Recognition: unknown
Revisable by Design: A Theory of Streaming LLM Agent Execution
Pith reviewed 2026-05-08 08:21 UTC · model grok-4.3
The pith
An agent's flexibility is bounded by its reversibility in the stream paradigm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the stream paradigm, agent execution and user intervention are concurrent interleaved processes. The reversibility taxonomy classifies every agent action as Idempotent, Reversible, Compensable, or Irreversible. An agent's flexibility is bounded by its reversibility: conflicting compensable actions impose unavoidable adaptation costs, and conflicting irreversible actions make full specification satisfaction impossible. These costs are properties of the action space, not of the algorithm. The Revision Absorber is a reactive algorithm based on the Earliest-Conflict Rollback rule that is structurally optimal under mild assumptions.
What carries the argument
The reversibility taxonomy that classifies every agent action into Idempotent, Reversible, Compensable, or Irreversible based on whether and how the action can be undone or compensated.
If this is right
- Conflicting compensable actions always impose some adaptation cost no matter which algorithm is used.
- Conflicting irreversible actions make it impossible to satisfy the full set of user specifications.
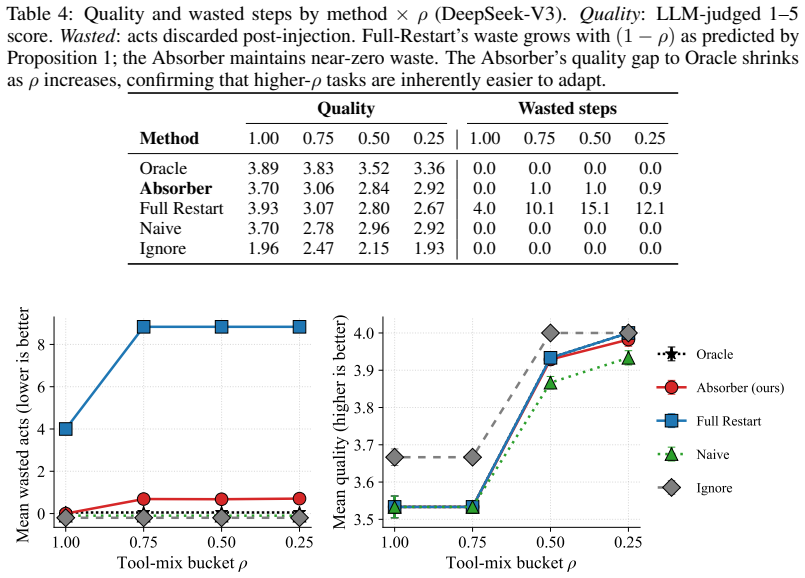
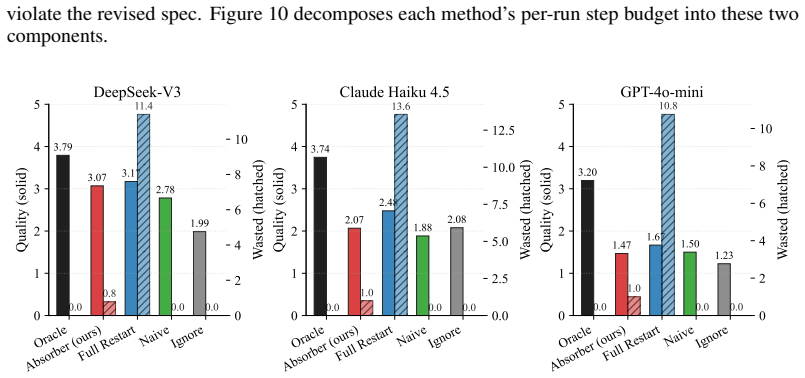
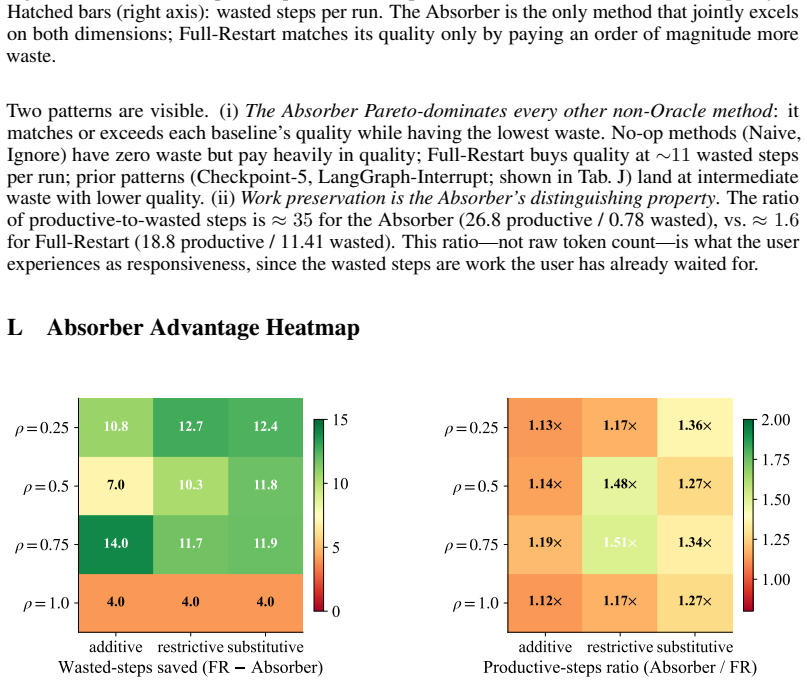
- The Revision Absorber achieves the same output quality as a full-restart baseline while wasting far fewer already-completed steps.
