Recognition: unknown
SpikingBrain2.0: Brain-Inspired Foundation Models for Efficient Long-Context and Cross-Platform Inference
Pith reviewed 2026-05-08 12:14 UTC · model grok-4.3
The pith
A hybrid sparse attention and spiking quantization design lets a 5B model recover most base transformer performance while delivering 10x faster long-context inference and neuromorphic hardware gains after under 7k GPU hours of conversion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpB2.0 is a 5B-parameter model built on Dual-Space Sparse Attention, an inter-layer mix of sparse softmax attention and sparse linear attention, together with dual quantization paths that support both INT8 event-driven spiking computation and FP8 GPU acceleration. An optimized Transformer-to-Hybrid conversion pipeline applied to a Qwen3-4B base model, using only curated open-source data and under 7k A100 GPU hours, recovers most of the original capability for both language and vision-language variants. The resulting model achieves a 10.13 times speedup in time-to-first-token at 4 million context length, supports more than 10 million tokens on eight A100 GPUs under vLLM where full-attention 4
What carries the argument
Dual-Space Sparse Attention (DSSA) is the central mechanism: an inter-layer hybrid of Sparse Softmax Attention and Sparse Linear Attention that improves the performance-efficiency trade-off for long sequences while enabling the dual quantization paths.
If this is right
- Context lengths exceeding 10 million tokens become feasible on eight A100 GPUs under vLLM where full-attention models run out of memory.
- Time-to-first-token improves by a factor of 10.13 at 4 million context length.
- Neuromorphic hardware at 500 MHz gains 70.6 percent area reduction and 46.5 percent power reduction from the 64.31 percent sparsity.
- Both language-only and vision-language models can follow the same dual-path conversion and retain most base performance with low additional compute.
Where Pith is reading between the lines
- The same hybrid attention and conversion approach could be tested on larger base models to see whether the efficiency gains scale without proportional increases in training cost.
- The spiking quantization path suggests potential for lower-power deployment on edge devices that support event-driven computation.
- Cross-platform results imply that existing transformer checkpoints can be adapted for mixed GPU and neuromorphic environments with modest effort.
- If the sparsity and recovery hold, energy use for long-context serving in data centers could decrease substantially.
Load-bearing premise
The transformer-to-hybrid conversion pipeline with curated open-source data recovers nearly all base-model capability without hidden losses on tasks or data distributions outside the reported evaluations.
What would settle it
A clear drop below the claimed recovery level on standard long-context or multimodal benchmarks, or on tasks outside the training distribution, when compared directly to the unmodified Qwen3-4B base model would show the conversion does not preserve capabilities as stated.
Figures

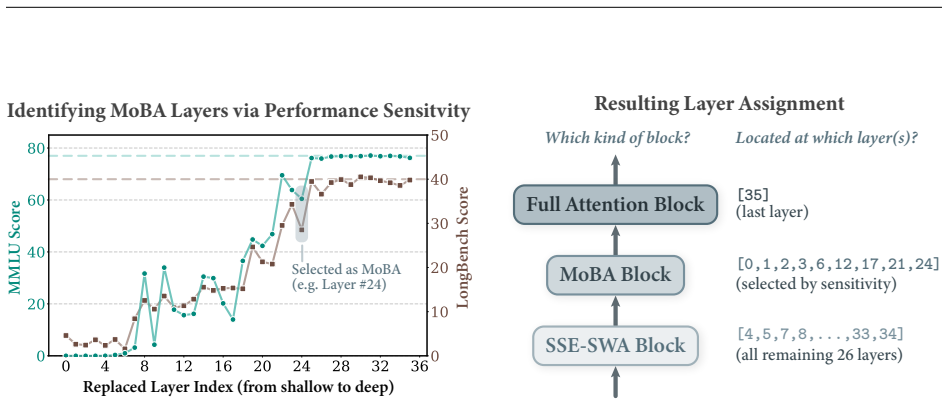
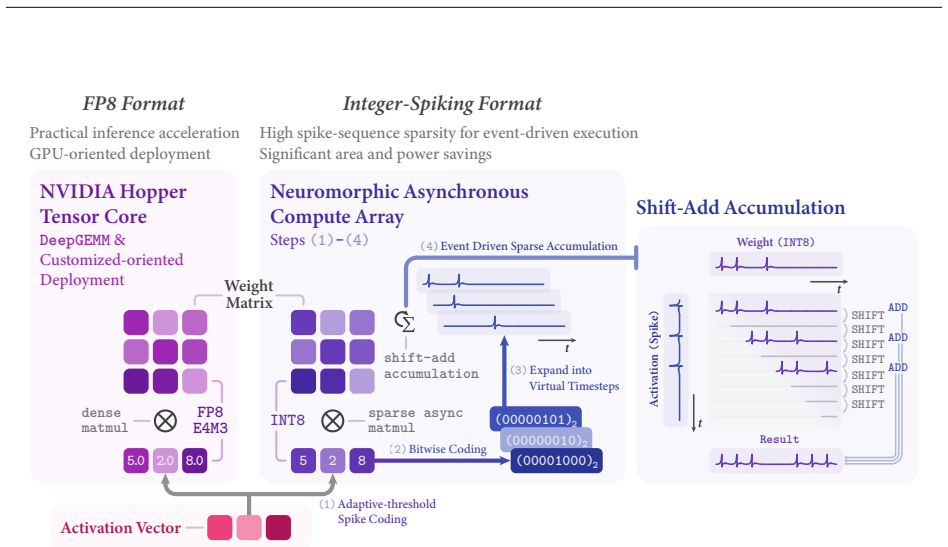


read the original abstract
