Recognition: unknown
Hamiltonian Graph Inference Networks: Joint structure discovery and dynamics prediction for lattice Hamiltonian systems from trajectory data
Pith reviewed 2026-05-08 06:23 UTC · model grok-4.3
The pith
Hamiltonian Graph Inference Networks jointly recover unknown interaction graphs and predict long-time trajectories from data for lattice Hamiltonian systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HGIN couples a structure-learning module, consisting of a learnable weighted adjacency matrix trained under a Hamilton's-equations loss, with a trajectory-prediction module that partitions edges into physically distinct subgraphs via k-means clustering and assigns each subgraph its own encoder. On a Klein-Gordon lattice with long-range interactions and two discrete nonlinear Schrödinger lattices (one homogeneous, one heterogeneous), this yields reductions in long-time energy and trajectory prediction error of six to thirteen orders of magnitude relative to baselines. A symmetry argument on the Hamiltonian loss shows that the learned weights encode the parity of the pair potential.
What carries the argument
Learnable weighted adjacency matrix trained under Hamilton's equations loss, combined with k-means clustering of edges into subgraphs each assigned a dedicated encoder.
If this is right
- Joint recovery of graph structure and dynamics becomes possible from trajectory data alone without assuming separability or node homogeneity.
- Long-time prediction accuracy improves by many orders of magnitude on standard lattice benchmarks compared with graph-based baselines.
- The parity of the pair potential can be read out directly from the learned edge weights via the symmetry of the Hamiltonian loss.
- Parameter-sharing limitations of standard GNNs are broken by assigning separate encoders to physically clustered subgraphs.
Where Pith is reading between the lines
- The same joint-inference strategy could be applied to other physical domains where a known conservation law can serve as the training loss.
- Clustering edges by learned weights might reveal multi-range or multi-body interaction scales in more complex lattices or networks.
- Extending the method to noisy or partially observed trajectories would test its usefulness on real experimental data from optics or biophysics.
Load-bearing premise
Enforcing Hamilton's equations as a training loss on a learnable adjacency matrix recovers the true interaction structure for non-separable Hamiltonians and heterogeneous nodes without the clustering step introducing artifacts that harm long-term stability.
What would settle it
Training HGIN on a new synthetic lattice whose non-separable Hamiltonian and heterogeneous node parameters are known in advance, then checking whether the recovered adjacency matrix matches the true interactions and whether energy and trajectories remain accurate over thousands of time steps.
Figures





read the original abstract
Lattice Hamiltonian systems underpin models across condensed matter, nonlinear optics, and biophysics, yet learning their dynamics from data is obstructed by two unknowns: the interaction topology and whether node dynamics are homogeneous. Existing graph-based approaches either assume the graph is given or, as in $\alpha$-separable graph Hamiltonian network, infer it only for separable Hamiltonians with homogeneous node dynamics. We introduce the Hamiltonian Graph Inference Network (HGIN), which jointly recovers the interaction graph and predicts long-time trajectories from state data alone, for both separable and non-separable Hamiltonians and under heterogeneous node dynamics. HGIN couples a structure-learning module -- a learnable weighted adjacency matrix trained under a Hamilton's-equations loss -- with a trajectory-prediction module that partitions edges into physically distinct subgraphs via $k$-means clustering, assigning each subgraph its own encoder and thereby breaking the parameter-sharing bottleneck of conventional GNNs. On three benchmarks -- a Klein--Gordon lattice with long-range interactions and two discrete nonlinear Schr\"odinger lattices (homogeneous and heterogeneous) -- HGIN reduces long-time energy prediction error and trajectory prediction error by six to thirteen orders of magnitude relative to baselines. A symmetry argument on the Hamiltonian loss further shows that the learned weights encode the parity of the underlying pair potential, yielding an interpretable readout of the system's interaction structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Hamiltonian Graph Inference Network (HGIN) for jointly recovering the unknown interaction graph and predicting long-time trajectories in lattice Hamiltonian systems from state data. It couples a learnable weighted adjacency matrix trained solely under a Hamilton's-equations loss with k-means clustering of edges to create separate encoders per subgraph, thereby addressing both separable/non-separable Hamiltonians and homogeneous/heterogeneous node dynamics. On three benchmarks (Klein-Gordon lattice with long-range interactions and homogeneous/heterogeneous discrete nonlinear Schrödinger lattices), HGIN is reported to reduce long-time energy and trajectory prediction errors by six to thirteen orders of magnitude relative to baselines, while a symmetry argument on the Hamiltonian loss shows that the learned edge weights encode the parity of the underlying pair potential.
