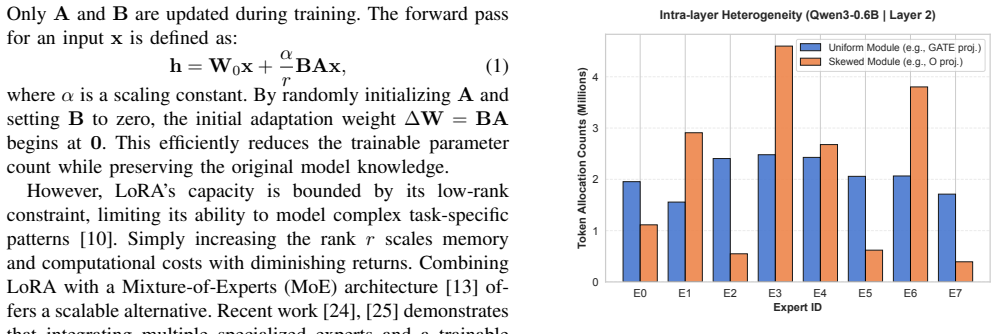
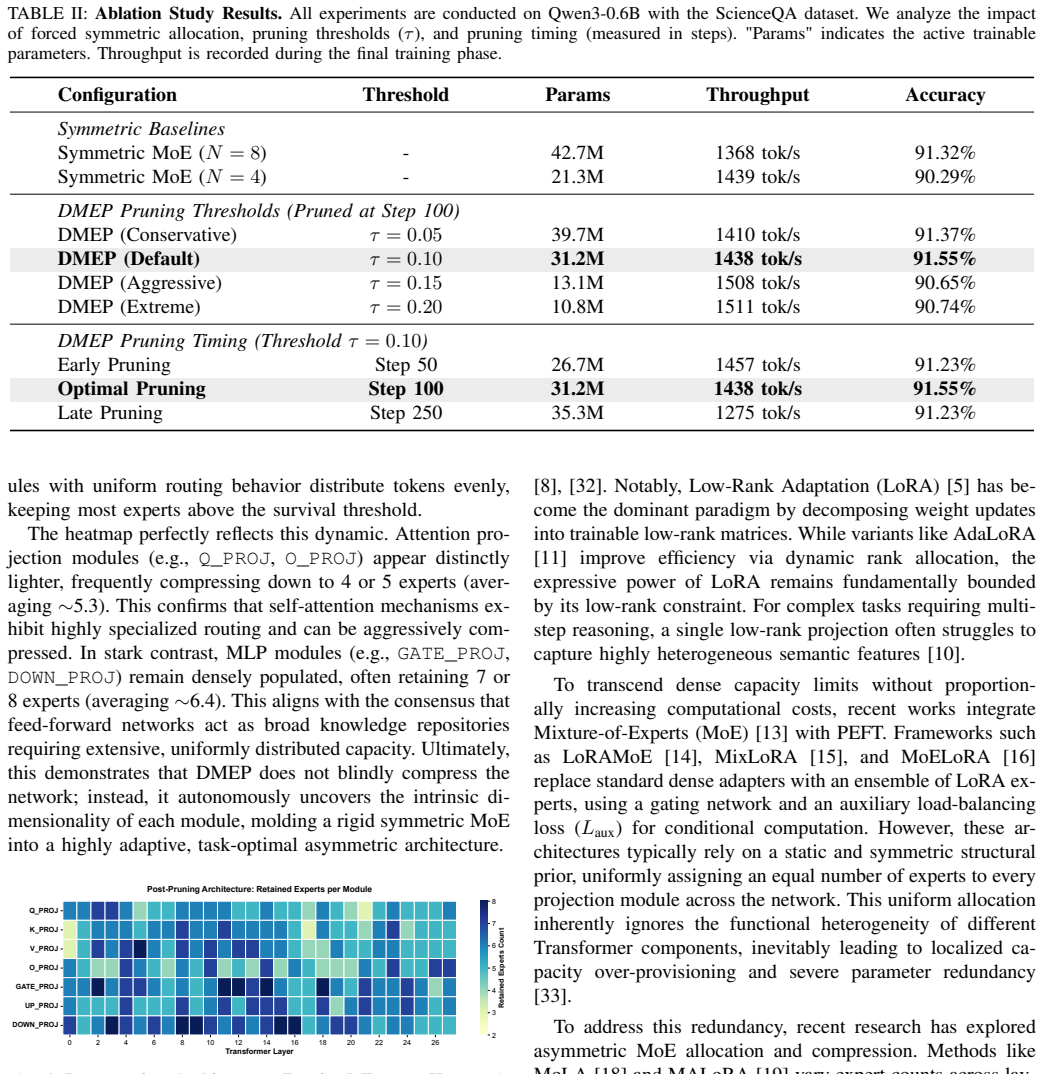
Recognition: unknown
Adaptive and Fine-grained Module-wise Expert Pruning for Efficient LoRA-MoE Fine-Tuning
Pith reviewed 2026-05-07 13:14 UTC · model grok-4.3
The pith
DMEP prunes low-utility experts on a per-module basis in LoRA-MoE and drops load balancing to cut trainable parameters by 35-43% while preserving reasoning accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DMEP tracks expert utilization during training and physically removes low-utility experts on a per-module basis, yielding a more compact expert structure tailored to different modules. The pruned model then continues training without the load-balancing constraint, freeing the remaining experts to focus entirely on the downstream task and develop specialized expertise.
What carries the argument
Dynamic Module-wise Expert Pruning, which records per-expert activation statistics separately for each module type, removes underused experts, and then relaxes load balancing to allow specialization.
If this is right
- Trainable parameters fall by 35% to 43% relative to uniform LoRA-MoE baselines.
- Training throughput rises by roughly 10% due to reduced optimizer state and computation.
- Downstream reasoning accuracy is maintained or improved on multiple benchmarks.
- Expert allocation becomes adapted to the distinct capacity needs of attention and MLP modules.
- Redundant expert parameters and their associated optimizer overhead are eliminated.
Where Pith is reading between the lines
- The same utilization-based pruning logic could reduce memory footprint when deploying pruned LoRA-MoE models at inference time.
- Limiting load balancing to early training stages may improve specialization in other MoE fine-tuning or pretraining setups.
- Module-wise capacity adaptation suggests that uniform expert counts are suboptimal across a wide range of Transformer-based tasks.
- The method points to potential gains if similar dynamic pruning is applied to full-parameter MoE training rather than LoRA only.
Load-bearing premise
Expert utilization statistics collected early in training reliably flag experts that can be removed per module without harming final performance, and experts will develop useful specialization once the load-balancing constraint is lifted.
What would settle it
