Recognition: unknown
Accelerating finite-element-based projector augmented-wave density functional theory calculations with scalable GPU-centric computational methods
Pith reviewed 2026-05-07 13:52 UTC · model grok-4.3
The pith
A finite-element projector augmented-wave DFT method with GPU-centric optimizations delivers up to 20x speedups and scales to 130,000-electron systems while preserving chemical accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
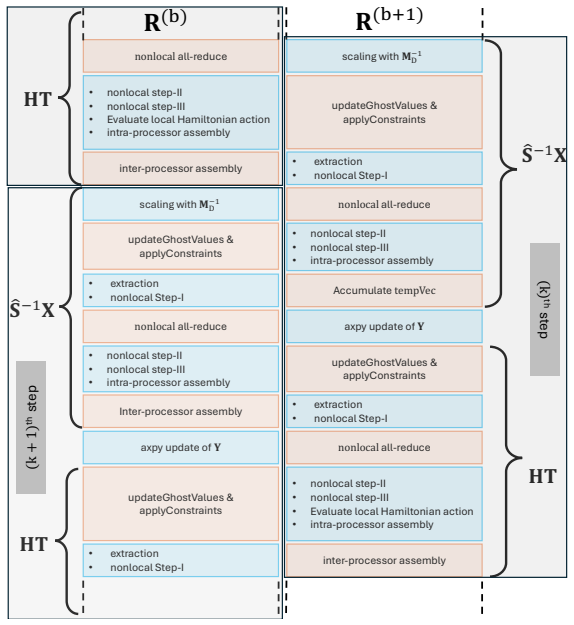
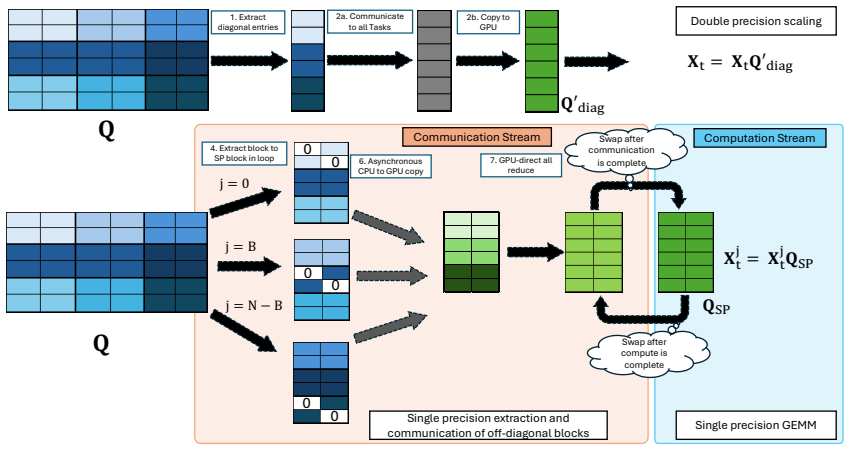
Within a collinear-spin finite-element framework, the generalized Hermitian eigenproblem arising from the PAW formulation is solved by residual-based Chebyshev filtered subspace iteration. The solver's tolerance for inexact matrix-multivector products permits an approximate inverse PAW overlap matrix, FP32/TF32 mixed-precision arithmetic, and BF16 nearest-neighbor communication during filtered subspace construction, together with block-wise computation-communication overlap. On NVIDIA GPUs the resulting PAW-FE implementation reduces time-to-solution by nearly 8x relative to plane-wave PAW methods for 10,000-electron systems and by roughly 6x relative to norm-conserving finite-element methods
What carries the argument
Residual-based Chebyshev filtered subspace iteration (R-ChFSI) that exploits tolerance to inexact matrix operations, combined with an approximate inverse PAW overlap matrix and mixed-precision arithmetic.
If this is right
- PAW-FE achieves close to 8x reduction in time-to-solution versus plane-wave PAW methods for 10,000-electron systems on NVIDIA GPUs, with larger gains at scale.
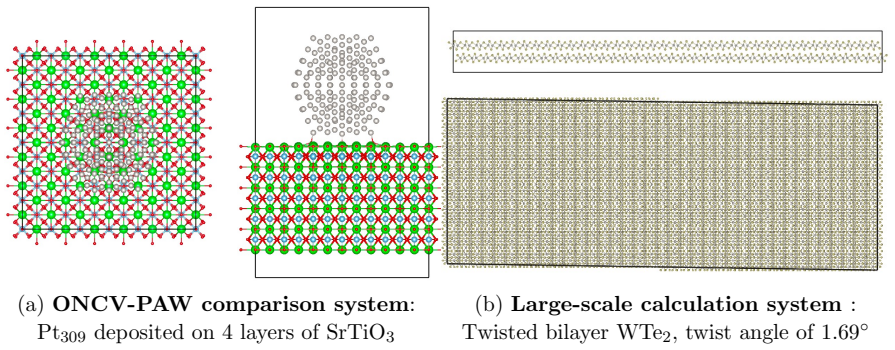
- The method scales to 130,000-electron systems on current GPU architectures.
