Recognition: unknown
RCProb: Probabilistic Rule Extraction for Efficient Simplification of Tree Ensembles
Pith reviewed 2026-05-07 16:32 UTC · model grok-4.3
The pith
RCProb achieves similar rule quality to RuleCOSI+ but with 22 times less computation by using probabilistic approximations instead of data scans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that rule statistics can be estimated probabilistically without empirical counting. RCProb employs Dirichlet-smoothed class priors and Beta-smoothed condition likelihoods in a Naive Bayes formulation to approximate the confidence measures used in rule selection, thereby eliminating the need for repeated dataset scans while preserving the quality of the extracted rules.
What carries the argument
The probabilistic estimation mechanism using Dirichlet and Beta smoothed priors and likelihoods within a Naive Bayes model to compute rule confidence scores.
If this is right
- Rule extraction becomes feasible for much larger datasets and ensembles due to reduced computational demands.
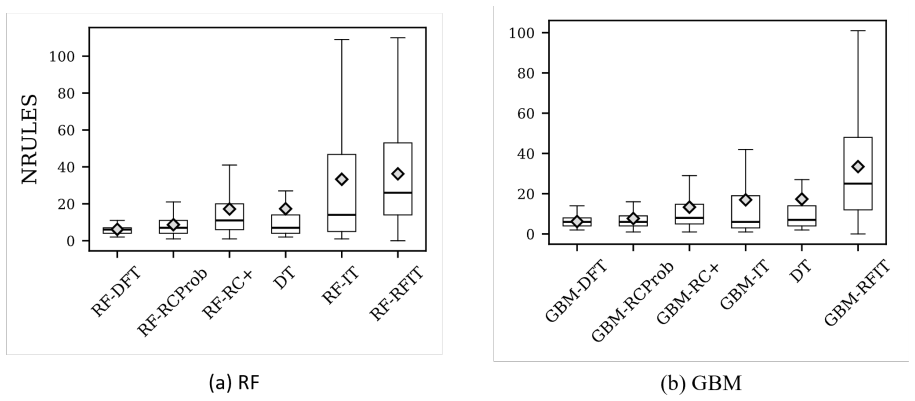
- The extracted rule sets tend to be more compact, enhancing human interpretability.
- Predictive performance stays competitive with both the original tree ensemble and the prior RuleCOSI+ method.
- Overall runtime decreases by a factor of about 22 times on benchmark datasets.
Where Pith is reading between the lines
- The method may extend to other greedy rule extraction algorithms that depend on frequency-based metrics.
- Further work could explore adaptive smoothing parameters based on dataset characteristics.
- Such probabilistic shortcuts might apply to other interpretability techniques in machine learning that involve counting.
Load-bearing premise
The smoothed probability estimates approximate the true empirical rule frequencies closely enough that the selected rules and their performance remain nearly identical to those from direct counting.
What would settle it
Observing a significant drop in accuracy or a different set of selected rules when comparing RCProb to RuleCOSI+ on a dataset where the smoothing introduces bias, such as one with highly skewed class distributions.
Figures


read the original abstract
Tree ensembles are widely used in industrial machine learning due to their strong predictive performance and efficient training procedures. However, as the number of trees in an ensemble grows, the resulting models become increasingly difficult for humans to interpret. To address this limitation, explainable artificial intelligence (XAI) studies methods that generate interpretable models capable of explaining complex predictors. One approach consists of extracting decision rules from tree ensembles while attempting to preserve the predictive performance of the original model. In previous work, we introduced RuleCOSI+, a greedy heuristic algorithm for extracting compact rule-based models from tree ensembles. Although RuleCOSI+ produces accurate and interpretable rule sets, it relies on repeated empirical frequency counting over the training data to estimate rule confidence, which becomes computationally expensive for large datasets. In this paper, we propose RCProb, a probabilistic reformulation of RuleCOSI+ designed to reduce the computational cost of rule extraction. RCProb estimates rule statistics using Dirichlet-smoothed class priors and Beta-smoothed condition likelihoods combined through a Naive Bayes formulation, avoiding repeated dataset scans. Experiments on 33 benchmark datasets show that RCProb maintains competitive predictive performance while reducing runtime by approximately $22\times$ compared with RuleCOSI+, while producing more compact rule sets on average.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RCProb, a probabilistic reformulation of the prior RuleCOSI+ greedy heuristic for extracting compact rule sets from tree ensembles. RCProb replaces repeated empirical frequency counts with closed-form estimates using Dirichlet-smoothed class priors, Beta-smoothed condition likelihoods, and a Naive Bayes combination, thereby avoiding full dataset scans. Experiments on 33 benchmark datasets are reported to show that RCProb achieves competitive predictive performance, an average 22× runtime reduction, and more compact rule sets compared with RuleCOSI+.
