Recognition: unknown
SpecRLBench: A Benchmark for Generalization in Specification-Guided Reinforcement Learning
Pith reviewed 2026-05-08 03:56 UTC · model grok-4.3
The pith
SpecRLBench benchmark shows existing LTL-guided RL methods lose performance as task and environment complexity grows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
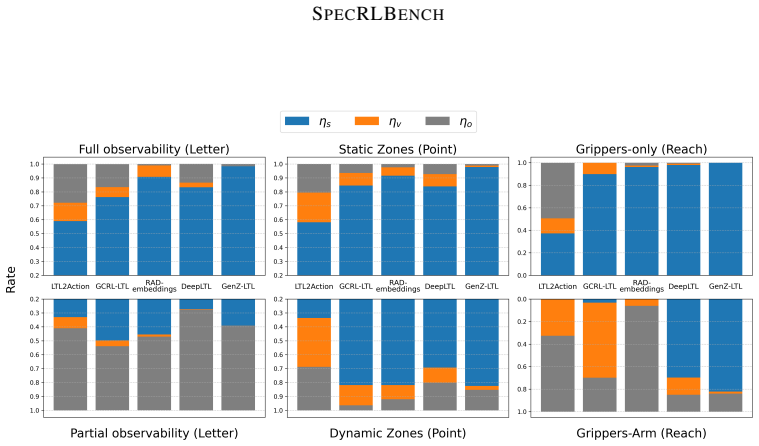
The authors establish SpecRLBench, which spans multiple difficulty levels across navigation and manipulation domains incorporating both static and dynamic environments, diverse robot dynamics, and varied observation modalities, and through extensive empirical evaluation characterize the strengths and limitations of existing LTL-based specification-guided RL approaches while revealing the challenges that emerge as specification and environment complexity increases.
What carries the argument
SpecRLBench, a multi-domain benchmark with graduated complexity levels designed to measure generalization of LTL specification-guided reinforcement learning methods.
If this is right
- Current methods exhibit clear performance degradation once specification length or environment dynamics increase beyond basic levels.
- Generalization across unseen specifications remains an open difficulty even in controlled benchmark settings.
- The benchmark enables direct, apples-to-apples comparison of different specification-guided RL algorithms.
- Future method development can target the specific failure modes identified at higher complexity tiers.
Where Pith is reading between the lines
- - Researchers could extend the benchmark to additional formal specification languages to check whether the same complexity scaling pattern appears.
- - Robotic systems intended for long-horizon tasks might first need new training regimes that explicitly penalize poor generalization on held-out specifications.
- - If the observed limits persist in physical hardware, deployment pipelines may require online adaptation modules rather than purely offline training.
Load-bearing premise
The chosen navigation and manipulation domains together with their static/dynamic variants, robot dynamics, and observation types sufficiently represent the main generalization difficulties faced by LTL-based specification-guided RL.
What would settle it
A controlled study in which one or more current methods maintain high success rates on all SpecRLBench difficulty tiers when evaluated on entirely new specification-environment pairs outside the benchmark would undermine the reported emergence of challenges with rising complexity.
Figures




read the original abstract
Specification-guided reinforcement learning (RL) provides a principled framework for encoding complex, temporally extended tasks using formal specifications such as linear temporal logic (LTL). While recent methods have shown promising results, their ability to generalize across unseen specifications and diverse environments remains insufficiently understood. In this work, we introduce SpecRLBench, a benchmark designed to evaluate the generalization capabilities of LTL-based specification-guided RL methods. The benchmark spans multiple difficulty levels across navigation and manipulation domains, incorporating both static and dynamic environments, diverse robot dynamics, and varied observation modalities. Through extensive empirical evaluation, we characterize the strengths and limitations of existing approaches and reveal the challenges that emerge as specification and environment complexity increase. SpecRLBench provides a structured platform for systematic comparison and supports the development of more generalizable specification-guided RL methods. Code is available at https://github.com/BU-DEPEND-Lab/SpecRLBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpecRLBench, a benchmark for evaluating generalization in LTL-based specification-guided reinforcement learning. It covers navigation and manipulation domains at multiple difficulty levels, including static and dynamic environments, diverse robot dynamics, and varied observation modalities. The authors perform extensive empirical evaluations of existing methods to characterize their strengths and limitations, with particular emphasis on challenges that emerge as specification and environment complexity increase. The benchmark is positioned as a structured platform for systematic comparison, and code is made publicly available.
