Recognition: unknown
A Reward-Free Viewpoint on Multi-Objective Reinforcement Learning
Pith reviewed 2026-05-08 03:59 UTC · model grok-4.3
The pith
Adapting reward-free RL as an auxiliary task improves multi-objective policy learning across user preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By using the RFRL training objective as an auxiliary task and introducing preference-guided exploration, the adapted algorithm learns policies that generalize across preference vectors more effectively than methods that condition only on the given multi-objective reward function.
What carries the argument
The RFRL training objective employed as an auxiliary task together with a preference-guided exploration strategy inside the MORL training loop.
Load-bearing premise
That adding the RFRL auxiliary objective will produce useful knowledge sharing without creating instabilities or biases that hurt the primary multi-objective objective.
What would settle it
Direct experiments on the same MO-Gymnasium tasks showing that the proposed method yields no improvement or worse performance and data efficiency than standard preference-conditioned MORL baselines.
Figures



















read the original abstract
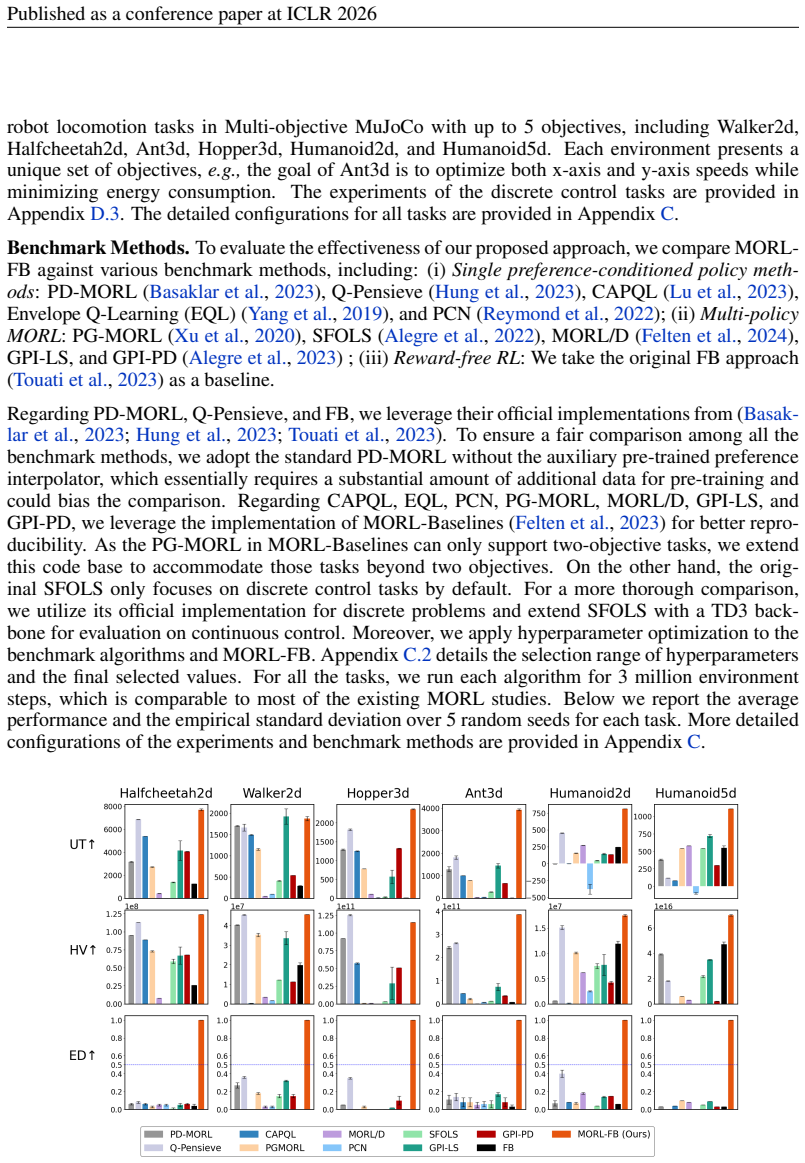
Many sequential decision-making tasks involve optimizing multiple conflicting objectives, requiring policies that adapt to different user preferences. In multi-objective reinforcement learning (MORL), one widely studied approach} addresses this by training a single policy network conditioned on preference-weighted rewards. In this paper, we explore a novel algorithmic perspective: leveraging reward-free reinforcement learning (RFRL) for MORL. While RFRL has historically been studied independently of MORL, it learns optimal policies for any possible reward function, making it a natural fit for MORL's challenge of handling unknown user preferences. We propose using the RFRL's training objective as an auxiliary task to enhance MORL, enabling more effective knowledge sharing beyond the multi-objective reward function given at training time. To this end, we adapt a state-of-the-art RFRL algorithm to the MORL setting and introduce a preference-guided exploration strategy that focuses learning on relevant parts of the environment. Through extensive experiments and ablation studies, we demonstrate that our approach significantly outperforms the state-of-the-art MORL methods across diverse MO-Gymnasium tasks, achieving superior performance and data efficiency. This work provides the first systematic adaptation of RFRL to MORL, demonstrating its potential as a scalable and empirically effective solution to multi-objective policy learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes adapting a state-of-the-art reward-free RL (RFRL) algorithm as an auxiliary training objective for multi-objective RL (MORL), combined with a preference-guided exploration strategy, to improve knowledge sharing across user preferences beyond the given multi-objective reward function. It claims this yields the first systematic RFRL-to-MORL adaptation and significantly outperforms existing MORL methods in performance and data efficiency across diverse MO-Gymnasium tasks.
