arrays and PETSc distributed vectors is supplied, which is load-bearing for the claim that full differentiability is retained with negligible cost.
- [Abstract] No concrete implementation details or performance data are given for the multilevel parallelism (GPU within nodes + MPI across nodes) on the targeted heterogeneous micromechanics discretizations, preventing assessment of whether the hybrid interface actually reduces overhead relative to a pure JAX or pure PETSc baseline.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point-by-point below. Where the presentation in the abstract or introduction can be strengthened by referencing or summarizing material already present in the body of the manuscript, we have revised accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that JetSCI 'outperforms JAX-only implementations in efficiency and accuracy' for finite-element discretizations of heterogeneous micromechanics problems is stated without any accompanying benchmarks, timing tables, error metrics, strong-scaling curves, or memory profiles; this absence leaves the empirical superiority unsupported.
Authors: We agree that the abstract would be strengthened by a brief reference to the supporting results. The full manuscript contains the requested benchmarks, timing tables, error metrics, strong-scaling curves, and memory profiles in Section 4. We have revised the abstract to include a concise summary of the key empirical gains (e.g., wall-clock time reductions and accuracy improvements on the heterogeneous micromechanics test cases) while retaining the abstract's brevity. This change directly supports the central claim without altering the manuscript's technical content. revision: yes
-
Referee: [Abstract / Introduction] The description of automatic differentiation through the PETSc solve step is absent; no custom vjp rules, adjoint formulations, checkpointing strategy, or data-movement overhead analysis between JAX arrays and PETSc distributed vectors is supplied, which is load-bearing for the claim that full differentiability is retained with negligible cost.
Authors: The mechanism for automatic differentiation through the PETSc solve is described in Section 3.2, including the custom VJP rules, the adjoint formulation, checkpointing strategy, and analysis of JAX-PETSc data movement overhead. We acknowledge that a high-level statement of this capability is missing from the abstract and introduction. We have added one sentence to the abstract and a short paragraph to the introduction that summarizes how end-to-end differentiability is preserved at negligible cost. These revisions make the differentiability claim explicit at the front of the paper while pointing readers to the detailed implementation. revision: yes
-
Referee: [Abstract] No concrete implementation details or performance data are given for the multilevel parallelism (GPU within nodes + MPI across nodes) on the targeted heterogeneous micromechanics discretizations, preventing assessment of whether the hybrid interface actually reduces overhead relative to a pure JAX or pure PETSc baseline.
Authors: Section 3.1 details the multilevel parallelism strategy (JAX for intra-node GPU discretizations and PETSc for inter-node MPI solves), and Section 4 provides the corresponding performance data and overhead comparisons against pure-JAX and pure-PETSc baselines on the heterogeneous micromechanics problems. We have revised the abstract to include a brief mention of the hybrid parallelization approach and the observed overhead reductions, with explicit references to Sections 3 and 4 for the concrete implementation and quantitative results. revision: yes
Circularity Check
No circularity: empirical framework description with benchmarking claims
full rationale
The paper introduces JetSCI as a hybrid JAX-PETSc implementation for differentiable FE simulations and supports its central claim (outperformance vs. JAX-only on heterogeneous micromechanics problems) via direct empirical comparison of efficiency and accuracy. No derivation chain, fitted parameters renamed as predictions, self-definitional equations, or load-bearing self-citations appear. The hybrid interface and differentiability assertions are engineering statements whose validity rests on implementation details and benchmarks rather than reducing to the inputs by construction. This is the expected non-finding for a software-framework paper.
Axiom & Free-Parameter Ledger
axioms (3)
- standard math JAX provides reliable automatic differentiation and GPU vectorization for discretizations.
- standard math PETSc supplies robust, scalable MPI solvers and preconditioners for distributed-memory systems.
- domain assumption Finite-element discretizations are appropriate for heterogeneous micromechanics problems.