Running the full DMEP pipeline on a standard reasoning benchmark and finding that final accuracy falls below the uniform LoRA-MoE baseline after the same total training steps.
Figures



read the original abstract
LoRA-MoE has emerged as an effective paradigm for parameter-efficient fine-tuning, combining the low training cost of LoRA with the increased adaptation capacity of Mixture-of-Experts (MoE). However, existing LoRA-MoE frameworks typically adopt a fixed and uniform expert configuration across heterogeneous Transformer modules (\eg, attention query/key projections and MLP gating networks), ignoring their distinct functional roles and capacity requirements. This design leads to localized over-provisioning, redundant trainable parameters, and unnecessary optimizer-state overhead. Moreover, prior methods enforce load balancing among experts throughout training. Although beneficial in the early stage, this constraint becomes restrictive once routing patterns stabilize, limiting expert specialization on downstream tasks. In this paper, we propose DMEP, a novel LoRA-MoE fine-tuning framework based on Dynamic Module-wise Expert Pruning. DMEP tracks expert utilization during training and physically removes low-utility experts on a per-module basis, yielding a more compact expert structure tailored to different modules. The pruned model then continues training without the load-balancing constraint, freeing the remaining experts to focus entirely on the downstream task and develop specialized expertise. By jointly adapting module-wise expert capacity and eliminating unnecessary balancing, DMEP improves both parameter efficiency and training efficiency. Extensive experiments on multiple reasoning benchmarks show that DMEP reduces trainable parameters by 35\%--43\% and improves training throughput by about 10\%, while maintaining or surpassing the downstream reasoning accuracy of uniform LoRA-MoE baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DMEP, a LoRA-MoE fine-tuning framework that tracks expert utilization during training, physically prunes low-utility experts on a per-module basis to create a compact structure tailored to heterogeneous Transformer modules, and then continues training without the load-balancing constraint to allow greater specialization. It reports 35-43% reduction in trainable parameters, ~10% improvement in training throughput, and maintained or improved accuracy on reasoning benchmarks relative to uniform LoRA-MoE baselines.