Significance. If the probabilistic estimates prove faithful to the empirical counts used by the original greedy selection, the work would offer a practical scalability improvement for rule extraction from large ensembles, which is relevant for industrial XAI applications. The approach is a direct and efficient reformulation that could generalize to other count-based rule simplification methods.
major comments (2)
- [§5] §5 (experimental evaluation): The manuscript reports average performance and runtime across 33 datasets but provides neither error bars, statistical significance tests, nor per-dataset breakdowns. More critically, it does not quantify the divergence between the probabilistic rule-confidence estimates and the empirical frequencies that drive RuleCOSI+ rule selection; without such a metric it remains unclear whether the 22× speedup preserves the same rule sets or merely yields comparable average accuracy by chance.
- [§3.2] §3.2 (probabilistic estimation): The Naive Bayes independence assumption underlying the combination of Beta-smoothed likelihoods is not validated against regimes of feature dependence or class imbalance, precisely where systematic bias relative to empirical counts would most affect the greedy pruning decisions. No sensitivity analysis on the Dirichlet/Beta smoothing hyperparameters is presented either.
minor comments (2)
- The abstract and introduction could more explicitly state that all runtime and compactness comparisons are against the authors' own prior RuleCOSI+ implementation rather than other rule-extraction baselines.
- Notation for the smoothed probabilities (e.g., distinction between prior, likelihood, and posterior) should be introduced once and used consistently to avoid reader confusion when comparing to the empirical counts of RuleCOSI+.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the strengths and limitations of our probabilistic reformulation. We respond to each major point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (experimental evaluation): The manuscript reports average performance and runtime across 33 datasets but provides neither error bars, statistical significance tests, nor per-dataset breakdowns. More critically, it does not quantify the divergence between the probabilistic rule-confidence estimates and the empirical frequencies that drive RuleCOSI+ rule selection; without such a metric it remains unclear whether the 22× speedup preserves the same rule sets or merely yields comparable average accuracy by chance.
Authors: We agree that the experimental reporting can be strengthened with error bars, statistical tests, and per-dataset details. In the revised manuscript we will add standard deviation error bars on all aggregate metrics, conduct paired statistical significance tests (Wilcoxon signed-rank) between RCProb and RuleCOSI+, and provide a supplementary table with per-dataset accuracy, runtime, and rule-set size. To directly quantify divergence, we will add an analysis computing (i) the mean absolute difference between the probabilistic rule-confidence scores and the empirical frequencies used by RuleCOSI+ for the same candidate rules, and (ii) the Jaccard overlap between the final rule sets selected by each method across all 33 datasets. These additions will clarify whether the 22× speedup preserves similar selections or achieves comparable accuracy through different rules. revision: yes
-
Referee: [§3.2] §3.2 (probabilistic estimation): The Naive Bayes independence assumption underlying the combination of Beta-smoothed likelihoods is not validated against regimes of feature dependence or class imbalance, precisely where systematic bias relative to empirical counts would most affect the greedy pruning decisions. No sensitivity analysis on the Dirichlet/Beta smoothing hyperparameters is presented either.
