Recognition: unknown
Data-Driven Hamiltonian Reduction for Superconducting Qubits via Meta-Learning
Pith reviewed 2026-05-08 03:58 UTC · model grok-4.3
The pith
Meta-learning trains on device simulations to recover effective qubit Hamiltonians from a handful of hardware measurements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
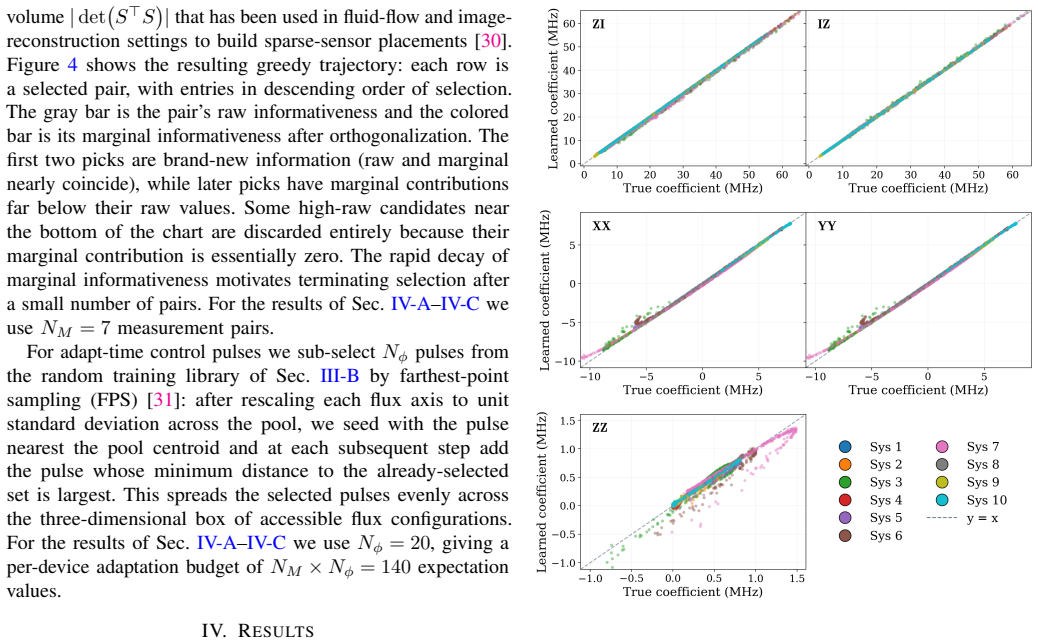
By training directly against effective coefficients extracted from full multi-mode simulations, the meta-model learns to predict the reduced two-qubit Hamiltonian for any control setting and device parameter set; a subsequent greedy selection of measurements then identifies the unknown parameters of a real device in a small number of steps, recovering accurate coefficients even in parameter regions where Schrieffer-Wolff perturbation theory diverges.
What carries the argument
HAML, the meta-learning procedure that trains an offline map from simulated control inputs and device parameters to effective Hamiltonian coefficients, then performs online parameter identification from few measurements.
If this is right
- Calibration and control loops can operate in regimes previously inaccessible to analytic approximations.
- Fewer hardware measurements are required to characterize each new device after the initial training phase.
- Error-mitigation protocols gain access to more accurate effective models without additional analytic derivation.
- The same trained meta-model can be reused across many devices that share the same underlying architecture.
Where Pith is reading between the lines
- The method could be tested by comparing prediction error on devices with deliberately introduced fabrication variations not seen in the training ensemble.
- If successful, the framework suggests replacing analytic reduction steps with data-driven surrogates for other quantum platforms such as ion traps or superconducting resonators.
- Online adaptation speed may allow Hamiltonian tracking during long experimental runs where device parameters drift.
Load-bearing premise
Models trained on simulated device ensembles will generalize accurately to the parameter variations and imperfections of real fabricated hardware.
What would settle it
A real transmon-coupler-transmon device whose effective coefficients measured after the predicted optimal measurements deviate systematically from the values recovered by HAML while remaining consistent with full numerical simulation.
