Recognition: unknown
How LLMs Detect and Correct Their Own Errors: The Role of Internal Confidence Signals
Pith reviewed 2026-05-08 12:26 UTC · model grok-4.3
The pith
Large language models use an internal post-answer signal to detect their errors and decide which ones they can fix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
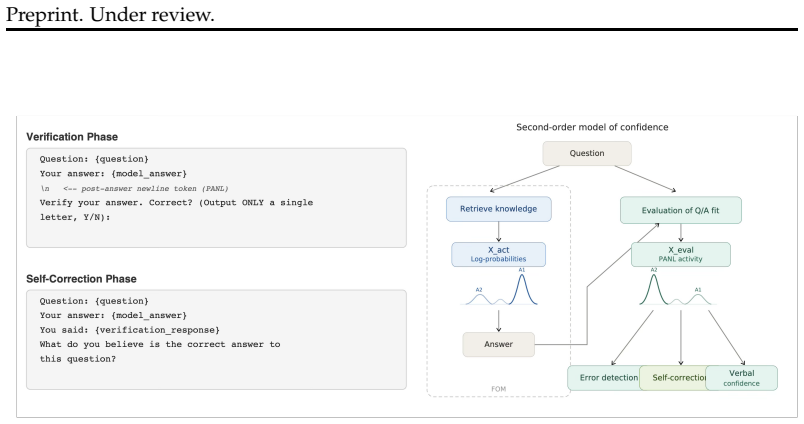
LLMs cache a confidence representation at the post-answer newline token that causally supports error detection and self-correction, implementing a second-order architecture whose internal signal encodes both whether an answer is likely wrong and whether the model possesses the knowledge needed to repair it.
What carries the argument
The PANL activation at the token immediately following the answer, which serves as a partially independent evaluative signal that can diverge from the generated response.
If this is right
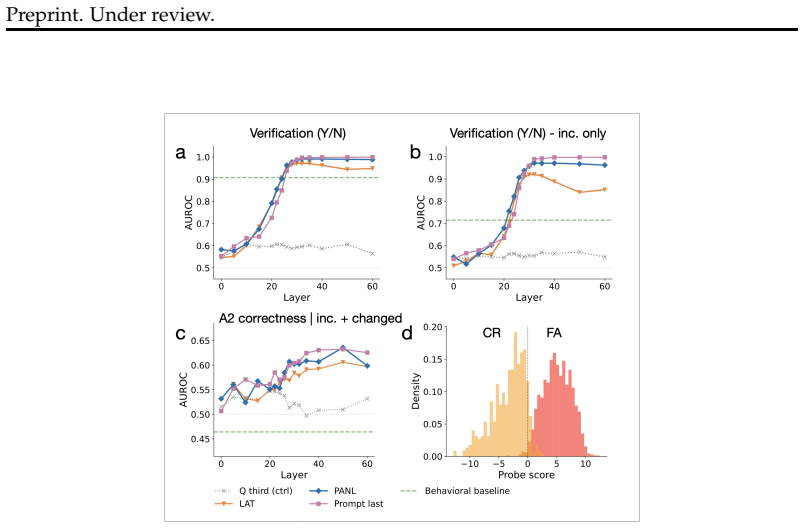
- Verbal confidence predicts error detection beyond what token log-probabilities alone can explain.
- PANL activations add predictive power for error detection even after accounting for verbal confidence.
- PANL activations identify which errors the model can correct when all behavioral measures fail.
- Causal disruption of PANL signals impairs error detection even when answer information remains available.
Where Pith is reading between the lines
- This internal signal could be monitored or amplified during generation to improve reliability without extra training.
- The same second-order structure may appear in other sequence models and could be tested by measuring activations after key decision tokens.
- If the signal reflects accessible knowledge, targeted fine-tuning on self-correction examples might strengthen it directly.
Load-bearing premise
The PANL signal acts as a partially independent evaluative mechanism that causally enables error detection and self-correction rather than arising only as a side effect of generating the answer.