Significance. If the performance claims prove robust, the work would be significant for data-driven modeling of physical lattice systems where both topology and node homogeneity are unknown a priori. The non-circular symmetry argument provides a useful interpretability tool, and the joint structure-discovery plus dynamics-prediction formulation extends beyond prior graph Hamiltonian networks that assume separability or given graphs.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: the central claim of 6–13 order-of-magnitude reductions in long-time energy and trajectory errors lacks supporting details on baseline implementations (e.g., how the α-separable graph Hamiltonian network and other GNN baselines were trained and tuned), data splits, hyperparameter sensitivity, or statistical significance across multiple random seeds. Without these, the evidential support for the performance advantage remains limited.
- [Method (structure-learning and clustering)] Method section on structure-learning module and clustering: the k-means partitioning of the converged weighted adjacency matrix is performed once in an unsupervised manner after training. For the heterogeneous discrete nonlinear Schrödinger benchmark, it is unclear whether this step correctly isolates physically distinct interaction types or injects partitioning artifacts that affect the parameter-sharing bottleneck and long-term rollout stability; the symmetry argument addresses only parity encoding and does not speak to clustering correctness.
- [Symmetry argument] Symmetry argument (derived from the Hamiltonian loss): while non-circular, the manuscript should explicitly verify that the parity-encoding property of the learned weights survives the downstream clustering step and separate encoders when the Hamiltonian is non-separable.
minor comments (2)
- [Notation and Methods] Clarify initialization, regularization, and convergence criteria for the learnable adjacency matrix in the methods section.
- [Figures] Trajectory and energy plots should explicitly mark the training horizon versus long-time extrapolation to substantiate the stability claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us improve the clarity and evidential support of the manuscript. We address each major comment below and have incorporated revisions to strengthen the presentation of results, methodological details, and interpretability arguments.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claim of 6–13 order-of-magnitude reductions in long-time energy and trajectory errors lacks supporting details on baseline implementations (e.g., how the α-separable graph Hamiltonian network and other GNN baselines were trained and tuned), data splits, hyperparameter sensitivity, or statistical significance across multiple random seeds. Without these, the evidential support for the performance advantage remains limited.
Authors: We agree that additional implementation and statistical details are needed to robustly support the performance claims. In the revised manuscript, we have substantially expanded the Experiments section and added a dedicated 'Implementation Details' subsection. This includes: full specifications of baseline architectures and training procedures (including optimizer, learning rates, and early stopping criteria); hyperparameter tuning methodology with the ranges explored; data split protocols (temporal train/validation/test divisions with ratios); and all quantitative results now reported as means ± standard deviations over five independent random seeds. Hyperparameter sensitivity analyses and ablation tables have been moved to the supplementary material. These changes provide the requested context and establish statistical significance for the reported error reductions. revision: yes
-
Referee: [Method (structure-learning and clustering)] Method section on structure-learning module and clustering: the k-means partitioning of the converged weighted adjacency matrix is performed once in an unsupervised manner after training. For the heterogeneous discrete nonlinear Schrödinger benchmark, it is unclear whether this step correctly isolates physically distinct interaction types or injects partitioning artifacts that affect the parameter-sharing bottleneck and long-term rollout stability; the symmetry argument addresses only parity encoding and does not speak to clustering correctness.
Authors: We acknowledge the concern about potential artifacts from the post-training k-means step in the heterogeneous case. While the original experiments showed that the partitions aligned with distinct interaction types and yielded stable rollouts, we have added targeted analyses in the revised manuscript to address this directly. Specifically, we include: (1) robustness checks of k-means to random initializations and choice of k, with quantitative alignment metrics (e.g., adjusted Rand index) against ground-truth interaction groupings; (2) ablations comparing rollout stability and error when using the learned clusters versus random or incorrect partitions; and (3) visualizations confirming that clusters separate physically meaningful subgraphs without degrading the parameter-sharing benefits. These additions demonstrate that clustering isolates distinct types without introducing detrimental artifacts, while the symmetry argument remains focused on parity as noted. revision: yes
-
Referee: [Symmetry argument] Symmetry argument (derived from the Hamiltonian loss): while non-circular, the manuscript should explicitly verify that the parity-encoding property of the learned weights survives the downstream clustering step and separate encoders when the Hamiltonian is non-separable.
