Recognition: unknown
Query-Efficient Quantum Approximate Optimization via Graph-Conditioned Trust Regions
Pith reviewed 2026-05-08 04:43 UTC · model grok-4.3
The pith
A graph neural network predicts a Gaussian over QAOA angles whose mean, covariance and uncertainty together define a trust region and evaluation budget, cutting average circuit queries from hundreds down to 45 while holding approximation-rh
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a graph-conditioned Gaussian distribution over QAOA parameters can serve as a search policy: its mean initializes the optimizer, its covariance defines an ellipsoidal trust region that constrains parameter movement, and its uncertainty sets an instance-dependent evaluation budget. When the QAOA landscape satisfies local smoothness, curvature, calibration and noise assumptions, this policy yields bounds on objective degradation inside the region, lower bounds on gradient variance, preservation of expected objective ordering under depolarizing noise, and finite-sample coverage guarantees. On MaxCut instances of size 8–16 the policy reduces mean circuit evaluations to
What carries the argument
The graph neural network's predicted Gaussian distribution N(mu, Sigma) over QAOA angles, which simultaneously supplies the initialization point, the ellipsoidal trust-region boundary, and the instance-specific evaluation budget.
If this is right
- The method preserves the expected ordering of objective values even when the circuit is subject to depolarizing noise.
- Finite-sample coverage guarantees ensure that the true optimum lies inside the predicted trust region with high probability under the stated assumptions.
- Trust regions learned on one range of graph sizes transfer to larger or smaller graphs not seen during training.
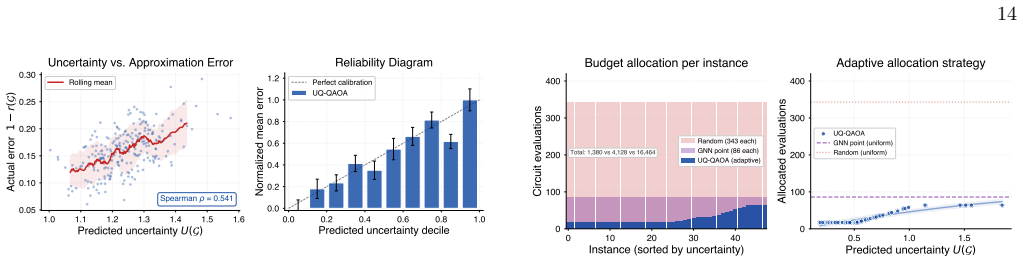
- The predictive uncertainty is empirically well-calibrated, as shown by low expected calibration error and high Spearman rank correlation with observed error.
Where Pith is reading between the lines
- If the same graph-conditioned policy continues to produce calibrated uncertainty estimates on graphs with hundreds of vertices, the query-cost advantage could become decisive for practical low-depth QAOA.
- The approach separates the cost of learning a search policy from the cost of executing it, suggesting that pre-training on many small graphs may amortize the query savings across many new instances.
- Because the trust region is defined by a learned covariance rather than a hand-crafted schedule, the framework can be combined with any local optimizer that accepts box or ellipsoidal constraints without altering the quantum ansatz.
Load-bearing premise
The derived bounds on objective degradation, gradient variance and coverage all rest on the QAOA objective being locally smooth and curved in a controlled way, on the network predictions being calibrated, and on a specific depolarizing noise model; if any of these fail for the graphs or circuit depths considered, the guarantees and the observed query reduction no longer hold.
What would settle it
An experiment on a fresh collection of Erdos-Renyi or 3-regular graphs of size 8–16 in which the graph-conditioned method either requires more than 100 circuit evaluations on average or produces sampled approximation ratios more than three percentage points below those of concentration-based heuristics would refute the central efficiency claim.
