Recognition: unknown
Surface Sensitivity in Lean 4 Autoformalization
Pith reviewed 2026-05-08 08:30 UTC · model grok-4.3
The pith
Paraphrase sensitivity in Lean autoformalization stems from compilation-boundary failures rather than semantic divergence among successful formalizations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
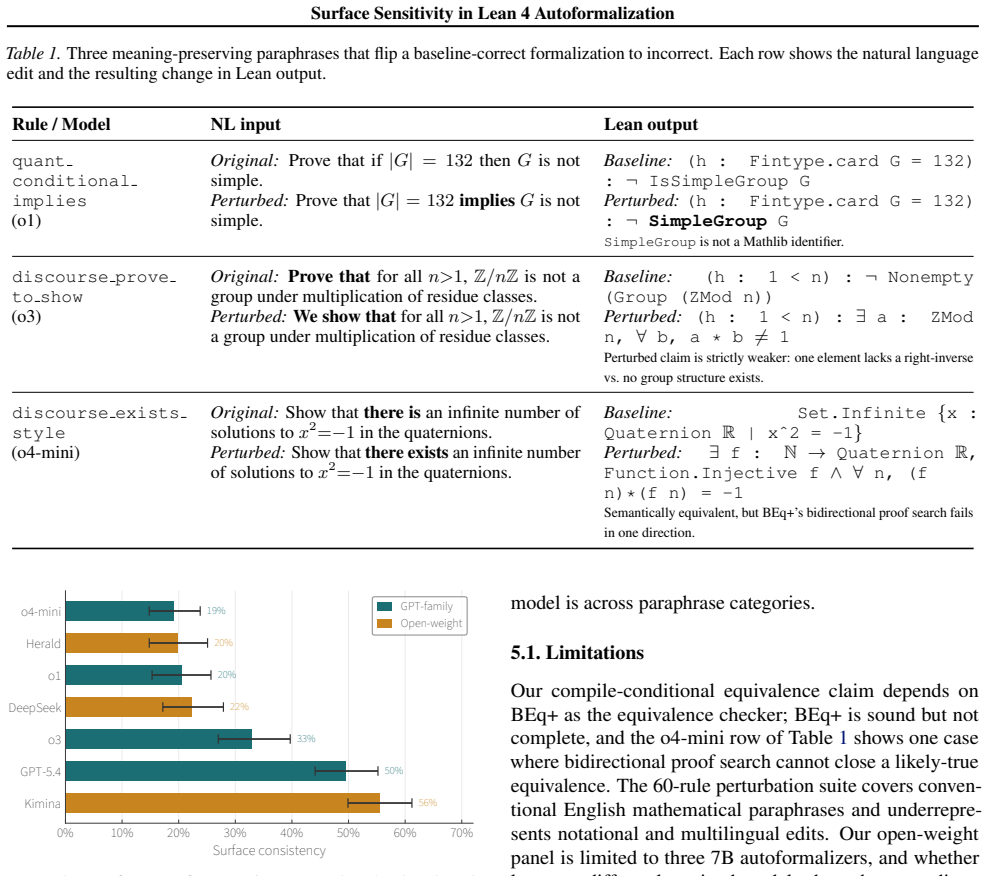
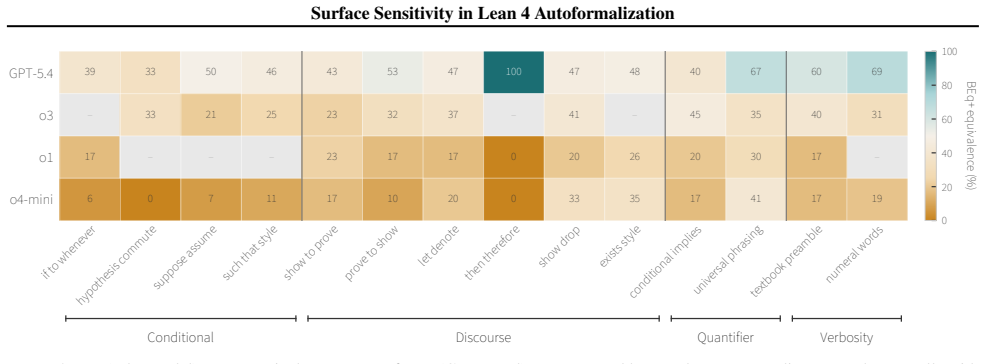
When both baseline and perturbed outputs compile, paired predictions are semantically equivalent under BEq+ and structurally near-identical under GTED. By contrast, paraphrasing substantially affects whether outputs compile, with failure modes varying across datasets and perturbation classes.
