Recognition: unknown
A Provably Robust Multi-Jet Framework applied to Active Flow Control of an Airfoil in Weakly Compressible Flow
Pith reviewed 2026-05-07 10:51 UTC · model grok-4.3
The pith
A new multi-jet formulation resolves redundant actions in reinforcement learning flow control and raises airfoil aerodynamic efficiency from 53 to 73 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
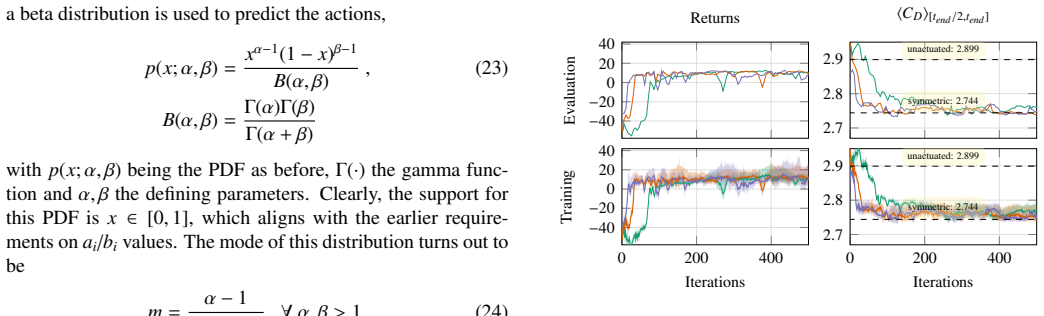
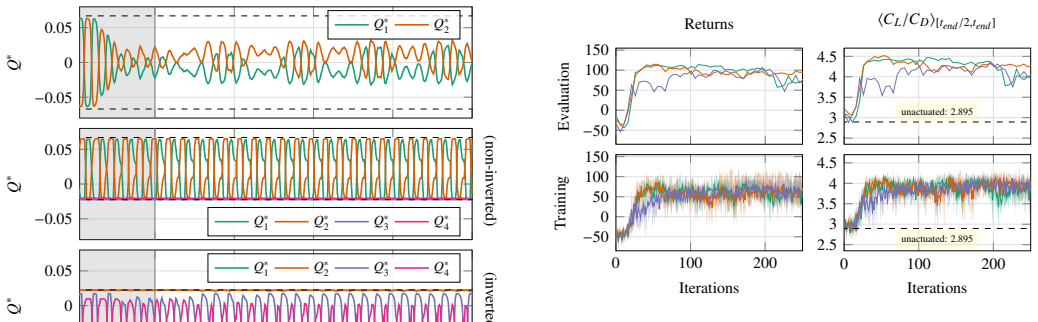
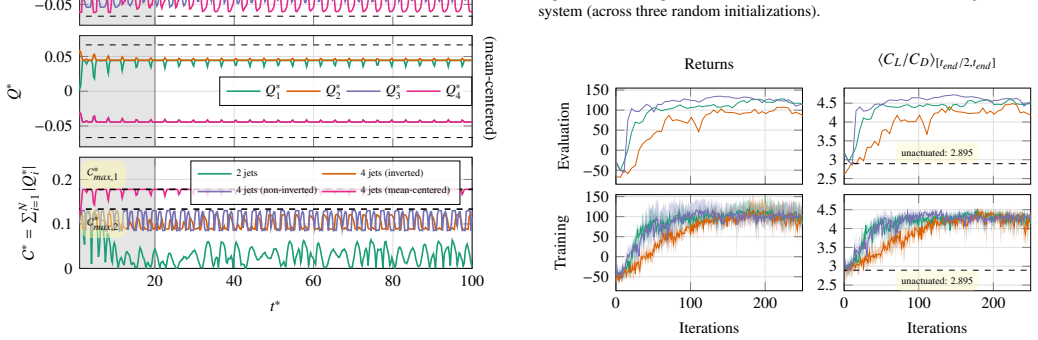
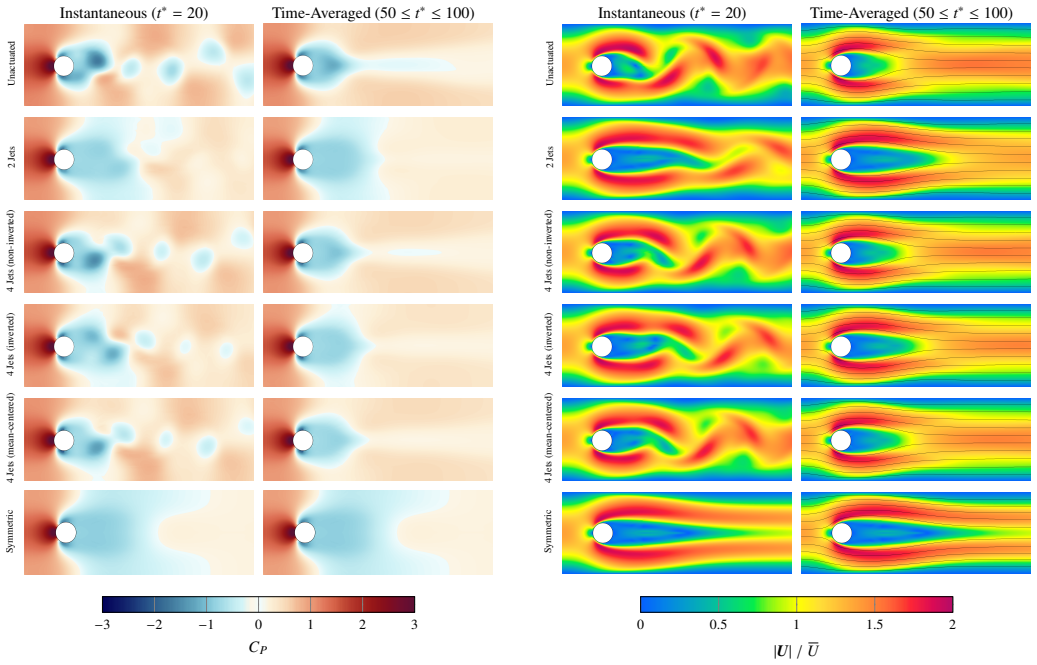