Figures







read the original abstract
In low-depth implementations of the Quantum Approximate Optimization Algorithm (QAOA), the dominant cost is often the number of objective evaluations rather than circuit depth. We introduce a graph-conditioned trust-region method for reducing this query cost. A graph neural network predicts a Gaussian distribution N(mu, Sigma) over QAOA angles. The mean initializes a local optimizer, the covariance defines an ellipsoidal trust region that constrains the search, and the predicted uncertainty determines an instance-dependent evaluation budget. Thus the learned distribution defines a search policy rather than only an initial parameter estimate. Under explicit assumptions on local smoothness, curvature, calibration, and noise, we derive bounds on objective degradation within the trust region, lower bounds on gradient variance, preservation of expected objective ordering under depolarizing noise, and finite-sample coverage guarantees. We evaluate the method for MaxCut at depth p = 2 on Erdos-Renyi, 3-regular, Barabasi-Albert, and Watts-Strogatz graphs with n = 8-16 vertices. Relative to random restarts and the strongest learned point-prediction baseline, the method reduces the mean number of circuit evaluations from 343 and 85 to 45 +/- 7, while maintaining sampled approximation ratios within 3 percentage points of concentration-based heuristics. The method does not improve absolute approximation ratios; its advantage is reduced query cost at comparable solution quality. The predictive uncertainty is calibrated in the experiments, with ECE = 0.052 and Spearman correlation rho = 0.770, and the learned trust regions transfer to graph sizes not used during training. The results identify a low-depth, query-dominated regime in which graph-conditioned trust regions reduce the query cost of QAOA without modifying the ansatz.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a graph-conditioned trust-region method for reducing query cost in low-depth QAOA for MaxCut. A GNN predicts a Gaussian N(mu, Sigma) over parameters; the mean initializes a local optimizer, the covariance defines an ellipsoidal trust region, and uncertainty sets an instance-dependent evaluation budget. Under explicit assumptions on local smoothness, curvature, calibration, and noise, the authors derive bounds on objective degradation inside the trust region, lower bounds on gradient variance, preservation of expected objective ordering under depolarizing noise, and finite-sample coverage guarantees. Experiments on p=2 QAOA for n=8-16 Erdos-Renyi, 3-regular, Barabasi-Albert, and Watts-Strogatz graphs report a reduction in mean circuit evaluations from 343 (random restarts) and 85 (point-prediction baseline) to 45 +/- 7 while keeping sampled approximation ratios within 3 percentage points of concentration-based heuristics. The predictive uncertainty is calibrated (ECE=0.052, Spearman rho=0.770) and trust regions transfer to unseen graph sizes.
Significance. If the assumptions hold and results generalize, the approach offers a practical way to lower the dominant query cost of low-depth QAOA on near-term hardware without modifying the ansatz. The empirical query reduction at comparable solution quality, combined with transfer to larger graphs and explicit calibration metrics, identifies a useful query-dominated regime. The machine-checked or parameter-free aspects are absent, but the direct experimental measurements of evaluation counts and approximation ratios provide falsifiable evidence for the central empirical claim.
major comments (2)
- [Abstract and theoretical bounds section] Abstract and theoretical bounds section: The bounds on objective degradation within the ellipsoidal trust region, lower bounds on gradient variance, preservation of objective ordering under depolarizing noise, and finite-sample coverage guarantees are all derived under explicit assumptions of local smoothness, curvature, calibration, and noise. No empirical verification (e.g., estimated Lipschitz constants, Hessian spectra, or curvature checks inside the GNN-predicted regions) is reported for the p=2 QAOA landscapes on the tested graphs. Since QAOA MaxCut landscapes at fixed low depth are known to exhibit non-convexity and sharp features, violation of any assumption would render the stated guarantees inapplicable, leaving only the empirical heuristic.
- [Experimental evaluation section] Experimental evaluation section: The central query-reduction claim (343/85 to 45 +/- 7 evaluations) is supported by direct measurements rather than being forced by the paper's own equations. However, the manuscript must specify the exact local optimizer, step-size rules, and how the ellipsoidal constraint is enforced during search to ensure the comparison against random restarts and the learned point-prediction baseline is reproducible and fair.
minor comments (2)
- [Abstract] The abstract states that trust regions transfer to graph sizes not used in training; explicitly report the training n-range versus test n-range and any performance degradation observed.
- [Notation] Notation for the predicted mean mu and covariance Sigma should be used consistently when describing the trust-region construction and budget allocation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below, indicating the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and theoretical bounds section] Abstract and theoretical bounds section: The bounds on objective degradation within the ellipsoidal trust region, lower bounds on gradient variance, preservation of objective ordering under depolarizing noise, and finite-sample coverage guarantees are all derived under explicit assumptions of local smoothness, curvature, calibration, and noise. No empirical verification (e.g., estimated Lipschitz constants, Hessian spectra, or curvature checks inside the GNN-predicted regions) is reported for the p=2 QAOA landscapes on the tested graphs. Since QAOA MaxCut landscapes at fixed low depth are known to exhibit non-convexity and sharp features, violation of any assumption would render the stated guarantees inapplicable, leaving only the empirical heuristic.