Authors: We appreciate this request for explicit verification in the non-separable setting. The symmetry argument follows directly from the structure of the Hamiltonian loss and applies to the learned weights independently of subsequent processing. In the revised manuscript, we have added a dedicated paragraph and supplementary proof showing that the parity-encoding property is preserved after clustering and per-subgraph encoders: because the loss is computed on the full predicted trajectories (which use the clustered encoders), the symmetry constraint on the weights remains enforced. We provide both a formal argument and empirical confirmation on the non-separable benchmark, confirming that the interpretability readout holds post-clustering. revision: yes
Circularity Check
No circularity: empirical results and symmetry argument are independent of inputs
full rationale
The paper's core contributions are an architecture (learnable adjacency + Hamilton loss + k-means partitioning into per-subgraph encoders) and benchmark evaluations showing large error reductions on specific lattices. The symmetry argument is presented as a mathematical consequence of the loss form rather than a fitted output renamed as prediction. No derivation step equates a claimed result to its training inputs by construction, no self-citation chain bears the central claim, and no uniqueness theorem is invoked to force the method. Performance numbers are data-driven and falsifiable on held-out rollouts; the clustering step is an unsupervised post-processing choice whose validity is assessed empirically rather than derived tautologically.
Axiom & Free-Parameter Ledger
free parameters (2)
- learnable weighted adjacency matrix
- k in k-means clustering of edges
axioms (2)
- domain assumption The observed dynamics obey Hamilton's equations
- domain assumption Interactions can be represented by a single weighted adjacency matrix
Reference graph
Works this paper leans on
-
[1]
Stan- dard GNN methods require prior knowledge of the graph structure; our approach does not
Our model learns the potential interactions among system particles under the assumption that only trajectory data is available. Stan- dard GNN methods require prior knowledge of the graph structure; our approach does not
-
[2]
3) Our model can identify whether the system exhibits heterogeneous node dynamics and perform clas- sification accordingly
Our model applies to both separable and non-separable Hamiltonian systems. 3) Our model can identify whether the system exhibits heterogeneous node dynamics and perform clas- sification accordingly. The remainder of the paper is organized as follows. Sec. II introduces the mathematical framework. Sec. III describes HGIN. Sec. IV reports numerical results, ...
-
[3]
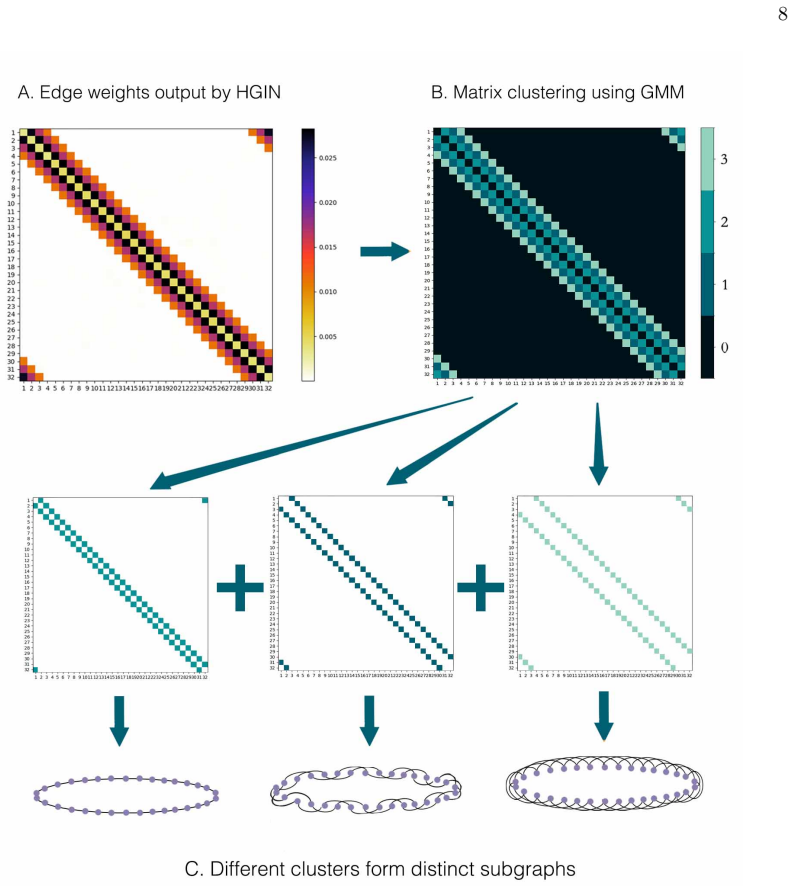
Subgraph classification The structural learning module outputs a weighted adjacency matrix Wθ = (wij), where each entry wij ∈ R quantifies the interaction strength between particles α i and α j. The weighted adjacency matrix has the following empirically observed property: Property 1 If the interaction potential be- tween particles α i and α j satisfies Vij(...