What would settle it
An intervention that selectively disrupts PANL activations while leaving answer generation intact would eliminate the model's ability to detect and correct its errors.
Figures



read the original abstract
Large language models can detect their own errors and sometimes correct them without external feedback, but the underlying mechanisms remain unknown. We investigate this through the lens of second-order models of confidence from decision neuroscience. In a first-order system, confidence derives from the generation signal itself and is therefore maximal for the chosen response, precluding error detection. Second-order models posit a partially independent evaluative signal that can disagree with the committed response, providing the basis for error detection. Kumaran et al. (2026) showed that LLMs cache a confidence representation at a token immediately following the answer (i.e. post-answer newline: PANL) -- that causally drives verbal confidence and dissociates from log-probabilities. Here we test whether this PANL signal extends beyond confidence to support error detection and self-correction. Here we test whether this signal supports error detection and self-correction, deriving predictions from the second-order framework. Using a verify-then-correct paradigm, we show that: (i) verbal confidence predicts error detection far beyond token log-probabilities, ruling out a first-order account; (ii) PANL activations predict error detection beyond verbal confidence itself; and (iii) PANL predicts which errors the model can correct -- where all behavioural signals fail. Causal interventions confirm that PANL signals rescue error detection behavior when answer information is corrupted. All findings replicate across models (Gemma 3 27B and Qwen 2.5 7B) and tasks (TriviaQA and MNLI). These results reveal that LLMs naturally implement a second-order confidence architecture whose internal evaluative signal encodes not only whether an answer is likely wrong but whether the model has the knowledge to fix it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates mechanisms of error detection and self-correction in LLMs through the lens of second-order confidence models from decision neuroscience. Building on prior work identifying a post-answer newline (PANL) activation as a cached confidence signal, the authors test whether this signal supports error detection and correction in a verify-then-correct paradigm. Key findings include: verbal confidence and PANL activations predict error detection beyond token log-probabilities; PANL predicts which errors are correctable where behavioral signals fail; and causal interventions on PANL rescue detection behavior under answer-token corruption. Results replicate across Gemma 3 27B and Qwen 2.5 7B on TriviaQA and MNLI.
Significance. If the central claims are substantiated, the work would offer mechanistic evidence that LLMs implement a second-order confidence architecture, with PANL serving as an evaluative signal that encodes both error likelihood and correctability. The replications across two models and two tasks, combined with causal interventions, provide a stronger empirical foundation than purely correlational analyses. These elements are strengths that elevate the potential contribution to understanding LLM metacognition.
major comments (2)
- [Methods (causal interventions)] Methods (causal interventions subsection): The manuscript does not specify the exact intervention technique (e.g., activation patching coordinates, magnitude of perturbation, or controls for attention-pattern leakage) used to manipulate PANL while corrupting answer tokens. This detail is load-bearing for the claim that PANL functions as a partially independent evaluative signal rather than modulating the same generation pathways, as any non-orthogonal effect would undermine the rescue-effect interpretation.
- [Results (prediction and replication analyses)] Results (prediction and replication analyses): No details are provided on data exclusion criteria, handling of multiple comparisons, or exact statistical models (including effect sizes and confidence intervals) for the claims that PANL predicts correctability beyond verbal confidence and log-probabilities. These omissions are load-bearing because the central distinction from first-order accounts rests on the incremental predictive power reported across replications.
minor comments (2)
- [Abstract] Abstract: The sentence 'Here we test whether this PANL signal extends beyond confidence to support error detection and self-correction' is immediately repeated in slightly altered form, which reduces clarity.
- [Introduction] Introduction: The citation to Kumaran et al. (2026) for the original PANL finding should include a brief parenthetical note on how the current experiments extend that prior result to avoid any appearance of circularity in the framing.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript to incorporate the requested clarifications on methods and statistical reporting.
read point-by-point responses
-
Referee: Methods (causal interventions subsection): The manuscript does not specify the exact intervention technique (e.g., activation patching coordinates, magnitude of perturbation, or controls for attention-pattern leakage) used to manipulate PANL while corrupting answer tokens. This detail is load-bearing for the claim that PANL functions as a partially independent evaluative signal rather than modulating the same generation pathways, as any non-orthogonal effect would undermine the rescue-effect interpretation.