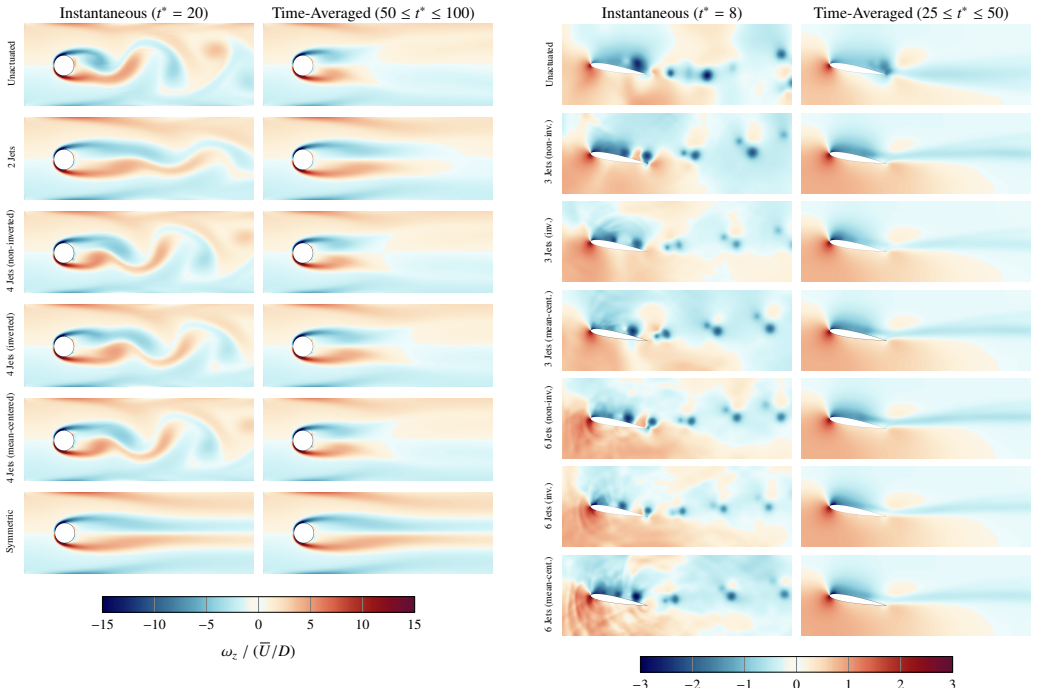
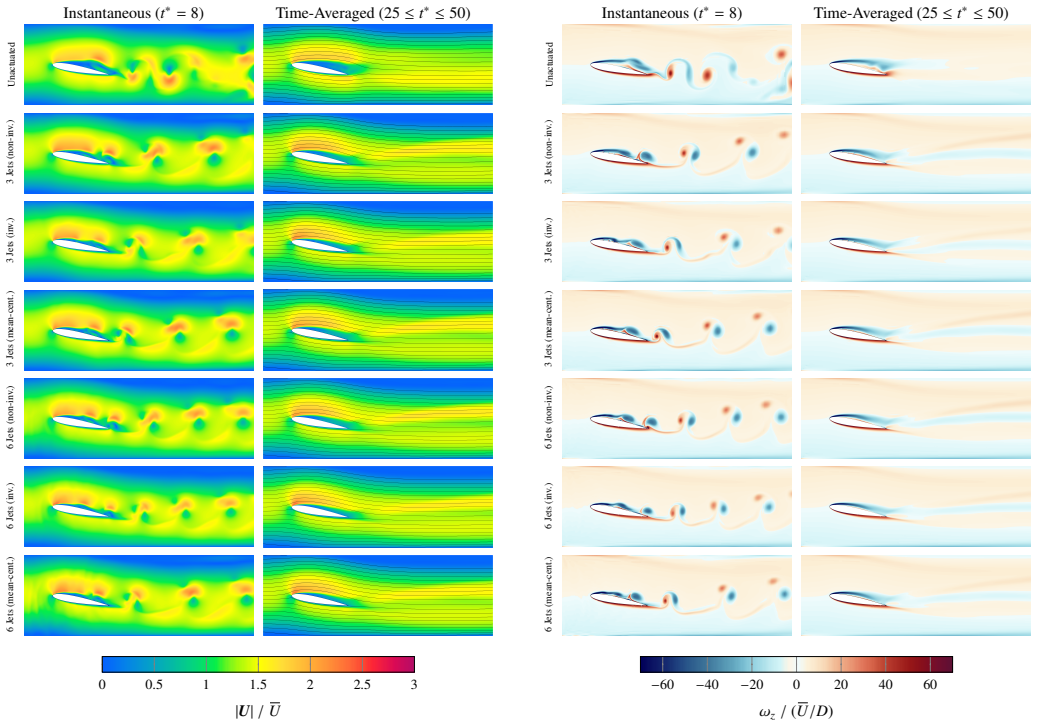
The paper claims that replacing the mean-centered multi-jet mapping with a non-injective alternative, together with cost upper bounds that do not grow with jet count, enables reinforcement learning to discover sophisticated coordinated jet strategies; these strategies suppress drag and total force beyond an idealized symmetric case for a cylinder in a channel and reduce the separation region on an airfoil, lifting aerodynamic efficiency from 53 percent to as high as 73 percent depending on the jet layout.