-
[4]
Per-subgraph Hamiltonian Reusing the node and edge features ( 1) and ( 2), we assign each off-diagonal cluster Co k its own edge encoder gk enc and each diagonal cluster Cd k its own node encoder gk noc, writing H(t) 1 = v∑ k=1 ∑ (i,j )∈C o k wijgk enc(e(t) ij ), (6) H(t) 2 = u∑ k=1 ∑ i∈C d k gk noc(n(t) i ), (7) H(t) = H(t) 1 + H(t) 2 . (8) Distinct encod...
-
[5]
Trajectory prediction Once trained, the learned Hamiltonian de- fines a vector field through Hamilton’s equa- tions; integrating this field from any initial con- dition ( q0, p0) yields the predicted trajectory (ˆqt, ˆpt) = ( q0, p0) + ∫ t t0 ( ∂H ∂p, − ∂H ∂q ) ds. (10) IV. COMPUTATIONAL RESULTS We evaluate HGIN on three lattice Hamilto- nian benchmarks span...
-
[6]
10, matching the coefficients of the three coupling terms in Eq
15 : 0. 10, matching the coefficients of the three coupling terms in Eq. ( 11). The diagonal entries is classified into one class and absorb the on- site kinetic and potential terms 1 2p2 + 1 2q2 + 1 4q4 into a single node-encoder cluster. Thus the four non-noise clusters reproduce the four dis- tinct functional forms of the true Hamiltonian without any prio...
-
[7]
The weights be- tween particle pairs (α 5,α 10) and (α 6,α 12) are 10 FIG
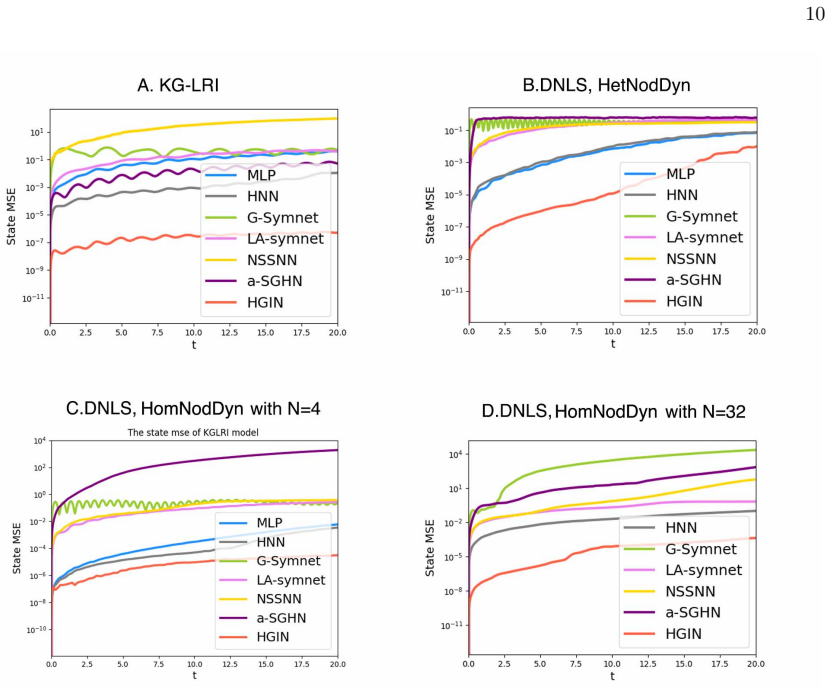
where 2(pnpn+1 + qnqn+1 +pnpn+3 +qnqn+3)). The weights be- tween particle pairs (α 5,α 10) and (α 6,α 12) are 10 FIG. 3. Average MSE of predicted trajectories over time on 30 test samples (y-axis on a logarithmic scale). Panel A: KG-LRI (Sec. IV A). Panel B: Heterogenous DNLS (Sec. IV C). Panels C and D: homogeneous DNLS with N=4 and N=32 (Sec. IV B). In ...
