Recognition: unknown
Beyond De Prado and Cotton: Hierarchical and Iterative Methods for General Mean-Variance Portfolios
Pith reviewed 2026-05-08 04:55 UTC · model grok-4.3
The pith
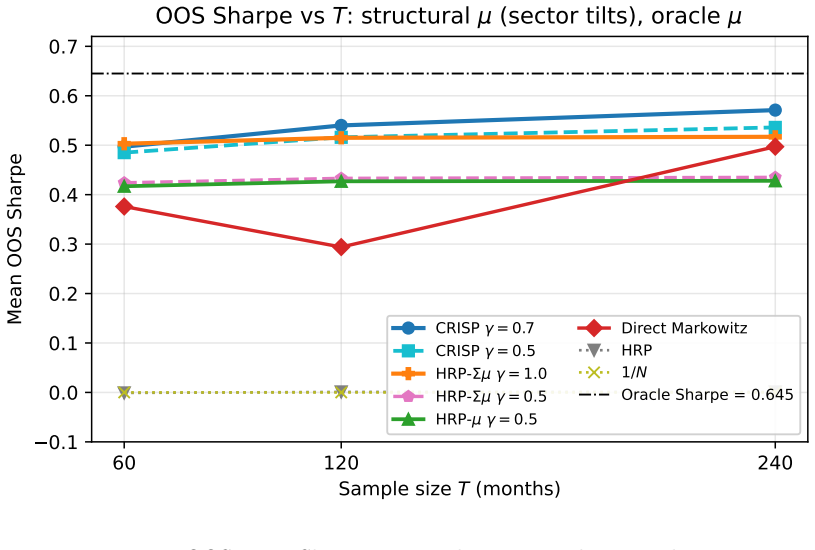
CRISP, an iterative correlation-shrinkage method, outperforms existing hierarchical and regularised approaches for mean-variance portfolios that incorporate return forecasts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The author establishes that solving the mean-variance problem iteratively on a covariance matrix whose off-diagonal elements are shrunk toward zero while diagonal variances stay fixed yields better risk-adjusted returns than hierarchical risk parity or other shrinkage techniques when return signals are present, with the shrinkage intensity chosen by out-of-sample performance rather than covariance fit.
What carries the argument
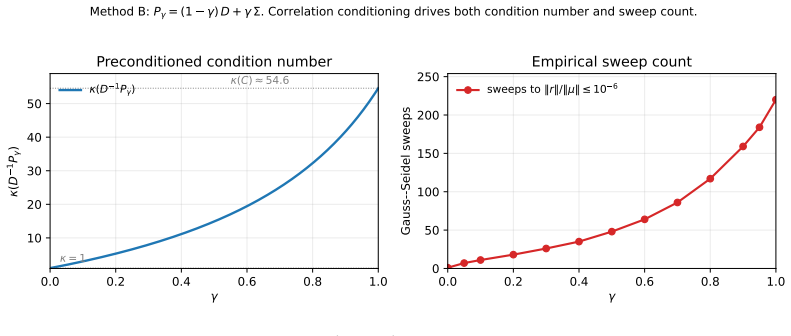
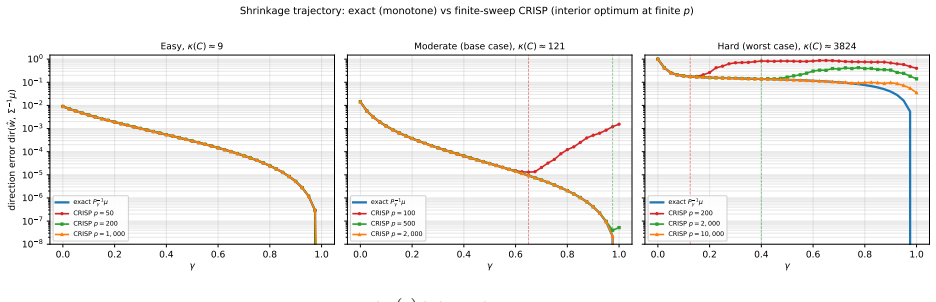
CRISP, the correlation-regularised iterative shrinkage portfolio solver that converges to the solution of P_gamma w equals mu, where P_gamma is a convex blend of the covariance matrix and its diagonal.