What carries the argument
The proposed non-injective alternative to the mean-centered multi-jet mapping, together with the derived jet-count-independent upper bounds on actuation costs.
If this is right
- Reinforcement learning can coordinate multiple jets in a sophisticated manner to produce favorable flow outcomes at minimal actuation cost.
- For the cylinder-in-channel configuration, drag and total-force suppression exceed the idealized symmetric case.
- For the airfoil, the separation region is minimized and aerodynamic efficiency improves from 53 percent up to 73 percent depending on jet configuration.
- Incorporating standard reinforcement learning practices reduces upfront training costs while maintaining fast, reproducible, and reliable learning.
- The overall approach supplies a robust and mathematically grounded method for designing multi-jet active flow control.
Where Pith is reading between the lines
- The cost bound that stays flat with added jets may allow practitioners to increase the number of actuators without a proportional rise in running expense across other fluid systems.
- If the non-injectivity fix generalizes, similar redundancy issues in other multi-actuator reinforcement learning problems could be resolved by the same mapping change.
- Direct numerical or experimental checks of the predicted cost bounds in the airfoil geometry would confirm whether the theoretical guarantees survive in the target flow regime.
Load-bearing premise
The theoretical non-injectivity analysis and cost upper bounds derived in general must remain valid and tight when applied to the specific weakly compressible airfoil flow, and reinforcement learning must discover the claimed complex coordinated strategies reliably without instability or extra tuning.
What would settle it
A side-by-side simulation of the airfoil case that records achieved aerodynamic efficiency and total actuation cost for both the mean-centered and the proposed multi-jet formulations; if the proposed method fails to exceed 53 percent efficiency or if measured costs increase with added jets, the central claims are falsified.
Figures














read the original abstract
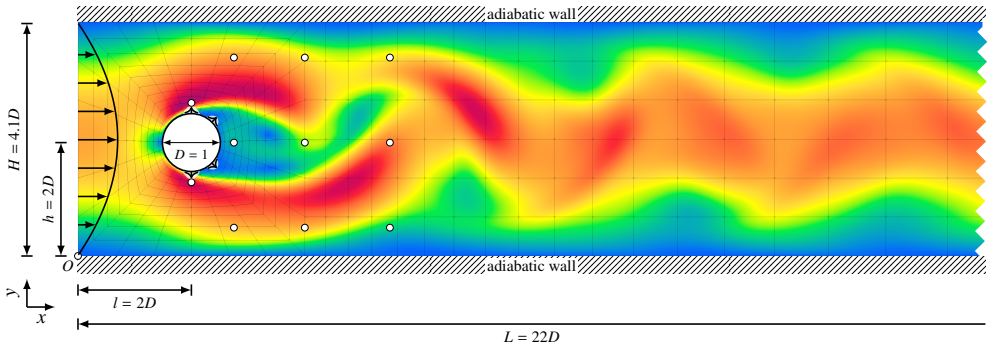
Reinforcement learning has by now become well established in finding excellent flow control strategies for a variety of scenarios. Existing literature has focused on using a simple two-jet solution (and variants there-of) or a straightforward mean-centered multi-jet setup. This mean-centering approach is however non-injective in nature, such that distinct action predictions by the actor network can lead to the same implemented jet-intensities. Thus, the potential of true multi-jet setups still remains unexplored. To this end, in this study we first theoretically analyze multi-jet setups, highlighting the aforementioned pitfall and offer a viable alternative. We also derive upper-bounds on the running costs of these setups, and find the proposed approach to have a jet-count-independent maximum running cost (compared to a near-linear scaling for the traditional setup). The mean-centered and proposed multi-jet setups are applied to a variety of flow-configurations, to test performance and learning capabilities. The new formulation proves effective in learning more complex flow-control strategies, coordinating the jets in a sophisticated manner so as to produce favorable outcomes at minimal actuation cost. For the cylinder-in-channel case, this results in drag and total-force suppression to beyond an idealized symmetric case, whereas for the airfoil the separation region is minimized and significant improvements in aerodynamic efficiency are observed (from 53% up to 73% depending on jet configuration). Additionally, we also incorporate some best practices from traditional RL literature to show fast, reproducible and reliable learning, thereby bringing down the upfront training costs. This study thus provides a robust and mathematically grounded approach to multi-jet design and closes a hitherto overlooked theoretical gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a new multi-jet action parameterization for RL-based active flow control that addresses the non-injectivity of mean-centered multi-jet setups. It provides theoretical analysis of multi-jet configurations, derives jet-count-independent upper bounds on running costs for the proposed approach (versus near-linear scaling for the traditional one), and applies both setups to cylinder-in-channel and airfoil cases in weakly compressible flow. The new formulation is claimed to enable learning of complex coordinated jet strategies yielding drag/total-force suppression beyond symmetric baselines for the cylinder and airfoil aerodynamic efficiency gains from 53% to 73%, with additional RL best practices incorporated for fast, reproducible training.