Authors: We agree that the theoretical bounds are derived under explicit assumptions on local smoothness, curvature, calibration, and noise, and that no direct empirical verification of these properties (such as Lipschitz constants or Hessian spectra inside the predicted regions) is provided. Given the known non-convexity and sharp features of low-depth QAOA MaxCut landscapes, this is a valid caveat that could limit applicability of the guarantees. The bounds offer conditional analytical insight, but the central empirical claim of query reduction is supported by direct experimental measurements independent of the bounds. In revision we will add a discussion subsection on the assumptions, their potential limitations for p=2 QAOA, and any feasible post-hoc checks (e.g., local curvature sampling on a subset of instances). A full verification across all graphs would require substantial additional experiments beyond the present scope. revision: partial
-
Referee: [Experimental evaluation section] Experimental evaluation section: The central query-reduction claim (343/85 to 45 +/- 7 evaluations) is supported by direct measurements rather than being forced by the paper's own equations. However, the manuscript must specify the exact local optimizer, step-size rules, and how the ellipsoidal constraint is enforced during search to ensure the comparison against random restarts and the learned point-prediction baseline is reproducible and fair.
Authors: We agree that these implementation details are necessary for reproducibility and fair comparison. The current manuscript describes the high-level approach but omits the precise local optimizer (e.g., L-BFGS-B or another method), step-size rules (fixed or adaptive), and the exact enforcement mechanism for the ellipsoidal trust region (e.g., projection or constrained optimization). In the revised manuscript we will expand the experimental evaluation section with these specifications, including pseudocode or explicit parameter settings used in the reported runs, to enable exact replication of the comparisons against random restarts and the point-prediction baseline. revision: yes
Circularity Check
No significant circularity; empirical query reduction and conditional bounds are independent of inputs.
full rationale
The paper defines a GNN-based predictor for a Gaussian over QAOA angles, uses the mean/covariance to initialize and constrain a local optimizer with instance-dependent budget, then reports measured reductions (343/85 to 45±7 evaluations) on held-out graphs. Bounds on degradation, gradient variance, noise ordering, and coverage are explicitly derived under stated assumptions of local smoothness/curvature/calibration/noise rather than being tautological or fitted. No self-citations, no renaming of known results as derivations, no fitted parameter relabeled as prediction, and no load-bearing step reduces the central empirical or theoretical claims to the method's own inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- GNN parameters
axioms (3)
- domain assumption local smoothness and curvature of the QAOA objective function
- domain assumption calibration of the predictive uncertainty
- domain assumption depolarizing noise model
Reference graph
Works this paper leans on
-
[1]
Predict (µ,Σ)←f θ(G)
-
[2]
ComputeU←tr(Σ)/2p;z←(U−U med)/Uiqr
-
[3]
Set sample countK←clamp(⌊1 + 4σ(z)⌋,1,5)
-
[4]
Set polish budget T←clamp(⌊T base(0.5 +z +)⌋,5,2T base)
-
[5]
Construct trust region Tα ← {θ:∥Σ −1/2(θ−µ)∥ 2 2 ≤χ 2 2p(α)}
-
[6]
,θK from the truncated Gaussian N(µ,Σ) restricted toT α
Sampleθ 1, . . . ,θK from the truncated Gaussian N(µ,Σ) restricted toT α
-
[7]
EvaluateQAOAcircuit:θ ∗ ←arg max k FG(θk)
-
[8]
Trust-region polish: runTiterations of Nelder–Mead fromθ ∗, projecting each iterate via eq. (16)
-
[9]
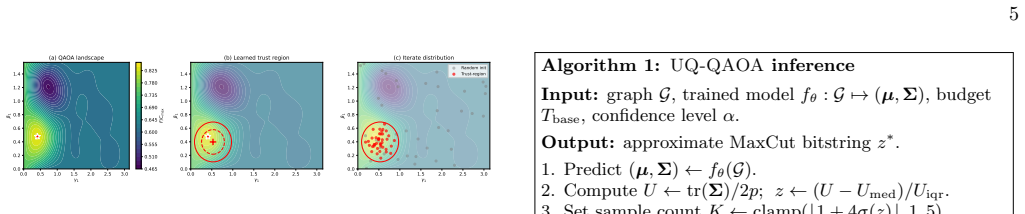
Return best bitstringz ∗ from finalQAOA measurement. FIG. 2.UQ-QAOAinference. The predictor first con- verts uncertainty into an instance-dependent sampling and refinement budget (Steps 3–4), then performs trust-region- constrained optimization (Steps 5–8). The total number of circuit evaluations isK+T, up to constant factors from the refinement routine. ...