If this is right
- The signal-aware hierarchical methods HRP-mu and HRP-Sigma mu improve upon standard HRP while preserving its tree structure.
- CRISP is equivalent to applying Markowitz optimisation to a shrunk covariance that preserves variances but reduces correlations.
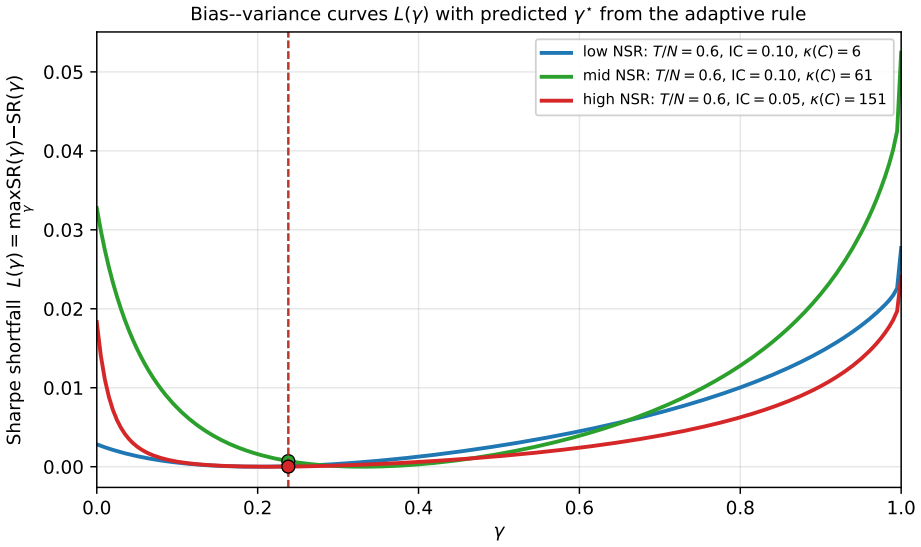
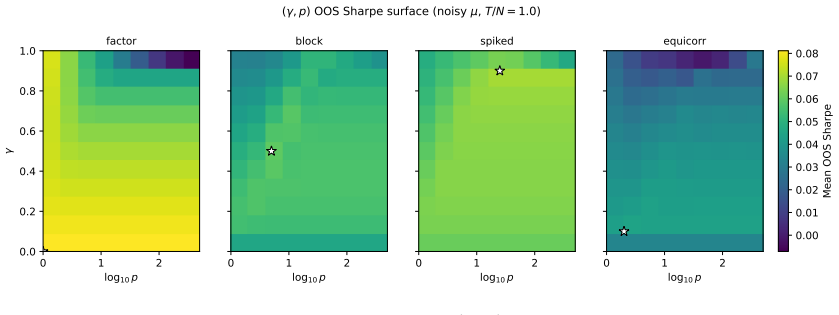
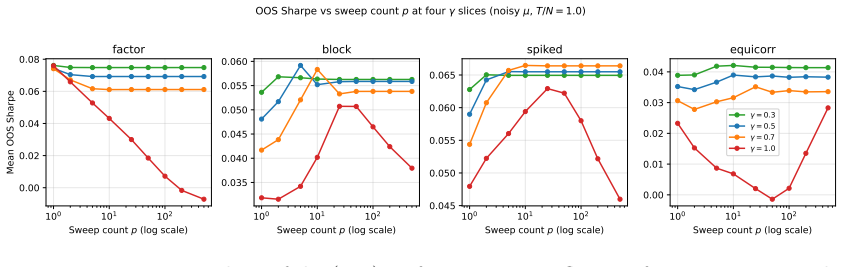
- Intermediate values of the regularisation parameter gamma in CRISP deliver the best performance in the tested Monte Carlo settings.
- The dominance of CRISP holds for both low and high ratios of observations to assets.
Where Pith is reading between the lines
- One could explore whether CRISP's gamma choice transfers across different asset classes or market regimes.