Reference graph
Works this paper leans on
-
[1]
Boehmet al., Nature Reviews Physics 10.1038/s42254-021- 00417-4 (2022)
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang, “Physics-informed machine learning,”Nature Reviews Physics, vol. 3, no. 6, pp. 422–440, 2021, https://doi.org/10.1038/s42254-021- 00314-5
-
[2]
Operator learning: A statistical perspective,
U. Subedi and A. Tewari, “Operator learning: A statistical perspective,” Annual Review of Statistics and Its Application, vol. 13, pp. 123–148, 2026, https://doi.org/10.1146/annurev-statistics-042424-070908
-
[3]
Deep learning in computational mechanics: a review,
L. Herrmann and S. Kollmannsberger, “Deep learning in computational mechanics: a review,”Computational Mechanics, vol. 74, pp. 281–331, 2024, https://doi.org/10.1007/s00466-023-02434-4
-
[4]
J. N. Fuhg, G. Anantha Padmanabha, N. Bouklas, B. Bahmani, W. Sun, N. N. Vlassis, M. Flaschel, P. Carrara, and L. De Lorenzis, “A review on data-driven constitutive laws for solids,”Archives of Computa- tional Methods in Engineering, vol. 32, no. 3, pp. 1841–1883, 2025, https://doi.org/10.1007/s11831-024-10196-2
-
[5]
K. Upadhyay, J. N. Fuhg, N. Bouklas, and K. T. Ramesh, “Physics- informed data-driven discovery of constitutive models with applica- tion to strain-rate-sensitive soft materials,”Computational Mechanics, vol. 74, pp. 1–30, 2024, https://doi.org/10.1007/s00466-024-02497-x
-
[6]
C. R. Harris, K. J. Millman, S. J. van der Walt, R. Gommers, P. Virtanen, D. Cournapeau, E. Wieser, J. Taylor, S. Berg, N. J. Smith, R. Kern, M. Picus, S. Hoyer, M. H. van Kerkwijk, M. Brett, A. Haldane, J. F. del R ´ıo, M. Wiebe, P. Peterson, P. G ´erard-Marchant, K. Sheppard, T. Reddy, W. Weckesser, H. Abbasi, C. Gohlke, and T. E. Oliphant, “Array progr...
-
[7]
P. Virtanen, R. Gommers, T. E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright, S. J. van der Walt, M. Brett, J. Wilson, K. J. Millman, N. Mayorov, A. R. J. Nelson, E. Jones, R. Kern, E. Larson, C. J. Carey,˙I. Polat, Y . Feng, E. W. Moore, J. VanderPlas, D. Laxalde, J. Perktold, R. Cimrman, I. Henrik- se...
-
[8]
JAX: composable transformations of Python+NumPy programs,
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, and S. Wanderman-Milne, “JAX: composable transformations of Python+NumPy programs,” 2018. [Online]. Available: https://github.com/jax-ml/jax
2018
-
[9]
T. Xue, S. Liao, Z. Gan, C. Park, X. Xie, W. K. Liu, and J. Cao, “JAX-FEM: A differentiable gpu-accelerated 3d finite ele- ment solver for automatic inverse design and mechanistic data sci- ence,”Computer Physics Communications, vol. 291, p. 108802, 2023, https://doi.org/10.1016/j.cpc.2023.108802
-
[10]
Efficient management of parallelism in object oriented numerical software li- braries,
S. Balay, W. D. Gropp, L. C. McInnes, and B. F. Smith, “Efficient management of parallelism in object oriented numerical software li- braries,” inModern Software Tools in Scientific Computing, E. Arge, A. M. Bruaset, and H. P. Langtangen, Eds. Boston, MA: Birkh ¨auser, 1997, pp. 163–202
1997
-
[11]
S. Balay, S. Abhyankar, M. F. Adams, S. Benson, J. Brown, P. Brune, K. Buschelman, E. M. Constantinescu, L. Dalcin, A. Dener, V . Ei- jkhout, J. Faibussowitsch, W. D. Gropp, V . Hapla, T. Isaac, P. Jo- livet, D. Karpeev, D. Kaushik, M. G. Knepley, F. Kong, S. Kruger, D. A. May, L. C. McInnes, R. T. Mills, L. Mitchell, T. Munson, J. E. Roman, K. Rupp, P. S...
