Optimization-Free Topological Sort for Causal Discovery via the Schur Complement of Score Jacobians
Pith reviewed 2026-05-07 16:40 UTC · model grok-4.3
The pith
Topological order for causal graphs can be recovered by Schur complements on the score-Jacobian matrix of an unconstrained generative model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
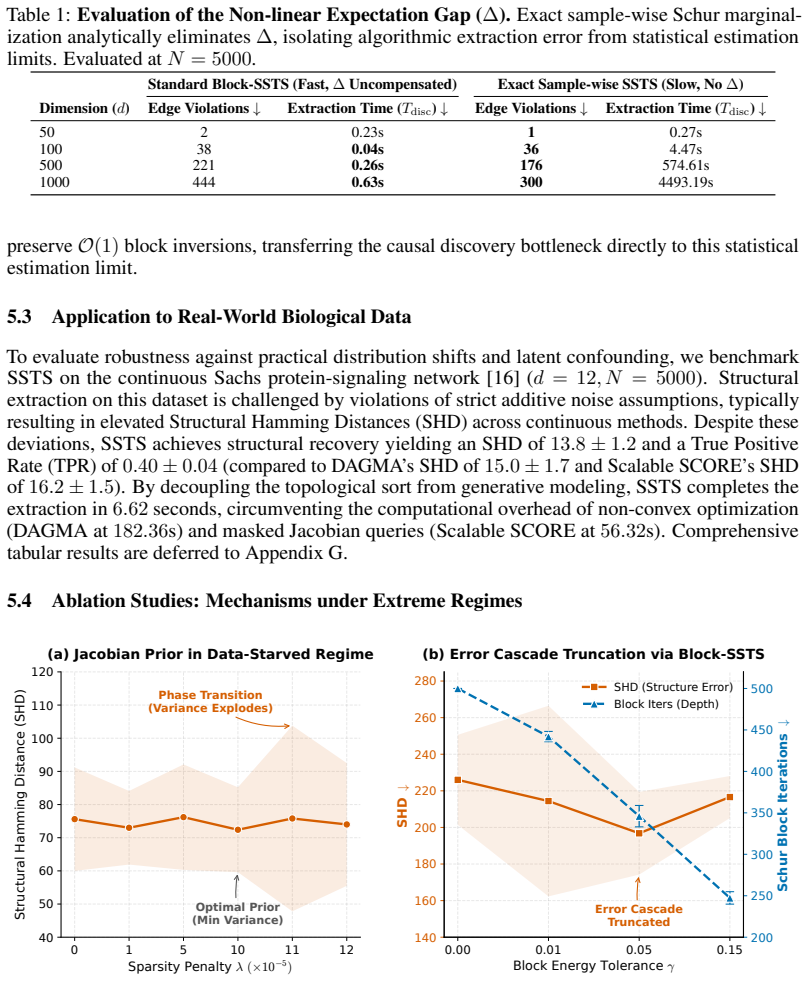
Iterative graph marginalization is mathematically equivalent to computing the Schur complement of the Score-Jacobian Information Matrix (SJIM) derived from the score function. Consequently, a topological order can be extracted directly from the score geometry of an unconstrained model by a sequence of matrix operations whose dominant cost is O(d^3). For nonlinear systems the same reduction produces an expectation gap that Block-SSTS controls by limiting extraction depth, so that structural error remains bounded by finite-sample score variance.
What carries the argument
The Score-Schur Topological Sort (SSTS) algorithm, which repeatedly applies the Schur complement to the SJIM to peel off sink nodes and recover the causal hierarchy.
If this is right
- Causal discovery reduces to statistical score estimation rather than constrained structure optimization.
- Graphs with a thousand variables become feasible because the dominant cost is now matrix arithmetic instead of iterative non-convex search.
- Once score estimation is accurate, further gains come only from better finite-sample geometry recovery rather than from improved optimizers.
- Block-SSTS provides an explicit depth-error trade-off that lets practitioners control structural fidelity on nonlinear data.
Where Pith is reading between the lines
- Any improvement in global score estimation (e.g., via better neural architectures or regularization) immediately translates into higher-fidelity causal orders without changes to the extraction routine.
- The same Schur-reduction view may apply to other ordering problems whose constraints can be expressed as successive marginalizations.
