Recognition: unknown
Prox-E: Fine-Grained 3D Shape Editing via Primitive-Based Abstractions
Pith reviewed 2026-05-08 05:02 UTC · model grok-4.3
The pith
Prox-E abstracts 3D shapes into geometric primitives so a vision-language model can specify precise edits that guide a generative model without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Representing an input 3D shape as a compact set of geometric primitives, editing that abstraction with a pretrained vision-language model according to text instructions, and then using the modified primitives to condition a 3D generative model produces fine-grained localized structural modifications while strictly preserving the object's overall identity and requiring no additional training.
What carries the argument
The explicit primitive-based geometric abstraction that serves as an editable intermediate representation between the vision-language model instructions and the 3D generative model.
If this is right
- Localized structural changes become possible while the overall identity of the shape is preserved.
- No additional training or fine-tuning of models is required for the editing process.
- The method outperforms both 2D-based 3D editing pipelines and training-based approaches on the joint criteria of identity preservation, shape quality, and instruction fidelity.
- Edits can be specified at the level of individual primitives for greater precision and interpretability.
Where Pith is reading between the lines
- The same primitive abstraction could be reused to improve controllability in related tasks such as 3D reconstruction from images or interactive shape design.
- Extending the set of allowed primitives to capture topological relations might enable edits that current methods still handle poorly.
- The framework could support real-time applications if the primitive extraction and editing steps are accelerated.
Load-bearing premise
Edits performed on the primitive abstraction by the vision-language model translate into accurate localized structural changes in the generative model's output without unwanted global distortions.
What would settle it
A case in which a vision-language model specifies a clear primitive-level change yet the output 3D shape either shows no corresponding local modification or exhibits distortions in regions that should remain unchanged.
Figures












read the original abstract
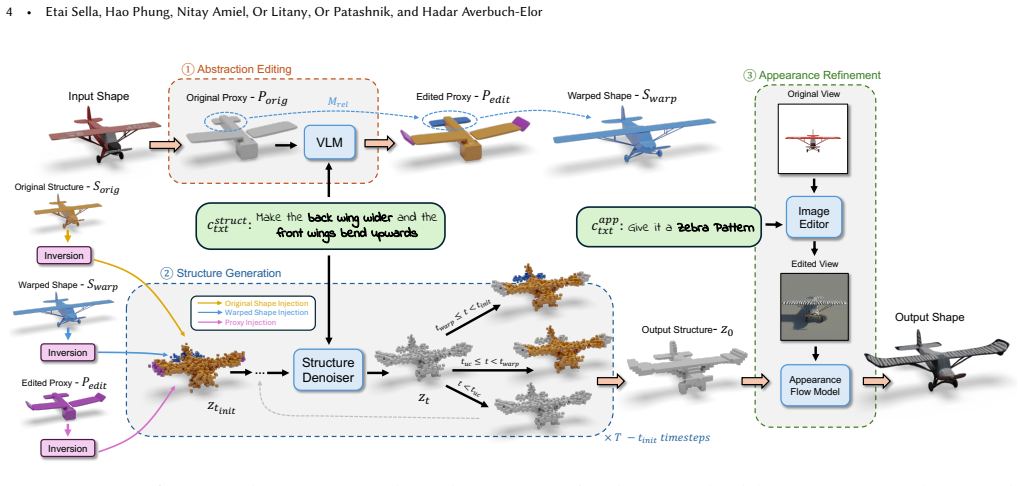
Text-based 2D image editing models have recently reached an impressive level of maturity, motivating a growing body of work that heavily depends on these models to drive 3D edits. While effective for appearance-based modifications, such 2D-centric 3D editing pipelines often struggle with fine-grained 3D editing, where localized structural changes must be applied while strictly preserving an object's overall identity. To address this limitation, we propose Prox-E, a training-free framework that enables fine-grained 3D control through an explicit, primitive-based geometric abstraction. Our framework first abstracts an input 3D shape into a compact set of geometric primitives. A pretrained vision-language model (VLM) then edits this abstraction to specify primitive-level changes. These structural edits are subsequently used to guide a 3D generative model, enabling fine-grained, localized modifications while preserving unchanged regions of the original shape. Through extensive experiments, we demonstrate that our method consistently balances identity preservation, shape quality, and instruction fidelity more effectively than various existing approaches, including 2D-based 3D editors and training-based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Prox-E, a training-free framework for fine-grained 3D shape editing. An input 3D shape is first abstracted into a compact set of geometric primitives; a pretrained VLM then edits this abstraction according to text instructions; the edited primitives are used to guide a 3D generative model, producing localized structural modifications while preserving unchanged regions and overall identity. The authors claim that extensive experiments show the method balances identity preservation, shape quality, and instruction fidelity more effectively than 2D-based 3D editors and training-based baselines.