-
[12]
PETSc Web page,
S. Balay, S. Abhyankar, M. F. Adams, J. Brown, P. Brune, K. Buschelman, L. Dalcin, V . Eijkhout, W. D. Gropp, D. Kaushik, M. G. Knepley, L. C. McInnes, K. Rupp, B. F. Smith, S. Zampini, and H. Zhang, “PETSc Web page,” http://www.mcs.anl.gov/petsc, 2015. [Online]. Available: http://www.mcs.anl.gov/petsc
2015
-
[13]
ChatGPT (GPT-5.3),
OpenAI, “ChatGPT (GPT-5.3),” https://chat.openai.com/, 2026, used for grammar correction assistance
2026
-
[14]
G. Wu, “Jax-sso: Differentiable finite element analysis solver for structural optimization and seamless integration with neural networks,”arXiv preprint arXiv:2407.20026, 2024, https://doi.org/10.48550/arXiv.2407.20026
-
[15]
Adcme: Learning spatially-varying physical fields using deep neural networks,
K. Xu and E. Darve, “Adcme: Learning spatially-varying physical fields using deep neural networks,”arXiv preprint arXiv:2011.11955, 2020, https://doi.org/10.48550/arXiv.2011.11955
-
[16]
D. A. Ham, P. H. J. Kelly, L. Mitchell, C. J. Cotter, R. C. Kirby, K. Sagiyama, N. Bouziani, S. V orderwuelbecke, T. J. Gregory, J. Bet- teridge, D. R. Shapero, R. W. Nixon-Hill, C. J. Ward, P. E. Farrell, P. D. Brubeck, I. Marsden, T. H. Gibson, M. Homolya, T. Sun, A. T. T. McRae, F. Luporini, A. Gregory, M. Lange, S. W. Funke, F. Rathgeber, G.-T. Bercea...
-
[17]
DOLFINx: the next generation FEniCS problem solving environment,
I. A. Baratta, J. P. Dean, J. S. Dokken, M. Habera, J. S. Hale, C. N. Richardson, M. E. Rognes, M. W. Scroggs, N. Sime, and G. N. Wells, “DOLFINx: the next generation FEniCS problem solving environment,” preprint, 2023
2023
-
[18]
dolfin-adjoint 2018.1: au- tomated adjoints for fenics and firedrake,
S. K. Mitusch, S. W. Funke, and J. S. Dokken, “dolfin-adjoint 2018.1: au- tomated adjoints for fenics and firedrake,”Journal of Open Source Soft- ware, vol. 4, no. 38, p. 1292, 2019, https://doi.org/10.21105/joss.01292
-
[19]
Physics-driven machine learning models coupling pytorch and firedrake,
N. Bouziani and D. A. Ham, “Physics-driven machine learning models coupling pytorch and firedrake,”arXiv preprint arXiv:2303.06871, 2023, https://doi.org/10.48550/arXiv.2303.06871
-
[20]
Differentiable program- ming across the pde and machine learning barrier,
N. Bouziani, D. A. Ham, and A. Farsi, “Differentiable program- ming across the pde and machine learning barrier,”arXiv preprint arXiv:2409.06085, 2024, https://doi.org/10.48550/arXiv.2409.06085
-
[21]
Formopt: A fenicsx toolbox for level set-based shape optimization supporting parallel computing,
J. D. D ´ıaz-Avalos and A. Laurain, “Formopt: A fenicsx toolbox for level set-based shape optimization supporting parallel computing,”arXiv preprint arXiv:2601.05709, 2026, https://doi.org/10.48550/arXiv.2601.05709
-
[22]
Instead of rewriting foreign code for machine learning, automatically synthesize fast gradients,
W. S. Moses and V . Churavy, “Instead of rewriting foreign code for machine learning, automatically synthesize fast gradients,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 12 472–12 485. [Online]. Available: https://dl.acm.org/doi/abs/10.5555/ 3495724.3496770
-
[23]
Reverse-mode automatic differentiation and optimization of gpu kernels via enzyme,
W. S. Moses, V . Churavy, L. Paehler, J. H ¨uckelheim, S. H. K. Narayanan, M. Schanen, and J. Doerfert, “Reverse-mode automatic differentiation and optimization of gpu kernels via enzyme,” inSC ’21: Proceedings of the International Conference for High Perfor- mance Computing, Networking, Storage and Analysis, 2021, pp. 1–18, https://doi.org/10.1145/345881...
-
[24]
Neutrino Production via $e^-e^+$ Collision at $Z$-boson Peak
W. S. Moses, S. H. K. Narayanan, L. Paehler, V . Churavy, M. Schanen, J. H ¨uckelheim, J. Doerfert, and P. Hovland, “Scalable automatic differ- entiation of multiple parallel paradigms through compiler augmentation,” inSC ’22: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2022, pp. 1–18, http...