Significance. If the evaluations are robust, this benchmark addresses a clear gap in understanding generalization for specification-guided RL, an area where formal task encodings are increasingly used but cross-environment and cross-specification performance remains poorly characterized. Providing a standardized testbed with controlled complexity variations can accelerate progress toward more reliable methods. The open release of code and the benchmark itself is a clear strength that supports reproducibility and community adoption.
major comments (1)
- [Benchmark Design] Benchmark Design section: The central claim that the empirical results reveal challenges 'as specification and environment complexity increase' rests on the assumption that the chosen navigation/manipulation domains, static/dynamic variants, robot dynamics, and observation modalities are representative of the broader space of generalization issues in LTL-guided RL. The manuscript provides no explicit justification, coverage analysis, or sensitivity study supporting this representativeness, which weakens the ability to generalize the observed limitations beyond the specific setups tested.
minor comments (3)
- [Abstract] Abstract: The phrase 'extensive empirical evaluation' is used without any quantitative indication of the number of methods, tasks, or independent runs; a brief clause summarizing scope would improve precision.
- [Experiments] Figures (throughout): Several result plots would benefit from explicit axis labels indicating the complexity metric (e.g., number of temporal operators or environment dynamism level) and consistent legend ordering across panels.
- [Related Work] Related Work: A small number of recent LTL-RL papers on generalization (post-2022) appear to be missing; a quick update would ensure completeness.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on the manuscript. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Benchmark Design] Benchmark Design section: The central claim that the empirical results reveal challenges 'as specification and environment complexity increase' rests on the assumption that the chosen navigation/manipulation domains, static/dynamic variants, robot dynamics, and observation modalities are representative of the broader space of generalization issues in LTL-guided RL. The manuscript provides no explicit justification, coverage analysis, or sensitivity study supporting this representativeness, which weakens the ability to generalize the observed limitations beyond the specific setups tested.
Authors: We agree that the manuscript would benefit from a more explicit discussion of the benchmark design choices and their relation to broader generalization challenges in LTL-guided RL. The current version describes the included domains, variants, dynamics, and modalities but does not provide a dedicated rationale or coverage analysis. In the revised manuscript, we will expand the Benchmark Design section with a new subsection on 'Design Choices and Scope.' This subsection will explain the selection of navigation and manipulation domains, static/dynamic environments, robot dynamics variations, and observation modalities by referencing prior work in specification-guided RL, showing how these elements target common generalization issues such as adaptation to environmental changes and increasing task complexity. We will also include a coverage analysis (e.g., via a table summarizing addressed vs. unaddressed aspects) and a limitations paragraph noting that the benchmark focuses on representative but not exhaustive scenarios. A comprehensive sensitivity study across all possible variations is not feasible within the current computational budget and is acknowledged as future work. This constitutes a partial revision focused on improved discussion and transparency rather than new experiments. revision: partial
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark paper that introduces SpecRLBench and evaluates existing LTL-based RL methods across navigation and manipulation domains. It contains no derivations, equations, fitted parameters, or predictions that could reduce to inputs by construction. The central claim follows directly from running the benchmark and reporting results, with no self-citation load-bearing steps or ansatz smuggling. The derivation chain is self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
BabyAI: A platform to study the sample efficiency of grounded language learning
Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen, and Yoshua Bengio. Babyai: A platform to study the sample efficiency of grounded language learning.arXiv preprint arXiv:1810.08272,
-
[2]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219,
work page internal anchor Pith review arXiv 2004
