Recognition: unknown
Enabling High Error Tolerance in Satellite Video Transmissions by Generative Semantic Communication
Pith reviewed 2026-05-07 15:35 UTC · model grok-4.3
The pith
Generative semantic communication reconstructs satellite video from over 80 percent corrupted signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
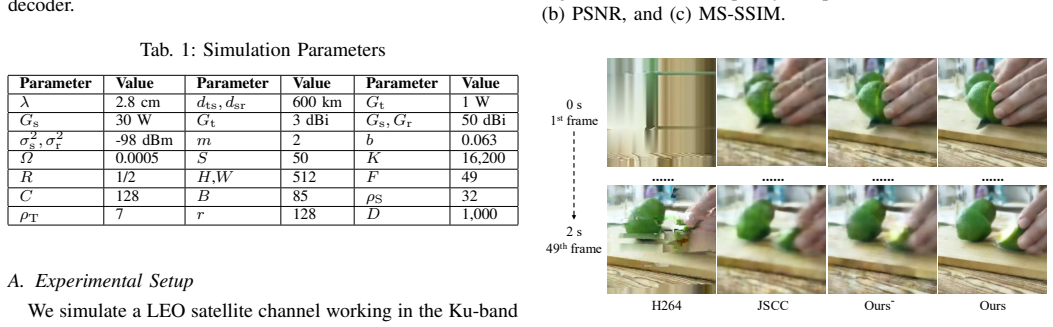
The authors design a generative semantic communication system in which the transmitter integrates a pre-trained video encoder with an LDPC encoder to produce forward-error-correctable semantic features, while the receiver applies an efficient in-context adaptation algorithm to fine-tune a generative video model that reconstructs semantically consistent frames from highly error-corrupted inputs, yielding 2.5 dB higher peak SNR than conventional semantic methods at 45 percent error rate and maintained robustness above 80 percent error rate.
What carries the argument
The generative video model after efficient in-context adaptation, which reconstructs semantically consistent video frames from error-corrupted semantic features.
If this is right
- Real-time video can be transmitted without repeated retransmissions over satellite channels.
- User devices can operate at lower transmit power while still delivering usable video.
- Mobile network coverage extends to remote regions for event-based video streaming.
- The same semantic-plus-generative structure could apply to other high-dimensional data such as 3D maps or sensor streams.
Where Pith is reading between the lines
- The adaptation technique might transfer to other generative models for audio or image streams under similar channel conditions.
- Deploying the system on actual LEO satellites would reveal whether the simulated error rates match orbital conditions and whether adaptation remains stable over time.
- Reducing the need for retransmissions could lower overall latency and energy use in satellite-relay networks.
Load-bearing premise
The generative video model can reliably produce semantically consistent frames even when more than 80 percent of the received semantic features are erroneous.
What would settle it
A simulation or measurement in which video peak SNR falls below the conventional baseline or semantic consistency is lost once the error rate exceeds 80 percent would falsify the robustness claim.
Figures




read the original abstract
Low Earth orbit (LEO) satellite relays will significantly extend the coverage of mobile networks, enabling users in remote areas to transmit data of real-time events. Nevertheless, the limited power of user devices and the long distance to satellites lead to low signal-to-noise ratio (SNR), which results in high error rates and frequent retransmissions, severely hindering the transmissions of high-dimensional data such as videos. In this paper, we propose a novel method to achieve high error tolerance in satellite-relay video transmissions using generative semantic communications (GSC). For the transmitter, we design and optimize a semantic encoder integrating a pre-trained video encoder with a low-density parity-check (LDPC) encoder, efficiently achieving generalizability and enabling forward error correction. For the receiver, we fine-tune a generative video model using an efficient in-context adaptation algorithm, enabling it to reconstruct videos from error-corrupted semantic information. Simulation results show that our method achieves 2.5 dB higher video peak SNR than conventional semantic communications at an error rate of 45%, and remains robust when the error rate exceeds 80%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a generative semantic communication (GSC) framework for video transmission over LEO satellite relays subject to low SNR and high error rates. The transmitter integrates a pre-trained video encoder with LDPC coding to produce error-protected semantic features. The receiver applies an efficient in-context adaptation algorithm to fine-tune a generative video model, enabling reconstruction of semantically consistent frames from corrupted features. Simulations report a 2.5 dB PSNR gain relative to conventional semantic communications at 45% error rate, with robustness asserted for error rates exceeding 80%.
Significance. If the in-context adaptation reliably supports reconstruction at error rates above 80%, the work could meaningfully advance semantic communications for power-limited satellite video links by reducing retransmission overhead and enabling operation in challenging low-SNR regimes. The combination of pre-trained encoders with LDPC for generalizability and generative models for error tolerance is a constructive direction; the simulation-based evidence of a concrete PSNR improvement provides a falsifiable benchmark that strengthens the contribution if the experimental setup is fully documented.
minor comments (4)
- The abstract states performance gains but omits any mention of the underlying channel model, noise distribution, or how the 45% and >80% error rates are realized; the full text should explicitly define these in the simulation setup section to allow readers to assess robustness.