- CPU-to-GPU speedups reach 8x on Intel GPUs and 20x on AMD GPUs.
- PAW-FE runs approximately 6x faster than norm-conserving finite-element approaches for the same systems.
Where Pith is reading between the lines
- The demonstrated tolerance to reduced-precision operations could be applied to other large-scale eigenvalue problems in materials modeling.
- Routine access to 100,000-electron DFT calculations would open systematic studies of defect formation energies across entire device-scale interfaces.
- Further development of the multi-resolution quadrature for PAW integrals might extend the same framework to time-dependent or non-collinear-spin DFT.
Load-bearing premise
The mixed-precision arithmetic, approximate inverse PAW overlap matrix, and low-precision communication preserve chemical accuracy and robustness of the Kohn-Sham solutions without introducing unacceptable errors in energies or forces.
What would settle it
A side-by-side comparison of total energies and atomic forces obtained from the mixed-precision PAW-FE scheme versus a reference double-precision run on the same 10,000-electron benchmark system would show whether deviations remain below typical chemical-accuracy thresholds.
Figures






read the original abstract
Accurate large-scale Kohn-Sham density functional theory (DFT) calculations are essential for modeling complex material systems, including interfaces, defects, nanoclusters, and twisted two-dimensional heterostructures. Achieving chemical accuracy at scales of $10^4$-$10^5$ electrons with practical time-to-solution, however, remains challenging for existing DFT implementations. We present GPU-centric computational methods and algorithmic innovations within a finite-element (FE) discretized projector augmented-wave (PAW) formulation (PAW-FE) for accurate, efficient, and scalable electronic-structure calculations on modern exascale systems. The FE discretization, developed within a collinear spin formalism, accommodates generic boundary conditions and employs multi-resolution quadrature for accurate evaluation of atom-centered PAW integrals on coarse grids. The resulting generalized Hermitian eigenproblem is solved using residual-based Chebyshev filtered subspace iteration (R-ChFSI). Exploiting R-ChFSI's tolerance to inexact matrix-multivector products, we employ an approximate inverse PAW overlap matrix, mixed-precision arithmetic (FP32/TF32), and low-precision nearest-neighbor communication (BF16) during filtered subspace construction, along with block-wise computation-communication overlap to reduce cost while preserving robustness. These strategies yield up to $8\times$ and $20\times$ CPU-GPU speedups on Intel and AMD GPU architectures, respectively. Compared to plane-wave PAW methods, PAW-FE achieves close to 8$\times$ reduction in time-to-solution for 10,000-electron systems on NVIDIA GPUs, with larger gains at scale, and around 6$\times$ over norm-conserving FE approaches. We demonstrate scalability to 130,000-electron systems, establishing PAW-FE as an exascale-ready method for chemically accurate first-principles simulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GPU-centric algorithmic and implementation advances for finite-element discretized projector-augmented-wave (PAW-FE) Kohn-Sham DFT. It solves the generalized eigenproblem via residual-based Chebyshev filtered subspace iteration (R-ChFSI) while exploiting the method's tolerance to inexact matrix-multivector products through mixed-precision (FP32/TF32) arithmetic, an approximate inverse of the PAW overlap matrix, BF16 nearest-neighbor communication, and computation-communication overlap. The work reports up to 8× and 20× CPU-GPU speedups on Intel and AMD GPUs, an 8× reduction in time-to-solution versus plane-wave PAW for 10k-electron systems (with larger gains at scale), a 6× improvement over norm-conserving FE, and weak scaling to 130k-electron systems, all while asserting that chemical accuracy and robustness are preserved.
Significance. If the accuracy claims are substantiated, the paper would be significant for enabling chemically accurate first-principles simulations of large-scale systems (interfaces, defects, twisted heterostructures) on exascale hardware. The combination of FE discretization with R-ChFSI's tolerance to inexact operations and GPU-specific optimizations addresses a recognized bottleneck in scaling DFT beyond current practical limits.
major comments (1)
- [Abstract] Abstract: the central performance claims (8–20× speedups, 8× vs. plane-wave PAW, 6× vs. norm-conserving FE, scaling to 130k electrons) are conditional on the statement that mixed-precision arithmetic, the approximate PAW overlap inverse, and BF16 communication 'preserve robustness' and produce 'chemically accurate' results. No quantitative error tables, energy/force deviation plots, or comparisons against double-precision or reference codes are supplied to show that errors remain below ~1 meV/atom or ~0.01 eV/Å thresholds. This verification is load-bearing for every reported speedup and scalability result.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The concern regarding substantiation of the accuracy claims under the mixed-precision and approximate-operator strategies is well-taken and central to the paper's conclusions. We address it directly below and commit to revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (8–20× speedups, 8× vs. plane-wave PAW, 6× vs. norm-conserving FE, scaling to 130k electrons) are conditional on the statement that mixed-precision arithmetic, the approximate PAW overlap inverse, and BF16 communication 'preserve robustness' and produce 'chemically accurate' results. No quantitative error tables, energy/force deviation plots, or comparisons against double-precision or reference codes are supplied to show that errors remain below ~1 meV/atom or ~0.01 eV/Å thresholds. This verification is load-bearing for every reported speedup and scalability result.