Significance. If the central claims hold, the work supplies a mathematically grounded multi-jet framework with explicit cost bounds that could improve efficiency and reliability of RL flow control in aerodynamics. The derivation of parameterization-independent cost upper bounds and the non-injectivity analysis constitute clear strengths, as does the extension to a realistic airfoil case. The incorporation of RL best practices is noted positively for training reliability, but the overall significance depends on whether performance gains can be attributed to the new formulation rather than the joint training practices.
major comments (2)
- [Abstract] Abstract: The efficiency gains (53% to 73%) and drag suppression beyond the idealized symmetric case are reported under the combined application of the proposed parameterization plus RL best practices, yet no controlled ablation (proposed vs. mean-centered, both with identical best practices) is described. This is load-bearing for the central claim that the new formulation enables superior coordinated strategies at minimal cost.
- [Abstract] Abstract and results on airfoil: The claim that the theoretical non-injectivity analysis and jet-count-independent cost upper bounds remain valid and tight is transferred to the weakly compressible airfoil without explicit verification that the bounds are achieved by the learned policies or that the reward explicitly leverages bound tightness; post-hoc selection of jet configurations may further affect the reported numbers.
minor comments (1)
- [Methods] The notation distinguishing jet intensities and the precise definition of the mean-centered baseline could be clarified for reproducibility, particularly when describing how distinct actor predictions map to implemented actions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments help clarify the attribution of results and the scope of the theoretical claims. We respond point-by-point below and indicate the revisions we will make to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: The efficiency gains (53% to 73%) and drag suppression beyond the idealized symmetric case are reported under the combined application of the proposed parameterization plus RL best practices, yet no controlled ablation (proposed vs. mean-centered, both with identical best practices) is described. This is load-bearing for the central claim that the new formulation enables superior coordinated strategies at minimal cost.
Authors: We agree that a controlled ablation isolating the parameterization effect from the RL best practices is necessary to strengthen attribution of the performance gains. The manuscript already applies and compares both the mean-centered and proposed multi-jet setups on the cylinder and airfoil cases, with the proposed formulation yielding coordinated strategies and lower costs. However, the best practices were incorporated primarily to ensure reliable training across experiments. In the revised manuscript we will add an explicit ablation section (or supplementary table) that retrains or reports results for the mean-centered baseline under the identical best-practice protocol used for the proposed method. This will allow direct comparison and better support the claim that the injective parameterization itself enables the superior strategies. revision: yes
-
Referee: [Abstract] Abstract and results on airfoil: The claim that the theoretical non-injectivity analysis and jet-count-independent cost upper bounds remain valid and tight is transferred to the weakly compressible airfoil without explicit verification that the bounds are achieved by the learned policies or that the reward explicitly leverages bound tightness; post-hoc selection of jet configurations may further affect the reported numbers.
Authors: The non-injectivity analysis and the jet-count-independent upper bounds on running cost are derived solely from the mathematical properties of the action parameterization; they hold for any downstream flow solver or reward and do not require flow-specific verification. The bounds limit the worst-case actuation cost of any policy, independent of compressibility. In the airfoil results the learned policies indeed operated at low actuation costs consistent with these bounds, but we did not explicitly measure how close the policies came to the theoretical maximum nor design the reward to enforce tightness. We also acknowledge that the reported jet-configuration numbers reflect post-training selection among several trained agents. In the revision we will (i) restate that the bounds are parameterization-level guarantees and therefore transfer directly to the airfoil, (ii) report the observed actuation costs relative to the derived upper bound for the airfoil policies, and (iii) clarify the selection procedure for the final jet configurations to rule out selective reporting. revision: partial
Circularity Check
Cost upper bounds are definitional properties of the new parameterization rather than independent predictions
specific steps
-
self definitional
[Abstract]
"We also derive upper-bounds on the running costs of these setups, and find the proposed approach to have a jet-count-independent maximum running cost (compared to a near-linear scaling for the traditional setup)."