-
[25]
Scalable analysis and design using automatic differentiation,
J. Andrej, T. Kolev, and B. S. Lazarov, “Scalable analysis and design using automatic differentiation,”arXiv preprint arXiv:2506.00746, 2025, https://doi.org/10.48550/arXiv.2506.00746
-
[26]
The deal.ii finite element library: Design, features, and insights,
D. Arndt, W. Bangerth, D. Davydov, T. Heister, L. Heltai, M. Kro- nbichler, M. Maier, J.-P. Pelteret, B. Turcksin, and D. Wells, “The deal.ii finite element library: Design, features, and insights,”Comput- ers & Mathematics with Applications, vol. 81, pp. 407–422, 2021, https://doi.org/10.1016/j.camwa.2020.02.022
-
[27]
Algorithm 755: Adol-c: a package for the automatic differentiation of algorithms written in c/c++,
A. Griewank, D. Juedes, and J. Utke, “Algorithm 755: Adol-c: a package for the automatic differentiation of algorithms written in c/c++,”ACM Transactions on Mathematical Software, vol. 22, no. 2, pp. 131–167, 1996, https://doi.org/10.1145/229473.229474
-
[28]
Automatic differentiation of c++ codes on emerging many-core architectures with sacado,
E. T. Phipps, R. P. Pawlowski, A. G. Salinger, R. A. Bartlett, D. M. Gay, and . Kokkos, “Automatic differentiation of c++ codes on emerging many-core architectures with sacado,”ACM Transactions on Mathemat- ical Software, 2022, https://doi.org/10.1145/3560262
-
[29]
4.0 MOOSE: Enabling massively parallel multiphysics simulation,
L. Harbour, G. Giudicelli, A. D. Lindsay, P. German, J. Hansel, C. Icenhour, M. Li, J. M. Miller, R. H. Stogner, P. Behne, D. Yankura, Z. M. Prince, C. DeChant, D. Schwen, B. W. Spencer, M. Tano, N. Choi, Y . Wang, M. Nezdyur, Y . Miao, T. Hu, S. Kumar, C. Matthews, B. Langley, N. Nobre, A. Blair, C. MacMackin, H. B. Rocha, E. Palmer, J. Carter, J. Meier,...
-
[30]
Automatic differentiation in metaphysicl and its applications in moose,
A. Lindsay, R. Stogner, D. Gaston, D. Schwen, C. Matthews, W. Jiang, L. K. Aagesen, R. Carlsen, F. Kong, A. Slaugh- teret al., “Automatic differentiation in metaphysicl and its applications in moose,”Nuclear Technology, pp. 1–18, 2021, https://doi.org/10.1080/00295450.2020.1838877
-
[31]
P. C. Africa, “lifex: A flexible, high performance library for the numer- ical solution of complex finite element problems,”SoftwareX, vol. 20, p. 101252, 2022, https://doi.org/10.1016/j.softx.2022.101252
-
[32]
High-performance derivative computations using codipack,
M. Sagebaum, T. Albring, and N. R. Gauger, “High-performance derivative computations using codipack,”ACM Transactions on Mathematical Software, vol. 45, no. 4, pp. 1–26, 2019, https://doi.org/10.1145/3356900
-
[33]
Jaxbind: Bind any function to jax,
J. Rothet al., “Jaxbind: Bind any function to jax,”arXiv preprint arXiv:2403.08847, 2024
-
[34]
Parallel distributed computing using python,
L. D. Dalcin, R. R. Paz, P. A. Kler, and A. Cosimo, “Parallel distributed computing using python,”Advances in Water Resources, vol. 34, no. 9, pp. 1124–1139, 2011, new Computational Methods and Software Tools. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S0309170811000777
2011
-
[35]
fea-in-jax,
K. Ballard, “fea-in-jax,” 2024, finite element method implementation in JAX; accessed 2026-04-07. [Online]. Available: https://github.com/ KeithBallard/fea-in-jax
2024
-
[36]
Jax documentation,
JAX authors, “Jax documentation,” 2026, accessed 2026-04-07. [Online]. Available: https://docs.jax.dev/en/latest/quickstart.html
2026
-
[37]
The influence of microstructure randomness on prediction of fiber properties in compos- ites,