Significance. If the empirical results hold under scrutiny, DMEP could meaningfully advance parameter-efficient fine-tuning for MoE architectures by addressing module heterogeneity and the limitations of persistent load balancing, potentially enabling more efficient adaptation of large models. The approach is practically relevant for reducing optimizer overhead and improving throughput, though no machine-checked proofs, open code, or parameter-free derivations are noted.
major comments (2)
- [Method (pruning procedure) and Experiments] The central efficiency-accuracy claim depends on the premise that mid-training utilization statistics identify experts whose removal (per-module) does not cause irrecoverable capacity loss even after the load-balancing constraint is lifted. No ablations testing pruning timing, threshold sensitivity, or isolated effect of constraint removal are referenced, leaving the key assumption unverified.
- [Abstract and Experiments section] Reported gains (35-43% parameter reduction, ~10% throughput) lack error bars, exact pruning criterion (e.g., utilization threshold formula or timing), and full benchmark list with per-task breakdowns, which are load-bearing for assessing whether gains are robust or result from post-hoc selection.
minor comments (2)
- [Abstract] The abstract refers to 'multiple reasoning benchmarks' without naming them, which reduces immediate reproducibility.
- [Method] Notation for utilization tracking and module-wise pruning could be formalized with an equation or algorithm box for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional verification, details, and transparency where the current version is lacking.
read point-by-point responses
-
Referee: The central efficiency-accuracy claim depends on the premise that mid-training utilization statistics identify experts whose removal (per-module) does not cause irrecoverable capacity loss even after the load-balancing constraint is lifted. No ablations testing pruning timing, threshold sensitivity, or isolated effect of constraint removal are referenced, leaving the key assumption unverified.
Authors: We agree that dedicated ablations are needed to fully substantiate the premise. The current results show maintained or improved accuracy after module-wise pruning and constraint removal, but we did not report sensitivity tests. In the revision we will add experiments varying pruning timing (e.g., 30/50/70 % of training), threshold values, and an isolated ablation of load-balancing removal post-pruning. These will demonstrate that mid-training utilization statistics reliably identify removable experts without irrecoverable capacity loss. revision: yes
-
Referee: Reported gains (35-43% parameter reduction, ~10% throughput) lack error bars, exact pruning criterion (e.g., utilization threshold formula or timing), and full benchmark list with per-task breakdowns, which are load-bearing for assessing whether gains are robust or result from post-hoc selection.
Authors: We concur that these elements are required for rigorous evaluation. The revised manuscript will report standard deviations over multiple random seeds, provide the exact utilization threshold formula and pruning timing used, and expand the experiments section with the complete benchmark list plus per-task breakdowns. This will allow direct assessment of robustness across tasks. revision: yes
Circularity Check
No circularity: efficiency gains are empirical outcomes of an independent pruning procedure measured against external benchmarks.