- The iterative nature of CRISP might be combined with other regularisation techniques for further gains.
- Real-market backtests would be needed to confirm if the Monte Carlo results hold without the controlled simulation assumptions.
Load-bearing premise
That the out-of-sample Sharpe ratio maximised over gamma in Monte Carlo simulations with specific covariance structures will correspond to good choices in actual financial markets.
What would settle it
A study applying the methods to historical asset returns and observing that CRISP no longer outperforms when gamma is tuned on the same out-of-sample criterion using rolling windows instead of Monte Carlo draws.
Figures


read the original abstract
Hierarchical Risk Parity (De Pardo) and the Schur-complement generalization of Cotton are among the most widely adopted regularised portfolio construction methods, yet both are signal-blind: they solve only the minimum-variance problem and cannot accommodate an arbitrary expected-return forecast. This paper introduces three methods that incorporate alpha signals into hierarchical and regularised portfolio construction. HRP-$\mu$ is a hierarchical allocator that accepts an arbitrary signal $\mu$ and nests standard HRP when $\gamma = 0$ and $\mu=\mathbf{1}$. It preserves the tree-based structure of HRP while extending it beyond the minimum-variance setting. HRP-$\Sigma\mu$ strengthens this construction by replacing inverse-variance representatives with recursive local mean-variance optima, thereby using richer within-cluster covariance information at the same $O(N^2)$ asymptotic cost. CRISP (Correlation-Regularised Iterative Shrinkage Portfolios) is an iterative solver for $P_\gamma w = \mu$ with $P_\gamma = (1-\gamma)\operatorname{diag}(\Sigma) + \gamma \Sigma$, so that $\gamma$ interpolates between a diagonal portfolio rule and full Markowitz. At convergence, CRISP is Markowitz applied to a variance-preserving shrunk covariance-diagonal variances unchanged, off-diagonal correlations shrunk-with $\gamma$ tuned for out-of-sample Sharpe rather than covariance-estimation loss. In Monte Carlo experiments across multiple covariance regimes and estimation ratios, HRP-$\mu$ and HRP-$\Sigma\mu$ both outperform plain HRP with HRP-$\Sigma\mu$ consistently improving on HRP-$\mu$. CRISP at intermediate $\gamma$ is the dominant method in both regimes, outperforming HRP, Cotton, Ledoit-Wolf shrinkage, direct Markowitz, and the signal-aware hierarchical methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two signal-aware extensions to Hierarchical Risk Parity (HRP-μ and HRP-Σμ) that incorporate arbitrary expected-return forecasts while preserving the hierarchical tree structure and O(N²) cost, and introduces CRISP, an iterative solver for the linear system P_γ w = μ where P_γ = (1-γ)diag(Σ) + γ Σ interpolates between a diagonal rule and full Markowitz. Monte Carlo experiments across covariance regimes and estimation ratios are used to claim that HRP-Σμ improves on HRP-μ (which improves on plain HRP) and that CRISP at intermediate γ dominates HRP, the Cotton Schur-complement method, Ledoit-Wolf shrinkage, direct Markowitz, and the new hierarchical variants.
Significance. If the empirical ranking can be reproduced under a protocol that selects γ without reference to the reported test Sharpe, the hierarchical extensions would usefully address the signal-blind limitation of standard HRP while retaining its interpretability and computational scaling; CRISP would supply a simple, variance-preserving shrinkage rule whose tuning can be studied separately. The preservation of exact diagonal variances under the shrinkage is a clean technical feature.
major comments (2)
- [Monte Carlo experiments] Monte Carlo experiments: the reported dominance of CRISP at intermediate γ is obtained by choosing γ to maximize realized out-of-sample Sharpe on the very simulation draws whose performance is being reported. Because this selection uses the test metric itself, the superiority over untuned baselines (HRP, Cotton, Ledoit-Wolf, direct Markowitz) is not an out-of-sample prediction and may not generalize to other data-generating processes or live markets.