- The description of the in-context adaptation algorithm would benefit from a concise pseudocode or step-by-step outline, including the number of adaptation steps, learning rate schedule, and how corrupted semantic features are presented as context, to support reproducibility.
- Baseline comparisons should specify the exact implementation of 'conventional semantic communications' (e.g., which semantic encoder/decoder pair and whether it also employs LDPC), along with any hyperparameter matching, to clarify the source of the reported 2.5 dB gain.
- Notation for error rate should be clarified once (bit error rate versus semantic feature corruption rate) and used consistently; the current phrasing leaves ambiguity about whether the generative model receives partially erased or fully random features.
Simulated Author's Rebuttal
We thank the referee for the constructive summary and positive recommendation of minor revision. The assessment accurately captures the core contributions of the GSC framework, including the integration of pre-trained encoders with LDPC for generalizability and in-context adaptation for error resilience. No specific major comments were provided in the report, so we have no point-by-point rebuttals to address. We remain available to incorporate any minor clarifications or additional documentation requested by the editor.
Circularity Check
No significant circularity
full rationale
The paper describes a transmitter design integrating a pre-trained video encoder with LDPC encoding and a receiver that fine-tunes a generative video model via in-context adaptation, then reports simulation outcomes (2.5 dB PSNR gain at 45% error rate, robustness above 80%). No equations, derivations, or first-principles results are presented that reduce the performance claims to fitted parameters by construction, self-definitional loops, or load-bearing self-citations. The central claims rest on external simulation benchmarks rather than renaming or smuggling in prior results from the same authors, making the derivation chain self-contained against the stated method and results.
Axiom & Free-Parameter Ledger
free parameters (1)
- in-context adaptation hyperparameters
axioms (1)
- domain assumption A generative video model can be fine-tuned to produce semantically consistent frames from error-corrupted features.
Reference graph
Works this paper leans on
-
[1]
Evolution of Non-Terrestrial Networks From 5G to 6G: A Survey,
M. M. Azari, S. Solanki, S. Chatzinotas, O. Kodheli, H. Sallouha, A. Col- paert, J. F. Mendoza Montoya, S. Pollin, A. Haqiqatnejad, A. Mostaani, E. Lagunas, and B. Ottersten, “Evolution of Non-Terrestrial Networks From 5G to 6G: A Survey,”IEEE Commun. Surv. Tutor ., vol. 24, no. 4, pp. 2633–2672, Fourthquarter 2022
2022
-
[2]
Ultra-dense leo satellite- based communication systems: A novel modeling technique,
R. Wang, M. A. Kishk, and M.-S. Alouini, “Ultra-dense leo satellite- based communication systems: A novel modeling technique,”IEEE Communications Magazine, vol. 60, no. 4, pp. 25–31, Apr. 2022
2022
-
[3]
Enhancement of direct leo satellite-to-smartphone communications by distributed beam- forming,
Z. Xu, G. Chen, R. Fernandez, Y . Gao, and R. Tafazolli, “Enhancement of direct leo satellite-to-smartphone communications by distributed beam- forming,”IEEE Trans. V eh. Technol., vol. 73, no. 8, pp. 11 543–11 555, Aug. 2024
2024
-
[4]
Deep learning enabled semantic communication systems,
H. Xie, Z. Qin, G. Y . Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,”IEEE Trans. Signal Process., vol. 69, pp. 2663–2675, Apr. 2021
2021
-
[5]
Distillation-Enabled Knowledge Alignment Protocol for Semantic Communication in AI Agent Networks,
J. Hu and G. Y . Li, “Distillation-Enabled Knowledge Alignment Protocol for Semantic Communication in AI Agent Networks,”IEEE Commun. Lett., vol. 29, no. 11, pp. 2541–2545, Aug. 2025
2025
-
[6]
Joint Source and Channel Coding for Multi-Modal Satellite-to-Ground Semantic Communications,
Y . Yin, S. Liu, D. Wen, Y . Wu, and Y . Shi, “Joint Source and Channel Coding for Multi-Modal Satellite-to-Ground Semantic Communications,” inProc. IEEE WCNC, Milan, Italy, Mar 2025
2025
-
[7]