Significance. If the empirical gains hold under rigorous controls, the work could establish RFRL objectives as a practical auxiliary mechanism for preference-conditioned policies, offering improved data efficiency and generalization in MORL without requiring explicit reward function knowledge at test time.
major comments (2)
- [Methods] Methods section: No derivation or stability analysis is provided for combining the RFRL auxiliary objective (which is reward-agnostic and targets coverage or worst-case behavior) with the preference-vector-conditioned MORL policy loss; this leaves open the risk of gradient conflicts or bias toward frequently sampled preferences, as noted in the skeptic concern.
- [Experiments] Experiments section: The central claim of outperforming SOTA MORL methods lacks explicit reporting of baseline implementations, number of random seeds, statistical significance tests (e.g., t-tests or confidence intervals), and complete ablation results on the auxiliary objective and exploration strategy, making it impossible to assess whether the reported gains are robust or attributable to the proposed adaptation.
minor comments (1)
- [Abstract] Abstract: The phrase 'extensive experiments and ablation studies' is used without naming the specific MO-Gymnasium environments or performance metrics, which reduces clarity for readers scanning the contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Methods] Methods section: No derivation or stability analysis is provided for combining the RFRL auxiliary objective (which is reward-agnostic and targets coverage or worst-case behavior) with the preference-vector-conditioned MORL policy loss; this leaves open the risk of gradient conflicts or bias toward frequently sampled preferences, as noted in the skeptic concern.
Authors: We agree that the manuscript does not contain a formal derivation or stability analysis of the combined loss. The approach is presented as an empirical adaptation, motivated by the fact that RFRL objectives encourage state-action coverage that aids generalization across preferences in MORL. In practice, we observed no training instability or obvious bias in the reported runs. To address the concern, we will add a short discussion subsection explaining the objective combination, the use of a fixed weighting hyperparameter to balance the terms, and practical steps (gradient clipping, separate learning rates) that mitigate potential conflicts. This provides a practical treatment without new theoretical claims. revision: partial
-
Referee: [Experiments] Experiments section: The central claim of outperforming SOTA MORL methods lacks explicit reporting of baseline implementations, number of random seeds, statistical significance tests (e.g., t-tests or confidence intervals), and complete ablation results on the auxiliary objective and exploration strategy, making it impossible to assess whether the reported gains are robust or attributable to the proposed adaptation.
Authors: The manuscript already contains ablation studies isolating the auxiliary objective and exploration strategy (Section 4.3 and Appendix B) and reports performance with means and standard deviations. However, we accept that explicit details on seeds, statistical tests, and baseline code references could be clearer. In the revision we will add a dedicated 'Experimental Setup' paragraph stating the number of random seeds used, the statistical tests performed (including p-values), confidence intervals, and direct links or descriptions of baseline implementations. This will make reproducibility and attribution fully transparent while leaving the empirical results unchanged. revision: yes
Circularity Check
No significant circularity: algorithmic adaptation plus empirical validation
full rationale
The paper proposes adapting an existing RFRL algorithm as an auxiliary objective for preference-conditioned MORL policies, augmented by a preference-guided exploration strategy, then validates the combined approach via experiments on MO-Gymnasium benchmarks. No load-bearing derivation, first-principles result, or prediction is presented that reduces by the paper's own equations to a fitted parameter, self-definition, or self-citation chain. The central claims rest on the empirical outperformance rather than any tautological equivalence between inputs and outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard RL assumptions (Markov decision process, bounded rewards, existence of optimal policies) hold in the MO-Gymnasium environments.
