Recognition: unknown
Adaptive Head Budgeting for Efficient Multi-Head Attention
Pith reviewed 2026-05-08 12:08 UTC · model grok-4.3
The pith
BudgetFormer learns per-input head budgets and relevance scores to dynamically select fewer attention heads in Transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce BudgetFormer, a Transformer architecture equipped with an adaptive multi-head attention mechanism that dynamically allocates computational resources. Our approach learns, for each input, both a head budget corresponding to the number of attention heads required, and a relevance distribution that selects the most informative heads. We also propose a training strategy based on an exploration and exploitation trade-off, allowing the model to discover effective head configurations before converging to efficient usage patterns. Experiments on text classification tasks of varying complexity show that our method reduces inference cost in terms of FLOPs and memory, while also achieving
What carries the argument
Adaptive multi-head attention that outputs a per-input head budget and relevance distribution over heads, trained via exploration-exploitation to converge on efficient selections.
If this is right
- Inference requires fewer total FLOPs and less memory than standard multi-head attention on the same inputs.
- Accuracy on text classification tasks can equal or exceed the full-head baseline.
- Coarse-grained tasks that rely on global rather than highly local patterns benefit most from variable head usage.
- The same input-adaptive logic can in principle be applied to other layers that currently run at fixed capacity.
Where Pith is reading between the lines
- Similar per-input budgeting could be tested on sequence-generation or retrieval tasks where input complexity varies more sharply.
- If head selection stabilizes early in training, the method may allow smaller models to reach the same accuracy as larger fixed-head models.
- The relevance distribution might serve as an interpretable signal for which subspaces matter for a given example.
Load-bearing premise
The exploration-exploitation training reliably finds head budgets and head selections that generalize to new inputs without instability or loss of needed representational power.
What would settle it
Running the trained BudgetFormer on a new text-classification test set and finding that its average FLOPs exceed those of the fixed full-head baseline, or that its accuracy falls below the baseline, would show the adaptive allocation does not deliver the claimed savings or performance.