Scaling context length is reshaping large-model development, yet full-attention Transformers suffer from prohibitive computation and inference bottlenecks at long sequences. A key challenge is to design foundation models that maintain performance and long-context efficiency with minimal training overhead. We introduce SpikingBrain2.0 (SpB2.0), a 5B model that advances both architecture and training efficiency of its predecessor. Our contributions are two-fold. (1) Architectural Innovation: We propose Dual-Space Sparse Attention (DSSA), an inter-layer hybrid of Sparse Softmax Attention (MoBA) and Sparse Linear Attention (SSE), achieving an improved performance-efficiency trade-off for long-context modeling. SpB2.0 further supports dual quantization paths: INT8-Spiking coding enables sparse event-driven computation, while FP8 coding accelerates inference on modern GPUs. (2) Enhanced Training Strategy: We develop an optimized Transformer-to-Hybrid (T2H) pipeline with dual conversion paths for LLMs and VLMs using curated open-source data. Empirically, SpB2.0-5B and SpB2.0-VL-5B recover most of the base Transformer (Qwen3-4B) capability with under 7k A100 GPU hours. SpB2.0 achieves a 10.13x TTFT speedup at 4M context and supports over 10M tokens on 8 A100 GPUs under vLLM, where full-attention models exceed memory limits. It also demonstrates strong cross-platform compatibility, enabling FP8 GPU inference (2.52x speedup at 250k) and efficient neuromorphic execution (64.31% sparsity, with 70.6% and 46.5% area and power reduction at 500MHz). Overall, SpikingBrain2.0 provides a practical pathway for lightweight, multimodal, spiking foundation models, highlighting the potential of combining brain-inspired mechanisms with efficient architectures for resource-constrained and edge scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpikingBrain2.0 (SpB2.0), a 5B-parameter brain-inspired foundation model advancing its predecessor via Dual-Space Sparse Attention (DSSA), an inter-layer hybrid of Sparse Softmax Attention (MoBA) and Sparse Linear Attention (SSE). It further proposes a Transformer-to-Hybrid (T2H) conversion pipeline with dual paths for LLMs and VLMs on curated open-source data, plus dual quantization (INT8-Spiking for event-driven computation and FP8 for GPU acceleration). Empirically, SpB2.0-5B and SpB2.0-VL-5B are claimed to recover most Qwen3-4B capability with under 7k A100 GPU hours, deliver 10.13x TTFT speedup at 4M context, support >10M tokens on 8 A100 GPUs under vLLM (where full attention exceeds limits), and achieve 64.31% sparsity with 70.6% area and 46.5% power reduction on neuromorphic hardware at 500MHz.
Significance. If the performance-recovery and efficiency claims hold under rigorous validation, the work would be significant for efficient long-context modeling in resource-constrained settings. The combination of hybrid sparse attention, low-overhead T2H conversion, and cross-platform support (GPU FP8 and neuromorphic spiking) addresses key bottlenecks in scaling context length while maintaining multimodal capability, offering a practical route toward lightweight foundation models for edge and specialized hardware.
major comments (2)
- [Abstract] Abstract: The abstract reports concrete empirical outcomes (10.13x TTFT speedup at 4M context, capability recovery of Qwen3-4B, 64.31% sparsity) but supplies no evaluation details, full baselines, error bars, data-exclusion rules, or per-task breakdowns; the central performance-recovery and speedup claims therefore cannot be assessed from the provided information.