2000
-
[8]
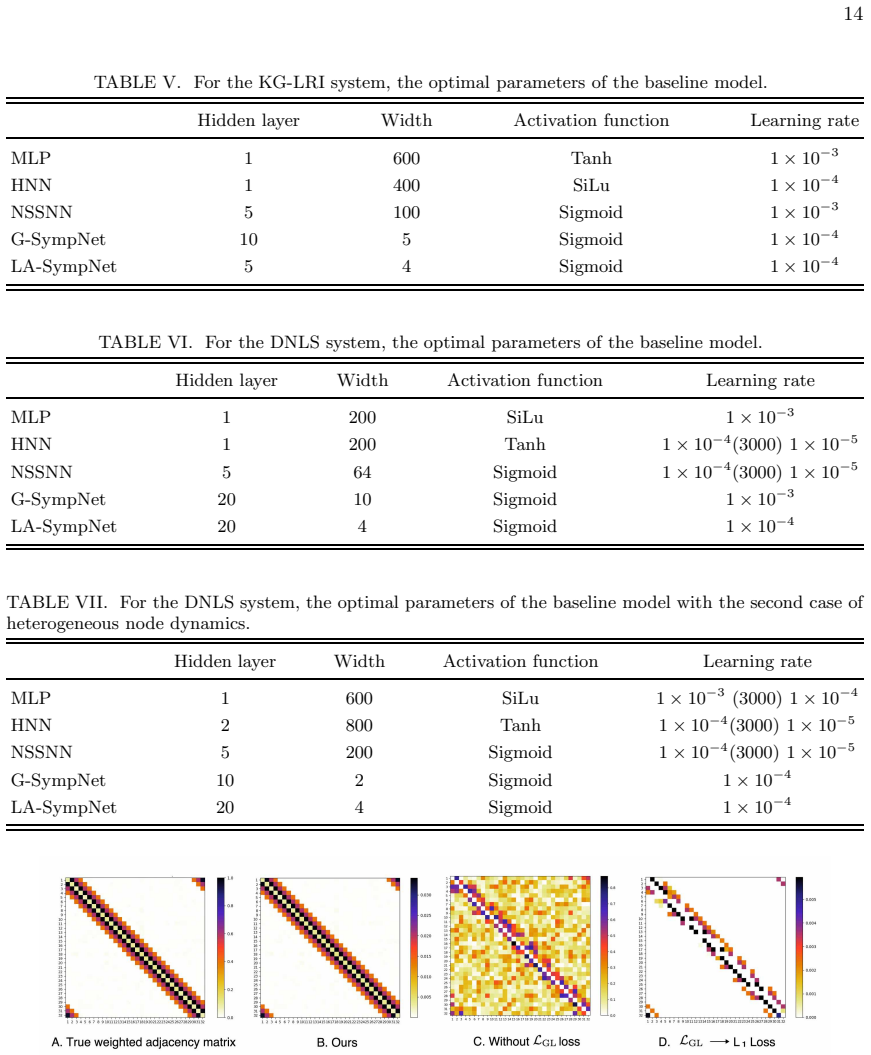
Replacement of the graph learning loss In this subsection, we test the importance of the LGL setting. Fig. 5 presents a compari- son of the system’s weighted adjacency matrices learned under different LGL settings. Clearly, only our method learns weights that are consis- tent with the ground truth
-
[9]
Comparison of weighted adjacency matrix module configurations In this subsection, we test the importance of the adjacency matrix weight learning setup. We replace the learning approach for the weights wij in our model with Graph Attention Neural Network (GAT) [ 49], Neural Relational Infer- ence (NRI) [ 50], and Transformer architecture [51], respectively,...