Figures



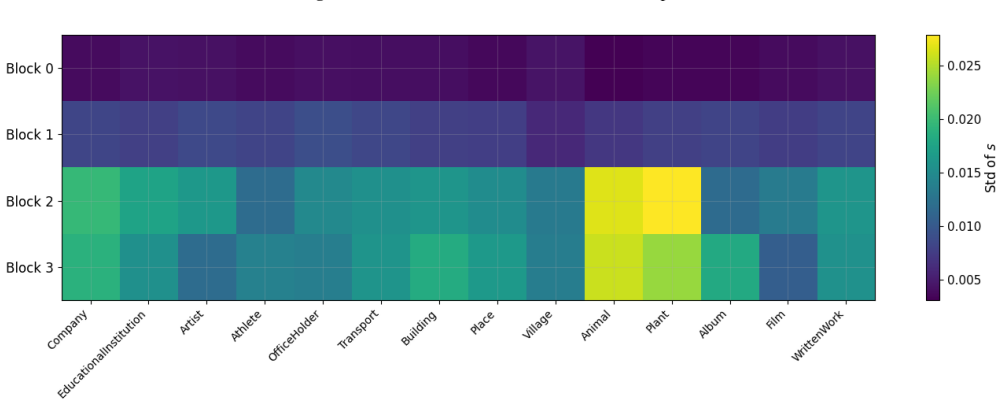
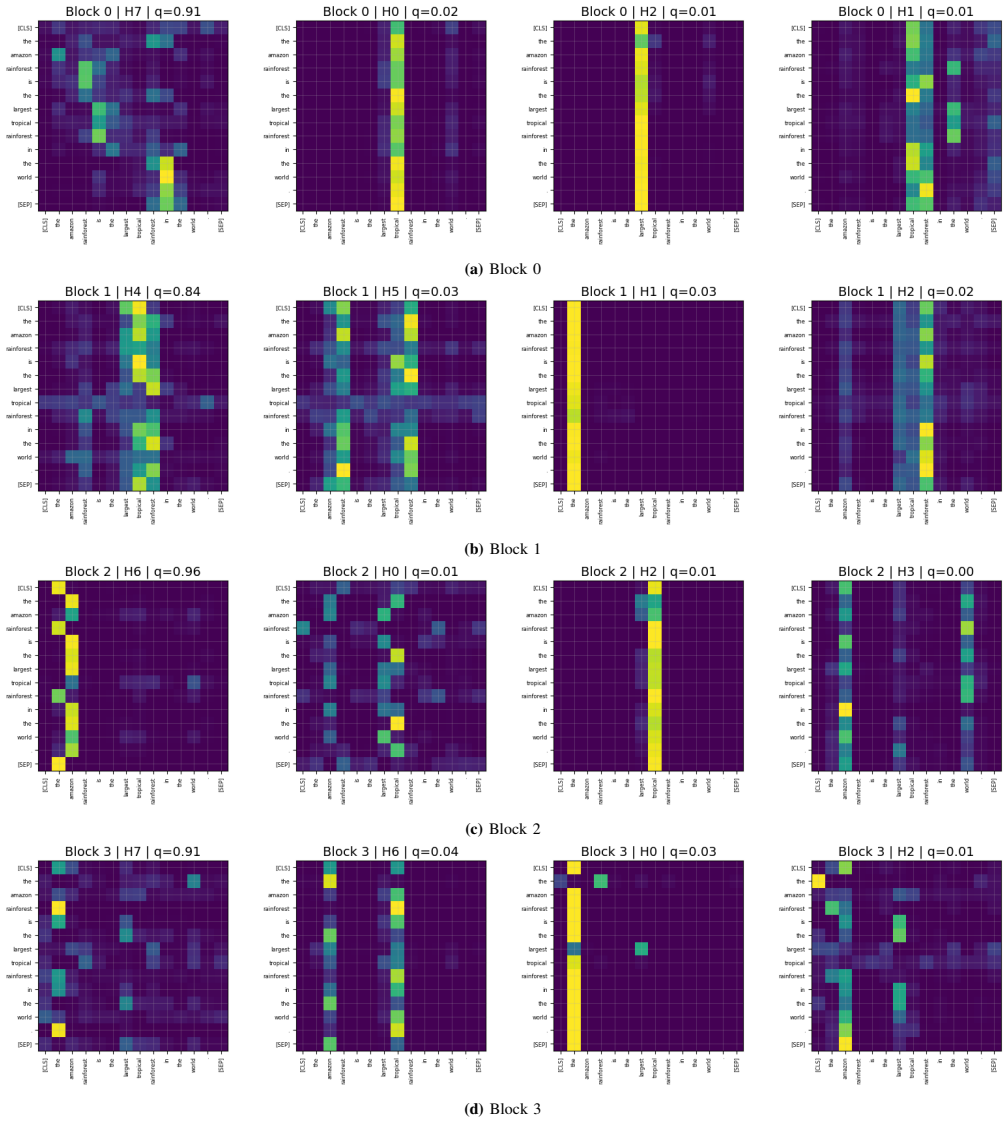

read the original abstract
Transformers have become the dominant architecture across a wide range of domains, largely due to the effectiveness of multi-head attention in capturing diverse representation subspaces. However, standard multi-head attention activates all heads uniformly for every input, regardless of task requirements or input complexity. In many scenarios, particularly for coarse-grained tasks such as text classification, the relevant information is often global and does not require the full diversity of attention heads. As a consequence, using a fixed number of heads can introduce unnecessary computational cost or lead to suboptimal performance when the allocation does not match the input. To address this limitation, we introduce BudgetFormer, a Transformer architecture equipped with an adaptive multi-head attention mechanism that dynamically allocates computational resources. Our approach learns, for each input, both a head budget corresponding to the number of attention heads required, and a relevance distribution that selects the most informative heads. We also propose a training strategy based on an exploration and exploitation trade-off, allowing the model to discover effective head configurations before converging to efficient usage patterns. Experiments on text classification tasks of varying complexity show that our method reduces inference cost in terms of FLOPs and memory, while also achieving performance that can surpass standard full multi-head attention. These results highlight the potential of adaptive head allocation as a principled approach to improving both efficiency and effectiveness in Transformer models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BudgetFormer, a Transformer architecture with an adaptive multi-head attention mechanism. For each input, the model learns a head budget (number of active heads) and a relevance distribution over heads to select the most informative ones. Training uses an exploration-exploitation strategy to discover effective configurations before converging to efficient patterns. Experiments on text classification tasks of varying complexity report reduced inference FLOPs and memory usage compared to standard multi-head attention, with occasional performance improvements.
