Recognition: unknown
Few-Shot Cross-Device Transfer for Quantum Noise Modeling on Real Hardware
Pith reviewed 2026-05-08 04:21 UTC · model grok-4.3
The pith
A residual neural network trained on one quantum device adapts to another with 20 fine-tuning samples, improving noise prediction by 28.6 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
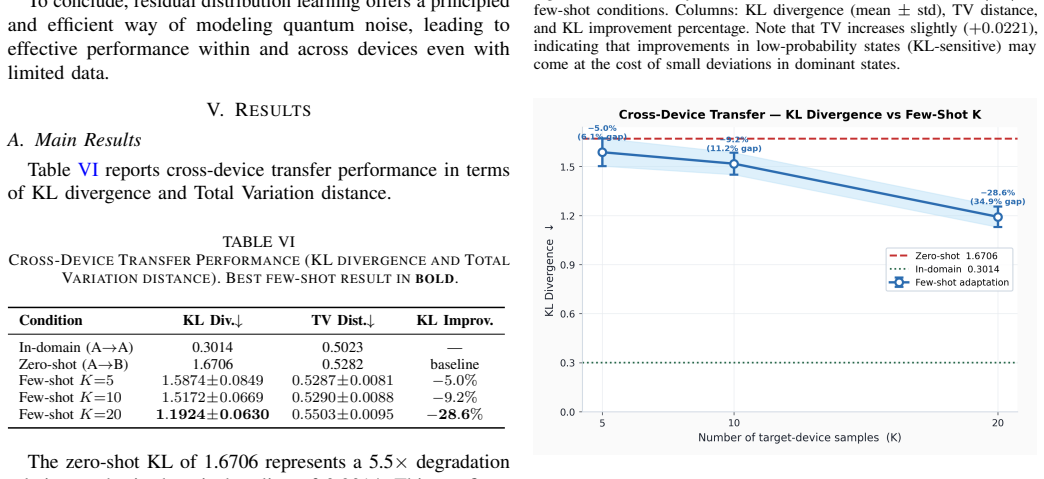
A residual neural network mapping noisy circuit distributions to ideal ones, trained on ibm_fez data, yields a KL divergence of 1.6706 on ibm_marrakesh in zero-shot transfer. After fine-tuning on 20 samples from the target device the divergence falls to 1.1924, a 28.6 percent improvement that recovers 34.9 percent of the distance to the in-domain value of 0.3014. Ablation experiments attribute the largest share of device-to-device mismatch to CX gate errors, with readout error next.
What carries the argument
Residual neural network that ingests noisy output distributions together with device calibration features and outputs corrected ideal distributions; the network supports both zero-shot application and low-sample fine-tuning across hardware.
If this is right
- Error mitigation strategies become practical across multiple devices once a base model exists and only small calibration sets are collected per machine.
- Calibration effort can be prioritized on CX gate fidelity and readout accuracy to maximize transfer success.
- Quantum noise modeling shifts from per-device full retraining toward reuse of pre-learned features plus minimal adaptation.
- The observed recovery of one-third of the in-domain performance gap suggests that few-shot methods can meaningfully lower data requirements for new hardware.
Where Pith is reading between the lines
- The same fine-tuning approach might extend to superconducting devices from other vendors if calibration features are standardized.
- Expanding the circuit set beyond 170 examples could further close the remaining performance gap to in-domain models.
- Integrating the transferred noise model with existing mitigation protocols could compound error reduction without extra hardware runs.
Load-bearing premise
The 170-circuit dataset and residual network capture noise features that are general enough to transfer, and the chosen 20 fine-tuning samples represent the target device without hidden selection effects.
What would settle it
A repeat experiment on a third device or fresh circuit set where fine-tuning on 20 samples produces no reduction in KL divergence relative to the zero-shot baseline.