Figures





read the original abstract
We introduce HAML (Hamiltonian Adaptation via Meta-Learning), a framework for fast online adaptation of effective Hamiltonian models of superconducting quantum processors. HAML proceeds in two phases. A supervised training phase uses an ensemble of simulated devices to learn an offline map from control inputs and device parameters to effective Hamiltonian coefficients. An online adaptation phase then uses a small number of hardware-accessible measurements to identify the unknown parameters of a new device. By training directly against effective two-qubit coefficients extracted from full multi-mode simulations, HAML implicitly learns the reduction from full multi-mode Hamiltonians to effective qubit descriptions without invoking perturbation theory. We further show that a variance-maximizing greedy selection of measurement configurations boosts online adaptation efficiency. We demonstrate HAML on a transmon-coupler-transmon system, recovering effective two-qubit coefficients across a wide range of operating regimes, including parameter regions where Schrieffer-Wolff perturbation theory (SWPT) breaks down. This establishes a scalable, sample-efficient approach to Hamiltonian reduction and characterization for near-term quantum processors, with direct implications for calibration, control, and error mitigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HAML (Hamiltonian Adaptation via Meta-Learning), a two-phase framework for data-driven reduction of multi-mode Hamiltonians to effective qubit models in superconducting processors. An offline supervised phase trains a meta-model on an ensemble of simulated devices to map control inputs and device parameters directly to effective two-qubit coefficients extracted from full simulations. An online phase then adapts the model to a new device using a small number of hardware-accessible measurements, with a variance-maximizing greedy strategy for selecting configurations. The approach is demonstrated on a transmon-coupler-transmon system, claiming accurate recovery of effective coefficients in regimes where Schrieffer-Wolff perturbation theory breaks down.
Significance. If the central claims are substantiated with quantitative validation, the work offers a scalable, sample-efficient alternative to analytic perturbation methods for Hamiltonian characterization. Strengths include the implicit learning of the reduction map without explicit perturbation theory and the emphasis on hardware-accessible adaptation, which could directly benefit calibration, control, and error mitigation on near-term devices. The meta-learning formulation and greedy measurement selection are technically interesting contributions.
major comments (3)
- [Abstract / demonstration] Abstract and demonstration section: the claim that HAML 'recovers effective two-qubit coefficients across a wide range of operating regimes, including parameter regions where SWPT breaks down' is unsupported by any quantitative metrics, error bars, fidelity measures, or baseline comparisons (e.g., to direct fitting or other ML methods). Without these, it is impossible to evaluate accuracy, sample efficiency, or the extent of improvement over SWPT.
- [Training target definition] Training target definition (implicit in abstract and §3): effective coefficients are extracted from full multi-mode simulations to serve as training labels. If this extraction step itself relies on fitting an assumed effective-model form (rather than an exact projection), the 'implicit learning without perturbation theory' claim risks circularity precisely in the regimes where the effective description is ill-defined.
- [Online adaptation phase] Generalization claim (abstract and online adaptation phase): the meta-model is trained exclusively on simulated ensembles yet asserted to adapt accurately to real hardware. No evidence or ablation is provided addressing transfer under unmodeled effects such as 1/f flux noise, stray couplings, or readout-induced dephasing that are absent from the training distribution.
minor comments (2)
- [Measurement selection] The variance-maximizing greedy selection procedure is mentioned but its algorithmic details, computational cost, and comparison to random or information-theoretic baselines are not elaborated.
- [Method] Notation for the meta-model input/output spaces and the precise form of the learned map (e.g., neural network architecture, loss function) should be formalized with equations for reproducibility.
Simulated Author's Rebuttal
Thank you for the referee's insightful comments on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract / demonstration] Abstract and demonstration section: the claim that HAML 'recovers effective two-qubit coefficients across a wide range of operating regimes, including parameter regions where SWPT breaks down' is unsupported by any quantitative metrics, error bars, fidelity measures, or baseline comparisons (e.g., to direct fitting or other ML methods). Without these, it is impossible to evaluate accuracy, sample efficiency, or the extent of improvement over SWPT.