full rationale
The paper describes DMEP as a concrete algorithm: track per-module expert utilization during training, physically delete low-utility experts, then continue fine-tuning without the load-balancing loss. The headline results (35-43% fewer trainable parameters, ~10% higher throughput, accuracy at or above uniform LoRA-MoE baselines) are obtained by running this procedure on standard reasoning benchmarks and reporting the measured deltas. No equation, definition, or self-citation reduces these deltas to quantities that are true by construction of the pruning rule itself; the downstream accuracy metric remains an independent external check. The derivation chain is therefore self-contained experimental validation rather than any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Identifying who you are no matter what you write through abstracting handwriting style,
J. Huang, Y . Feng, F.-Q. Cui, X. Zhang, Z. Liu, X. Liu, J. Liu, F. Zhang, and M. Li, “Identifying who you are no matter what you write through abstracting handwriting style,”IEEE Transactions on Dependable and Secure Computing, 2026
2026
-
[2]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
Palm: Scal- ing language modeling with pathways,
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmannet al., “Palm: Scal- ing language modeling with pathways,”Journal of Machine Learning Research, vol. 24, no. 240, pp. 1–113, 2023
2023
-
[4]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[6]
Mitigating catastrophic forgetting with adaptive transformer block expansion in federated fine-tuning,
Y . Huo, J. Liu, H. Xu, Z. Ma, S. Wang, and L. Huang, “Mitigating catastrophic forgetting with adaptive transformer block expansion in federated fine-tuning,”IEEE Transactions on Mobile Computing, 2026
2026
-
[7]
The power of scale for parameter-efficient prompt tuning,
B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” inProceedings of the 2021 confer- ence on empirical methods in natural language processing, 2021, pp. 3045–3059
2021
-
[8]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,”arXiv preprint arXiv:2101.00190, 2021
work page internal anchor Pith review arXiv 2021
-
[9]
Fedquad: Adaptive layer-wise lora deployment and activation quantization for federated fine-tuning,
J. Liu, R. Li, H. Xu, Q. Ma, J. Yan, and L. Huang, “Fedquad: Adaptive layer-wise lora deployment and activation quantization for federated fine-tuning,”IEEE Transactions on Mobile Computing, 2025
2025
-
[10]
Alphalora: Assigning lora experts based on layer training quality,
P. Qing, C. Gao, Y . Zhou, X. Diao, Y . Yang, and S. V osoughi, “Alphalora: Assigning lora experts based on layer training quality,”arXiv preprint arXiv:2410.10054, 2024
-
[11]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Q. Zhang, M. Chen, A. Bukharin, N. Karampatziakis, P. He, Y . Cheng, W. Chen, and T. Zhao, “Adalora: Adaptive budget allocation for parameter-efficient fine-tuning,”arXiv preprint arXiv:2303.10512, 2023
work page internal anchor Pith review arXiv 2023
-
[12]
Adaptive mixtures of local experts,
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,”Neural computation, vol. 3, no. 1, pp. 79–87, 1991
1991
-
[13]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,”arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review arXiv 2017
-
[14]
Loramoe: Alleviate world knowledge for- getting in large language models via moe-style plugin,
S. Dou, E. Zhou, Y . Liu, S. Gao, J. Zhao, W. Shen, Y . Zhou, Z. Xi, X. Wang, X. Fanet al., “Loramoe: Alleviate world knowledge for- getting in large language models via moe-style plugin,”arXiv preprint arXiv:2312.09979, 2023
-
[15]
Mixlora: Enhancing large language models fine-tuning with lora based mixture of experts,
D. Li, Y . Ma, N. Wang, Z. Ye, Z. Cheng, Y . Tang, Y . Zhang, L. Duan, J. Zuo, C. Yanget al., “Mixlora: Enhancing large language models fine-tuning with lora-based mixture of experts,”arXiv preprint arXiv:2404.15159, 2024
-
[16]
When moe meets llms: Parameter efficient fine-tuning for multi-task medical applications,
Q. Liu, X. Wu, X. Zhao, Y . Zhu, D. Xu, F. Tian, and Y . Zheng, “When moe meets llms: Parameter efficient fine-tuning for multi-task medical applications,” inProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, 2024, pp. 1104–1114
2024
-
[17]
Da-moe: Towards dy- namic expert allocation for mixture-of-experts models,