The upper bound follows immediately from how the proposed parameterization is defined (total actuation capped independently of jet count), so the 'derivation' and 'finding' restate the construction rather than providing new content or external validation.
full rationale
The paper's theoretical analysis derives jet-count-independent cost upper bounds directly from the definition of the proposed multi-jet action space (as contrasted with mean-centered scaling). This is a mathematical property of the formulation itself, not an external verification or falsifiable prediction. However, the central empirical claims (drag suppression, efficiency gains from 53% to 73%) rest on RL experiments that incorporate external best practices and are not reduced to the bounds. No self-citation chains or uniqueness theorems are invoked as load-bearing; the derivation chain remains partially independent outside the cost analysis.
Axiom & Free-Parameter Ledger
free parameters (1)
- number and placement of jets
axioms (2)
- domain assumption The mean-centered multi-jet mapping is non-injective
- domain assumption RL agent can learn coordinated jet strategies under the new mapping
Reference graph
Works this paper leans on
-
[1]
Cambridge University Press, 2000
Mohamed Gad-el Hak.Flow Control: Passive, Active, and Reactive Flow Management. Cambridge University Press, 2000
2000
-
[2]
McLellan and Charles L
Bruce W. McLellan and Charles L. Ladson. A history of suction-type laminar-flow control with emphasis on flight research. Technical Report TM-4080, NASA, 1988
1988
-
[3]
Squires, and Elias Balaras
Nikolaos Beratlis, Kyle D. Squires, and Elias Balaras. Separation control and drag reduction using roughness elements. InProceeding of Tenth International Sympo- sium on Turbulence and Shear Flow Phenomena, pages 199–204. Begellhouse, 2017. Place: Swissotel Chicago, Chicago, Illinois, U.S.A
2017
-
[4]
D. W. Bechert and M. Bartenwerfer. The viscous flow on surfaces with longitudinal ribs.Journal of Fluid Mechan- ics, 206:105–129, September 1989. ISSN 1469-7645, 0022-1120
1989
-
[5]
Concept to reality: contributions of the langley research center to us civil aircraft of the 1990s
Joseph R Chambers. Concept to reality: contributions of the langley research center to us civil aircraft of the 1990s. NASA Special Publication, page 59513, 2003
2003
-
[6]
Review of research on low-profile vortex gen- erators to control boundary-layer separation.Progress in aerospace sciences, 38(4-5):389–420, 2002
John C Lin. Review of research on low-profile vortex gen- erators to control boundary-layer separation.Progress in aerospace sciences, 38(4-5):389–420, 2002
2002
-
[7]
Aerody- namic flow control using synthetic jet technology
Michael Amitay, Barton Smith, and Ari Glezer. Aerody- namic flow control using synthetic jet technology. In36th AIAA Aerospace Sciences Meeting and Exhibit, page 208, 1998
1998
-
[8]
Wygnanski
David Greenblatt and Israel J. Wygnanski. The control of flow separation by periodic excitation.Progress in Aerospace Sciences, 36(7):487–545, October 2000. ISSN 0376-0421
2000
-
[9]
Direct numerical simulation of spatially developing turbulent boundary lay- ers with uniform blowing or suction.Journal of Fluid Me- chanics, 681:154–172, August 2011
Yukinori Kametani and Koji Fukagata. Direct numerical simulation of spatially developing turbulent boundary lay- ers with uniform blowing or suction.Journal of Fluid Me- chanics, 681:154–172, August 2011. ISSN 1469-7645, 0022-1120
2011
-
[10]
Three-dimensional suction flow control and suction jet length optimization of NACA 0012 wing.Meccanica, 50(6):1481–1494, June
Kianoosh Yousefi and Reza Saleh. Three-dimensional suction flow control and suction jet length optimization of NACA 0012 wing.Meccanica, 50(6):1481–1494, June
-
[11]
A. V . V oevodin, A. A. Kornyakov, A. S. Petrov, D. A. Petrov, and G. G. Sudakov. Improvement of the take-off and landing characteristics of wing using an ejector pump. Thermophysics and Aeromechanics, 26(1):9–18, January
-
[12]
High- lift enhancement using active flow control
Michael Desalvo, Edward Whalen, and Ari Glezer. High- lift enhancement using active flow control. In6th AIAA flow control conference, page 3245, 2012
2012
-
[13]
Post-stall flow control on an airfoil by local unsteady forcing.Journal of fluid Mechanics, 371: 21–58, 1998
Jie-Zhi Wu, Xi-Yun Lu, Andrew G Denny, Meng Fan, and Jain-Ming Wu. Post-stall flow control on an airfoil by local unsteady forcing.Journal of fluid Mechanics, 371: 21–58, 1998
1998
-
[14]
Active flow control for high lift with steady blowing.The Aeronautical Journal, 120(1223):171–200, 2016
Rolf Radespiel, Marco Burnazzi, M Casper, and P Scholz. Active flow control for high lift with steady blowing.The Aeronautical Journal, 120(1223):171–200, 2016