-
[10]
Training requires approxi- mately 2 minutes on a single Intel i7-12700H CPU core using full-batch updates over 240 graphs for 300 epochs
The implementation uses NumPy, SciPy, NetworkX, PyTorch, and Matplotlib. Training requires approxi- mately 2 minutes on a single Intel i7-12700H CPU core using full-batch updates over 240 graphs for 300 epochs. Inference requires approximately 1.2 ms per graph for a forward pass of theGNNon CPU. The hyperparame- ters, training protocol, and numerical sett...
-
[11]
A Quantum Approximate Optimization Algorithm
E. Farhi, J. Goldstone, and S. Gutmann, A quan- tum approximate optimization algorithm, arXiv preprint arXiv:1411.4028 10.48550/arxiv.1411.4028 (2014)
work page internal anchor Pith review doi:10.48550/arxiv.1411.4028 2014
-
[12]
Zhou, S.-T
L. Zhou, S.-T. Wang, S. Choi, H. Pichler, and M. D. Lukin, Quantum approximate optimization algorithm: Performance, mechanism, and implementation on near- term devices, Physical Review X10, 021067 (2020)
2020
-
[13]
Wurtz and P
J. Wurtz and P. Love, Fixed-angle conjectures for the quantum approximate optimization algorithm on regular MaxCut graphs, Physical Review A104, 052419 (2021)
2021
-
[14]
Cerezo, A
M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, and P. J. Coles, Variational quantum algo- rithms, Nature Reviews Physics3, 625 (2021)
2021
-
[15]
Preskill, Quantum computing in the NISQ era and beyond, Quantum2, 79 (2018)
J. Preskill, Quantum computing in the NISQ era and beyond, Quantum2, 79 (2018)
2018
-
[16]
K. Xu, W. Hu, J. Leskovec, and S. Jegelka, How powerful are graph neural networks?, inInternational Conference on Learning Representations(2019)
2019
-
[17]
V. P. Dwivedi, C. K. Joshi, A. T. Luo, T. Laurent, Y. Bengio, and X. Bresson, Benchmarking graph neu- ral networks, Journal of Machine Learning Research24, 1 (2023)
2023
-
[18]
D. Lim, J. Robinson, L. Zhao, T. Smidt, S. Sra, H. Maron, and S. Jegelka, Sign and basis invariant net- works for spectral graph representation learning, inInter- 20 national Conference on Learning Representations(2023)
2023
-
[19]
R. M. Karp, Reducibility among combinatorial problems, inComplexity of Computer Computations(Springer, Boston, MA, 1972) pp. 85–103
1972
-
[20]
M. X. Goemans and D. P. Williamson, Improved approx- imation algorithms for maximum cut and satisfiability problems using semidefinite programming, Journal of the ACM42, 1115 (1995)
1995
-
[21]
H˚ astad, Some optimal inapproximability results, Jour- nal of the ACM48, 798 (2001)
J. H˚ astad, Some optimal inapproximability results, Jour- nal of the ACM48, 798 (2001)
2001
-
[22]
S. Khot, G. Kindler, E. Mossel, and R. O’Donnell, Opti- mal inapproximability results for MAX-CUT and other 2-variable CSPs?, SIAM Journal on Computing37, 319 (2007)
2007
-
[23]
F. G. S. L. Brand˜ ao, M. Broughton, E. Farhi, S. Gut- mann, and H. Napp, For fixed control parameters the quantum approximate optimization algorithm’s objective function value concentrates for typical instances, arXiv preprint arXiv:1812.04170 10.48550/arxiv.1812.04170 (2018)
-
[24]
Akshay, D
V. Akshay, D. Rabinovich, E. Campos, and J. Biamonte, Parameter concentrations in quantum approximate opti- mization, Physical Review A104, L010401 (2021)
2021
-
[25]
Galda, X
A. Galda, X. Liu, D. Lykov, Y. Alexeev, and I. Safro, Transferability of optimal QAOA parameters between random graphs, in2021 IEEE International Conference on Quantum Computing and Engineering (QCE)(IEEE,
-
[26]