- The adaptation costs are determined by the action space itself rather than by algorithmic sophistication.
Where Pith is reading between the lines
- Agent builders could increase practical flexibility by preferring reversible or idempotent actions when possible during task design.
- The same reversibility bounds may apply to other concurrent AI systems such as robotic controllers or real-time planners.
- Interfaces could surface the reversibility type of pending actions so users can anticipate revision costs before issuing changes.
Load-bearing premise
The four-category taxonomy comprehensively covers every possible agent action in the stream paradigm, and the mild assumptions under which the Revision Absorber is structurally optimal actually hold.
What would settle it
A concrete execution trace in which two irreversible actions conflict yet the final output still satisfies the complete original and revised user specification without any rollback or loss, or a trace in which compensable conflicts are resolved with zero adaptation cost.
Figures










read the original abstract
Current LLM agents operate under an implicit but universal assumption: execution is a transaction -- the user submits a request, the agent works in isolation, and only upon completion does the dialogue resume. This forces users into a binary choice: wait for a potentially incorrect output, or interrupt and lose all progress. We reject this assumption and propose the stream paradigm, in which agent execution and user intervention are concurrent, interleaved processes sharing a bidirectional channel. We formalize this paradigm through a reversibility taxonomy that classifies every agent action as Idempotent, Reversible, Compensable, or Irreversible, and arrive at a core conclusion: an agent's flexibility is bounded by its reversibility. We prove that conflicting compensable actions impose unavoidable adaptation costs and that conflicting irreversible actions make full specification satisfaction impossible -- these costs are properties of the action space, not of the algorithm. Guided by this insight, we present the Revision Absorber, a reactive algorithm based on the Earliest-Conflict Rollback rule that is structurally optimal under mild assumptions. Experiments on StreamBench with real LLM agents validate all predictions: the Absorber matches the quality of a brute-force full-restart baseline while wasting an order of magnitude fewer steps of already-completed work, turning mid-execution revisions from a dead-end into a first-class interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the stream paradigm for LLM agents, replacing the transactional execution model with concurrent, interleaved agent execution and user intervention over a bidirectional channel. It introduces a four-way reversibility taxonomy (Idempotent, Reversible, Compensable, Irreversible) classifying all agent actions, proves that flexibility is bounded by reversibility (unavoidable adaptation costs for conflicting compensable actions; impossibility of full specification satisfaction for conflicting irreversible actions), shows these costs are properties of the action space, presents the Revision Absorber algorithm (Earliest-Conflict Rollback) that is structurally optimal under mild assumptions, and validates the predictions experimentally on StreamBench with real LLM agents, reporting order-of-magnitude reductions in wasted steps while matching full-restart quality.
Significance. If the taxonomy is exhaustive and the optimality result holds under the stated assumptions, the work supplies a clean theoretical foundation for interactive LLM agent design that treats revision as first-class rather than an afterthought. The separation of inherent action-space costs from algorithmic choices, the structural optimality claim, and the empirical confirmation on StreamBench constitute a substantive advance for streaming agent systems.
major comments (2)
- [theoretical development / reversibility taxonomy] The proof that conflicting irreversible actions render full specification satisfaction impossible (abstract and theoretical development) rests on the taxonomy being exhaustive for the stream paradigm; an explicit argument or counter-example check is needed showing that common LLM actions (e.g., partial tool invocations or stateful API calls) cannot fall outside the four categories.
- [Revision Absorber algorithm section] The structural optimality of the Revision Absorber under 'mild assumptions' is load-bearing for the algorithmic contribution; these assumptions must be stated verbatim and their mildness justified with respect to realistic LLM agent action spaces, as they directly determine whether the Earliest-Conflict Rollback rule is optimal.
minor comments (2)
- [experiments] StreamBench task descriptions and error-analysis details are referenced but not fully enumerated in the provided abstract; adding a concise table of benchmark characteristics would strengthen reproducibility.
- [introduction / formalization] Notation for the bidirectional channel and rollback rule could be introduced earlier with a small diagram to aid readers unfamiliar with streaming execution models.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive assessment of the theoretical and algorithmic contributions, and constructive suggestions. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [theoretical development / reversibility taxonomy] The proof that conflicting irreversible actions render full specification satisfaction impossible (abstract and theoretical development) rests on the taxonomy being exhaustive for the stream paradigm; an explicit argument or counter-example check is needed showing that common LLM actions (e.g., partial tool invocations or stateful API calls) cannot fall outside the four categories.