Figures







read the original abstract
In the noisy intermediate-scale quantum (NISQ) regime, quantum devices contain hardware-specific noise sources which restrict device-invariant error mitigation strategies. We explore transfer learning approaches to apply noise models learned on one quantum device to a different device with the help of a small amount of data. We create a real-hardware dataset from two IBM quantum devices, ibm_fez (source) and ibm_marrakesh (target), comprising 170 noisy and ideal circuit output distributions, with device calibration features added. We train a residual neural network on the source device to map noisy to ideal outcomes. The zero-shot transfer test shows a KL divergence of 1.6706 (up from 0.3014), establishing device specificity. With K = 20 fine-tuning samples, KL drops to 1.1924 (28.6% improvement over zero-shot), recovering 34.9% of the gap between zero-shot and in-domain KL. Ablation studies reveal that the major cause of mismatches across devices is CX gate error, followed by readout error. The results show quantum noise can be learned and fine-tuned with minimal samples, and provide a plausible approach to cross-device quantum error mitigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a few-shot transfer learning approach for quantum noise modeling across NISQ devices. A residual neural network is trained on a 170-circuit dataset of noisy and ideal output distributions collected from IBM device ibm_fez (source) with added calibration features; it is then evaluated zero-shot and with K=20 fine-tuning samples on ibm_marrakesh (target). The central empirical result is that zero-shot KL divergence of 1.6706 drops to 1.1924 after fine-tuning (28.6% relative improvement), recovering 34.9% of the gap to the in-domain KL of 0.3014. Ablation studies attribute most cross-device mismatch to CX gate errors followed by readout errors.
Significance. If the reported KL improvements prove robust, the work supplies a practical route to cross-device noise modeling that requires only modest target-device data, which could support scalable error mitigation on heterogeneous quantum hardware. The use of real-device data from two IBM processors and the explicit ablation isolating CX versus readout contributions are concrete strengths that ground the transfer claim in hardware reality.
major comments (2)
- [Results section] Results section (headline KL numbers): The reported values (zero-shot KL = 1.6706, K=20 fine-tuned KL = 1.1924) are given as single scalars without error bars, averages over random seeds, or multiple random draws of the 20 fine-tuning circuits. With a modest 170-circuit corpus, any particular 20-sample subset may overfit device-specific idiosyncrasies rather than learn transferable CX/readout features; the 28.6% improvement and 34.9% gap recovery therefore cannot yet be taken as evidence of generalizable transfer without statistical characterization of selection variance.
- [Methods section] Methods / Experimental setup: The manuscript does not specify the circuit-selection protocol for the 170-circuit corpus, the precise residual-network architecture (layer count, hidden dimensions, residual connections), training hyperparameters, or the train/validation/test split used for both source training and target fine-tuning. These omissions directly affect whether the observed KL reduction can be reproduced or attributed to transferable noise features rather than post-hoc choices.
minor comments (2)
- [Abstract / Methods] The abstract states that 'device calibration features' are added to the input but does not enumerate which calibration parameters (e.g., T1, T2, gate error rates) are used or how they are normalized/encoded; this detail belongs in the methods for clarity.
- [Figures] Figure captions and axis labels for any KL-versus-K plots should explicitly state whether the curves represent single runs or averages, and whether shaded regions (if present) denote standard deviation or min/max over trials.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Results section] Results section (headline KL numbers): The reported values (zero-shot KL = 1.6706, K=20 fine-tuned KL = 1.1924) are given as single scalars without error bars, averages over random seeds, or multiple random draws of the 20 fine-tuning circuits. With a modest 170-circuit corpus, any particular 20-sample subset may overfit device-specific idiosyncrasies rather than learn transferable CX/readout features; the 28.6% improvement and 34.9% gap recovery therefore cannot yet be taken as evidence of generalizable transfer without statistical characterization of selection variance.
Authors: We agree that reporting only single scalar values limits the ability to assess robustness. In the revised manuscript we will add statistical characterization by computing the KL metrics over multiple random training seeds and multiple independent random draws of the 20-sample fine-tuning sets. We will report means and standard deviations (error bars) for both the zero-shot and fine-tuned cases to show that the observed 28.6 % improvement and 34.9 % gap recovery are stable across selections rather than artifacts of particular subsets. revision: yes
-
Referee: [Methods section] Methods / Experimental setup: The manuscript does not specify the circuit-selection protocol for the 170-circuit corpus, the precise residual-network architecture (layer count, hidden dimensions, residual connections), training hyperparameters, or the train/validation/test split used for both source training and target fine-tuning. These omissions directly affect whether the observed KL reduction can be reproduced or attributed to transferable noise features rather than post-hoc choices.