- [Method and Experiments] Method and Experiments (T2H pipeline and DSSA): The claim that the T2H conversion recovers most base-model capability is load-bearing for the headline efficiency results, yet the manuscript provides no ablations on DSSA components (MoBA + SSE) or explicit long-context metrics such as Needle-in-Haystack at 4M; the approximation inherent in the hybrid sparse attention risks degrading long-range dependencies on untested distributions, directly undermining the practical value of the reported speedups and neuromorphic gains.
minor comments (1)
- [Abstract] Abstract: The notation 'SpB2.0-5B' and 'SpB2.0-VL-5B' is introduced without an explicit mapping to the base model sizes or architectural differences from Qwen3-4B.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and committing to targeted revisions that strengthen the presentation of our results without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports concrete empirical outcomes (10.13x TTFT speedup at 4M context, capability recovery of Qwen3-4B, 64.31% sparsity) but supplies no evaluation details, full baselines, error bars, data-exclusion rules, or per-task breakdowns; the central performance-recovery and speedup claims therefore cannot be assessed from the provided information.
Authors: We agree that the abstract's brevity limits the inclusion of full evaluation protocols. The main manuscript details the baselines (primarily Qwen3-4B and other long-context efficient models), per-task results across standard benchmarks, and error bars from repeated runs in Section 4 and the associated tables. Data handling follows the original benchmark protocols, with exclusions noted in Appendix B. To address the concern, we will revise the abstract to include a brief reference to the evaluation framework and direct readers to the experimental sections for complete details, baselines, and breakdowns. revision: partial
-
Referee: [Method and Experiments] Method and Experiments (T2H pipeline and DSSA): The claim that the T2H conversion recovers most base-model capability is load-bearing for the headline efficiency results, yet the manuscript provides no ablations on DSSA components (MoBA + SSE) or explicit long-context metrics such as Needle-in-Haystack at 4M; the approximation inherent in the hybrid sparse attention risks degrading long-range dependencies on untested distributions, directly undermining the practical value of the reported speedups and neuromorphic gains.
Authors: We acknowledge that the manuscript does not present explicit component ablations for DSSA (MoBA + SSE) in the main text, nor a Needle-in-Haystack evaluation at the full 4M scale. Long-context results are instead reported via LongBench and custom retrieval/perplexity tasks up to 4M tokens. We will add a dedicated ablation subsection analyzing the individual and combined contributions of MoBA and SSE, along with Needle-in-Haystack results at contexts up to 1M (with extrapolation analysis to 4M, noting the prohibitive cost of full-attention baselines at extreme lengths). Regarding risks to long-range dependencies, the inter-layer hybrid design interleaves sparse softmax attention for local precision with linear attention for global efficiency; our empirical capability recovery on long-context benchmarks indicates that this preserves essential dependencies without significant degradation. revision: yes
Circularity Check
No circularity: empirical results with no equations or self-referential reductions
full rationale
The paper's abstract and described contributions contain no mathematical derivations, equations, or first-principles predictions. DSSA and the T2H pipeline are introduced as architectural and training innovations, with all performance numbers (10.13x TTFT, 64.31% sparsity, recovery of Qwen3-4B capability) presented as direct empirical measurements on hardware and benchmarks. No fitted parameters are renamed as predictions, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results occurs. The chain is self-contained because claims rest on external comparisons and measurements rather than internal definitions or tautologies.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Curated open-source data and the dual conversion paths in T2H recover most base Transformer capability with under 7k GPU hours
invented entities (1)
-
Dual-Space Sparse Attention (DSSA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Llama 3.2: Revolutionizing edge ai and vision with open, customizable models.https://ai
AI at Meta. Llama 3.2: Revolutionizing edge ai and vision with open, customizable models.https://ai. meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/ , September
2024
-
[2]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Accessed: 2026-03-25. Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661,
work page internal anchor Pith review arXiv 2026
-
[3]
Simran Arora, Sabri Eyuboglu, Aman Timalsina, Isys Johnson, Michael Poli, James Zou, Atri Rudra, and Christopher Ré. Zoology: Measuring and improving recall in efficient language models. InProceedings of 12th International Conference on Learning Representations (ICLR). ICLR, 2024a. Simran Arora, Sabri Eyuboglu, Michael Zhang, Aman Timalsina, Silas Alberti...
work page internal anchor Pith review arXiv
-
[4]
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.172. URL https: //aclanthology.org/2024.acl-long.172. Aarti Basant, Abhijit Khairnar, Abhijit Paithankar, Abhinav Khattar, Adithya Renduchintala, Aditya Malte, Akhiad Bercovich, Akshay Hazare, Alejandra Rico, Aleksander Ficek, et al. Nvidia nemotron nano 2: An accurate and efficient...