Authors: We agree that an explicit argument for exhaustiveness would strengthen the theoretical development. The manuscript asserts that the taxonomy classifies every agent action but does not include a dedicated mapping or counter-example check for edge cases. In the revision we will add a short subsection (or paragraph) in the theoretical development section that formally argues the four categories are exhaustive by construction: any action is classified according to whether its state change is absent/repeatable (Idempotent), directly undoable (Reversible), undoable via a compensating action (Compensable), or permanently alters observable state (Irreversible). We will explicitly map partial tool invocations (typically Reversible or Compensable depending on whether partial state is observable and rollback-capable) and stateful API calls (Irreversible if they commit external state, otherwise Compensable) to the taxonomy, confirming no common LLM actions fall outside. This addition supports the existing impossibility proof without altering its logic. revision: yes
-
Referee: [Revision Absorber algorithm section] The structural optimality of the Revision Absorber under 'mild assumptions' is load-bearing for the algorithmic contribution; these assumptions must be stated verbatim and their mildness justified with respect to realistic LLM agent action spaces, as they directly determine whether the Earliest-Conflict Rollback rule is optimal.
Authors: The referee is correct that the assumptions were referenced but not enumerated verbatim. In the revised manuscript we will state them explicitly in the Revision Absorber section: (1) action conflicts are detectable from the reversibility taxonomy labels; (2) rollback to the earliest conflict preserves causality and does not introduce new conflicts; (3) rollback cost is linear in the number of rolled-back steps. We will justify their mildness by observing that these hold for standard LLM agent action spaces (discrete tool calls and state updates with observable effects and taxonomy labels). Under these conditions the Earliest-Conflict Rollback rule is structurally optimal because any later rollback would waste strictly more completed work while achieving the same final state. This clarification will make the optimality claim precise without changing the result. revision: yes
Circularity Check
No significant circularity identified
full rationale
The derivation begins by defining the stream paradigm and introducing an explicit four-way reversibility taxonomy (Idempotent, Reversible, Compensable, Irreversible) that classifies actions by their intrinsic properties. From this taxonomy the paper directly derives the bounding of flexibility by reversibility, the unavoidable adaptation costs for conflicting compensable actions, and the impossibility of full specification satisfaction for conflicting irreversible actions; these results are presented as consequences of action-space conflicts rather than algorithmic choices. The Revision Absorber is then constructed as a reactive algorithm whose structural optimality is proven under separately stated mild assumptions, without the optimality claim reducing to a fitted parameter, self-definition, or self-citation chain. Empirical results on StreamBench are described as validation of the pre-existing theoretical predictions, not as the source of those predictions. No load-bearing step equates a claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper Mild assumptions under which the Revision Absorber is structurally optimal
invented entities (2)
-
Reversibility taxonomy (Idempotent, Reversible, Compensable, Irreversible)
no independent evidence
-
Revision Absorber algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
work page internal anchor Pith review arXiv
-
[2]
https://arxiv. org/abs/2412.19437. 10 Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a generalist agent for the web. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track,
work page internal anchor Pith review arXiv
-
[3]
G-Eval: NLG evaluation using GPT-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG evaluation using GPT-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2511–2522,
2023
-
[4]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. WebGPT: Browser-assisted question-answering with human feedback.arXiv preprint arXiv...
work page internal anchor Pith review arXiv
-
[5]
https://arxiv.org/abs/ 2303.08774. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to fo...
work page internal anchor Pith review arXiv
-
[6]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334,
work page internal anchor Pith review arXiv
-
[7]
InThe F ourteenth International Conference on Learning Representations
12 Yijia Shao, Vinay Samuel, Yucheng Jiang, John Yang, and Diyi Yang. Collaborative gym: A frame- work for enabling and evaluating human-agent collaboration.arXiv preprint arXiv:2412.15701,
-
[8]
Toolalpaca: Generalized tool learning for language models with 3000 simulated cases
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, and Le Sun. ToolAlpaca: General- ized tool learning for language models with 3000 simulated cases.arXiv preprint arXiv:2306.05301,
-
[9]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cris- tian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Har...
work page internal anchor Pith review arXiv
-
[10]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation framework. arXiv preprint arXiv:2308.08155,
work page internal anchor Pith review arXiv
-
[11]
The Rise and Potential of Large Language Model Based Agents: A Survey
13 Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou, Rongx- iang Weng, Wensen Cheng, Qi Zhang, Wenjuan Qin, Yongyan Zheng, Xipeng Qiu, Xuanjing Hua...
work page internal anchor Pith review arXiv
-
[12]
16 Table 6: Per-scenario results on DeepSeek-V3 (each cell: Q / wasted-acts)
visualizes the same structure. 16 Table 6: Per-scenario results on DeepSeek-V3 (each cell: Q / wasted-acts). Event Planning has the most K-class actions (5 of 15 steps), so Full-Restart pays the highest waste penalty there. The Absorber’s waste remains at∼0.7regardless of scenario structure. Scenario Oracle Absorber Full Restart Naive Ignore Event Plannin...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.