2016
-
[15]
Feedback control of vortex shedding from a circular cylinder by cross-flow cylinder oscillations.Experiments in Fluids, 21(1):49–56, 1996
HM Warui and N Fujisawa. Feedback control of vortex shedding from a circular cylinder by cross-flow cylinder oscillations.Experiments in Fluids, 21(1):49–56, 1996
1996
-
[16]
Suboptimal feedback control of vortex shedding at low reynolds numbers.Jour- nal of Fluid Mechanics, 401:123–156, 1999
Chulhong Min and Haecheon Choi. Suboptimal feedback control of vortex shedding at low reynolds numbers.Jour- nal of Fluid Mechanics, 401:123–156, 1999
1999
-
[17]
Sridhar Muddada and B. S. V . Patnaik. An active flow control strategy for the suppression of vortex structures behind a circular cylinder.European Journal of Mechan- ics - B/Fluids, 29(2):93–104, March 2010. ISSN 0997- 7546
2010
-
[18]
Closed- loop active flow control of stall separation using synthetic jets
Byunghyun Lee, Minhee Kim, Byounghun Choi, Chongam Kim, H Jin Kim, and Kyoung Jin Jung. Closed- loop active flow control of stall separation using synthetic jets. In31st AIAA applied aerodynamics conference, page 2925, 2013
2013
-
[19]
Loïc Michel, Ingrid Neunaber, Rishabh Mishra, Caroline Braud, Franck Plestan, Jean-Pierre Barbot, and Pol Ha- mon. A novel lift controller for a wind turbine blade sec- tion using an active flow control device including satura- tions: experimental results.IEEE Transactions on Control Systems Technology, 32(5):1590–1601, 2024
2024
-
[20]
An active flow control approach for spa- tially growing mixing layer.Journal of Fluids Engineer- ing, 144(6):061110, 2022
Upender K Kaul. An active flow control approach for spa- tially growing mixing layer.Journal of Fluids Engineer- ing, 144(6):061110, 2022. 22
2022
-
[21]
Matthias Kiesner and Rudibert King. Multivariable closed-loop active flow control of a compressor stator cascade.AIAA Journal, 55(10):3371–3380, 2017. doi: 10.2514/1.J055728. URLhttps://doi.org/10.2514/ 1.J055728
-
[22]
Closed-loop active flow control of a non-steady flow field in a highly-loaded compressor cascade.CEAS Aeronauti- cal Journal, 8(1):197–208, 2017
Marcel Staats, W Nitsche, SJ Steinberg, and R King. Closed-loop active flow control of a non-steady flow field in a highly-loaded compressor cascade.CEAS Aeronauti- cal Journal, 8(1):197–208, 2017
2017
-
[23]
Application of active flow control on generic 3d car models
Daniel Krentel, Rifet Muminovic, André Brunn, Wolf- gang Nitsche, and Rudibert King. Application of active flow control on generic 3d car models. InActive Flow Control II: Papers Contributed to the Conference” Active Flow Control II 2010”, Berlin, Germany, May 26 to 28, 2010, pages 223–239. Springer, 2010
2010
-
[24]
Artificial neural networks trained through deep reinforcement learning discover con- trol strategies for active flow control.Journal of Fluid Me- chanics, 865:281–302, apr 2019
Jean Rabault, Miroslav Kuchta, Atle Jensen, Ulysse Reglade, and Nicolas Cerardi. Artificial neural networks trained through deep reinforcement learning discover con- trol strategies for active flow control.Journal of Fluid Me- chanics, 865:281–302, apr 2019. ISSN 0022-1120, 1469-
2019
-
[25]
doi: 10.1017/jfm.2019.62
-
[26]
Jean Rabault and Alexander Kuhnle. Accelerating deep reinforcement learning strategies of flow control through a multi-environment approach.Physics of Fluids, 31(9): 094105, sep 2019. ISSN 1070-6631, 1089-7666. doi: 10.1063/1.5116415
-
[27]
Jean Rabault, Feng Ren, Wei Zhang, Hui Tang, and Hui Xu. Deep reinforcement learning in fluid mechanics: a promising method for both active flow control and shape optimization.arXiv preprint arXiv:2001.02464, 2020
-
[28]
Hongwei Tang, Jean Rabault, Alexander Kuhnle, Yan Wang, and Tongguang Wang. Robust active flow con- trol over a range of reynolds numbers using an artificial neural network trained through deep reinforcement learn- ing.Physics of Fluids, 32(5):053605, 05 2020. ISSN 1070-6631. doi: 10.1063/5.0006492. URLhttps:// doi.org/10.1063/5.0006492
-
[29]
Deep reinforcement learning based synthetic jet control on disturbed flow over airfoil
Yi-Zhe Wang, Yu-Fei Mei, Nadine Aubry, Zhihua Chen, Peng Wu, and Wei-Tao Wu. Deep reinforcement learning based synthetic jet control on disturbed flow over airfoil. Physics of Fluids, 34(3), 2022
2022
-
[30]
Xavier Garcia, Arnau Miró, Pol Suárez, Francisco Alcántara-Ávila, Jean Rabault, Bernat Font, Oriol Lehmkuhl, and Ricardo Vinuesa. Deep-reinforcement- learning-based separation control in a two-dimensional airfoil.International Journal of Heat and Fluid Flow, 116:109913, 2025. ISSN 0142-727X. doi: https://doi.org/10.1016/j.ijheatfluidflow.2025.109913. URLh...