-
[10]
The learned weighted adjacency ma- trices are shown in Fig
Comparison of structural learning methods In this section, we compare our structure learning method with those of Equivariant Multi-agent Motion Prediction (EqMotion) [ 52] and NRI. The learned weighted adjacency ma- trices are shown in Fig
-
[11]
Appendix D: The importance of subgraph learning To isolate the contribution of the subgraph learning strategy, we train an ablation variant which we call HGIN-oracle
Clearly, only our method correctly captures the interactions and their intensity relationships within the system. Appendix D: The importance of subgraph learning To isolate the contribution of the subgraph learning strategy, we train an ablation variant which we call HGIN-oracle. In HGIN-oracle, the weighted adjacency matrix Wθ is fixed. To be more precise...
-
[12]
Lewenstein, A
M. Lewenstein, A. Sanpera, V. Ahufinger, B. Damski, A. Sen, and U. Sen, Ultracold atomic gases in optical lattices: mimicking con- densed matter physics and beyond, Advances in Physics 56, 243 (2007)
2007
-
[13]
Jiao and G
Y. Jiao and G. Xu, PEPX-type lattice design and optimization for the high energy photon source, Chinese Physics C 39, 067004 (2015)
2015
-
[14]
Bruneton and J
J.-P. Bruneton and J. Larena, Dynamics of a lattice Universe: the dust approximation in 16 TABLE VIII. KG-LRI benchmark: train loss, test loss, and ene rgy MSE in 20s (twice the training horizon), averaged over 30 trajectories. Train loss Test loss Energy MSE HGIN-oracle 3.14 × 10− 7 3.14× 10− 7 9.77× 10− 4 HGIN 2. 03 × 10− 8 2. 39 × 10− 8 1. 53 × 10− 7 F...
2012
-
[15]
F. W. Zok, Integrating lattice materials sci- ence into the traditional processing–structure– properties paradigm, Mrs Communications 9, 1284 (2019)
2019
-
[16]
J. P. Coe, Lattice density-functional theory for quantum chemistry, Physical Review B 99, 165118 (2019)
2019
-
[17]
Ramakrishna and G
D. Ramakrishna and G. Bala Murali, Bio- inspired 3D-printed lattice structures for en- ergy absorption applications: A review, Pro- ceedings of the Institution of Mechanical En- gineers, Part L: Journal of Materials: Design and Applications 237, 503 (2023)
2023
-
[18]
J. Hu, D. Chen, and P. Liang, A novel interval three-way concept lattice model with its ap- plication in medical diagnosis, Mathematics 7, 103 (2019)
2019
-
[19]
J. Adriazola, P. G. Kevrekidis, V. Koukouloy- annis, and W. Zhu, Machine learning of non- linear waves: Data-driven methods for comput- er-assisted discovery of equations, symmetries, conservation laws, and integrability (2025), arXiv:2510.15069
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Y. Gao, R. Geng, P. Kevrekidis, H.-K. Zhang, and J. Zu, α -separable graph hamiltonian net- work: A robust model for learning particle in- teractions in lattice systems, Physical Review E 111, 015309 (2025)
2025
-
[21]
S. Saqlain, W. Zhu, E. G. Charalam- pidis, and P. G. Kevrekidis, Discovering governing equations in discrete systems us- ing PINNs, arXiv preprint arXiv:2212.00971 10.48550/arXiv.2212.00971 (2022)
-
[22]
S. L. Brunton, J. L. Proctor, and J. N. Kutz, Discovering governing equations from data by sparse identification of nonlinear dynamical systems, Proceedings of the National Academy of Sciences 113, 3932 (2016)
2016
-
[23]
S. H. Rudy, S. L. Brunton, J. L. Proctor, and J. N. Kutz, Data-driven discovery of par- tial differential equations, Science Advances 3, e1602614 (2017)
2017
-
[24]
Raissi, P
M. Raissi, P. Perdikaris, and G. E. Karni- adakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear par- tial differential equations, Journal of Compu- tational Physics 378, 686 (2019) . 17 TABLE IX. Noise experiment on KG-LRI benchmark: test loss, a nd energy MSE in 20s (twice the tra...