Authors: The Naive Bayes assumption is an explicit modeling choice that trades exactness for speed; we acknowledge it can introduce bias under strong feature dependence or severe class imbalance. Nevertheless, the competitive accuracy and more compact rule sets observed across 33 datasets with diverse dependence structures and imbalance ratios provide empirical evidence that any such bias does not materially degrade the greedy selection outcome in practice. We will add a sensitivity study in the revision by varying the Dirichlet and Beta smoothing parameters over a grid (e.g., α ∈ {0.01, 0.1, 1, 10}) and reporting the resulting changes in runtime, accuracy, and rule-set size. A exhaustive validation across all possible dependence regimes would require a separate, large-scale study and is therefore left for future work. revision: partial
- Exhaustive validation of the Naive Bayes independence assumption across all possible feature-dependence and class-imbalance regimes (beyond the sensitivity analysis we can add)
Circularity Check
Minor self-citation to prior RuleCOSI+ without load-bearing circularity in the probabilistic reformulation
full rationale
The paper's core contribution is RCProb, a new probabilistic estimation procedure (Dirichlet-smoothed priors, Beta-smoothed likelihoods, Naive Bayes combination) that approximates but does not reproduce the empirical frequency counts of the earlier RuleCOSI+ algorithm. This estimation is derived from standard smoothing techniques and is not tautological with the inputs; the greedy selection decisions remain external to the approximation. The sole self-reference is to the prior RuleCOSI+ work whose counts are being approximated rather than redefined. Experiments on 33 independent benchmark datasets supply external validation of runtime and compactness gains. No step in the derivation chain reduces by construction to a fitted parameter, self-citation chain, or renamed known result. This is the normal case of a self-contained incremental method with only incidental self-citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Naive Bayes conditional independence assumption when combining class priors and condition likelihoods
Reference graph
Works this paper leans on
-
[1]
A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects.IEEE Access, 10:99129–99149, 2022
Ibomoiye Domor Mienye and Yanxia Sun. A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects.IEEE Access, 10:99129–99149, 2022. ISSN 2169-
2022
-
[2]
doi: 10.1109/ACCESS.2022.3207287
-
[3]
Information fusion58, 82–115 (2020), https://doi.org/10.1016/j.inffus.2019.12.012
Alejandro Barredo Arrieta, Natalia D´ ıaz-Rodr´ ıguez, Javier Del Ser, Adrien Bennetot, Si- ham Tabik, Alberto Barbado, Salvador Garcia, Sergio Gil-Lopez, Daniel Molina, Richard Benjamins, Raja Chatila, and Francisco Herrera. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI.Information Fus...
-
[4]
Explanation of ensemble models
Josue Obregon and Jae Yoon Jung. Explanation of ensemble models. InHuman-Centered Artificial Intelligence: Research and Applications, pages 51–72. Academic Press, January
-
[5]
doi: 10.1016/B978-0-323-85648-5.00011-6
ISBN 978-0-323-85648-5. doi: 10.1016/B978-0-323-85648-5.00011-6
-
[6]
Jerome H. Friedman and Bogdan E. Popescu. Predictive learning via rule ensembles.Annals of Applied Statistics, 2(3):916–954, 2008. ISSN 19326157. doi: 10.1214/07-AOAS148
-
[7]
Houtao Deng. Interpreting tree ensembles with inTrees.International Journal of Data Sci- ence and Analytics, 7(4):277–287, 2019. ISSN 2364-415X. doi: 10.1007/s41060-018-0144-8. 18
-
[8]
Making Tree Ensembles Interpretable: A Bayesian Model Selection Approach
Satoshi Hara and Kohei Hayashi. Making Tree Ensembles Interpretable: A Bayesian Model Selection Approach. In Amos Storkey and Fernando Perez-Cruz, editors,Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84, pages 77–85. PMLR, July 2018
2018
-
[9]
Explainable decision forest: Transforming a decision forest into an interpretable tree.Information Fusion, 61:124–138, September 2020
Omer Sagi and Lior Rokach. Explainable decision forest: Transforming a decision forest into an interpretable tree.Information Fusion, 61:124–138, September 2020. ISSN 1566-
2020
-
[10]
doi: 10.1016/J.INFFUS.2020.03.013
-
[11]
Atomic cross-chain settlement model for central banks digital currency
Omer Sagi and Lior Rokach. Approximating XGBoost with an interpretable decision tree. Information Sciences, 572:522–542, September 2021. ISSN 0020-0255. doi: 10.1016/J.INS. 2021.05.055
-
[12]