-
[3]
Lewis Hammond, Alessandro Abate, Julian Gutierrez, and Michael Wooldridge. Multi-agent rein- forcement learning with temporal logic specifications.arXiv preprint arXiv:2102.00582,
-
[4]
Logically-constrained re- inforcement learning.arXiv preprint arXiv:1801.08099,
Mohammadhosein Hasanbeig, Alessandro Abate, and Daniel Kroening. Logically-constrained re- inforcement learning.arXiv preprint arXiv:1801.08099,
-
[5]
Glide-rl: grounded language instruction through demonstration in rl.arXiv preprint arXiv:2401.02991,
Chaitanya Kharyal, Sai Krishna Gottipati, Tanmay Kumar Sinha, Srijita Das, and Matthew E Taylor. Glide-rl: grounded language instruction through demonstration in rl.arXiv preprint arXiv:2401.02991,
-
[6]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Opti- mizing speed and success.arXiv preprint arXiv:2502.19645,
work page internal anchor Pith review arXiv
-
[7]
Goal-conditioned re- inforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299,
Minghuan Liu, Menghui Zhu, and Weinan Zhang. Goal-conditioned reinforcement learning: Prob- lems and solutions.arXiv preprint arXiv:2201.08299,
-
[8]
Shuo Liu, Wenliang Liu, Wei Xiao, and Calin A Belta. Learning robust and correct con- trollers guided by feasibility-aware signal temporal logic via barriernet.arXiv preprint arXiv:2512.06973,
-
[9]
Composuite: A compo- sitional reinforcement learning benchmark
Jorge A Mendez, Marcel Hussing, Meghna Gummadi, and Eric Eaton. Composuite: A composi- tional reinforcement learning benchmark.arXiv preprint arXiv:2207.04136,
-
[10]
Yue Meng, Fei Chen, and Chuchu Fan. Tgpo: Temporal grounded policy optimization for signal temporal logic tasks.arXiv preprint arXiv:2510.00225,
-
[11]
Jing-Cheng Pang, Kaiyuan Li, Yidi Wang, Si-Hang Yang, Shengyi Jiang, and Yang Yu. Imag- inebench: Evaluating reinforcement learning with large language model rollouts.arXiv preprint arXiv:2505.10010,
-
[12]
Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092,
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092,
-
[13]
The temporal logic of programs
Amir Pnueli. The temporal logic of programs. In18th annual symposium on foundations of com- puter science (sfcs 1977), pages 46–57. ieee,
1977
-
[14]
Rajarshi Roy, Yash Pote, David Parker, and Marta Kwiatkowska. Learning probabilistic temporal logic specifications for stochastic systems.arXiv preprint arXiv:2505.12107,
-
[15]
Daqian Shao and Marta Kwiatkowska
ISSN 2835-8856. Daqian Shao and Marta Kwiatkowska. Sample efficient model-free reinforcement learning from ltl specifications with optimality guarantees.arXiv preprint arXiv:2305.01381,
-
[16]
Revisiting parameter sharing in multi-agent deep reinforcement learning,
Justin K Terry, Nathaniel Grammel, Sanghyun Son, Benjamin Black, and Aakriti Agrawal. Revisiting parameter sharing in multi-agent deep reinforcement learning.arXiv preprint arXiv:2005.13625,
-
[17]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U Balis, Gianluca De Cola, Tristan Deleu, Manuel Goul˜ao, Andreas Kallinteris, Markus Krimmel, Arjun KG, et al. Gymnasium: A standard interface for reinforcement learning environments.arXiv preprint arXiv:2407.17032,
work page internal anchor Pith review arXiv
-
[18]
Multi-agent reinforcement learning guided by signal temporal logic specifications
Jiangwei Wang, Shuo Yang, Ziyan An, Songyang Han, Zhili Zhang, Rahul Mangharam, Meiyi Ma, and Fei Miao. Multi-agent reinforcement learning guided by signal temporal logic specifications. arXiv preprint arXiv:2306.06808, 2023a. Jiao Wang, Haoyi Sun, and Can Zhu. Vision-based autonomous driving: A hierarchical rein- forcement learning approach.IEEE Transact...
-
[19]
Runpeng Xie, Quanwei Wang, Hao Hu, Zherui Zhou, Ni Mu, Xiyun Li, Yiqin Yang, Shuang Xu, Qianchuan Zhao, and Bo Xu. Dail: Beyond task ambiguity for language-conditioned reinforce- ment learning.arXiv preprint arXiv:2510.19562,
-
[20]
Automata-conditioned cooperative multi-agent reinforcement learning.arXiv preprint arXiv:2511.02304,
Beyazit Yalcinkaya, Marcell Vazquez-Chanlatte, Ameesh Shah, Hanna Krasowski, and Sanjit A Seshia. Automata-conditioned cooperative multi-agent reinforcement learning.arXiv preprint arXiv:2511.02304,
-
[21]
Chao Yu, Yuanqing Wang, Zhen Guo, Hao Lin, Si Xu, Hongzhi Zang, Quanlu Zhang, Yongji Wu, Chunyang Zhu, Junhao Hu, et al. Rlinf: Flexible and efficient large-scale reinforcement learning via macro-to-micro flow transformation.arXiv preprint arXiv:2509.15965,
-
[22]
Goalladder: Incremental goal discovery with vision- language models.arXiv preprint arXiv:2506.16396,
Alexey Zakharov and Shimon Whiteson. Goalladder: Incremental goal discovery with vision- language models.arXiv preprint arXiv:2506.16396,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.