2019
-
[25]
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang, Physics- informed machine learning, Nature Reviews Physics 3, 422 (2021)
2021
-
[26]
David and F
M. David and F. M´ ehats, Symplectic learn- ing for Hamiltonian neural networks, Journal of Computational Physics 494, 112495 (2023)
2023
-
[27]
Robinson, S
H. Robinson, S. Pawar, A. Rasheed, and O. San, Physics guided neural networks for modelling of non-linear dynamics, Neural Net- works 154, 333 (2022)
2022
-
[28]
N¨ uske, S
F. N¨ uske, S. Peitz, F. Philipp, M. Schaller, and K. Worthmann, Finite-data error bounds for Koopman-based prediction and control, Jour- nal of Nonlinear Science 33, 14 (2023)
2023
-
[29]
Radhakrishnan, M
A. Radhakrishnan, M. Belkin, and C. Uhler, Wide and deep neural networks achieve consis- tency for classification, Proceedings of the Na- tional Academy of Sciences 120, e2208779120 (2023)
2023
-
[30]
Arnold and F
J. Arnold and F. Sch¨ afer, Replacing neural net- works by optimal analytical predictors for the detection of phase transitions, Physical Review X 12, 031044 (2022)
2022
-
[31]
Ruiz-Balet and E
D. Ruiz-Balet and E. Zuazua, Neural ODE control for classification, approximation, and transport, SIAM Review 65, 735 (2023)
2023
-
[32]
Q. Cao, S. Goswami, and G. E. Karniadakis, Laplace neural operator for solving differential equations, Nature Machine Intelligence 6, 631 (2024)
2024
-
[33]
Z. Chen, V. Churchill, K. Wu, and D. Xiu, Deep neural network modeling of unknown partial differential equations in nodal space, Journal of Computational Physics 449, 110782 (2022)
2022
-
[34]
P. Y. Lu, R. Dangovski, and M. Soljaˇ ci´ c, Dis- covering conservation laws using optimal trans- port and manifold learning, Nature Communi- cations 14, 4744 (2023)
2023
-
[35]
Liu and M
Z. Liu and M. Tegmark, Machine learning con- servation laws from trajectories, Physical Re- view Letters 126, 180604 (2021)
2021
-
[36]
Saqlain, W
S. Saqlain, W. Zhu, E. G. Charalampidis, and P. G. Kevrekidis, Discovering governing equa- tions in discrete systems using PINNs, Commu- nications in Nonlinear Science and Numerical Simulation 126, 107498 (2023)
2023
-
[37]
Zvyagintseva, H
D. Zvyagintseva, H. Sigurdsson, V. K. Kozin, I. Iorsh, I. A. Shelykh, V. Ulyantsev, and O. Kyriienko, Machine learning of phase tran- sitions in nonlinear polariton lattices, Commu- nications Physics 5, 8 (2022)
2022
-
[38]
W. Zhu, W. Khademi, E. G. Charalampidis, and P. G. Kevrekidis, Neural networks enforc- ing physical symmetries in nonlinear dynami- cal lattices: The case example of the Ablowitz– Ladik model, Physica D: Nonlinear Phenomena 434, 133264 (2022)
2022
-
[39]
S. Chen, P. G. Kevrekidis, H.-K. Zhang, and W. Zhu, Data-driven discovery of conserva- tion laws from trajectories via neural deflation, Communications in Nonlinear Science and Nu- merical Simulation 143, 108563 (2025)
2025
-
[40]
P. Jin, Z. Zhang, I. G. Kevrekidis, and G. E. Karniadakis, Learning Poisson systems and trajectories of autonomous systems via Poisson neural networks, IEEE Transactions on Neu- ral Networks and Learning Systems 34, 8271 (2022)
2022
-
[41]
Atkinson, A
O. Atkinson, A. Bhardwaj, S. Brown, C. En- glert, D. J. Miller, and P. Stylianou, Improved constraints on effective top quark interactions using edge convolution networks, Journal of High Energy Physics 2022, 1 (2022)
2022
-
[42]
Bishnoi, R
S. Bishnoi, R. Bhattoo, J. Jayadeva, S. Ranu, and N. A. Krishnan, Learning the dynamics of physical systems with hamiltonian graph neural networks, in ICLR 2023 Workshop on Physics for Machine Learning (2023)
2023
-
[43]
Hamiltonian graph networks with ODE integrators.arXiv:1909.12790,
A. Sanchez-Gonzalez, V. Bapst, K. Cran- mer, and P. Battaglia, Hamiltonian graph net- works with ODE integrators, arXiv preprint arXiv:1909.12790 10.48550/arXiv.1909.12790 18 (2019)