Authors: We acknowledge that the current version lacks explicit quantitative metrics in the abstract and demonstration. In the revised manuscript, we will add mean squared errors, error bars from multiple runs, fidelity measures between the effective model and full simulation, and direct comparisons to Schrieffer-Wolff perturbation theory as well as a baseline of direct least-squares fitting on the same measurement data. This will allow clear evaluation of accuracy and sample efficiency. revision: yes
-
Referee: [Training target definition] Training target definition (implicit in abstract and §3): effective coefficients are extracted from full multi-mode simulations to serve as training labels. If this extraction step itself relies on fitting an assumed effective-model form (rather than an exact projection), the 'implicit learning without perturbation theory' claim risks circularity precisely in the regimes where the effective description is ill-defined.
Authors: The extraction of effective coefficients involves diagonalizing the full multi-mode Hamiltonian and projecting onto the computational subspace or fitting the low-lying eigenvalues to the effective two-qubit Hamiltonian. This is not circular because the meta-model learns a direct mapping from parameters to these coefficients without requiring perturbation expansions. However, we agree to clarify this procedure in §3 and add a discussion on the validity of the effective model in the regimes considered, including quantitative checks on the approximation error. revision: partial
-
Referee: [Online adaptation phase] Generalization claim (abstract and online adaptation phase): the meta-model is trained exclusively on simulated ensembles yet asserted to adapt accurately to real hardware. No evidence or ablation is provided addressing transfer under unmodeled effects such as 1/f flux noise, stray couplings, or readout-induced dephasing that are absent from the training distribution.
Authors: The manuscript demonstrates the online adaptation in simulation, including tests with added noise models. We do not claim experimental validation on real hardware in the current version. We will revise the abstract and conclusions to specify that the results are simulation-based and discuss the potential impact of unmodeled effects, proposing that the meta-learning approach can be extended with domain adaptation techniques for hardware deployment. revision: yes
Circularity Check
No significant circularity: meta-learning derives effective coefficients from independent simulation targets
full rationale
The paper trains an offline meta-model on an ensemble of simulated multi-mode devices using effective two-qubit coefficients extracted directly from full simulations as supervised targets, then performs online adaptation via hardware measurements on new devices. This chain does not reduce any central prediction to its inputs by construction, nor invoke load-bearing self-citations or uniqueness theorems. The claim of implicitly learning the Hamiltonian reduction without perturbation theory rests on data-driven training against externally generated simulation targets, which remains verifiable against independent benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Meta-learning can learn a generalizable map from device parameters and controls to effective two-qubit Hamiltonian coefficients when trained on simulated full multi-mode data.
Reference graph
Works this paper leans on
-
[1]
Tunable coupling scheme for implementing high-fidelity two-qubit gates,
F. Yan, P. Krantz, Y . Sung, M. Kjaergaard, D. L. Campbell, T. P. Orlando, S. Gustavsson, and W. D. Oliver, “Tunable coupling scheme for implementing high-fidelity two-qubit gates,”Phys. Rev. Appl., vol. 10, p. 054062, Nov 2018. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevApplied.10.054062
-
[2]
Schrieffer–wolff transformation for quantum many-body systems,
S. Bravyi, D. P. DiVincenzo, and D. Loss, “Schrieffer–wolff transformation for quantum many-body systems,”Annals of Physics, vol. 326, no. 10, pp. 2793–2826, 2011. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0003491611001059
2011
-
[3]
A. Blais, A. L. Grimsmo, S. Girvin, and A. Wallraff, “Circuit quantum electrodynamics,”Reviews of Modern Physics, vol. 93, no. 2, May 2021. [Online]. Available: http://dx.doi.org/10.1103/RevModPhys.93.025005
-
[4]
UnitaryTransformations.jl: Symbolic Unitary Transformations for Quantum Hamiltonians,
V . Karle, “UnitaryTransformations.jl: Symbolic Unitary Transformations for Quantum Hamiltonians,” 2025. [Online]. Available: https://github. com/volkerkarle/UnitaryTransformations.jl
2025
-
[5]
Characterization of tunable coupler without a dedicated readout resonator in superconducting circuits,
C. Zhang, T.-L. Wang, L.-L. Guo, X.-Y . Yang, X.-X. Yang, P. Duan, Z.-L. Jia, W.-C. Kong, and G.-P. Guo, “Characterization of tunable coupler without a dedicated readout resonator in superconducting circuits,”Applied Physics Letters, vol. 122, no. 2, 2023. [Online]. Available: https://pubs.aip.org/aip/apl/article/122/2/024001/ 2876150/Characterization-of-...