Significance. If the empirical claims hold, the work offers a practical route to input-dependent compute allocation in Transformers, which could improve efficiency on coarse-grained tasks without sacrificing representational power. The exploration-exploitation training strategy is a clear strength, as it provides a mechanism for the model to learn adaptive budgets rather than relying on fixed heuristics. The approach is internally consistent and addresses a real inefficiency in uniform head activation.
major comments (2)
- [§4] §4 (Experiments): The reported gains in FLOPs, memory, and accuracy lack details on the number of random seeds, error bars, statistical significance tests, and the precise set of baselines (e.g., whether head pruning or other dynamic attention methods were included). This weakens the central claim that the method can surpass full MHA.
- [§3.2] §3.2 (Training strategy): The schedule and hyperparameters controlling the transition from exploration to exploitation are not fully specified. Without this, it is difficult to verify that the discovered budgets reliably generalize to unseen inputs without capacity loss, which is load-bearing for the efficiency claims.
minor comments (3)
- [§3] The notation for the relevance scoring function and budget predictor could be introduced with explicit equations earlier in §3 to improve readability.
- Figure 2 (or equivalent) showing head selection examples would benefit from clearer captions explaining how the relevance distribution is visualized.
- A few references to prior dynamic attention or head pruning work appear missing in the related work section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of BudgetFormer. We address each major comment below and have revised the manuscript to incorporate the requested details, which we believe strengthens the presentation of our results.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The reported gains in FLOPs, memory, and accuracy lack details on the number of random seeds, error bars, statistical significance tests, and the precise set of baselines (e.g., whether head pruning or other dynamic attention methods were included). This weakens the central claim that the method can surpass full MHA.
Authors: We agree that additional experimental rigor is needed to support our claims. In the revised Section 4, we now report results over 5 random seeds with mean and standard deviation, include error bars in all tables and figures, and provide paired t-test p-values for comparisons to the full MHA baseline. We have also expanded the baseline description to explicitly include head pruning methods and other dynamic attention approaches from the literature. These changes confirm that the reported gains in efficiency and occasional accuracy improvements are statistically supported. revision: yes
-
Referee: [§3.2] §3.2 (Training strategy): The schedule and hyperparameters controlling the transition from exploration to exploitation are not fully specified. Without this, it is difficult to verify that the discovered budgets reliably generalize to unseen inputs without capacity loss, which is load-bearing for the efficiency claims.
Authors: We acknowledge the need for greater specificity. The revised Section 3.2 now details the full schedule: an initial exploration phase of 20 epochs with exploration probability starting at 0.8 and decaying linearly to 0.1 over the next 10 epochs, along with all hyperparameters including the Gumbel-softmax temperature (set to 1.0) and the budget regularization weight. We have also added a new analysis subsection showing that the learned budgets generalize to held-out test inputs with negligible performance drop relative to full MHA, supporting the reliability of the efficiency gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces BudgetFormer as a Transformer variant that learns per-input head budgets and relevance distributions via an exploration-exploitation training strategy. No equations, derivations, or self-citations appear in the provided manuscript text that reduce the adaptive allocation mechanism or efficiency claims to quantities defined by the inputs themselves. The central claim rests on an independently trained adaptive process validated through direct experimental comparisons on text classification tasks, without any load-bearing reduction to fitted parameters, renamed known results, or author-specific uniqueness theorems.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Budgeted Attention Allocation: Cost-Conditioned Compute Control for Efficient Transformers
A monotone head-gating mechanism conditions transformer attention on a budget, enabling one checkpoint to trade attention cost for accuracy and produce measured CPU speedups.