-
[5]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review arXiv 2004
-
[6]
Martin Benfeghoul, Teresa Delgado, Adnan Oomerjee, Haitham Bou Ammar, Jun Wang, and Zafeirios Fountas. Untangling component imbalance in hybrid linear attention conversion methods.arXiv preprint arXiv:2510.05901,
-
[7]
23 Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchin- tala, Aditya Vavre, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, et al. Nemotron 3 nano: Open, efficient mixture-of-experts hybrid mamba-transformer model for agentic reasoning.arXiv preprint arXiv:2512.20848,
-
[8]
Evaluating Large Language Models Trained on Code
Beidi Chen, Tri Dao, Eric Winsor, Zhao Song, Atri Rudra, and Christopher Ré. Scatterbrain: Unifying sparse and low-rank attention.Advances in Neural Information Processing Systems, 34:17413–17426, 2021a. Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for e...
work page internal anchor Pith review arXiv 1904
-
[9]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv:1803.05457v1,
work page internal anchor Pith review arXiv
-
[10]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review arXiv
-
[11]
Griffin: Mixing gated linear recurrences with local attention for efficient language models
Soham De, Samuel L Smith, Anushan Fernando, Aleksandar Botev, George Cristian-Muraru, Albert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, Srivatsan Srinivasan, et al. Griffin: Mixing gated linear recurrences with local attention for efficient language models.arXiv preprint arXiv:2402.19427,
-
[12]
Hymba: A Hybrid-head Architecture for Small Language Models
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, et al. Hymba: A hybrid-head architecture for small language models.arXiv preprint arXiv:2411.13676,
-
[13]
Jet-nemotron: Efficient language model with post neural architecture search, 2025
Yuxian Gu, Qinghao Hu, Shang Yang, Haocheng Xi, Junyu Chen, Song Han, and Han Cai. Jet-nemotron: Efficient language model with post neural architecture search.arXiv preprint arXiv:2508.15884,
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv
-
[15]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021a. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt....
-
[16]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654,
work page internal anchor Pith review arXiv
-
[17]
Parallel training in spiking neural networks.arXiv preprint arXiv:2602.01133,
Yanbin Huang, Man Yao, Yuqi Pan, Changze Lv, Siyuan Xu, Xiaoqing Zheng, Bo Xu, and Guoqi Li. Parallel training in spiking neural networks.arXiv preprint arXiv:2602.01133,
-
[18]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509,
work page internal anchor Pith review arXiv
-
[19]
Albert Qiaochu Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.ArXiv, abs/2310.06825,
work page internal anchor Pith review arXiv
-
[20]
Jungo Kasai, Hao Peng, Yizhe Zhang, Dani Yogatama, Gabriel Ilharco, Nikolaos Pappas, Yi Mao, Weizhu Chen, and Noah A Smith
URLhttps://api.semanticscholar.org/ CorpusID:263830494. Jungo Kasai, Hao Peng, Yizhe Zhang, Dani Yogatama, Gabriel Ilharco, Nikolaos Pappas, Yi Mao, Weizhu Chen, and Noah A Smith. Finetuning pretrained transformers into rnns. In2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, pp. 10630–10643. Association for Computational L...
2021
-
[21]
Llava-onevision: Easy visual task transfer.Transactions on Machine Learning Research, 2024a
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.Transactions on Machine Learning Research, 2024a. Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed- bench: Benchmarking multimodal large language m...
-
[22]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025a. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processi...
work page internal anchor Pith review arXiv
-
[23]
A Comprehensive Sur- vey on Long Context Language Modeling.arXiv preprint arXiv:2503.17407, 2025
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024a. URLhttps://llava-vl.github.io/ blog/2024-01-30-llava-next/. Jiaheng Liu, Dawei Zhu, Zhiqi Bai, Yancheng He, Huanxuan Liao, Haoran Que, Zekun Wang, Chenchen Zhang, Ge Zhang, Jiebin Zhang, et al. A...