2023
-
[6]
X. Li, T. Cai, H. Yan, Z. Wang, X. Pan, Y . Ma, W. Cai, J. Han, Z. Hua, X. Han, Y . Wu, H. Zhang, H. Wang, Y . Song, L. Duan, and L. Sun, “Tunable coupler for realizing a controlled-phase gate with dynamically decoupled regime in a superconducting circuit,” Phys. Rev. Appl., vol. 14, p. 024070, Aug 2020. [Online]. Available: https://link.aps.org/doi/10.11...
-
[7]
Suppression of qubit crosstalk in a tunable coupling superconducting circuit,
P. Mundada, G. Zhang, T. Hazard, and A. Houck, “Suppression of qubit crosstalk in a tunable coupling superconducting circuit,” Phys. Rev. Appl., vol. 12, p. 054023, Nov 2019. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevApplied.12.054023
-
[8]
Modular quantum processor with an all-to-all reconfigurable router,
X. Wu, H. Yan, G. Andersson, A. Anferov, M.-H. Chou, C. R. Conner, J. Grebel, Y . J. Joshi, S. Li, J. M. Miller, R. G. Povey, H. Qiao, and A. N. Cleland, “Modular quantum processor with an all-to-all reconfigurable router,”Phys. Rev. X, vol. 14, p. 041030, Nov 2024. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevX.14.041030
-
[9]
Mitigating cosmic-ray-like correlated events with a modular quantum processor,
X. Wu, Y . J. Joshi, H. Yan, G. Andersson, A. Anferov, C. R. Conner, B. Karimi, A. M. King, S. Li, H. L. Malc, J. M. Miller, H. Mishra, H. Qiao, M. Ryu, S. Xing, J. Shi, and A. N. Cleland, “Mitigating cosmic-ray-like correlated events with a modular quantum processor,” Phys. Rev. Appl., vol. 24, p. 044022, Oct 2025. [Online]. Available: https://link.aps.o...
-
[10]
Universal gate for fixed-frequency qubits via a tunable bus,
D. C. McKay, S. Filipp, A. Mezzacapo, E. Magesan, J. M. Chow, and J. M. Gambetta, “Universal gate for fixed-frequency qubits via a tunable bus,”Phys. Rev. Appl., vol. 6, p. 064007, Dec 2016. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevApplied.6.064007
-
[11]
Tunable coupling architecture for fixed-frequency transmon superconducting qubits,
J. Stehlik, D. M. Zajac, D. L. Underwood, T. Phung, J. Blair, S. Carnevale, D. Klaus, G. A. Keefe, A. Carniol, M. Kumph, M. Steffen, and O. E. Dial, “Tunable coupling architecture for fixed-frequency transmon superconducting qubits,”Phys. Rev. Lett., vol. 127, p. 080505, Aug 2021. [Online]. Available: https: //link.aps.org/doi/10.1103/PhysRevLett.127.080505
-
[12]
F. Arute, K. Arya, R. Babbush, D. Bacon, J. C. Bardin, R. Barends, R. Biswas, S. Boixo, F. G. Brandao, D. A. Buellet al., “Quantum supremacy using a programmable superconducting processor,” nature, vol. 574, no. 7779, pp. 505–510, 2019. [Online]. Available: https://doi.org/10.1038/s41586-019-1666-5
-
[13]
Abanin, Laleh Aghababaie-Beni, Igor Aleiner, Trond I
“Quantum error correction below the surface code threshold,” Nature, vol. 638, no. 8052, pp. 920–926, 2025. [Online]. Available: https://doi.org/10.1038/s41586-024-08449-y
-
[14]
Bilinear dynamic mode decomposition for quantum control,
A. Goldschmidt, E. Kaiser, J. L. Dubois, S. L. Brunton, and J. N. Kutz, “Bilinear dynamic mode decomposition for quantum control,”New Journal of Physics, vol. 23, no. 3, p. 033035, 2021. [Online]. Available: https://iopscience.iop.org/article/10.1088/1367-2630/abe972/meta