- [CRISP description] CRISP definition and evaluation protocol: the abstract states that γ is tuned for out-of-sample Sharpe rather than for covariance-estimation loss. This choice makes the central performance claim a fitted quantity; any revision must either (a) fix γ on a separate validation set before reporting test Sharpe or (b) demonstrate that a single γ chosen on covariance loss alone still yields the reported ranking.
minor comments (2)
- [Abstract] Abstract: the Monte Carlo design is summarized only as “multiple covariance regimes and estimation ratios”; the manuscript should report the exact factor-model parameters, correlation lengths, N/T ratios, number of replications, and whether error bars or statistical tests accompany the Sharpe comparisons.
- [CRISP description] Notation: the claim that CRISP leaves diagonal variances unchanged while shrinking off-diagonal correlations should be accompanied by an explicit statement of the fixed-point equation and a short proof that the converged covariance has the same diagonal as the input Σ.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the experimental protocol. We agree that the current tuning of γ for CRISP requires revision to ensure strictly out-of-sample evaluation, and we will update the Monte Carlo design accordingly while preserving the contributions of the hierarchical methods.
read point-by-point responses
-
Referee: [Monte Carlo experiments] Monte Carlo experiments: the reported dominance of CRISP at intermediate γ is obtained by choosing γ to maximize realized out-of-sample Sharpe on the very simulation draws whose performance is being reported. Because this selection uses the test metric itself, the superiority over untuned baselines (HRP, Cotton, Ledoit-Wolf, direct Markowitz) is not an out-of-sample prediction and may not generalize to other data-generating processes or live markets.
Authors: We agree that selecting γ to maximize Sharpe on the same simulation draws used for reporting constitutes in-sample tuning with respect to the evaluation metric. In the revision we will introduce a nested validation procedure: for each Monte Carlo trial we will generate separate validation draws, select γ by maximizing validation Sharpe, and evaluate final performance on an independent test set. All tables and figures will be regenerated under this protocol, and the methods section will document the change. We expect the qualitative ranking to be robust, but the quantitative results will be updated to reflect the corrected procedure. revision: yes
-
Referee: [CRISP description] CRISP definition and evaluation protocol: the abstract states that γ is tuned for out-of-sample Sharpe rather than for covariance-estimation loss. This choice makes the central performance claim a fitted quantity; any revision must either (a) fix γ on a separate validation set before reporting test Sharpe or (b) demonstrate that a single γ chosen on covariance loss alone still yields the reported ranking.
Authors: We acknowledge that the present abstract and experiments tune γ directly on the out-of-sample Sharpe, rendering the performance claims fitted. We will adopt option (a) by implementing a validation-set selection of γ before test evaluation, as described above. The abstract will be revised to state that γ is chosen on a held-out validation set. For completeness we will also add a short supplementary check using a single γ selected by covariance estimation loss (Frobenius norm to the true Σ), confirming whether the reported dominance persists under that alternative rule. revision: yes
Circularity Check
CRISP dominance claim obtained by tuning γ directly on the out-of-sample Sharpe metric within the reported Monte Carlo regimes
specific steps
-
fitted input called prediction
[Abstract]
"CRISP at intermediate γ is the dominant method in both regimes, outperforming HRP, Cotton, Ledoit-Wolf shrinkage, direct Markowitz, and the signal-aware hierarchical methods. ... with γ tuned for out-of-sample Sharpe rather than covariance-estimation loss."
γ is chosen to maximize the Sharpe ratio on the identical out-of-sample Monte Carlo periods that are later used to declare CRISP dominant. The reported superiority is therefore the result of fitting the hyperparameter to the evaluation metric rather than an independent prediction or first-principles derivation.
full rationale
The paper's central empirical result—that CRISP at intermediate γ outperforms HRP, Cotton, Ledoit-Wolf, direct Markowitz and the signal-aware hierarchical methods—is produced by selecting γ to maximize realized Sharpe on the out-of-sample periods of the same simulations used for evaluation. This matches the fitted-input-called-prediction pattern: the parameter is optimized against the exact performance quantity whose superiority is then asserted. The methods themselves (HRP-μ, HRP-Σμ, CRISP definition) are derived independently without circularity, but the load-bearing claim of dominance reduces to a tuned quantity inside the experimental design. No self-citation load-bearing, self-definitional equations, or ansatz smuggling appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- gamma
axioms (2)
- domain assumption Hierarchical clustering on pairwise correlations captures economically meaningful asset groupings for allocation purposes.