What carries the argument
Sixty deterministic paraphrase rules applied to ProofNet# and miniF2F, evaluated with the BEq+ semantic equivalence metric and GTED structural similarity metric on compiling formalizations.
If this is right
- Training-time interventions should target the compile boundary rather than the semantic layer.
- Benchmarks should separate compile-conditional equivalence from surface consistency.
- Paraphrasing affects compilation success rates, with failure modes that differ by dataset and perturbation class.
Where Pith is reading between the lines
- The same compile-boundary pattern may appear in autoformalization for other proof assistants beyond Lean 4.
- Increasing robustness to surface variation could raise overall success rates by improving the fraction of outputs that reach compilation.
- Datasets enriched with controlled paraphrases could serve as better probes for where models lose the ability to produce valid formal statements.
Load-bearing premise
The 60 deterministic paraphrase rules preserve semantic equivalence of the original theorems, and the BEq+ and GTED metrics fully capture any semantic or structural differences in the formal outputs.
What would settle it
Finding even one pair of formalizations from semantically equivalent paraphrases that both compile successfully yet differ under the BEq+ metric would disprove the claim that successful outputs show no semantic divergence.
Figures

read the original abstract
Natural-language variation poses a key challenge in Lean autoformalization: semantically equivalent paraphrases of the same theorem statements can induce divergent formal outputs, yet it remains unclear whether this variation reflects semantic disagreements or shallower failures. We investigate this question in Lean 4 using 60 deterministic paraphrase rules applied to ProofNet\# and miniF2F. Across four GPT-family models and three open-weight 7B autoformalizers, we find that the observed paraphrase sensitivity reflects compilation-boundary failures rather than semantic divergence among successful formalizations. In particular, when both baseline and perturbed outputs compile, paired predictions are semantically equivalent under BEq+ and structurally near-identical under GTED. By contrast, paraphrasing substantially affects whether outputs compile, with failure modes varying across datasets and perturbation classes. Our results suggest that future training-time interventions should target the compile boundary rather than the semantic layer, and that benchmarks should separate compile-conditional equivalence from surface consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates paraphrase sensitivity in Lean 4 autoformalization by applying 60 deterministic, meaning-preserving paraphrase rules to theorems drawn from ProofNet# and miniF2F. Across four GPT-family models and three open-weight 7B autoformalizers, it reports that paraphrase-induced variation primarily manifests as compilation failures rather than semantic divergence: when both baseline and perturbed outputs compile successfully, the formalizations are equivalent under the BEq+ metric and structurally near-identical under GTED. The work concludes that future interventions should target the compile boundary and that benchmarks should separate compile-conditional equivalence from surface consistency.
Significance. If the central empirical distinction holds, the result usefully separates compilation-boundary effects from deeper semantic disagreements in autoformalization. The deterministic construction of the 60 paraphrase rules and the conditional analysis (equivalence only among successful compilations) provide a clean operationalization that can guide both model training and benchmark design. The explicit use of BEq+ for semantic equivalence and GTED for structural similarity adds precision to the claims.
minor comments (3)
- The experimental section should specify the exact number of outputs sampled or evaluated per theorem (including any filtering for successful compilations) and report the raw counts of cases where both baseline and perturbed outputs compile, to allow readers to assess the statistical power of the BEq+ and GTED comparisons.
- The prompt templates used for each model family are referenced but not reproduced; including them (or a representative example) would improve reproducibility of the reported compilation rates and failure-mode distributions.
- Table or figure captions for the per-dataset and per-perturbation-class results should explicitly state the total number of theorem-paraphrase pairs evaluated so that the reported percentages of compilation success can be interpreted in absolute terms.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work and for recommending minor revision. We are pleased that the central empirical finding—that paraphrase sensitivity primarily manifests at the compilation boundary rather than through semantic divergence among successful formalizations—was viewed as useful, along with the clean operationalization via deterministic rules, BEq+, and GTED.