Reference graph
Works this paper leans on
-
[1]
PD-MORL: Preference-driven multi-Objective reinforcement learning algorithm
11 Published as a conference paper at ICLR 2026 Toygun Basaklar, Suat Gumussoy, and Umit Ogras. PD-MORL: Preference-driven multi-Objective reinforcement learning algorithm. InInternational Conference on Learning Representations,
2026
-
[2]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4RL: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219,
work page internal anchor Pith review arXiv 2004
-
[3]
Reinforcement learning with unsupervised auxiliary tasks,
Max Jaderberg, V olodymyr Mnih, Wojciech Marian Czarnecki, Tom Schaul, Joel Z Leibo, David Silver, and Koray Kavukcuoglu. Reinforcement learning with unsupervised auxiliary tasks.arXiv preprint arXiv:1611.05397,
-
[4]
Deep Successor Reinforcement Learning
12 Published as a conference paper at ICLR 2026 Tejas D Kulkarni, Ardavan Saeedi, Simanta Gautam, and Samuel J Gershman. Deep successor reinforcement learning.arXiv preprint arXiv:1606.02396,
work page Pith review arXiv 2026
-
[5]
Demonstration guided multi-objective reinforcement learning.arXiv preprint arXiv:2404.03997,
Junlin Lu, Patrick Mannion, and Karl Mason. Demonstration guided multi-objective reinforcement learning.arXiv preprint arXiv:2404.03997,
-
[6]
Hossam Mossalam, Yannis M Assael, Diederik M Roijers, and Shimon Whiteson. Multi-objective deep reinforcement learning.arXiv preprint arXiv:1610.02707,
-
[7]
Shuang Qiu, Dake Zhang, Rui Yang, Boxiang Lyu, and Tong Zhang. Traversing Pareto optimal poli- cies: Provably efficient multi-objective reinforcement learning.arXiv preprint arXiv:2407.17466,
-
[8]
Banafsheh Rafiee, Jun Jin, Jun Luo, and Adam White. What makes useful auxiliary tasks in rein- forcement learning: investigating the effect of the target policy.arXiv preprint arXiv:2204.00565,
-
[9]
Zero-shot whole-body humanoid control via behav- ioral foundation models
13 Published as a conference paper at ICLR 2026 Andrea Tirinzoni, Ahmed Touati, Jesse Farebrother, Mateusz Guzek, Anssi Kanervisto, Yingchen Xu, Alessandro Lazaric, and Matteo Pirotta. Zero-shot whole-body humanoid control via behav- ioral foundation models. InInternational Conference on Learning Representations,
2026
-
[10]
Finite-time convergence and sample complexity of actor-critic multi-objective reinforcement learning
14 Published as a conference paper at ICLR 2026 Tianchen Zhou, FNU Hairi, Haibo Yang, Jia Liu, Tian Tong, Fan Yang, Michinari Momma, and Yan Gao. Finite-time convergence and sample complexity of actor-critic multi-objective reinforcement learning. InInternational Conference on Machine Learning,
2026
-
[11]
16 A.2 Forward-Backward (FB) Representations
15 Published as a conference paper at ICLR 2026 APPENDICES A Additional Background: Successor Measure and Forward-Backward Representations 16 A.1 Successor Measure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 A.2 Forward-Backward (FB) Representations . . . . . . . . . . . . . . . . . . . . . . 17 B Detailed Pseudo Code of MORL-FB...
2026
-
[12]
what happens next
asz← √dz z ∥z∥2 . This normalization step, motivated by the prior work (Touati et al., 2023), has been observed to improve performance. As shown in Algorithm 2, the training of MORL-FB involves the following loss functions: Measure Loss.The Measure loss,L M(θ, ω;z λ), is central to learning a task-agnostic representation of environment dynamics,F θ(st, at...
2023
-
[13]
Similar to Humanoid2d, the healthy reward parameter is set to 1.0 to ensure meaningful evaluation
This environment has five objectives: maximizing moving speed along the x-axis, max- imizing moving speed along the y-axis, maximizing angular velocity on the left elbow, maximizing angular velocity on the right elbow, and minimizing energy cost. Similar to Humanoid2d, the healthy reward parameter is set to 1.0 to ensure meaningful evaluation. Classic Con...
2011
-
[14]
Table 1 and Table 3 list the detailed hyperparameters used in our ex- periments
and CAPQL (Lu et al., 2023). Table 1 and Table 3 list the detailed hyperparameters used in our ex- periments. For PGMORL, the hyperparameters reflect its evolutionary population-based design. The parameterndefines the number of parallel reinforcement learning tasks in each generation. Each task includesm w warm-up iterations andm t evolutionary iterations...
2023
-
[15]
Table 1: Hyperparameters of PGMORL. Environmentsn m w mt Pnum KP size α HalfCheetah2d6 80 20 100 2 7−1 Walker2d6 80 20 100 2 7−1 Hopper3d15 200 40 210 2 7−10 6 Ant3d15 200 40 210 2 7−10 6 Humanoid2d6 200 40 100 2 7−1 Humanoid5d35 200 40 550 2 7−10 6 20 Published as a conference paper at ICLR 2026 Table 2: PPO hyperparameters used in PGMORL. Parameter Valu...