Authors: We agree that these methodological specifics are necessary to substantiate the independence of the PANL signal. In the revised manuscript, we have added a dedicated paragraph in the causal interventions subsection detailing: the activation patching coordinates (specific layer index and PANL token position identified via prior localization), the perturbation magnitude (multiplicative scaling of the activation vector toward a neutral baseline computed from correct trials), and controls for attention-pattern leakage (verified by comparing attention maps pre- and post-intervention, confirming no spillover to answer-token positions). These additions directly support the interpretation that the rescue effect arises from the evaluative rather than generative pathway. revision: yes
-
Referee: Results (prediction and replication analyses): No details are provided on data exclusion criteria, handling of multiple comparisons, or exact statistical models (including effect sizes and confidence intervals) for the claims that PANL predicts correctability beyond verbal confidence and log-probabilities. These omissions are load-bearing because the central distinction from first-order accounts rests on the incremental predictive power reported across replications.
Authors: We acknowledge these omissions and have expanded the results section accordingly. The revised manuscript now specifies: data exclusion criteria (removal of trials with no generated answer, missing confidence ratings, or duplicate responses, resulting in <5% exclusion per dataset); multiple-comparison correction (Bonferroni adjustment across the four primary prediction models); and exact statistical models (hierarchical logistic regressions predicting error detection and correctability, with incremental PANL effects tested via likelihood-ratio tests against baseline models containing only verbal confidence and log-probabilities). We report standardized coefficients, 95% confidence intervals, and Nagelkerke R^{2} changes for both models and tasks, confirming the incremental predictive power. revision: yes
Circularity Check
Self-citation on PANL underpins second-order architecture claim
specific steps
-
self citation load bearing
[Abstract]
"Kumaran et al. (2026) showed that LLMs cache a confidence representation at a token immediately following the answer (i.e. post-answer newline: PANL) -- that causally drives verbal confidence and dissociates from log-probabilities. Here we test whether this PANL signal extends beyond confidence to support error detection and self-correction, deriving predictions from the second-order framework."
The central premise that PANL functions as a partially independent evaluative signal (able to disagree with the committed response and support error detection/correction even under corruption) is justified only by the authors' own prior citation. The current claims about LLMs implementing a second-order architecture, plus the interpretation of verbal confidence and intervention results, build directly on this self-cited foundation rather than re-deriving or externally validating the signal's independence.
full rationale
The paper's derivation begins with second-order confidence models from decision neuroscience and applies them to LLMs by positing PANL as the key partially independent evaluative signal. This PANL status and its causal dissociation from first-order generation signals is established solely via citation to the authors' prior work (Kumaran et al. 2026). New experiments then test extensions to error detection and self-correction, including causal interventions. While these tests add independent empirical content and replications across models/tasks, the load-bearing premise that PANL provides an orthogonal second-order channel (rather than a byproduct) reduces to the self-cited result without an external benchmark or parameter-free derivation in the present manuscript. This qualifies as self-citation load-bearing (pattern 3) but does not collapse the full result to a tautology, as the verify-then-correct paradigm and intervention outcomes remain falsifiable. No self-definitional, fitted-prediction, or ansatz-smuggling patterns appear.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Second-order models of confidence from decision neuroscience apply to transformer-based LLMs
invented entities (1)
-
PANL as partially independent evaluative signal
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Hypothesis generation and updating in large language models
LLMs exhibit Bayesian-like hypothesis updating with strong-sampling bias and an evaluation-generation gap but generalize poorly outside observed data.