M. K. Ballard, W. R. McLendon, and J. D. Whitcomb, “The influence of microstructure randomness on prediction of fiber properties in compos- ites,”Journal of Composite Materials, vol. 48, no. 29, pp. 3605–3620, 2014, https://doi.org/10.1177/0021998313511654
-
[38]
Prediction of tow ar- chitecture and stress distributions for a 3d woven composite,
M. K. Ballard and J. D. Whitcomb, “Prediction of tow ar- chitecture and stress distributions for a 3d woven composite,” inProceedings of the 32nd ASC Technical Conference, 2017, https://doi.org/10.12783/asc2017/15402
-
[39]
Outgassing Environment of Spacecraft: An Overview
Ballard, M. Keith and Whitcomb, John D., “Stress analysis of 3d textile composites using high performance computing: new insights and challenges,”IOP Conference Series: Materials Science and Engi- neering, vol. 406, no. 1, p. 012004, 2018, https://doi.org/10.1088/1757- 899X/406/1/012004
-
[40]
PETSc overview,
“PETSc overview,” https://petsc.org/release/overview/, 2026, accessed 2026-04-07
2026
-
[41]
petsc4py: Petsc for python,
L. Dalcin, “petsc4py: Petsc for python,” 2026, accessed 2026-04-07. [Online]. Available: https://petsc.org/release/petsc4py/
2026
-
[42]
petsc4py documentation,
Dalcin, Lisandro, “petsc4py documentation,” 2026, accessed 2026- 04-07. [Online]. Available: https://petsc.org/release/petsc4py/reference/ petsc4py.html
2026
-
[43]
Advances in Water Resources , volume =
L. D. Dalcin, R. R. Paz, and M. Storti, “Parallel distributed computing using python,”Advances in Water Resources, vol. 34, no. 9, pp. 1124– 1139, 2011, https://doi.org/10.1016/j.advwatres.2011.04.013
-
[44]
mpi4py: Status update after 12 years of development,
L. Dalcin and Y .-L. L. Fang, “mpi4py: Status update after 12 years of development,”Computing in Science & Engineering, vol. 23, no. 4, pp. 47–54, 2021, https://doi.org/10.1109/MCSE.2021.3083216
-
[45]
Mpi for python documentation,
L. Dalcin, “Mpi for python documentation,” 2025, accessed 2026-04-07. [Online]. Available: https://mpi4py.readthedocs.io/
2025
-
[46]
CuPy: A NumPy-compatible library for NVIDIA GPU calculations,
R. Okuta, Y . Unno, D. Nishino, S. Hido, and C. Loomis, “CuPy: A NumPy-compatible library for NVIDIA GPU calculations,” in Proceedings of Workshop on Machine Learning Systems (LearningSys) in The Thirty-First Annual Conference on Neural Information Processing Systems (NIPS), 2017. [Online]. Available: http://learningsys.org/nips17/ assets/papers/paper 16.pdf
2017
-
[47]
Cupy documentation,
CuPy developers, “Cupy documentation,” 2026, accessed 2026-04-07. [Online]. Available: https://docs.cupy.dev/en/stable/overview.html
2026
-
[48]
Python specification for dlpack,
Data APIs Consortium and DLPack contributors, “Python specification for dlpack,” 2026, accessed 2026-04-07. [Online]. Available: https: //dmlc.github.io/dlpack/latest/python spec.html
2026
-
[49]
Dlpack: Open in-memory tensor structure,
DLPack contributors, “Dlpack: Open in-memory tensor structure,” 2026, accessed 2026-04-07. [Online]. Available: https://github.com/ dmlc/dlpack
2026
-
[50]
[Online]
Python Software Foundation,ctypes — A foreign function library for Python, Python Software Foundation, 2026, accessed 2026-04-07. [Online]. Available: https://docs.python.org/3/library/ctypes.html
2026
-
[51]
A supernodal approach to sparse partial pivoting,
J. W. Demmel, S. C. Eisenstat, J. R. Gilbert, X. S. Li, and J. W. H. Liu, “A supernodal approach to sparse partial pivoting,”SIAM Journal on Matrix Analysis and Applications, vol. 20, no. 3, pp. 720–755, 1999, https://doi.org/10.1137/S0895479895291765
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.