J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Bab- bush, and H. Neven, Barren plateaus in quantum neural network training landscapes, Nature Communications9, 4812 (2018)
2018
-
[27]
Arrasmith, M
A. Arrasmith, M. Cerezo, P. Czarnik, L. Cincio, and P. J. Coles, Effect of barren plateaus on gradient-free optimization, Quantum5, 558 (2021)
2021
-
[28]
S. Wang, E. Fontana, M. Cerezo, K. Sharma, A. Sone, L. Cincio, and P. J. Coles, Noise-induced barren plateaus in variational quantum algorithms, Nature Communica- tions12, 6961 (2021)
2021
-
[29]
Kreuzer, D
D. Kreuzer, D. Beaini, W. L. Hamilton, V. L´ etourneau, and P. Tossou, Rethinking graph transformers with spec- tral attention, inAdvances in Neural Information Pro- cessing Systems, Vol. 34 (2021) pp. 21618–21629
2021
-
[30]
Fiedler, Algebraic connectivity of graphs, Czechoslo- vak Mathematical Journal23, 298 (1973)
M. Fiedler, Algebraic connectivity of graphs, Czechoslo- vak Mathematical Journal23, 298 (1973)
1973
-
[31]
Weisfeiler and A
B. Weisfeiler and A. Leman, The reduction of a graph to canonical form and the algebra which appears therein, NTI, Series 29, 12 (1968)
1968
-
[32]
W. L. Hamilton, R. Ying, and J. Leskovec, Inductive rep- resentation learning on large graphs, inAdvances in Neu- ral Information Processing Systems, Vol. 30 (2017)
2017
-
[33]
Gilmer, S
J. Gilmer, S. S. Schoenholz, P. F. Riley, O. Vinyals, and G. E. Dahl, Neural message passing for quantum chem- istry, inInternational Conference on Machine Learning (PMLR, 2017) pp. 1263–1272
2017
-
[34]
D. J. Egger, J. Mareˇ cek, and S. Woerner, Warm-starting quantum optimization, Quantum5, 479 (2021)
2021
-
[35]
S. H. Sack and M. Serbyn, Quantum annealing initializa- tion of the quantum approximate optimization algorithm, Quantum5, 491 (2021)
2021
-
[36]
N. Jain, B. Coyle, E. Kashefi, and N. Kumar, Graph neu- ral network initialisation of quantum approximate opti- misation, Quantum6, 861 (2022)
2022
-
[37]
Khairy, R
S. Khairy, R. Shaydulin, L. Cincio, Y. Alexeev, and P. Balaprakash, Learning to optimize variational quan- tum circuits to solve combinatorial problems, inProceed- ings of the AAAI Conference on Artificial Intelligence, Vol. 34 (2020) pp. 2367–2375
2020
-
[38]
Tibaldi, D
S. Tibaldi, D. Vodola, S. Notarnicola, and S. Montangero, Bayesian optimization for QAOA, Quantum Science and Technology8, 035022 (2023)
2023
-
[39]
R. Shaydulin and S. M. Wild, On the importance of classical preprocessing in QAOA, arXiv preprint arXiv:2306.16979 10.48550/arxiv.2306.16979 (2023)
-
[40]
Streif and M
M. Streif and M. Leib, Training the quantum approxi- mate optimization algorithm without access to a quan- tum processing unit, Quantum Science and Technology 5, 034008 (2020)
2020
-
[41]
Moussa, H
C. Moussa, H. Calandra, and V. Dunjko, Unsupervised strategies for identifying optimal parameters in quan- tum approximate optimization algorithm, EPJ Quantum Technology9, 11 (2022)
2022
-
[42]
Sauvage, S
F. Sauvage, S. Sim, A. A. Kunitsa, W. A. Simon, M. Mauri, and A. Perdomo-Ortiz, Building spatial sym- metries into parameterized quantum circuits for faster training, Quantum Science and Technology9, 015029 (2024)
2024
-
[43]
Bengio, A
Y. Bengio, A. Lodi, and A. Prouvost, Machine learning for combinatorial optimization: a methodological tour d’horizon, European Journal of Operational Research 290, 405 (2021)
2021
-
[44]
Cappart, D
Q. Cappart, D. Ch´ etelat, E. B. Khalil, A. Lodi, C. Mor- ris, and P. Veliˇ ckovi´ c, Combinatorial optimization and reasoning with graph neural networks, Journal of Ma- chine Learning Research24, 1 (2023)