- In high-dimensional regimes the limiting factor shifts from algorithmic scalability to the statistical question of how much data is required to make the score geometry faithful to the true causal hierarchy.
Load-bearing premise
The causal hierarchy must leave a geometric signature inside the score function that survives finite-sample estimation and that the Schur complement recovers exactly when the system is linear.
What would settle it
A linear Gaussian structural equation model with known ground-truth order whose recovered SSTS order differs from the true order after exact score computation, or a nonlinear system where increasing sample size fails to reduce structural error below the bound predicted by the expectation-gap analysis.
Figures


read the original abstract
Continuous causal discovery typically couples representation learning with structural optimization via non-convex acyclicity penalties, which subjects solvers to local optima and restricts scalability in high-dimensional regimes. We propose a decoupled paradigm that shifts the causal discovery bottleneck from non-convex optimization to statistical score estimation. We introduce the Score-Schur Topological Sort (SSTS), an algorithm that extracts topological order directly from unconstrained generative models, bypassing constrained structure optimization. We establish that the causal hierarchy leaves a geometric signature within the score function: iterative graph marginalization is mathematically equivalent to computing the Schur complement of the Score-Jacobian Information Matrix (SJIM) under linear conditions. This translates the acyclicity constraint into an algebraic procedure with a dominant cost of O(d^3) operations. For non-linear systems, we formulate the expectation gap of Schur marginalization and introduce Block-SSTS to compress extraction depth, bounding structural error. Empirically, SSTS allows causal structural analysis on non-linear graphs up to d=1000. At this scale, our framework indicates that once the non-convex optimization bottleneck is mathematically bypassed, the structural fidelity of continuous causal discovery is bounded by the finite-sample estimation variance of the global score geometry. By reducing graph extraction to matrix operations, this work reframes scalable causal discovery from a constrained optimization problem to a statistical estimation challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Score-Schur Topological Sort (SSTS) algorithm for continuous causal discovery. It decouples representation learning from structural optimization by extracting topological order directly from unconstrained generative models via the Schur complement of the Score-Jacobian Information Matrix (SJIM). The central claim is that iterative graph marginalization is mathematically equivalent to this Schur complement operation under linear conditions, with an expectation-gap formulation and Block-SSTS variant for nonlinear systems that bounds structural error; the approach is shown to scale to d=1000 by reframing the problem as statistical estimation of global score geometry rather than non-convex acyclicity-constrained optimization.
Significance. If the equivalence holds with controlled error propagation, the work would meaningfully shift the bottleneck in continuous causal discovery from non-convex optimization to finite-sample score estimation, enabling larger-scale analyses without acyclicity penalties. The reframing as a matrix-algebraic procedure with O(d^3) cost is a clear conceptual contribution, though its practical impact hinges on the unshown derivation and perturbation bounds.
major comments (2)
- [Abstract] Abstract: the claim that 'iterative graph marginalization is mathematically equivalent to computing the Schur complement of the Score-Jacobian Information Matrix (SJIM) under linear conditions' is asserted without derivation steps, proof sketch, or reference to lemmas; this equivalence is load-bearing for the entire contribution and must be supplied with explicit algebraic steps (e.g., relating the score Jacobian of a linear Gaussian model to a scalar multiple of the precision matrix and showing that Schur complements implement the required marginalization).
- [Abstract] Abstract: no explicit error-propagation analysis or bound is given on how entry-wise finite-sample perturbations in the estimated SJIM accumulate across the d successive Schur marginalization steps required for a full topological order; matrix perturbation theory indicates that small errors can be amplified when pivots are small or the matrix is ill-conditioned, directly undermining the claim that the causal hierarchy's geometric signature survives realistic sample sizes.
minor comments (1)
- [Abstract] Abstract: the empirical statement that SSTS 'allows causal structural analysis on non-linear graphs up to d=1000' lacks any mention of validation metrics, baseline comparisons, or sample-size regimes used to support the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below. Where the manuscript requires additional clarification or analysis, we commit to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'iterative graph marginalization is mathematically equivalent to computing the Schur complement of the Score-Jacobian Information Matrix (SJIM) under linear conditions' is asserted without derivation steps, proof sketch, or reference to lemmas; this equivalence is load-bearing for the entire contribution and must be supplied with explicit algebraic steps (e.g., relating the score Jacobian of a linear Gaussian model to a scalar multiple of the precision matrix and showing that Schur complements implement the required marginalization).