- domain assumption Shrinking only off-diagonal correlations while leaving variances unchanged produces a usable regularized covariance for mean-variance optimization.
Reference graph
Works this paper leans on
-
[1]
Santa-Clara, 2015, Beyond the Carry Trade: Optimal Currency Portfolios, Journal of Financial and Quantitative Analysis 50(5), 1037--1056
Barroso, P., and P. Santa-Clara, 2015, Beyond the Carry Trade: Optimal Currency Portfolios, Journal of Financial and Quantitative Analysis 50(5), 1037--1056
2015
-
[2]
Litterman, 1992, Global Portfolio Optimization, Financial Analysts Journal 48(5), 28--43
Black, F., and R. Litterman, 1992, Global Portfolio Optimization, Financial Analysts Journal 48(5), 28--43
1992
-
[3]
Brandt, M. W., P. Santa-Clara, and R. Valkanov, 2009, Parametric Portfolio Policies: Exploiting Characteristics in the Cross-Section of Equity Returns, Review of Financial Studies 22(9), 3411--3447
2009
-
[4]
Wiesel, Y
Chen, Y., A. Wiesel, Y. C. Eldar, and A. O. Hero, 2010, Shrinkage Algorithms for MMSE Covariance Estimation, IEEE Transactions on Signal Processing 58(10), 5016--5029
2010
-
[5]
Clarabel: An interior-point solver for conic programs with quadratic objectives,
Goulart, P. J., and Y. Chen, 2024, Clarabel: An Interior-Point Solver for Conic Programs with Quadratic Objectives, arXiv preprint arXiv:2405.12762
- [6]
-
[7]
Garlappi, and R
DeMiguel, V., L. Garlappi, and R. Uppal, 2009, Optimal Versus Naive Diversification: How Inefficient is the 1/N Portfolio Strategy?, Review of Financial Studies 22(5), 1915--1953
2009
-
[8]
F., and K
Fama, E. F., and K. R. French, 1993, Common Risk Factors in the Returns on Stocks and Bonds, Journal of Financial Economics 33(1), 3--56
1993
-
[9]
Liao, and M
Fan, J., Y. Liao, and M. Mincheva, 2013, Large Covariance Estimation by Thresholding Principal Orthogonal Complements, Journal of the Royal Statistical Society, Series B 75(4), 603--680
2013
-
[10]
G\^arleanu, N., and L. H. Pedersen, 2013, Dynamic Trading with Predictable Returns and Transaction Costs, Journal of Finance 68(6), 2309--2340
2013
-
[11]
C., and R
Grinold, R. C., and R. N. Kahn, 1999, Active Portfolio Management, 2nd edition, McGraw-Hill
1999
-
[12]
Hackbusch, W., 2016, Iterative Solution of Large Sparse Systems of Equations, 2nd edition, Springer Applied Mathematical Sciences vol. 95
2016
-
[13]
Ma, 2003, Risk Reduction in Large Portfolios: Why Imposing the Wrong Constraints Helps, Journal of Finance 58(4), 1651--1683
Jagannathan, R., and T. Ma, 2003, Risk Reduction in Large Portfolios: Why Imposing the Wrong Constraints Helps, Journal of Finance 58(4), 1651--1683
2003
-
[14]
Nagel, and S
Kozak, S., S. Nagel, and S. Santosh, 2020, Shrinking the Cross-Section, Journal of Financial Economics 135(2), 271--292
2020
-
[15]
Wolf, 2003, Improved Estimation of the Covariance Matrix of Stock Returns with an Application to Portfolio Selection, Journal of Empirical Finance 10(5), 603--621
Ledoit, O., and M. Wolf, 2003, Improved Estimation of the Covariance Matrix of Stock Returns with an Application to Portfolio Selection, Journal of Empirical Finance 10(5), 603--621
2003
-
[16]
Wolf, 2004, Honey, I Shrunk the Sample Covariance Matrix, Journal of Portfolio Management 30(4), 110--119