-
[31]
Pol Suárez, Francisco Alcántara-Ávila, Arnau Miró, Jean Rabault, Bernat Font, and Oriol Lehmkuhl. Active flow control for three-dimensional cylinders through deep re- inforcement learning.arXiv preprint arXiv:2309.02462, 2023
-
[32]
Suárez, F
P. Suárez, F. Álcantara-Ávila, J. Rabault, A. Miró, B. Font, O. Lehmkuhl, and R. Vinuesa. Flow control of three-dimensional cylinders transitioning to turbulence via multi-agent reinforcement learning, may 2024
2024
-
[33]
Active flow control for drag reduction through multi-agent reinforcement learning on a turbulent cylin- der at r e d=3900.Flow, Turbulence and Combustion, pages 1–25, 2025
Pol Suárez, Francisco Alcántara-Ávila, Arnau Miró, Jean Rabault, Bernat Font, Oriol Lehmkuhl, and Ricardo Vin- uesa. Active flow control for drag reduction through multi-agent reinforcement learning on a turbulent cylin- der at r e d=3900.Flow, Turbulence and Combustion, pages 1–25, 2025
2025
-
[34]
Trishit Mondal, Ricardo Vinuesa, and Ameya D Jag- tap. Shocks under control: Taming transonic compress- ible flow over an rae2822 airfoil with deep reinforcement learning.arXiv preprint arXiv:2511.07564, 2025
-
[35]
Pol Suárez, Francisco Alcántara-Ávila, Arnau Miró, Jean Rabault, Bernat Font, Oriol Lehmkuhl, and Ricardo Vin- uesa. Active flow control for drag reduction through multi-agent reinforcement learning on a turbulent cylin- der at Re D =3900.Flow, Turbulence and Combus- tion, mar 2025. ISSN 1386-6184, 1573-1987. doi: 10.1007/s10494-025-00642-x
-
[36]
Invariant control strategies for active flow control using graph neural networks.Com- puters&Fluids, 303:106854, 2025
Marius Kurz, Rohan Kaushik, Marcel Blind, Patrick Kopper, Anna Schwarz, Felix Rodach, and An- drea Beck. Invariant control strategies for active flow control using graph neural networks.Com- puters&Fluids, 303:106854, 2025. ISSN 0045-
2025
-
[37]
doi: https://doi.org/10.1016/j.compfluid.2025. 106854. URLhttps://www.sciencedirect.com/ science/article/pii/S0045793025003147
-
[38]
Inflow/outflow boundary condi- tions with application to FUN3D
Jan-Reneé Carlson. Inflow/outflow boundary condi- tions with application to FUN3D. Technical Report NASA/TM–2011-217181, Langley Research Center, Lan- gley Research Center, Hampton, V A, United States, oct 2011
2011
-
[39]
Nico Krais, Andrea Beck, Thomas Bolemann, Hannes Frank, David Flad, Gregor Gassner, Florian Hindenlang, Malte Hoffmann, Thomas Kuhn, Matthias Sonntag, and Claus-Dieter Munz. FLEXI: A high order discontinu- ous Galerkin framework for hyperbolic–parabolic con- servation laws.Computers&Mathematics with Appli- cations, 81:186–219, jan 2021. ISSN 08981221. doi...
-
[40]
Springer Nature Switzerland, Cham, 2024
Marcel Blind, Patrick Kopper, Daniel Kempf, Marius Kurz, Anna Schwarz, Claus-Dieter Munz, and Andrea Beck.Performance Improvements for Large Scale Sim- ulations Using the Discontinuous Galerkin Framework 23 FLEXI, pages 249–264. Springer Nature Switzerland, Cham, 2024. ISBN 978-3-031-46870-4
2024
-
[41]
Blind, Tobias Gibis, Christoph Wenzel, and An- drea Beck
Marcel P. Blind, Tobias Gibis, Christoph Wenzel, and An- drea Beck. Wall-modeled large eddy simulation of a tan- dem wing configuration in transonic flow.Physics of Fluids, 36(5):055125, 05 2024. ISSN 1070-6631. doi: 10.1063/5.0198271
-
[42]
An efficient sliding mesh interface method for high- order discontinuous galerkin schemes.Comput- ers&Fluids, 217:104825, 2021
Jakob Dürrwächter, Marius Kurz, Patrick Kopper, Daniel Kempf, Claus-Dieter Munz, and Andrea Beck. An efficient sliding mesh interface method for high- order discontinuous galerkin schemes.Comput- ers&Fluids, 217:104825, 2021. ISSN 0045-
2021
-
[43]
doi: https://doi.org/10.1016/j.compfluid.2020. 104825. URLhttps://www.sciencedirect.com/ science/article/pii/S0045793020303959
-
[44]
Proximal policy optimization algorithms.arXiv preprint, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint, 2017
2017
-
[45]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforce- ment learning.arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review arXiv 2015
-
[46]
Distributed distributional deterministic policy gradients
Gabriel Barth-Maron, Matthew W Hoffman, David Bud- den, Will Dabney, Dan Horgan, Dhruva Tb, Alistair Mul- dal, Nicolas Heess, and Timothy Lillicrap. Distributed distributional deterministic policy gradients.arXiv preprint arXiv:1804.08617, 2018
-
[47]
Continuous deep Q-learning with model- based acceleration
Shixiang Gu, Timothy Lillicrap, Ilya Sutskever, and Sergey Levine. Continuous deep Q-learning with model- based acceleration. In Maria Florina Balcan and Kil- ian Q. Weinberger, editors,Proceedings of The 33rd International Conference on Machine Learning, vol- ume 48 ofProceedings of Machine Learning Research, pages 2829–2838, New York, New York, USA, 20–...