Authors: We agree that the abstract states the equivalence without inline derivation steps. The full algebraic derivation appears in Section 3 (Lemma 3.1 and Theorem 3.2), which explicitly relates the score Jacobian of a linear Gaussian model to a scalar multiple of the precision matrix and demonstrates that successive Schur complements implement the marginalization operations required for topological ordering. In the revised manuscript we will update the abstract to include a direct reference to Lemma 3.1 and add a one-sentence proof sketch in the introduction for immediate accessibility. revision: yes
-
Referee: [Abstract] Abstract: no explicit error-propagation analysis or bound is given on how entry-wise finite-sample perturbations in the estimated SJIM accumulate across the d successive Schur marginalization steps required for a full topological order; matrix perturbation theory indicates that small errors can be amplified when pivots are small or the matrix is ill-conditioned, directly undermining the claim that the causal hierarchy's geometric signature survives realistic sample sizes.
Authors: We acknowledge that an explicit finite-sample perturbation analysis for the linear case is not provided. The manuscript does supply an expectation-gap formulation and structural-error bounds for the nonlinear Block-SSTS variant, and it reframes the problem as statistical estimation of score geometry. However, we agree that a dedicated perturbation bound tracking accumulation over d Schur steps (including conditioning and pivot-size considerations) would address the referee's concern. We will add this analysis, drawing on standard matrix perturbation results, in a new subsection of the linear-case development and an accompanying appendix. revision: yes
Circularity Check
No significant circularity; central equivalence is an algebraic derivation from score functions and Schur complements.
full rationale
The paper derives that iterative graph marginalization equals Schur complement computation on the SJIM under linear conditions as a direct mathematical equivalence, without reducing to fitted parameters, self-definitions, or load-bearing self-citations. The abstract presents this as established from properties of score Jacobians and matrix operations, reframing the problem as statistical estimation rather than optimization. No ansatzes, uniqueness theorems from prior self-work, or renamings of known results are invoked in the derivation chain. Finite-sample error is acknowledged as a separate challenge, not part of the core algebraic claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The causal hierarchy leaves a geometric signature within the score function
Reference graph
Works this paper leans on
-
[1]
Dagma: Learning dags via m-matrices and a log-determinant acyclicity characterization
Kevin Bello, Bryon Aragam, and Pradeep Ravikumar. Dagma: Learning dags via m-matrices and a log-determinant acyclicity characterization. InAdvances in Neural Information Processing Systems, volume 35, pages 8226–8239, 2022
work page 2022
-
[2]
Peter Bühlmann, Jonas Peters, and Jan Ernest. Cam: Causal additive models, high-dimensional order search and penalized regression.The Annals of Statistics, 42(6):2526–2556, 2014
work page 2014
-
[3]
Sparse inverse covariance estimation with the graphical lasso.Biostatistics, 9(3):432–441, 2008
Jerome Friedman, Trevor Hastie, and Robert Tibshirani. Sparse inverse covariance estimation with the graphical lasso.Biostatistics, 9(3):432–441, 2008
work page 2008
-
[4]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
work page 2020
-
[5]
Nonlinear causal discovery with additive noise models
Patrik O Hoyer, Dominik Janzing, Joris M Mooij, Jonas Peters, and Bernhard Schölkopf. Nonlinear causal discovery with additive noise models. InAdvances in Neural Information Processing Systems, volume 21, pages 689–696, 2008
work page 2008
-
[6]
Aapo Hyvärinen. Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6:695–709, 2005
work page 2005
-
[7]
Ilyes Khemakhem, Ricardo Monti, Robert Leech, and Aapo Hyvarinen. Causal autoregressive flows. InInternational Conference on Artificial Intelligence and Statistics, pages 3520–3528. PMLR, 2021
work page 2021
-
[8]
Gradient- based neural DAG learning
Sébastien Lachapelle, Philippe Brouillard, Tristan Deleu, and Simon Lacoste-Julien. Gradient- based neural DAG learning. InInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[9]