Ledoit, O., and M. Wolf, 2004, Honey, I Shrunk the Sample Covariance Matrix, Journal of Portfolio Management 30(4), 110--119
2004
-
[17]
Wolf, 2017, Nonlinear Shrinkage of the Covariance Matrix for Portfolio Selection: Markowitz Meets Goldilocks, Review of Financial Studies 30(12), 4349--4388
Ledoit, O., and M. Wolf, 2017, Nonlinear Shrinkage of the Covariance Matrix for Portfolio Selection: Markowitz Meets Goldilocks, Review of Financial Studies 30(12), 4349--4388
2017
-
[18]
Wolf, 2020, Analytical Nonlinear Shrinkage of Large-Dimensional Covariance Matrices, Annals of Statistics 48(5), 3043--3065
Ledoit, O., and M. Wolf, 2020, Analytical Nonlinear Shrinkage of Large-Dimensional Covariance Matrices, Annals of Statistics 48(5), 3043--3065
2020
-
[19]
L\'opez de Prado, M., 2016, Building Diversified Portfolios that Outperform Out of Sample, Journal of Portfolio Management 42(4), 59--69
2016
-
[20]
L\'opez de Prado, M., and M. J. Lewis, 2019, Detection of False Investment Strategies Using Unsupervised Learning Methods, Quantitative Finance 19(9), 1555--1565
2019
-
[21]
A., and L
Marchenko, V. A., and L. A. Pastur, 1967, Distribution of Eigenvalues for Some Sets of Random Matrices, Matematicheskii Sbornik 72(4), 507--536
1967
-
[22]
Markowitz, H., 1952, Portfolio Selection, Journal of Finance 7(1), 77--91
1952
-
[23]
O., 1989, The Markowitz Optimization Enigma: Is `Optimized' Optimal?, Financial Analysts Journal 45(1), 31--42
Michaud, R. O., 1989, The Markowitz Optimization Enigma: Is `Optimized' Optimal?, Financial Analysts Journal 45(1), 31--42
1989
-
[24]
Banjac, P
Stellato, B., G. Banjac, P. Goulart, A. Bemporad, and S. Boyd, 2020, OSQP: An Operator Splitting Solver for Quadratic Programs, Mathematical Programming Computation 12(4), 637--672
2020
-
[25]
M., 1954, On the Linear Iteration Procedures for Symmetric Matrices, Rendiconti di Matematica e delle sue Applicazioni 14, 140--163
Ostrowski, A. M., 1954, On the Linear Iteration Procedures for Symmetric Matrices, Rendiconti di Matematica e delle sue Applicazioni 14, 140--163
1954
-
[26]
Raffinot, T., 2018, Hierarchical Clustering-Based Asset Allocation, Journal of Portfolio Management 44(2), 89--99
2018
-
[27]
Saad, Y., 2003, Iterative Methods for Sparse Linear Systems, 2nd edition, SIAM
2003
-
[28]
Shumway, T., 1997, The Delisting Bias in CRSP Data, Journal of Finance 52(1), 327--340
1997
-
[29]
Stein, C., 1956, Inadmissibility of the Usual Estimator for the Mean of a Multivariate Normal Distribution, Proc.\ Third Berkeley Symposium on Mathematical Statistics and Probability, 197--206
1956
-
[30]
S., 2000, Matrix Iterative Analysis, 2nd edition, Springer Series in Computational Mathematics vol
Varga, R. S., 2000, Matrix Iterative Analysis, 2nd edition, Springer Series in Computational Mathematics vol. 27
2000
-
[31]
Vershynin, R., 2012, Introduction to the Non-Asymptotic Analysis of Random Matrices, in Compressed Sensing: Theory and Applications, edited by Y. C. Eldar and G. Kutyniok, Cambridge University Press, pp. 210--268
2012
-
[32]
M., 1971, Iterative Solution of Large Linear Systems, Academic Press
Young, D. M., 1971, Iterative Solution of Large Linear Systems, Academic Press
1971
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.