-
[15]
Experimental graybox quantum system identification and control,
A. Youssry, Y . Yang, R. J. Chapman, B. Haylock, F. Lenzini, M. Lobino, and A. Peruzzo, “Experimental graybox quantum system identification and control,”npj Quantum Information, vol. 10, p. 9, 2024
2024
-
[16]
Quantum optimal control of superconducting qubits based on machine-learning characterization,
E. Genois, N. J. Stevenson, N. Goss, I. Siddiqi, and A. Blais, “Quantum optimal control of superconducting qubits based on machine-learning characterization,”Phys. Rev. Appl., vol. 24, p. 034073, Sep 2025. [Online]. Available: https://link.aps.org/doi/10.1103/d9yg-d3qr
-
[17]
Model-free quantum control with reinforcement learning,
V . V . Sivak, A. Eickbusch, H. Liu, B. Royer, I. Tsioutsios, and M. H. Devoret, “Model-free quantum control with reinforcement learning,”Physical Review X, vol. 12, 03 2022. [Online]. Available: https://doi.org/10.1103/PhysRevX.12.011059
-
[18]
Efficient n-qubit entangling operations via a superconducting quantum router,
X. Wu, H. Yan, G. Andersson, A. Anferov, C. R. Conner, Y . J. Joshi, B. Karimi, A. M. King, S. Li, H. L. Malc, J. M. Miller, H. Mishra, H. Qiao, M. Ryu, J. Shi, and A. N. Cleland, “Efficient n-qubit entangling operations via a superconducting quantum router,” 4 2026
2026
-
[19]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inProceedings of the 34th International Conference on Machine Learning - Volume 70, ser. ICML’17. JMLR.org, 2017, p. 1126–1135
2017
-
[20]
Fast context adaptation via meta-learning,
L. Zintgraf, K. Shiarlis, V . Kurin, K. Hofmann, and S. Whiteson, “Fast context adaptation via meta-learning,” inProceedings of the 36th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 97. PMLR, 2019, pp. 7693–7702
2019
-
[21]
Advanced CMOS manufacturing of superconducting qubits on 300 mm wafers,
J. Van Damme, S. Massar, R. Acharya, T. Ivanov, D. Perez Lozano, Y . Canvel, M. Demarets, D. Vangoidsenhoven, Y . Hermans, J. G. Lai, A. M. Vadiraj, M. Mongillo, D. Wan, J. De Boeck, A. Poto ˇcnik, and K. De Greve, “Advanced CMOS manufacturing of superconducting qubits on 300 mm wafers,”Nature, vol. 634, no. 8032, p. 74–79, sep
-
[22]
Advanced CMOS manufacturing of superconducting qubits on 300 mm wafers
[Online]. Available: http://dx.doi.org/10.1038/s41586-024-07941-9
-
[23]
Decoherence benchmarking of superconducting qubits,
J. J. Burnett, A. Bengtsson, M. Scigliuzzo, D. Niepce, M. Kudra, P. Delsing, and J. Bylander, “Decoherence benchmarking of superconducting qubits,”npj Quantum Information, vol. 5, no. 1, jun
-
[24]
Decoherence benchmarking of su- perconducting qubits,
[Online]. Available: http://dx.doi.org/10.1038/s41534-019-0168-5
-
[25]
Metalearning generalizable dynamics from trajectories,
Q. Li, T. Wang, V . Roychowdhury, and M. K. Jawed, “Metalearning generalizable dynamics from trajectories,”Phys. Rev. Lett., vol. 131, p. 067301, Aug 2023. [Online]. Available: https://link.aps.org/doi/10.1103/ PhysRevLett.131.067301
2023
-
[26]
Meta-learning characteristics and dynamics of quantum systems,
L. Schorling, P. Vaidhyanathan, J. Schuff, M. J. Carballido, D. Zumb ¨uhl, G. Milburn, F. Marquardt, J. Foerster, M. A. Osborne, and N. Ares, “Meta-learning characteristics and dynamics of quantum systems,” 2025. [Online]. Available: https://arxiv.org/abs/2503.10492