Authors: We agree that explicit, quantitative validation of accuracy and robustness is essential and load-bearing for the reported performance gains. The manuscript asserts that the chosen approximations preserve chemical accuracy and includes some supporting tests for smaller systems, but it does not contain the comprehensive error tables, energy/force deviation plots, or direct comparisons to double-precision runs and reference plane-wave codes (e.g., VASP or Quantum ESPRESSO) that would rigorously demonstrate errors remain below the ~1 meV/atom and ~0.01 eV/Å thresholds across the full range of system sizes. In the revised manuscript we will add a dedicated subsection (and associated appendix) presenting these quantitative results, including tables of total-energy and force deviations for representative systems at both small and large scales, comparisons against double-precision PAW-FE runs, and cross-checks against established codes where feasible. This addition will directly substantiate the central claims. revision: yes
Circularity Check
No circularity in derivation chain; results rest on benchmarks
full rationale
The manuscript describes algorithmic innovations in a finite-element PAW DFT framework, including R-ChFSI with mixed-precision arithmetic, approximate overlap inverse, and low-precision communication. Performance claims (speedups, scalability to 130k electrons) are presented as outcomes of implementation and empirical testing on specific architectures and system sizes. No equations, fitted parameters, or derivations are shown that reduce by construction to the inputs or prior self-citations. The tolerance of R-ChFSI to inexact products is invoked as a property of the solver rather than a self-referential definition. The paper is self-contained against external benchmarks, with no load-bearing steps that qualify as self-definitional, fitted-input predictions, or uniqueness imported via self-citation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Finite-element discretization with multi-resolution quadrature accurately evaluates atom-centered PAW integrals on coarse grids
- domain assumption Residual-based Chebyshev filtered subspace iteration remains robust under inexact matrix-multivector products
Reference graph
Works this paper leans on
-
[1]
(1) Kohn, W.; Sham, L. J. Self-Consistent Equations Including Exchange and Correlation Effects.Phys. Rev.1965,140, A1133–A1138. (2) Kohn, W. Nobel Lecture: Electronic structure of matter—wave functions and density functionals.Rev. Mod. Phys.1999,71, 1253–1266. (3) Martin, R. M.Electronic structure: basic theory and practical methods; Cambridge university press,
1965
-
[2]
Efficient iterative schemes for ab initio total-energy calcu- lations using a plane-wave basis set.Phys
(4) Kresse, G.; Furthm¨ uller, J. Efficient iterative schemes for ab initio total-energy calcu- lations using a plane-wave basis set.Phys. Rev. B1996,54, 11169–11186. (5) Giannozzi, P.; Baroni, S.; Bonini, N.; Calandra, M.; Car, R.; Cavazzoni, C.; Ceresoli, D.; Chiarotti, G. L.; Cococcioni, M.; Dabo, I.; Corso, A. D.; de Gironcoli, S.; Fabris, S.; Fratesi...
2022
-
[3]
(9) Fan, Z.; Wang, Y.; Song, X.; Ma, Y. Neuroevolution Potential: A Machine Learning Potential with High Accuracy and Low Cost.Journal of Chemical Physics2021,154, 234106. (10) Bl¨ ochl, P. E. Projector augmented-wave method.Phys. Rev. B1994,50, 17953–17979. 47 (11) Kresse, G.; Joubert, D. From ultrasoft pseudopotentials to the projector augmented- wave m...
-
[4]
(30) Tackett, A.; Holzwarth, N.; Matthews, G. A Projector Augmented Wave (PAW) code for electronic structure calculations, PartII: pwpaw for periodic solids in a plane wave basis.Computer Physics Communications2001,135, 348–376. (31) Dal Corso, A. Pseudopotentials periodic table: From H to Pu.Computational Materials Science2014,95, 337–350. (32) Lebedev, ...
1965
-
[5]
C.; Knepley, M.; Logg, A.; Scott, L
(43) Kirby, R. C.; Knepley, M.; Logg, A.; Scott, L. R. Optimizing the Evaluation of Finite Element Matrices.SIAM Journal on Scientific Computing2005,27, 741–758. (44) Kronbichler, M.; Kormann, K. A generic interface for parallel cell-based finite element operator application.Computers & Fluids2012,63, 135–147. (45) Panigrahi, G.; Kodali, N.; Panda, D.; Mo...
2013
-
[6]
W.; Kaplan, A
(61) Furness, J. W.; Kaplan, A. D.; Ning, J.; Perdew, J. P.; Sun, J. Accurate and Numerically Efficient r2SCAN Meta-Generalized Gradient Approximation.The Journal of Physical Chemistry Letters2020,11, 8208–8215, PMID: 32876454. (62) Lebeda, T.; Aschebrock, T.; K¨ ummel, S. Balancing the Contributions to the Gradient Expansion: Accurate Binding and Band Ga...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.