2026
-
[16]
Point) for each environment
Reference Points for HV Evaluation.We compute the HV indicator using predefined reference points (Ref. Point) for each environment. These reference points serve as baselines to measure the 23 Published as a conference paper at ICLR 2026 Table 12: Hyperparameter configuration for MORL-FB experiments. Parameter Value Total number of environment steps3×10 6 ...
2026
-
[17]
Ant3d (0, 0, -8000) Humanoid2d (0, -8000) Humanoid5d (0, 0, 0, 0, -8000) C.3 COMPUTERESOURCES All models were trained on a workstation featuring a single NVIDIA RTX 4090 GPU, an Intel Core i7-13700K CPU, and 64 GB of system memory. 24 Published as a conference paper at ICLR 2026 D ADDITIONALEXPERIMENTALRESULTS D.1 VISUALIZATION OFzDISTRIBUTION INDIFFERENT...
2026
-
[18]
Original
This demonstrates that MORL-FB ef- fectively encodes different preferences into separate regions of the latent space, leading to more diverse policies. To further illustrate this, we provide a demo of the policies learned by MORL-FB and vanilla FB in this link:https://imgur.com/a/ehx1v7q, where the z’s are selected from different positions on the t-SNE pl...
2026
-
[19]
auxiliary
This shows that the auxiliary loss of FB cannot be directly applied and needs to be adapted properly in the context of MORL. Note that we use the term “auxiliary” since the original FB is directly built on the measure loss and hence the Q loss is auxiliary for learning FB representation, rather than being unimportant for MORL. Table 16: Ablation study of ...
2026
-
[20]
Since some MO MuJoCo rewards depend on both states and actions, we compare MORL-FB and the extended one
and state-action-based rewards (Touati & Ollivier, 2021), MORL-FB can also be extended to state-action-based rewards by replacingB(s)withB(s, a). Since some MO MuJoCo rewards depend on both states and actions, we compare MORL-FB and the extended one. As shown in the Figure 14, the state-action-based variant yields slight performance improvements on severa...
2021
-
[21]
Figure 15:Evaluation of MORL-FB under stochastic reward.This figure assesses the perfor- mance of MORL-FB in environments featuring stochastic reward functions. 30 Published as a conference paper at ICLR 2026 D.6 PERFORMANCECOMPARISON OFMORL-FB WITHNONLINEARSCALARIZATION While we focus on linear scalarization in this paper, MORL-FB can be readily extended...
2026
-
[22]
D.9 RFRLAS A SOURCE OF AUXILIARY TASKS During training, thezvectors computed for each preferenceλare diverse, covering both CCS and non-CCS policies
MORL-FB consistently outperforms FB across all configurations in terms of utility and hypervolume. D.9 RFRLAS A SOURCE OF AUXILIARY TASKS During training, thezvectors computed for each preferenceλare diverse, covering both CCS and non-CCS policies. Learning from non-CCS policies serves as auxiliary tasks. From Figure 19, we find that the return vectors ac...
2026
-
[23]
34 Published as a conference paper at ICLR 2026 Table 22: Wall-clock time comparison (100K steps)
The results in Tables 23 to 26 correspond to the visualizations shown in Figure 2, Figure 4, Figure 12 and Figure 13, respectively. 34 Published as a conference paper at ICLR 2026 Table 22: Wall-clock time comparison (100K steps). Algorithm Wall-Clock Time (seconds) PD-MORL 1166 CAPQL 3369 MORL/D 793 SFOLS 550 Q-Pensieve 12960 PGMORL 4237 PCN 4445 GPI-LS ...
2026
-
[24]
2.38±0.30 -1.43±0.148.13±0.01 HV(×10 7)1.78±0.000.96±0.00 1.75±0.02 35 Published as a conference paper at ICLR 2026 Table 26: Comparative performance of MORL-FB and various benchmark algorithms across continuous control tasks in MuJoCo. Environments Metrics PD-MORL Q-Pensieve CAPQL PGMORL MORL/D PCN SFOLS GPI-LS GPI-PD FB MORL-FB (w/o interpolator) (Ours)...
2026
-
[25]
The results demonstrate that MORL-FB consistently achieves superior performance compared to baselines
POI quantifies the likelihood that one algorithm will outperform another. The results demonstrate that MORL-FB consistently achieves superior performance compared to baselines. Additionally, we assessed the performance of training with constraint preferences using the method from Agarwal et al. (2021), presented in Figures 22 and
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.