2023
-
[45]
E. B. Khalil, H. Dai, Y. Zhang, B. Dilkina, and L. Song, Learning combinatorial optimization algorithms over graphs, inAdvances in Neural Information Processing Systems, Vol. 30 (2017)
2017
-
[46]
H. Dai, B. Dai, and L. Song, Discriminative embeddings of latent variable models for structured data, inInterna- tional Conference on Machine Learning(PMLR, 2016) pp. 723–732
2016
-
[47]
W. Kool, H. van Hoof, and M. Welling, Attention, learn to solve routing problems!, inInternational Conference on Learning Representations(2019)
2019
-
[48]
M. J. A. Schuetz, J. K. Brubaker, and H. G. Katz- graber, Combinatorial optimization with physics-inspired graph neural networks, Nature Machine Intelligence4, 367 (2022)
2022
-
[49]
D. A. Nix and A. S. Weigend, Estimating the mean and variance of the target probability distribution, inProceed- ings of 1994 IEEE International Conference on Neural Networks, Vol. 1 (IEEE, 1994) pp. 55–60
1994
-
[50]
Kendall and Y
A. Kendall and Y. Gal, What uncertainties do we need in Bayesian deep learning for computer vision?, inAd- vances in Neural Information Processing Systems, Vol. 30 (2017)
2017
-
[51]
Lakshminarayanan, A
B. Lakshminarayanan, A. Pritzel, and C. Blundell, Sim- ple and scalable predictive uncertainty estimation using deep ensembles, inAdvances in Neural Information Pro- cessing Systems, Vol. 30 (2017)
2017
-
[52]
Gal and Z
Y. Gal and Z. Ghahramani, Dropout as a Bayesian ap- proximation: Representing model uncertainty in deep learning, inInternational Conference on Machine Learn- ing(PMLR, 2016) pp. 1050–1059
2016
-
[53]
Kuleshov, N
V. Kuleshov, N. Fenner, and S. Ermon, Accurate uncer- tainties for deep learning using calibrated regression, in 21 International Conference on Machine Learning(PMLR,
-
[54]
Abdar, F
M. Abdar, F. Pourpanah, S. Hussain, D. Rezazadegan, L. Liu, M. Ghavamzadeh, P. Fieguth, X. Cao, A. Khos- ravi, U. R. Acharya, V. Makarenkov, and S. Nahavandi, A review of uncertainty quantification in deep learning: Techniques, applications and challenges, Information Fu- sion76, 243 (2021)
2021
-
[55]
H¨ ullermeier and W
E. H¨ ullermeier and W. Waegeman, Aleatoric and epis- temic uncertainty in machine learning: an introduction to concepts and methods, Machine Learning110, 457 (2021)
2021
-
[56]
A. F. Psaros, X. Meng, Z. Zou, L. Guo, and G. E. Kar- niadakis, Uncertainty quantification in scientific machine learning: Methods, metrics, and comparisons, Journal of Computational Physics477, 111902 (2023)
2023
-
[57]
D. C. Dowson and B. V. Landau, The Fr´ echet distance between multivariate normal distributions, Journal of Multivariate Analysis12, 450 (1982)
1982
-
[58]
Arjovsky, S
M. Arjovsky, S. Chintala, and L. Bottou, Wasserstein generative adversarial networks, inInternational Confer- ence on Machine Learning(PMLR, 2017) pp. 214–223
2017
-
[59]
Frogner, C
C. Frogner, C. Zhang, H. Mobahi, M. Arber, and T. Pog- gio, Learning with a Wasserstein loss, inAdvances in Neural Information Processing Systems, Vol. 28 (2015)
2015
-
[60]
Villani,Optimal Transport: Old and New, Vol
C. Villani,Optimal Transport: Old and New, Vol. 338 (Springer, 2009)
2009
-
[61]
Cuturi, Sinkhorn distances: Lightspeed computation of optimal transport, inAdvances in Neural Information Processing Systems, Vol
M. Cuturi, Sinkhorn distances: Lightspeed computation of optimal transport, inAdvances in Neural Information Processing Systems, Vol. 26 (2013)
2013
-
[62]
Peyr´ e and M