-
[24]
Thinking Machines Lab: Connectionism , year =
doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy-distillation. Xinhao Luo, Man Yao, Yuhong Chou, Bo Xu, and Guoqi Li. Integer-valued training and spike-driven inference spiking neural network for high-performance and energy-efficient object detection. InEuropean Conference on Computer Vision, pp. 253–272. Springer,
-
[25]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pp. 2263–2279,
2022
-
[26]
Linearizing large language models.arXiv preprint arXiv:2405.06640,
Jean Mercat, Igor Vasiljevic, Sedrick Keh, Kushal Arora, Achal Dave, Adrien Gaidon, and Thomas Kollar. Linearizing large language models.arXiv preprint arXiv:2405.06640,
-
[27]
Hugging Face Space, accessed 2026-03-26. Yuqi Pan, Yongqi An, Zheng Li, Yuhong Chou, Ruijie Zhu, Xiaohui Wang, Mingxuan Wang, Jinqiao Wang, and Guoqi Li. Scaling linear attention with sparse state expansion.arXiv preprint arXiv:2507.16577, 2025a. Yuqi Pan, Yupeng Feng, Jinghao Zhuang, Siyu Ding, Han Xu, Zehao Liu, Bohan Sun, Yuhong Chou, Xuerui Qiu, Anlin...
-
[28]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
27 Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.arXiv preprint arXiv:1907.10641,
work page internal anchor Pith review arXiv 1907
-
[29]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review arXiv
-
[31]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621,
work page internal anchor Pith review arXiv
-
[32]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them.arXiv preprint arXiv:2210.09261,
work page internal anchor Pith review arXiv
-
[33]
Hongyuan Tao, Bencheng Liao, Shaoyu Chen, Haoran Yin, Qian Zhang, Wenyu Liu, and Xinggang Wang. Infinitevl: Synergizing linear and sparse attention for highly-efficient, unlimited-input vision-language models.arXiv preprint arXiv:2512.08829,
-
[34]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review arXiv
-
[35]
Kimi Linear: An Expressive, Efficient Attention Architecture
Kimi Team, Yu Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, et al. Kimi linear: An expressive, efficient attention architecture.arXiv preprint arXiv:2510.26692, 2025a. Ling Team, Bin Han, Caizhi Tang, Chen Liang, Donghao Zhang, Fan Yuan, Feng Zhu, Jie Gao, Jingyu Hu, Longfei Li, et al. Every att...
work page internal anchor Pith review arXiv
-
[36]
Han Xu, Zhiyong Qin, Di Shang, Jiahong Zhang, Xuerui Qiu, Bo Lei, Tiejun Huang, Bo Xu, and Guoqi Li. Spikemllm: Spike-based multimodal large language models via modality-specific temporal scales and temporal compression, 2026a. URLhttps://arxiv.org/abs/2604.18610. Han Xu, Xuerui Qiu, Baiyu Chen, Xinhao Luo, Xingrun Xing, Jiahong Zhang, Bo Lei, Tiejun Huan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Spike- driven transformer v2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips
Man Yao, JiaKui Hu, Tianxiang Hu, Yifan Xu, Zhaokun Zhou, Yonghong Tian, Bo XU, and Guoqi Li. Spike- driven transformer v2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips. InThe Twelfth International Conference on Learning Representations, 2024a. Man Yao, Ole Richter, Guangshe Zhao, Ning Qiao, Yannan Xi...
2041
-
[38]
doi: 10.1109/ TPAMI.2025.3530246. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
-
[39]
Jintao Zhang, Haofeng Huang, Pengle Zhang, Jia Wei, Jun Zhu, and Jianfei Chen. Sageattention2: Efficient attention with thorough outlier smoothing and per-thread int4 quantization. InInternational Conference on Machine Learning, pp. 75097–75119. PMLR, 2025a. Jintao Zhang, Haoxu Wang, Kai Jiang, Shuo Yang, Kaiwen Zheng, Haocheng Xi, Ziteng Wang, Hongzhou Z...
-
[40]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review arXiv
-
[41]
Jingwei Zuo, Maksim Velikanov, Ilyas Chahed, Younes Belkada, Dhia Eddine Rhayem, Guillaume Kunsch, Hakim Hacid, Hamza Yous, Brahim Farhat, Ibrahim Khadraoui, et al. Falcon-h1: A family of hybrid-head language models redefining efficiency and performance.arXiv preprint arXiv:2507.22448,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.