-
[27]
Neural ordinary differential equations,
R. T. Q. Chen, Y . Rubanova, J. Bettencourt, and D. Duvenaud, “Neural ordinary differential equations,” inProceedings of the 32nd International Conference on Neural Information Processing Systems, ser. NIPS’18. Red Hook, NY , USA: Curran Associates Inc., 2018, p. 6572–6583. [Online]. Available: https://dl.acm.org/doi/10.5555/3327757.3327764
-
[28]
T.-M. Li, J.-C. Zhang, B.-J. Chen, K. Huang, H.-T. Liu, Y .-X. Xiao, C.-L. Deng, G.-H. Liang, C.-T. Chen, Y . Liu, H. Li, Z.-T. Bao, K. Zhao, Y . Xu, L. Li, Y . He, Z.-H. Liu, Y .-H. Yu, S.-Y . Zhou, Y .-J. Liu, X. Song, D. Zheng, Z. Xiang, Y .-H. Shi, K. Xu, and H. Fan, “High-precision pulse calibration of tunable couplers for high-fidelity two-qubit gat...
-
[29]
X. Zhang, X. Zhang, C. Chen, K. Tang, K. Yi, K. Luo, Z. Xie, Y . Chen, and T. Yan, “Characterization and optimization of tunable couplers via adiabatic control in superconducting circuits,”Phys. Rev. Appl., vol. 24, p. 034003, Sep 2025. [Online]. Available: https://link.aps.org/doi/10.1103/wgqf-8rcy
-
[30]
Comprehensive explanation of ZZ coupling in superconducting qubits,
S. P. Fors, J. Fern ´andez-Pend´as, and A. F. Kockum, “Comprehensive explanation of ZZ coupling in superconducting qubits,”arXiv preprint arXiv:2408.15402, 2024
-
[31]
P.-O. L¨owdin, “On the non-orthogonality problem connected with the use of atomic wave functions in the theory of molecules and crystals,” The Journal of Chemical Physics, vol. 18, no. 3, pp. 365–375, 1950. [Online]. Available: https://doi.org/10.1063/1.1747632
-
[32]
Data-driven sparse sensor placement for reconstruction: Demonstrating the benefits of exploiting known patterns,
K. Manohar, B. W. Brunton, J. N. Kutz, and S. L. Brunton, “Data-driven sparse sensor placement for reconstruction: Demonstrating the benefits of exploiting known patterns,”IEEE Control Systems Magazine, vol. 38, no. 3, pp. 63–86, 2018
2018
-
[33]
The farthest point strategy for progressive image sampling,
Y . Eldar, M. Lindenbaum, M. Porat, and Y . Y . Zeevi, “The farthest point strategy for progressive image sampling,”IEEE Transactions on Image Processing, vol. 6, no. 9, pp. 1305–1315, 1997
1997
-
[34]
Quantum-tailored machine-learning characterization of a superconducting qubit,
E. Genois, J. A. Gross, A. Di Paolo, N. J. Stevenson, G. Koolstra, A. Hashim, I. Siddiqi, and A. Blais, “Quantum-tailored machine-learning characterization of a superconducting qubit,”PRX Quantum, vol. 2, p. 040355, Dec 2021. [Online]. Available: https://link.aps.org/doi/10.1103/ PRXQuantum.2.040355
2021
-
[35]
cuquantum sdk: A high-performance library for accelerating quantum science,
H. Bayraktar, A. Charara, D. Clark, S. Cohen, T. Costa, Y .-L. L. Fang, Y . Gao, J. Guan, J. Gunnels, A. Haidar, A. Hehn, M. Hohnerbach, M. Jones, T. Lubowe, D. Lyakh, S. Morino, P. Springer, S. Stanwyck, 11 I. Terentyev, S. Varadhan, J. Wong, and T. Yamaguchi, “cuquantum sdk: A high-performance library for accelerating quantum science,” in2023 IEEE Inter...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.