G. Peyr´ e and M. Cuturi, Computational optimal trans- port: With applications to data science, Foundations and Trends in Machine Learning11, 355 (2019)
2019
-
[63]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, A simple framework for contrastive learning of visual representations, inInternational Conference on Machine Learning(PMLR, 2020) pp. 1597–1607
2020
-
[64]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y. Li, and O. Vinyals, Representa- tion learning with contrastive predictive coding, arXiv preprint arXiv:1807.03748 10.48550/arxiv.1807.03748 (2018)
-
[65]
Y. You, T. Chen, Y. Sui, T. Chen, Z. Wang, and Y. Shen, Graph contrastive learning with augmentations, inAd- vances in Neural Information Processing Systems, Vol. 33 (2020) pp. 5812–5823
2020
-
[66]
Suresh, P
S. Suresh, P. Li, C. Hao, and G. Nishi, Adversarial graph augmentation to improve graph contrastive learn- ing, inAdvances in Neural Information Processing Sys- tems, Vol. 34 (2021) pp. 15920–15933
2021
-
[67]
Khosla, P
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, Super- vised contrastive learning, inAdvances in Neural Infor- mation Processing Systems, Vol. 33 (2020) pp. 18661– 18673
2020
-
[68]
Amos, Tutorial on amortized optimization, Founda- tions and Trends in Machine Learning16, 592 (2023)
B. Amos, Tutorial on amortized optimization, Founda- tions and Trends in Machine Learning16, 592 (2023)
2023
-
[69]
T. Chen, X. Chen, W. Chen, H. Heaton, J. Liu, Z. Wang, and W. Yin, Learning to optimize: A primer and a benchmark, Journal of Machine Learning Research23, 1 (2022)
2022
-
[70]
C. Finn, P. Abbeel, and S. Levine, Model-agnostic meta- learning for fast adaptation of deep networks, inInterna- tional Conference on Machine Learning(PMLR, 2017) pp. 1126–1135
2017
-
[71]
R. Shu, H. H. Xu, T.-H. Oh, and K. Swersky, Amortized implicit differentiation for stochastic bilevel optimization, inInternational Conference on Learning Representations (2022)
2022
-
[72]
J. L. Ba, J. R. Kiros, and G. E. Hinton, Layer normalization, arXiv preprint arXiv:1607.06450 10.48550/arxiv.1607.06450 (2016)
-
[73]
J. A. Nelder and R. Mead, A simplex method for function minimization, The Computer Journal7, 308 (1965)
1965
-
[74]
Schuld, V
M. Schuld, V. Bergholm, C. Gogolin, J. Izaac, and N. Kil- loran, Evaluating analytic gradients on quantum hard- ware, Physical Review A99, 032331 (2019)
2019
-
[75]
P. L. Bartlett, D. J. Foster, and M. J. Telgarsky, Spectrally-normalized margin bounds for neural net- works, inAdvances in Neural Information Processing Systems, Vol. 30 (2017)
2017
-
[76]
Neyshabur, S
B. Neyshabur, S. Bhojanapalli, and N. Srebro, A PAC-Bayesian approach to spectrally-normalized margin bounds for neural networks, inInternational Conference on Learning Representations(2018)
2018
-
[77]
Golowich, A
N. Golowich, A. Rakhlin, and O. Shamir, Size- independent sample complexity of neural networks, in Proceedings of the 31st Conference on Learning Theory (2018) pp. 297–299
2018
-
[78]
V. Vovk, A. Gammerman, and G. Shafer,Algorithmic Learning in a Random World(Springer, 2005)
2005
-
[79]
Romano, E
Y. Romano, E. Patterson, and E. Cand` es, Conformalized quantile regression, inAdvances in Neural Information Processing Systems, Vol. 32 (2019)
2019
-
[80]
A. N. Angelopoulos and S. Bates, A gentle introduc- tion to conformal prediction and distribution-free un- certainty quantification, arXiv preprint arXiv:2107.07511 10.48550/arxiv.2107.07511 (2021)
work page internal anchor Pith review doi:10.48550/arxiv.2107.07511 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.