Reference graph
Works this paper leans on
-
[1]
Varun Chandola, Arindam Banerjee, and Vipin Kumar
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying.arXiv preprint arXiv:2304.13734,
-
[2]
The validation gap: A mechanistic analysis of how language models compute arithmetic but fail to validate it
Leonardo Bertolazzi, Philipp Mondorf, Barbara Plank, and Raffaella Bernardi. The validation gap: A mechanistic analysis of how language models compute arithmetic but fail to validate it. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 29375–29412,
2025
-
[3]
arXiv preprint arXiv:2212.03827 , year =
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision.arXiv preprint arXiv:2212.03827,
-
[4]
Jiefeng Chen, Jie Ren, Xinyun Chen, Chengrun Yang, Ruoxi Sun, Jinsung Yoon, and Sercan¨O Arık. Sets: Leveraging self-verification and self-correction for improved test-time scaling. arXiv preprint arXiv:2501.19306,
-
[5]
Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars
Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, and Noah D. Good- man. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective STaRs.arXiv:2503.01307,
-
[6]
arXiv preprint arXiv:2311.08298 , year=
Jiahui Geng, Fengyu Cai, Yuxia Wang, Heinz Koeppl, Preslav Nakov, and Iryna Gurevych. A survey of language model confidence estimation and calibration.arXiv preprint arXiv:2311.08298,
-
[7]
How to use and interpret activation patching.arXiv preprint arXiv:2404.15255,
Stefan Heimersheim and Neel Nanda. How to use and interpret activation patching.arXiv preprint arXiv:2404.15255,
-
[8]
Steering Evaluation-Aware Language Models to Act Like They Are Deployed
Tim Tian Hua, Andrew Qin, Samuel Marks, and Neel Nanda. Steering evaluation-aware language models to act like they are deployed.arXiv preprint arXiv:2510.20487,
-
[9]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension.arXiv preprint arXiv:1705.03551,
work page internal anchor Pith review arXiv
-
[10]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review arXiv
-
[11]
How do llms compute verbal confidence.arXiv preprint arXiv:2603.17839, 2026
Dharshan Kumaran, Arthur Conmy, Federico Barbero, Simon Osindero, Viorica Patraucean, and Petar Veli ˇckovi´c. How do LLMs compute verbal confidence?arXiv preprint arXiv:2603.17839,
-
[12]
arXiv preprint arXiv:2402.12563 , year=
Loka Li, Zhenhao Chen, Guangyi Chen, Yixuan Zhang, Yusheng Su, Eric Xing, and Kun Zhang. Confidence matters: Revisiting intrinsic self-correction capabilities of large language models.arXiv preprint arXiv:2402.12563,
-
[13]
Large language models have intrinsic self-correction ability.arXiv preprint arXiv:2406.15673,
Dancheng Liu, Amir Nassereldine, Ziming Yang, Chenhui Xu, Yuting Hu, Jiajie Li, Utkarsh Kumar, Changjae Lee, Ruiyang Qin, Yiyu Shi, et al. Large language models have intrinsic self-correction ability.arXiv preprint arXiv:2406.15673,
-
[14]
arXiv preprint arXiv:2510.04013 , year=
Jiarui Liu, Jivitesh Jain, Mona Diab, and Nishant Subramani. Llm microscope: What model internals reveal about answer correctness and context utilization.arXiv preprint arXiv:2510.04013,
-
[15]
Yi-Long Lu, Jiajun Song, and Wei Wang. A unified representation underlying the judgment of large language models.arXiv preprint arXiv:2510.27328,
-
[16]
doi:10.48550/arXiv.2410.02707 , abstract =
Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. Llms know more than they show: On the intrinsic representation of llm hallucinations.arXiv preprint arXiv:2410.02707,
-
[17]
Steering Llama 2 via Contrastive Activation Addition
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexan- der Matt Turner. Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681,
work page internal anchor Pith review arXiv
-
[18]
Mark Steyvers, Heliodoro Tejeda, Aakriti Kumar, Catarina Bel´em, Sheer Karny, Xinyue Hu, Lukas W
doi: 10.1038/212438a0. Mark Steyvers, Heliodoro Tejeda, Aakriti Kumar, Catarina Bel´em, Sheer Karny, Xinyue Hu, Lukas W. Mayer, and Padhraic Smyth. What large language models know and what people think they know.Nature Machine Intelligence, 7:221–231,