Authors: We acknowledge that the current text omits these implementation details. In the revised Methods section we will add a complete description of the circuit-selection protocol used to assemble the 170-circuit corpus, the exact residual-network architecture (layer counts, hidden dimensions, and residual-connection structure), all training hyperparameters (optimizer, learning rate, batch size, epochs, regularization), and the precise train/validation/test splits applied during source training and target fine-tuning. These additions will enable full reproducibility and clarify that performance gains arise from transferable features. revision: yes
Circularity Check
No significant circularity: empirical KL results are independent held-out measurements
full rationale
The paper reports direct empirical measurements of KL divergence between model outputs and ideal circuit distributions on held-out test circuits from real hardware. The zero-shot and fine-tuned KL values (1.6706 and 1.1924) are computed on separate data splits after training/fine-tuning the residual network; they are not algebraically or definitionally equivalent to the training inputs, loss function, or selected fine-tuning subset. No equations, self-citations, uniqueness theorems, or ansatzes are present that would reduce the reported improvement to a fitted quantity by construction. The evaluation metric remains external to the model parameters.
Axiom & Free-Parameter Ledger
free parameters (1)
- K (number of fine-tuning samples)
axioms (1)
- domain assumption Noise characteristics of a quantum device are sufficiently stationary and learnable from circuit output distributions to allow a neural network to map noisy to ideal outcomes.
Reference graph
Works this paper leans on
-
[1]
Quantum Computing in the NISQ era and beyond.Quantum, 2:79, August 2018
J. Preskill, “Quantum computing in the NISQ era and beyond,” Quantum, vol. 2, p. 79, 2018, arXiv:1801.00862. [Online]. Available: https://doi.org/10.22331/q-2018-08-06-79
-
[2]
Stability of noisy quantum computing devices,
S. Dasgupta and T. S. Humble, “Stability of noisy quantum computing devices,” 2021, arXiv:2105.09472. [Online]. Available: https://arxiv.org/abs/2105.09472
-
[3]
https://doi.org/10.1103/PhysRevX.7.021050
Y . Li and S. C. Benjamin, “Efficient variational quantum simulator incorporating active error minimization,”Physical Review X, vol. 7, p. 021050, 2017, arXiv:1611.09301. [Online]. Available: https: //doi.org/10.1103/PhysRevX.7.021050
-
[4]
K. Temme, S. Bravyi, and J. M. Gambetta, “Error mitigation for short-depth quantum circuits,”Physical Review Letters, vol. 119, p. 180509, 2017, arXiv:1612.02058. [Online]. Available: https: //doi.org/10.1103/PhysRevLett.119.180509
-
[5]
Error mitigation with clifford quantum-circuit data,
P. Czarnik, A. Arrasmith, P. J. Coles, and L. Cincio, “Error mitigation with clifford quantum-circuit data,”Quantum, vol. 5, p. 592, 2021, arXiv:2005.10189. [Online]. Available: https://doi.org/10.22331/ q-2021-11-26-592
-
[6]
Z. Duet al., “From noise modeling to layout optimization: A framework for quantum circuit fidelity enhancement with machine learning,” Advanced Quantum Technologies, vol. 9, no. 3, p. e00464, 2026. [Online]. Available: https://doi.org/10.1002/qute.202500464
-
[7]
IEEE Transactions on Knowledge and Data Engineering 22, 1345–1359
S. J. Pan and Q. Yang, “A survey on transfer learning,”IEEE Transactions on Knowledge and Data Engineering, vol. 22, no. 10, pp. 1345–1359, 2010, IEEE Xplore: 5288526. [Online]. Available: https://doi.org/10.1109/TKDE.2009.191
-
[8]
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inProceedings of the 34th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 70. PMLR, 2017, pp. 1126–1135, arXiv:1703.03400. [Online]. Available: https: //proceedings.mlr.press/v70/finn17a.html
work page Pith review arXiv 2017
-
[9]
https://doi.org/10.1103/PRXQuantum.2.040330
A. Strikis, D. Qin, Y . Chen, S. C. Benjamin, and Y . Li, “Learning-based quantum error mitigation,”PRX Quantum, vol. 2, p. 040330, 2021, arXiv:2005.07601. [Online]. Available: https: //doi.org/10.1103/PRXQuantum.2.040330
-
[10]
Suppressing quantum circuit errors due to system variability,
P. D. Nation and M. Treinish, “Suppressing quantum circuit errors due to system variability,”PRX Quantum, vol. 4, p. 010327, 2023. [Online]. Available: https://doi.org/10.1103/PRXQuantum.4.010327 APPENDIX All experiments use IBM Quantum real hardware accessed via Qiskit IBM Runtime. All 85 circuits per backend are submitted as a single batch job to minimi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.