Lu-an Dong, Xin Ye, and Guangfei Yang. Two-stage rule extraction method based on tree ensemble model for interpretable loan evaluation.Information Sciences, 573:46–64, September 2021. ISSN 0020-0255. doi: 10.1016/j.ins.2021.05.063
-
[13]
Forest-ORE: Mining Optimal Rule Ensemble to interpret Random Forest models, March 2024
Haddouchi Maissae and Berrado Abdelaziz. Forest-ORE: Mining Optimal Rule Ensemble to interpret Random Forest models, March 2024
2024
-
[14]
Akihiro Takemura and Katsumi Inoue. Generating Explainable Rule Sets from Tree- Ensemble Learning Methods by Answer Set Programming.Electron. Proc. Theor. Comput. Sci., 345:127–140, September 2021. ISSN 2075-2180. doi: 10.4204/EPTCS.345.26
-
[15]
Josue Obregon, Aekyung Kim, and Jae-Yoon Jung. RuleCOSI: Combination and simplifi- cation of production rules from boosted decision trees for imbalanced classification.Expert Systems with Applications, 126, 2019. ISSN 09574174. doi: 10.1016/j.eswa.2019.02.012
-
[16]
Josue Obregon and Jae Yoon Jung. RuleCOSI+: Rule extraction for interpreting classi- fication tree ensembles.Information Fusion, 89:355–381, January 2023. ISSN 1566-2535. doi: 10.1016/J.INFFUS.2022.08.021
-
[17]
Bastian Pfeifer, Arne Gevaert, Markus Loecher, and Andreas Holzinger. Tree smoothing: Post-hoc regularization of tree ensembles for interpretable machine learning.Information Sciences, 690:121564, February 2025. ISSN 0020-0255. doi: 10.1016/j.ins.2024.121564
-
[18]
Understanding variable importances in forests of randomized trees
Gilles Louppe, Louis Wehenkel, Antonio Sutera, and Pierre Geurts. Understanding variable importances in forests of randomized trees. InAdvances in Neural Information Processing Systems, volume 26, pages 431–439, 2013
2013
-
[19]
Andrea Cristina McGlinchey and Peter J
Scott M. Lundberg, Gabriel Erion, Hugh Chen, Alex DeGrave, Jordan M. Prutkin, Bala Nair, Ronit Katz, Jonathan Himmelfarb, Nisha Bansal, and Su-In Lee. From local expla- nations to global understanding with explainable AI for trees.Nature Machine Intelligence 2020 2:1, 2(1):56–67, January 2020. ISSN 2522-5839. doi: 10.1038/s42256-019-0138-9
-
[20]
Born-Again Tree Ensembles
Thibaut Vidal and Maximilian Schiffer. Born-Again Tree Ensembles. InInternational Conference on Machine Learning, pages 9743–9753. PMLR, November 2020
2020
-
[21]
Extracting Interpretable Decision Tree Ensemble from Random Forest
Bogdan Gulowaty and Micha l Wo´ zniak. Extracting Interpretable Decision Tree Ensemble from Random Forest. In2021 International Joint Conference on Neural Networks (IJCNN), pages 1–8, July 2021. doi: 10.1109/IJCNN52387.2021.9533601
-
[22]
Rule Extraction from Decision Trees Ensembles: New Algorithms Based on Heuristic Search and Sparse Group Lasso Methods.Int
Morteza Mashayekhi and Robin Gras. Rule Extraction from Decision Trees Ensembles: New Algorithms Based on Heuristic Search and Sparse Group Lasso Methods.Int. J. Info. Tech. Dec. Mak., 16(06):1707–1727, November 2017. ISSN 0219-6220. doi: 10.1142/ S0219622017500055. 19
2017
-
[23]
Zhen Li, Weikai Yang, Jun Yuan, Jing Wu, Changjian Chen, Yao Ming, Fan Yang, Hui Zhang, and Shixia Liu. RuleExplorer: A Scalable Matrix Visualization for Understanding Tree Ensemble Classifiers.IEEE Transactions on Visualization and Computer Graphics, 31(9):6370–6384, September 2025. ISSN 1941-0506. doi: 10.1109/TVCG.2024.3514115
-
[24]
A Bayesian Framework for Learning Rule Sets for Interpretable Classification
Tong Wang, Cynthia Rudin, Finale Doshi-Velez, Yimin Liu, Erica Klampfl, and Perry MacNeille. A Bayesian Framework for Learning Rule Sets for Interpretable Classification. Journal of Machine Learning Research, 18(70):1–37, 2017. ISSN 1533-7928
2017
-
[25]
Leo Breiman. Random forests.Machine Learning, 45(1):5–32, October 2001. ISSN 08856125. doi: 10.1023/A:1010933404324
-
[26]
Jerome H. Friedman. Greedy function approximation: A gradient boosting machine.An- nals of Statistics, 29(5):1189–1232, 2001. ISSN 00905364. doi: 10.2307/2699986
-
[27]
Statistical Comparisons of Classifiers over Multiple Data Sets.Journal of Machine Learning Research, 7:1–30, 2006
Janez Demˇ sar. Statistical Comparisons of Classifiers over Multiple Data Sets.Journal of Machine Learning Research, 7:1–30, 2006
2006
-
[28]
Should We Really Use Post-Hoc Tests Based on Mean-Ranks?Journal of Machine Learning Research, 17:1–10, 2016
Alessio Benavoli, Giorgio Corani, and Francesca Mangili. Should We Really Use Post-Hoc Tests Based on Mean-Ranks?Journal of Machine Learning Research, 17:1–10, 2016. 20
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.