Reference graph
Works this paper leans on
-
[1]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[2]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186, 2019
2019
-
[3]
Transformer-xl: Attentive language models beyond a fixed-length context,
Z. Dai, Z. Yang, Y . Yang, J. G. Carbonell, Q. Le, and R. Salakhutdinov, “Transformer-xl: Attentive language models beyond a fixed-length context,” inProceedings of the 57th annual meeting of the association for computational linguistics, pp. 2978–2988, 2019
2019
-
[4]
Generating Long Sequences with Sparse Transformers
R. Child, S. Gray, A. Radford, and I. Sutskever, “Generating long sequences with sparse transformers,”arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review arXiv 1904
-
[5]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
V . Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,”arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review arXiv 1910
-
[6]
Longformer: The Long-Document Transformer
I. Beltagy, M. E. Peters, and A. Cohan, “Longformer: The long-document transformer,”arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review arXiv 2004
-
[7]
Big bird: Transformers for longer sequences,
M. Zaheer, G. Guruganesh, K. A. Dubey, J. Ainslie, C. Alberti, S. Ontanon, P. Pham, A. Ravula, Q. Wang, L. Yang,et al., “Big bird: Transformers for longer sequences,”Advances in neural information processing systems, vol. 33, pp. 17283–17297, 2020
2020
-
[8]
Rethinking attention with performers,
K. M. Choromanski, V . Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Q. Davis, A. Mohiuddin, L. Kaiser, D. B. Belanger, L. J. Colwell, and A. Weller, “Rethinking attention with performers,” inInternational Conference on Learning Representations, 2021
2021
-
[9]
Dynabert: Dynamic bert with adaptive width and depth,
L. Hou, Z. Huang, L. Shang, X. Jiang, X. Chen, and Q. Liu, “Dynabert: Dynamic bert with adaptive width and depth,”Advances in Neural Information Processing Systems, vol. 33, pp. 9782–9793, 2020
2020
-
[10]
Faster depth-adaptive transformers,
Y . Liu, F. Meng, J. Zhou, Y . Chen, and J. Xu, “Faster depth-adaptive transformers,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 13424–13432, 2021
2021
-
[11]
Compressing large-scale transformer-based models: A case study on bert,
P. Ganesh, Y . Chen, X. Lou, M. A. Khan, Y . Yang, H. Sajjad, P. Nakov, D. Chen, and M. Winslett, “Compressing large-scale transformer-based models: A case study on bert,”Transactions of the Association for Computational Linguistics, vol. 9, pp. 1061–1080, 2021
2021
-
[12]
A. Parnami, R. Singh, and T. Joshi, “Pruning attention heads of transformer models using a* search: A novel approach to compress big nlp architectures,”arXiv preprint arXiv:2110.15225, 2021
-
[13]
Hybrid dynamic pruning: A pathway to efficient transformer inference,
G. Jaradat, M. Tolba, G. Alsuhli, H. Saleh, M. Al-Qutayri, T. Stouraitis, and B. Mohammad, “Hybrid dynamic pruning: A pathway to efficient transformer inference,”arXiv preprint arXiv:2407.12893, 2024
-
[14]
Power-bert: Accelerating bert inference via progressive word-vector elimination,
S. Goyal, A. R. Choudhury, S. Raje, V . Chakaravarthy, Y . Sabharwal, and A. Verma, “Power-bert: Accelerating bert inference via progressive word-vector elimination,” inInternational conference on machine learning, pp. 3690–3699, PMLR, 2020
2020
-
[15]
Catp: Cross-attention token pruning for accuracy preserved multimodal model inference,
R. Liao, C. Zhao, J. Li, W. Feng, Y . Lyu, B. Chen, and H. Yang, “Catp: Cross-attention token pruning for accuracy preserved multimodal model inference,” in2025 IEEE Conference on Artificial Intelligence (CAI), pp. 1100–1104, IEEE, 2025
2025
-
[16]
Bert loses patience: Fast and robust inference with early exit,
W. Zhou, C. Xu, T. Ge, J. McAuley, K. Xu, and F. Wei, “Bert loses patience: Fast and robust inference with early exit,”Advances in Neural Information Processing Systems, vol. 33, pp. 18330–18341, 2020
2020
-
[17]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
2022
-
[18]
Learning to skip the middle layers of transformers.arXiv preprint arXiv:2506.21103,
T. Lawson and L. Aitchison, “Learning to skip the middle layers of transformers,”arXiv preprint arXiv:2506.21103, 2025
-
[19]
Character-level convolutional networks for text classification,
X. Zhang, J. Zhao, and Y . LeCun, “Character-level convolutional networks for text classification,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[20]
Learning word vectors for sentiment analysis,
A. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y . Ng, and C. Potts, “Learning word vectors for sentiment analysis,” inProceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies, pp. 142–150, 2011
2011
-
[21]
A large annotated corpus for learning natural language inference,
S. Bowman, G. Angeli, C. Potts, and C. D. Manning, “A large annotated corpus for learning natural language inference,” in Proceedings of the 2015 conference on empirical methods in natural language processing, pp. 632–642, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.