Semantic image encoding and communication for earth observation with leo satellites,
V .-P. Bui, Thinh Quang Dinh, I. Leyva-Mayorga, S. R. Pandey, E. La- gunas, and P. Popovski, “Semantic image encoding and communication for earth observation with leo satellites,”IEEE Trans. Cogn. Commun. Netw., vol. 11, no. 2, pp. 1210–1224, Apr 2025
2025
-
[8]
Free space optical semantic communication for satellite remote sensing image transmission,
W. Chen, C. Ju, T. Yuan, Y . Zhan, M. Zhang, and D. Wang, “Free space optical semantic communication for satellite remote sensing image transmission,”IEEE Trans. Commun., Apr 2025, Early Access
2025
-
[9]
Semantic communication in satellite-borne edge cloud network for computation offloading,
G. Zheng, Q. Ni, K. Navaie, and H. Pervaiz, “Semantic communication in satellite-borne edge cloud network for computation offloading,”IEEE J. Sel. Areas Commun., vol. 42, no. 5, pp. 1145–1158, May 2024
2024
-
[10]
Semantic Satellite Communications Based on Generative Foundation Model,
P. Jiang, C.-K. Wen, X. Li, S. Jin, and G. Y . Li, “Semantic Satellite Communications Based on Generative Foundation Model,”IEEE J. Sel. Areas Commun., vol. 43, no. 7, pp. 2431–2445, Jul 2025
2025
-
[11]
In-context lora for diffusion transformers.arXiv preprint arXiv:2410.23775, 2024a
L. Huang, W. Wang, Z.-F. Wu, Y . Shi, H. Dou, C. Liang, Y . Feng, Y . Liu, and J. Zhou, “In-context LoRA for diffusion transformers,” arXiv:2410.23775, Nov. 2024
-
[12]
Per- formance analysis of leo satellite-based iot networks in the presence of interference,
A. K. Dwivedi, S. Chaudhari, N. Varshney, and P. K. Varshney, “Per- formance analysis of leo satellite-based iot networks in the presence of interference,”IEEE Internet Things J., vol. 11, no. 5, pp. 8783–8799, May 2023
2023
-
[13]
I. S. Gradshteyn and I. M. Ryzhik,Tables of Integrals, Series, and Products. New York, NY , USA: Academic Press, 2000
2000
-
[14]
A survey on video diffusion models,
Z. Xing, Q. Feng, H. Chen, Q. Dai, H. Hu, H. Xu, Z. Wu, and Y .-G. Jiang, “A survey on video diffusion models,”ACM Comput. Surv., vol. 57, no. 2, pp. 1–42, Nov. 2024
2024
-
[15]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review arXiv 2010
-
[16]
DeepWiVe: Deep-Learning-Aided Wireless Video Transmission,
T.-Y . Tung and D. G ¨und¨uz, “DeepWiVe: Deep-Learning-Aided Wireless Video Transmission,”IEEE J. Sel. Areas Commun., vol. 40, no. 9, pp. 2570–2583, Sep. 2022
2022
-
[17]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proc. IEEE/CVF CVPR, Salt Lake City, UT, USA, Jun 2018
2018
-
[18]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv:1412.6980, Dec. 2014
work page internal anchor Pith review arXiv 2014
-
[19]
Distillation-Enabled Knowledge Alignment for Gen- erative Semantic Communications of AIGC Images,
J. Hu and G. Y . Li, “Distillation-Enabled Knowledge Alignment for Gen- erative Semantic Communications of AIGC Images,”arXiv:2506.19893, Jan. 2026
-
[20]
Study on New Radio (NR) to support non-terrestrial networks,
3GPP, “Study on New Radio (NR) to support non-terrestrial networks,” Technical Report, TR 38.811, Sep. 2020, Release 15
2020
-
[21]
EN 302 307-1, 2014
ETSI,Digital Video Broadcasting (DVB-S2) Standard, European Telecommunications Standards Institute Std. EN 302 307-1, 2014
2014
-
[22]
LTX-Video: Realtime Video Latent Diffusion
Y . HaCohen, N. Chiprut, B. Brazowski, D. Shalem, D. Moshe, E. Richard- son, E. Levin, G. Shiran, N. Zabari, O. Gordonet al., “Ltx-video: Realtime video latent diffusion,”arXiv:2501.00103, Dec. 2024
work page internal anchor Pith review arXiv 2024
-
[23]
Perception Encoder: The best visual embeddings are not at the output of the network
D. Bolya, P.-Y . Huang, P. Sun, J. H. Cho, A. Madotto, C. Wei, T. Ma, J. Zhi, J. Rajasegaran, H. Rasheedet al., “Perception encoder: The best vi- sual embeddings are not at the output of the network,”arXiv:2504.13181, Apr. 2025
work page internal anchor Pith review arXiv 2025
-
[24]
Overview of the H.264/A VC video coding standard,
T. Wiegand, G. Sullivan, G. Bjontegaard, and A. Luthra, “Overview of the H.264/A VC video coding standard,”IEEE Trans. Circuits Syst. Video Technol., vol. 13, no. 7, pp. 560–576, Jul. 2003
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.