-
[44]
M. J. Schuetz, J. K. Brubaker, and H. G. Katzgraber, Combinatorial optimization with physics-inspired graph neural networks, Nature Machine Intelligence 4, 367 (2022)
2022
-
[45]
Xiong, Y
S. Xiong, Y. Tong, X. He, S. Yang, C. Yang, and B. Zhu, Nonseparable symplectic neu- ral networks, in International Conference on Learning Representations (2021)
2021
-
[46]
Liang, V
H. Liang, V. Stanev, A. G. Kusne, and I. Takeuchi, CRYSPNet: Crystal structure pre- dictions via neural networks, Physical Review Materials 4, 123802 (2020)
2020
-
[47]
W. Gu, F. Gao, X. Lou, and J. Zhang, Link prediction via graph attention net- work, arXiv preprint arXiv:1910.04807 10.48550/arXiv.1910.04807 (2019)
-
[48]
Goodfellow, Y
I. Goodfellow, Y. Bengio, and A. Courville, Deep learning (2016)
2016
-
[49]
S. Greydanus, M. Dzamba, and J. Yosin- ski, Hamiltonian neural networks, Ad- vances in Neural Information Process- ing Systems 32 (NeurIPS 2019) 32, 10.48550/arXiv.1906.01563 (2019)
-
[50]
P. Jin, Z. Zhang, A. Zhu, Y. Tang, and G. E. Karniadakis, Sympnets: Intrinsic structure- preserving symplectic networks for identifying Hamiltonian systems, Neural Networks 132, 166 (2020)
2020
-
[51]
L. N. Sai, M. S. Shreya, A. A. Subudhi, B. J. Lakshmi, and K. Madhuri, Optimal k-means clustering method using silhouette coefficient, Int J Appl Res Inf Technol Comput 8, 335 (2017)
2017
-
[52]
Flach and A
S. Flach and A. V. Gorbach, Discrete breathers — Advances in theory and applications, Physics Reports 467, 1 (2008)
2008
-
[53]
P. G. Kevrekidis, Non-linear waves in lattices: past, present, future, IMA Journal of Applied Mathematics 76, 389 (2011)
2011
-
[54]
J. C. Eilbeck and M. Johansson, The discrete nonlinear Schr¨ odinger equation - 20 years on, Localization and Energy Transfer in Nonlinear Systems , pp. 44 (2003)
2003
-
[55]
P. G. Kevrekidis, The discrete nonlinear schr¨ odinger equation: mathematical analysis, numerical computations and physical perspec- tives, Springer Science & Business Media 232, 10.1007/978-3-540-89199-4 (2009)
-
[56]
Szameit and M
A. Szameit and M. C. Rechtsman, Dis- crete nonlinear topological photonics, Nature Physics 20, 905 (2024)
2024
-
[57]
Cruickshank, F
R. Cruickshank, F. Lorenzi, A. La Rooij, E. F. Kerr, T. Hilker, S. Kuhr, L. Salasnich, and E. Haller, Experimental observation of single- and multisite matter-wave solitons in an op- tical accordion lattice, Phys. Rev. Lett. 135, 263404 (2025)
2025
-
[58]
N. K. Efremidis and D. N. Christodoulides, Discrete solitons in nonlinear zigzag opti- cal waveguide arrays with tailored diffrac- tion properties, Physical Review E 65, 056607 (2002)
2002
-
[59]
Montavon, G
G. Montavon, G. Orr, and K.-R. M¨ uller, Neu- ral networks: tricks of the trade , Vol. 7700 (springer, 2012)
2012
-
[60]
P. Veliˇ ckovi´ c, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio, Graph attention networks, International Conference on Learning Representations 10.48550/arXiv.1710.10903 (2017)
work page internal anchor Pith review doi:10.48550/arxiv.1710.10903 2017
-
[61]
T. Kipf, E. Fetaya, K.-C. Wang, M. Welling, and R. Zemel, Neural relational inference for interacting systems, in International Confer- ence on Machine Learning (PMLR, 2018) pp. 2688–2697
2018
-
[62]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszko- reit, L. Jones, A. N. Gomez, /suppress L. Kaiser, and I. Polosukhin, Attention is all you need, Ad- vances in Neural Information Processing Sys- tems 30 (2017)
2017
-
[63]
C. Xu, R. T. Tan, Y. Tan, S. Chen, Y. G. Wang, X. Wang, and Y. Wang, Eq- motion: Equivariant multi-agent motion pre- diction with invariant interaction reasoning, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023) pp. 1410–1420
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.