-
[19]
Alessandro Stolfo, Vidhisha Balachandran, Safoora Yousefi, Eric Horvitz, and Besmira Nushi. Improving instruction-following in language models through activation steering. arXiv preprint arXiv:2410.12877,
-
[20]
12 Preprint. Under review. Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram ´e, Morgane Rivi `ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review arXiv
-
[21]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. arXiv preprint arXiv:2305.14975,
-
[22]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering. arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review arXiv
-
[23]
Base models know how to reason, thinking models learn when.arXiv preprint arXiv:2510.07364,
Constantin Venhoff, Iv´an Arcuschin, Philip Torr, Arthur Conmy, and Neel Nanda. Base models know how to reason, thinking models learn when.arXiv preprint arXiv:2510.07364,
-
[24]
Reasoning-finetuning repurposes latent representations in base models.arXiv:2507.12638,
Jake Ward, Chuqiao Lin, Constantin Venhoff, and Neel Nanda. Reasoning-finetuning repurposes latent representations in base models.arXiv:2507.12638,
-
[25]
Large language models are better reasoners with self-verification
Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, and Jun Zhao. Large language models are better reasoners with self-verification. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 2550–2575,
2023
-
[26]
A broad-coverage challenge corpus for sentence understanding through inference
Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 1112–1122,
2018
-
[27]
Xiaohu Xie, Xiaohu Liu, and Benjamin Yao. Know when you’re wrong: Aligning confidence with correctness for LLM error detection.arXiv preprint arXiv:2603.06604,
-
[28]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. arXiv preprint arXiv:2306.13063,
work page internal anchor Pith review arXiv
-
[29]
Xiao-Wen Yang, Xiao-Yu Zhu, Wei-Da Wei, De-Chuan Zhang, Jian-Jun Shao, Zhi Zhou, Lan-Zhe Guo, and Yu-Feng Li. Step back to leap forward: Self-backtracking for boosting reasoning of language models.arXiv:2502.04404, 2025a. Zhe Yang, Yichang Zhang, Yudong Wang, Ziyao Xu, Junyang Lin, and Zhifang Sui. Confi- dence vs critique: A decomposition of self-correct...
-
[30]
doi: 10.1037/0033-295X.111.4.931. Dongryeol Yoon, Seongyun Kim, Sukyung Yang, Seongjin Kim, Yireun Kim, Eunji Kim, Eunsol Choi, Yohan Kim, and Minjoon Seo. Reasoning models better express their confidence.arXiv preprint arXiv:2505.14489,
-
[31]
Fred Zhang and Neel Nanda. Towards best practices of activation patching in language models: Metrics and methods.arXiv preprint arXiv:2309.16042,
-
[32]
No chance
as our primary dataset, a factual question- answering benchmark requiring retrieval of real-world knowledge. After deduplication, our TriviaQA sample comprises 7,227 questions for Gemma and 3,500 for Qwen. We additionally test on the Multi-Genre Natural Language Inference (MNLI) dataset (Williams et al., 2018), a three-way classification task (entailment,...
2018
-
[33]
(2024); Chen et al
iteratively refines the output of the model until verified as correct, showing improvement, as do Liu et al. (2024); Chen et al. (2025). Self-Enhanced Test-Time Scaling (SETS; Chen et al
2024
-
[34]
consistency heads
combines parallel sampling with iterative self-verification and self-correction using a single LLM to show increased performance in reasoning tasks. Weng et al. (2023) show that self-verification of reasoning enhances performance. Self- verification is a diagnostic step where the model judges whether a proposed solution satisfies the task constraints, pro...
2023
-
[35]
the candidate’s answer
Correction= A2 correct among trials where the model changed the candidate’s answer. A1 correctness is excluded from all analyses as it is constant within each foil condition (always incorrect). The likelihood-ratio test assesses whether PANL adds to the combined behavioural model. Individual Target ConditionnConf Verif LD Behav PANL Behav + PANL LRχ 2 p V...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.