Circularity Check
No significant circularity
full rationale
The paper conducts an empirical measurement of model outputs on paraphrased theorem statements from ProofNet# and miniF2F, using deterministic meaning-preserving rules and external verification via compilation success plus BEq+ semantic equivalence and GTED structural metrics. The central claim is scoped to the compile-conditional regime and does not derive any quantity from fitted parameters, self-definitions, or load-bearing self-citations; all reported quantities are direct observations against independent checks. No step reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 60 deterministic paraphrase rules preserve the semantic meaning of the theorems.
Reference graph
Works this paper leans on
-
[1]
arXiv:2302.12433 [cs.CL] https://arxiv.org/abs/2302.12433
Azerbayev, Z., Piotrowski, B., Schoelkopf, H., Ayers, E. W., Radev, D., and Avigad, J. Proofnet: Autoformalizing and formally proving undergraduate-level mathematics. CoRR, abs/2302.12433,
-
[2]
Chen, J., Li, Z., Hu, X., and Xia, X. NLPerturbator: Study- ing the robustness of code LLMs to natural language variations.arXiv preprint arXiv:2406.19783,
- [3]
-
[4]
Math-perturb: Benchmarking llms’ math reasoning abilities against hard perturbations
Huang, K., Guo, J., Li, Z., Ji, X., Ge, J., Li, W., Guo, Y ., Cai, T., Yuan, H., Wang, R., Wu, Y ., Yin, M., Tang, S., Huang, Y ., Jin, C., Chen, X., Zhang, C., and Wang, M. MATH- Perturb: Benchmarking LLMs’ math reasoning abilities against hard perturbations.CoRR, abs/2502.06453,
-
[5]
Liu, Q., Zheng, X., Lu, X., Cao, Q., and Yan, J. Rethinking and improving autoformalization: Towards a faithful met- ric and a dependency retrieval-based approach. InThe Thirteenth International Conference on Learning Repre- sentations, 2025a. Liu, X., Bao, K., Zhang, J., Liu, Y ., Chen, Y ., Liu, Y ., Jiao, Y ., and Luo, T. ATLAS: Autoformalizing theo- r...
- [6]
-
[7]
Moore, H. and Shah, A. Evaluating autoformalization ro- bustness via semantically similar paraphrasing.CoRR, abs/2511.12784,
-
[8]
Re- liable evaluation and benchmarks for statement autofor- malization
Poiroux, A., Weiss, G., Kunˇcak, V ., and Bosselut, A. Re- liable evaluation and benchmarks for statement autofor- malization. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 17958–17980,
2025
-
[9]
Ren, Z. Z., Shao, Z., Song, J., Xin, H., Wang, H., Zhao, W., Zhang, L., Fu, Z., Zhu, Q., Yang, D., Wu, Z. F., Gou, Z., Ma, S., Tang, H., Liu, Y ., Gao, W., Guo, D., and Ruan, C. DeepSeek-Prover-V2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition.CoRR, abs/2504.21801,
-
[10]
Wang, H., Unsal, M., Lin, X., Baksys, M., Liu, J., Dos San- tos, M., Sung, F., Vinyes, M., Ying, Z., Zhu, Z., Lu, J., de Saxc´e, H., et al. Kimina-Prover Preview: Towards large formal reasoning models with reinforcement learn- ing.arXiv preprint arXiv:2504.11354,
-
[11]
PromptBench : Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts
Zhu, K., Wang, J., Zhou, J., Wang, Z., Chen, H., Wang, Y ., Yang, L., Ye, W., Gong, N. Z., Zhang, Y ., and Xie, X. Promptbench: Towards evaluating the robustness of large language models on adversarial prompts.CoRR, abs/2306.04528,
-
[12]
ifPthenQ
5 Surface Sensitivity in Lean 4 Autoformalization A. Additional Results A.1. Compile Rates Table 2 reports per-cell compile rates underlying theN=602 compile-both claim in §4.1. Compile rates range from 11.4% to 24.2% per prediction direction. The both-compile column gives the number of pairs where both baseline and perturbed predictions type-check. BEq+ ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.