Significance. If the central claims hold, the work would be significant for 3D content creation pipelines by offering a training-free route to structural edits that avoids the identity drift common in purely 2D-driven methods. The explicit primitive abstraction supplies interpretability and a natural interface for VLM-based control, which is a clear strength over implicit or learned editing approaches. The training-free design and use of off-the-shelf VLMs and generative models further increase applicability.
major comments (2)
- [§4.2] §4.2 (Guidance from edited primitives): The load-bearing step is the claim that VLM edits on the primitive abstraction translate into strictly localized 3D structural changes inside the generative model. The manuscript provides no formal analysis, ablation, or visualization demonstrating that the conditioning signal remains spatially selective; small inaccuracies in primitive pose or connectivity could propagate to global distortions, directly undermining the fine-grained editing guarantee.
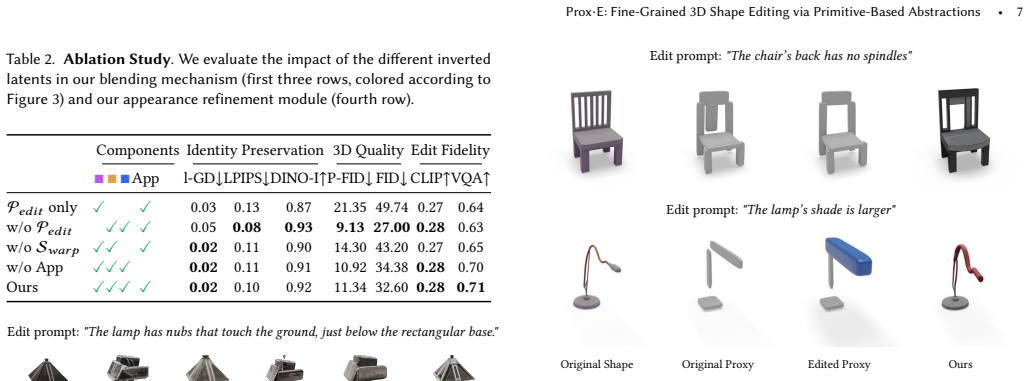
- [§5] §5 (Experiments): The superiority claim rests on quantitative comparisons, yet the text supplies no concrete metrics (e.g., identity cosine similarity, localized edit IoU, or region-preservation scores), ablation tables, or failure-case analysis. Without these, it is impossible to verify that the method actually outperforms baselines on the three-way balance asserted in the abstract.
minor comments (2)
- The abstract and method overview would benefit from explicitly naming the 3D generative model and the precise form of the conditioning signal derived from the edited primitives.
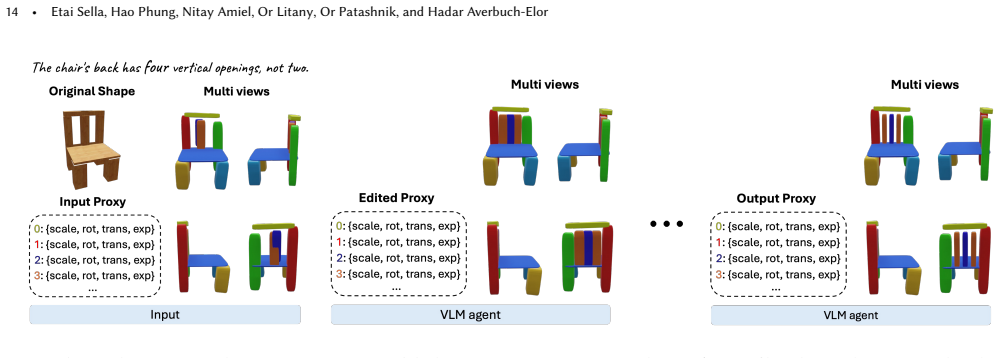
- Figure captions should clarify whether visualizations show only the final output or also intermediate primitive edits and guidance maps.
Simulated Author's Rebuttal
Thank you for your thorough review and for recognizing the potential significance of Prox-E for 3D content creation pipelines. We address each major comment below and outline revisions that will strengthen the manuscript's rigor and clarity.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Guidance from edited primitives): The load-bearing step is the claim that VLM edits on the primitive abstraction translate into strictly localized 3D structural changes inside the generative model. The manuscript provides no formal analysis, ablation, or visualization demonstrating that the conditioning signal remains spatially selective; small inaccuracies in primitive pose or connectivity could propagate to global distortions, directly undermining the fine-grained editing guarantee.
Authors: We thank the referee for highlighting this critical aspect of the method. Prox-E is designed so that the explicit primitive abstraction localizes structural changes, with the 3D generative model conditioned only on the edited primitives while original primitives guide preservation of unchanged regions. The manuscript includes qualitative visualizations of the editing pipeline and results (Section 5 and associated figures) that illustrate locality in practice. However, we agree that a dedicated formal analysis and ablation on spatial selectivity are absent. In the revised manuscript we will add an ablation study quantifying the impact of primitive pose and connectivity inaccuracies on edit locality, together with visualizations of the conditioning signals. This will provide stronger support for the fine-grained editing claim. revision: yes
-
Referee: [§5] §5 (Experiments): The superiority claim rests on quantitative comparisons, yet the text supplies no concrete metrics (e.g., identity cosine similarity, localized edit IoU, or region-preservation scores), ablation tables, or failure-case analysis. Without these, it is impossible to verify that the method actually outperforms baselines on the three-way balance asserted in the abstract.