M. A. Aghdam, H. Jin, and Y . Wu, “Da-moe: Towards dy- namic expert allocation for mixture-of-experts models,”arXiv preprint arXiv:2409.06669, 2024
-
[18]
Higher layers need more lora experts,
C. Gao, K. Chen, J. Rao, B. Sun, R. Liu, D. Peng, Y . Zhang, X. Guo, J. Yang, and V . Subrahmanian, “Higher layers need more lora experts,” arXiv preprint arXiv:2402.08562, 2024
-
[19]
Malora: Mixture of asymmetric low-rank adaptation for enhanced multi-task learning,
X. Wang, H. Zhao, S. Wang, H. Wang, and Z. Liu, “Malora: Mixture of asymmetric low-rank adaptation for enhanced multi-task learning,” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 5609–5626
2025
-
[20]
Transformer feed-forward layers are key-value memories,
M. Geva, R. Schuster, J. Berant, and O. Levy, “Transformer feed-forward layers are key-value memories,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 5484– 5495
2021
-
[21]
Attention is not all you need: Pure attention loses rank doubly exponentially with depth,
Y . Dong, J.-B. Cordonnier, and A. Loukas, “Attention is not all you need: Pure attention loses rank doubly exponentially with depth,” in International Conference on Machine Learning. PMLR, 2021, pp. 2793–2803
2021
-
[22]
Hift: A hierarchical full parameter fine-tuning strategy,
Y . Liu, Y . Zhang, Q. Li, T. Liu, S. Feng, D. Wang, Y . Zhang, and H. Schütze, “Hift: A hierarchical full parameter fine-tuning strategy,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 18 266–18 287
2024
-
[23]
Adafun: Enhancing federated unlearning with adaptive local step in edge computing,
Z. Ma, Y . Sun, H. Xu, J. Liu, B. Wang, K. Dong, and Z. He, “Adafun: Enhancing federated unlearning with adaptive local step in edge computing,”IEEE Transactions on Services Computing, 2026
2026
-
[24]
T. Luo, J. Lei, F. Lei, W. Liu, S. He, J. Zhao, and K. Liu, “Moelora: Con- trastive learning guided mixture of experts on parameter-efficient fine- tuning for large language models,”arXiv preprint arXiv:2402.12851, 2024
-
[25]
Pushing mixture of experts to the limit: Extremely parameter efficient moe for instruction tuning,
T. Zadouri, A. Üstün, A. Ahmadian, B. Ermi¸ s, A. Locatelli, and S. Hooker, “Pushing mixture of experts to the limit: Extremely parameter efficient moe for instruction tuning,”arXiv preprint arXiv:2309.05444, 2023
-
[26]
Mixture-of-loras: An efficient multitask tuning for large language models,
W. Feng, C. Hao, Y . Zhang, Y . Han, and H. Wang, “Mixture-of-loras: An efficient multitask tuning for large language models,”arXiv preprint arXiv:2403.03432, 2024
-
[27]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
Learn to explain: Multimodal reasoning via thought chains for science question answering,
P. Lu, S. Mishra, T. Xia, L. Qiu, K.-W. Chang, S.-C. Zhu, O. Tafjord, P. Clark, and A. Kalyan, “Learn to explain: Multimodal reasoning via thought chains for science question answering,”Advances in neural information processing systems, vol. 35, pp. 2507–2521, 2022
2022
-
[29]
Asynchronous federated learning over non-iid data via over-the-air computation,
Q. Ma, X. Song, J. Zhou, H. Wang, Y . Liao, J. Liu, and H. Xu, “Asynchronous federated learning over non-iid data via over-the-air computation,”IEEE Transactions on Networking, 2025
2025
-
[30]
Can a suit of armor conduct electricity? a new dataset for open book question answering,
T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal, “Can a suit of armor conduct electricity? a new dataset for open book question answering,” inProceedings of the 2018 conference on empirical methods in natural language processing, 2018, pp. 2381–2391
2018
-
[31]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakanoet al., “Training verifiers to solve math word problems,”arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[32]
Parameter-efficient transfer learning for nlp,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for nlp,” inInternational conference on machine learning. PMLR, 2019, pp. 2790–2799
2019
-
[33]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
2022
-
[34]
A sensitivity- driven expert allocation method in lora-moe for efficient fine-tuning,
J. Xu, B. Diao, C. Qi, S. Zhao, R. Wang, and Y . Xu, “A sensitivity- driven expert allocation method in lora-moe for efficient fine-tuning,” in 2025 IEEE 25th International Symposium on Cluster, Cloud and Internet Computing (CCGrid). IEEE, 2025, pp. 01–08
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.