Steffen L Lauritzen.Graphical Models, volume 17. Clarendon Press, 1996
work page 1996
-
[10]
Dibs: Differentiable bayesian structure learning
Lars Lorch, Jonas Rothfuss, Bernhard Schölkopf, and Andreas Krause. Dibs: Differentiable bayesian structure learning. InAdvances in Neural Information Processing Systems, volume 34, pages 24111–24123, 2021
work page 2021
-
[11]
Scalable causal discovery with score matching
Francesco Montagna, Nicoletta Noceti, Lorenzo Rosasco, Kun Zhang, and Francesco Locatello. Scalable causal discovery with score matching. InProceedings of the Second Conference on Causal Learning and Reasoning, pages 752–771. PMLR, 2023
work page 2023
-
[12]
On the role of sparsity and dag constraints for learning linear dags
Ignavier Ng, AmirEmad Ghassami, and Kun Zhang. On the role of sparsity and dag constraints for learning linear dags. InAdvances in Neural Information Processing Systems, volume 33, pages 17943–17954, 2020
work page 2020
-
[13]
Cambridge University Press, 2009
Judea Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, 2009. 10
work page 2009
-
[14]
Jonas Peters, Joris M Mooij, Dominik Janzing, and Bernhard Schölkopf. Causal discovery with continuous additive noise models.The Journal of Machine Learning Research, 15(1): 2009–2053, 2014
work page 2009
-
[15]
Score matching enables causal discovery of nonlinear additive noise models
Paul Rolland, V olkan Cevher, Matthäus Kleindessner, Chris Russell, Dominik Janzing, Bernhard Schölkopf, and Francesco Locatello. Score matching enables causal discovery of nonlinear additive noise models. InInternational Conference on Machine Learning, pages 18741–18753. PMLR, 2022
work page 2022
-
[16]
Karen Sachs, Omar Perez, Dana Pe’er, Douglas A Lauffenburger, and Garry P Nolan. Causal protein-signaling networks derived from multiparameter single-cell data.Science, 308(5721): 523–529, 2005
work page 2005
-
[17]
Diffusion models for causal discovery via topological ordering
Pedro Sanchez, Xiao Liu, Alison Q O’Neil, and Sotirios A Tsaftaris. Diffusion models for causal discovery via topological ordering. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[18]
Shohei Shimizu, Patrik O Hoyer, Aapo Hyvärinen, and Antti Kerminen. A linear non-gaussian acyclic model for causal discovery.Journal of Machine Learning Research, 7(10), 2006
work page 2006
-
[19]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[20]
Peter Spirtes, Clark N Glymour, and Richard Scheines.Causation, Prediction, and Search. MIT press, 2000
work page 2000
-
[21]
Dag-gnn: Dag structure learning with graph neural networks
Yue Yu, Jie Chen, Tian Gao, and Mo Yu. Dag-gnn: Dag structure learning with graph neural networks. InInternational Conference on Machine Learning, pages 7155–7163. PMLR, 2019
work page 2019
-
[22]
Model selection and estimation in regression with grouped variables
Ming Yuan and Yi Lin. Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(1):49–67, 2006
work page 2006
-
[23]
On the identifiability of the post-nonlinear causal model
Kun Zhang and Aapo Hyvärinen. On the identifiability of the post-nonlinear causal model. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, pages 647–655, 2009
work page 2009
-
[24]
Dags with no tears: Continuous optimization for structure learning
Xun Zheng, Bryon Aragam, Pradeep K Ravikumar, and Eric P Xing. Dags with no tears: Continuous optimization for structure learning. InAdvances in Neural Information Processing Systems, volume 31, pages 9472–9483, 2018. A Deferred Proofs and Derivations A.1 Proof of Theorem 3.1 Proof. By the Markov property of the ANM, the joint distribution factorizes as p...
-
[25]
SF networks exhibit a power-law degree distribution, testing precision under topological imbalance
Topological Shifts:We contrast Erd ˝os-Rényi (ER) graphs with Scale-Free (SF) networks. SF networks exhibit a power-law degree distribution, testing precision under topological imbalance
-
[26]
These asymmetric distributions violate zero-mean Gaussian assumptions
Distributional Shifts:We replace Gaussian noise with Exponential and Gumbel distributions. These asymmetric distributions violate zero-mean Gaussian assumptions. Table 10:Robustness Benchmark across Topology and Noise Distributions ( d= 50, N= 5000 ). Evaluated over 5 random seeds (Mean±Std). Graph Topology Noise Distribution Edge Violations↓SHD↓TPR↑ Erd˝...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.