Authors: We appreciate the referee's emphasis on verifiable quantitative evidence. The current manuscript relies primarily on qualitative comparisons and user studies to demonstrate the balance among identity preservation, shape quality, and instruction fidelity. To strengthen the evaluation, the revised Section 5 will incorporate concrete metrics including identity cosine similarity, localized edit IoU, and region-preservation scores, presented in comparison tables against baselines. We will also add ablation tables and a dedicated failure-case analysis. These additions will allow direct verification of the superiority claims. revision: yes
Circularity Check
No circularity detected in derivation or claims
full rationale
The paper describes a procedural framework: abstract input shape to primitives, apply VLM edits to the abstraction, then use those edits to condition a 3D generative model. No equations, fitted parameters, or first-principles derivations are referenced in the provided text. Claims of superior balance in identity preservation and instruction fidelity rest on experimental comparisons rather than any self-referential mapping or self-citation that reduces the result to its own inputs by construction. The implicit translation from primitive edits to localized 3D changes is presented as an empirical property validated by experiments, not a definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InConference on Computer Vision and Pattern Recognition (CVPR), Vol
ChangeIt3D: Languageassisted 3d shape edits and deformations. InConference on Computer Vision and Pattern Recognition (CVPR), Vol. 2. 6. Panos Achlioptas, Ian Huang, Minhyuk Sung, Sergey Tulyakov, and Leonidas Guibas
-
[2]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
ShapeTalk: A language dataset and framework for 3d shape edits and defor- mations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12685–12694. Armen Avetisyan, Christopher Xie, Henry Howard-Jenkins, Tsun-Yi Yang, Samir Aroudj, Suvam Patra, Fuyang Zhang, Duncan Frost, Luke Holland, Campbell Orme, et al
-
[3]
Scenescript: Reconstructing scenes with an autoregressive structured language model. InEuropean Conference on Computer Vision. Springer, 247–263. Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025). Roi Bar-On, Dan...
work page internal anchor Pith review arXiv 2025
-
[4]
William Gao, Noam Aigerman, Thibault Groueix, Vova Kim, and Rana Hanocka
Superdec: 3d scene decomposition with superquadric primitives.arXiv preprint arXiv:2504.00992(2025). William Gao, Noam Aigerman, Thibault Groueix, Vova Kim, and Rana Hanocka. 2023. Textdeformer: Geometry manipulation using text guidance. InACM SIGGRAPH 2023 Conference Proceedings. 1–11. Daniel Gilo and Or Litany. 2026. InstructMix2Mix: Consistent Sparse-V...
-
[5]
Sining Lu, Guan Chen, Nam Anh Dinh, Itai Lang, Ari Holtzman, and Rana Hanocka
EXIM: A Hybrid Explicit-Implicit Representation for Text-Guided 3D Shape Generation.ACM Transactions on Graphics (TOG)42, 6 (2023), 1–12. Sining Lu, Guan Chen, Nam Anh Dinh, Itai Lang, Ari Holtzman, and Rana Hanocka
2023
-
[6]
The target has a shorter shade
Ll3m: Large language 3d modelers.arXiv preprint arXiv:2508.08228(2025). Brandon Man, Ghadi Nehme, Md Ferdous Alam, and Faez Ahmed. 2025. VideoCAD: A Dataset and Model for Learning Long-Horizon 3D CAD UI Interactions from Video. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track. Hengyu Meng, Duotun ...
-
[7]
Provide a concise description of the specific visual elements (objects, attributes, spatial relations, or actions) that are directly relevant to this query
Visual Context Analysis Observe the images and the question. Provide a concise description of the specific visual elements (objects, attributes, spatial relations, or actions) that are directly relevant to this query
-
[8]
checkpoints
Reasoning Plan Identify the logical steps required to verify the answer. Break this down into 2-3 specific "checkpoints" or observations (e.g., identifying a specific object, then verifying its attribute, then checking its relation to others)
-
[9]
Provide a brief, evidence-based reasoning trace for each step based solely on the visual data
Step-by-Step Execution Systematically address each checkpoint from your plan. Provide a brief, evidence-based reasoning trace for each step based solely on the visual data
-
[10]
Final Answer:\nYes
Final Conclusion Based on the reasoning above, provide a definitive answer with this format Final Answer: Yes/No Note: You must end with "Final Answer:\nYes" or "Final Answer:\nNo". Before providing your answer, you must explicitly write out your reasoning, starting with the phrase'1. Visual Context Analysis:'. Fig. 10. System prompt with CoT integration ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.