2016
-
[48]
MIT press Cam- bridge, 2020
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cam- bridge, 2020
2020
-
[49]
SIAM, 1973
Peter D Lax.Hyperbolic systems of conservation laws and the mathematical theory of shock waves. SIAM, 1973
1973
-
[50]
Springer Science & Business Media, 2013
Eleuterio F Toro.Riemann solvers and numerical meth- ods for fluid dynamics: a practical introduction. Springer Science & Business Media, 2013
2013
-
[51]
Marius Kurz, Philipp Offenhäuser, Dominic Viola, Michael Resch, and Andrea Beck. Relexi — A scalable open source reinforcement learning framework for high- performance computing.Software Impacts, 14:100422, dec 2022. ISSN 2665-9638. doi: 10.1016/j.simpa.2022. 100422
-
[52]
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghe- mawat, Ian Goodfellow, Andrew Harp, Geoffrey Irv- ing, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan- delion Mané, Rajat Monga, Sherry Moore, Derek...
2015
-
[53]
TF-Agents: A library for reinforcement learning in tensorflow.https: //github.com/tensorflow/agents, 2018
Sergio Guadarrama, Anoop Korattikara, Oscar Ramirez, Pablo Castro, Ethan Holly, Sam Fishman, Ke Wang, Eka- terina Gonina, Neal Wu, Efi Kokiopoulou, Luciano Sbaiz, Jamie Smith, Gábor Bartók, Jesse Berent, Chris Harris, Vincent Vanhoucke, and Eugene Brevdo. TF-Agents: A library for reinforcement learning in tensorflow.https: //github.com/tensorflow/agents, ...
2018
-
[54]
Shao, Scott Bachman, Gustavo Marques, and Benjamin Robbins
Sam Partee, Matthew Ellis, Alessandro Rigazzi, An- drew E. Shao, Scott Bachman, Gustavo Marques, and Benjamin Robbins. Using machine learning at scale in numerical simulations with SmartSim: An application to ocean climate modeling.Journal of Computational Science, 62:101707, July 2022. ISSN 18777503. doi: 10.1016/j.jocs.2022.101707
-
[55]
Implementation matters in deep RL: A case study on PPO and TRPO
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dim- itris Tsipras, Firdaus Janoos, Larry Rudolph, and Alek- sander Madry. Implementation matters in deep RL: A case study on PPO and TRPO. InInternational conference on learning representations, 2019
2019
-
[56]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review arXiv 2014
-
[57]
Yuxing Liu, Yuze Ge, Rui Pan, An Kang, and Tong Zhang. Theoretical analysis on how learning rate warmup accel- erates convergence.arXiv preprint arXiv:2509.07972, 2025
-
[58]
Revisiting the initial steps in adaptive gradient descent optimization
Abulikemu Abuduweili and Changliu Liu. Revisiting the initial steps in adaptive gradient descent optimization. arXiv preprint arXiv:2412.02153, 2024
-
[59]
Why warmup the learning rate? underlying mechanisms and improve- ments.Advances in Neural Information Processing Sys- tems, 37:111760–111801, 2024
Dayal Singh Kalra and Maissam Barkeshli. Why warmup the learning rate? underlying mechanisms and improve- ments.Advances in Neural Information Processing Sys- tems, 37:111760–111801, 2024
2024
-
[60]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, 24 and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[61]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noord- huis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large mini- batch sgd: Training imagenet in 1 hour.arXiv preprint arXiv:1706.02677, 2017
work page internal anchor Pith review arXiv 2017
-
[62]
Akhilesh Gotmare, Nitish Shirish Keskar, Caiming Xiong, and Richard Socher. A closer look at deep learning heuris- tics: Learning rate restarts, warmup and distillation.arXiv preprint arXiv:1810.13243, 2018
-
[63]
C. Vignon, J. Rabault, and R. Vinuesa. Recent advances in applying deep reinforcement learning for flow control: Perspectives and future directions.Physics of Fluids, 35 (3):031301, mar 2023. ISSN 1070-6631, 1089-7666. doi: 10.1063/5.0143913
-
[64]
Perspectives on predicting and control- ling turbulent flows through deep learning.Physics of Flu- ids, 36(3):031401, March 2024
Ricardo Vinuesa. Perspectives on predicting and control- ling turbulent flows through deep learning.Physics of Flu- ids, 36(3):031401, March 2024. ISSN 1070-6631, 1089-
2024
-
[65]
doi: 10.1063/5.0190452. 25
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.