Recognition: unknown
Who Trains Matters: Federated Learning under Enrollment and Participation Selection Biases
Pith reviewed 2026-05-07 13:11 UTC · model grok-4.3
The pith
Federated learning can be skewed by enrollment and participation biases, but inverse-probability weighting recovers the target population's intended update.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FedIPW is an inverse-probability-weighted aggregation scheme that recovers the target-population mean update under ignorability and positivity assumptions for the two-stage selection process in federated learning.
What carries the argument
FedIPW, the inverse-probability-weighted aggregation that multiplies each participating client's update by the reciprocal of its enrollment and participation probability.
If this is right
- Ordinary federated averaging yields a persistent objective mismatch whenever enrollment or participation is non-random.
- The limited-information calibration version can still reduce target-population error when only aggregate population statistics are available.
- Any uncorrected residual in the weights produces a non-vanishing bias floor rather than converging to zero.
- Enrollment correction yields measurable drops in target error on synthetic logistic-regression tasks under two-stage selection.
Where Pith is reading between the lines
- The same weighting logic could be applied to correct demographic imbalances that arise from device or user filtering in other distributed systems.
- Accurate estimation of selection probabilities may require new protocols that let the server learn enrollment rules without seeing individual client data.
- If selection bias is left uncorrected, models deployed in practice may systematically underperform for the very subpopulations that are least likely to participate.
Load-bearing premise
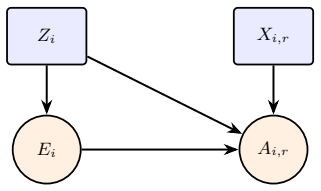
Selection into enrollment and participation depends only on observed factors and every client has a positive chance of being chosen.
What would settle it
A controlled simulation in which the two-stage selection probabilities are known exactly, FedIPW is applied, yet the weighted aggregate still deviates from the true population mean update.
Figures

read the original abstract
Federated learning (FL) trains a shared model from updates contributed by distributed clients, often implicitly assuming that contributing clients are representative of the target population. In practice, this representativeness assumption can fail at two distinct stages, inducing selection bias. First, eligibility rules such as device constraints, software requirements, or user consent determine which clients are ever enrolled and reachable for training, inducing \emph{enrollment bias}. Second, among enrolled clients, user and system factors such as battery state, network status, and local time determine which clients participate in each communication round, inducing \emph{participation bias}. Although existing work has largely addressed round-level participation bias, it has paid far less attention to population-level enrollment bias, which can induce a persistent mismatch between the training objective and the target-population objective. We formalize FL under a two-stage selection model and derive \textsc{FedIPW}, an inverse-probability-weighted aggregation scheme that recovers the target-population mean update under standard ignorability and positivity assumptions. Because client-level covariates are often unavailable for non-enrolled clients, we also introduce a limited-information aggregate-calibration extension that uses known target-population summaries to reweight the enrolled sample, partially correcting enrollment bias. We further provide an algorithm-agnostic optimization analysis under residual weighting error and show that incomplete selection correction can induce a non-vanishing bias floor. Finally, experiments on synthetic federated logistic regression validate the predicted objective mismatch and show that enrollment correction reduces target-population error under two-stage selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes federated learning under a two-stage selection model that separates enrollment bias (eligibility rules determining reachable clients) from participation bias (round-level factors among enrolled clients). It derives FedIPW, an inverse-probability-weighted aggregation rule that recovers the target-population mean update under standard ignorability and positivity assumptions. The paper also supplies a limited-information aggregate-calibration extension that reweights using known target-population summaries, an algorithm-agnostic analysis showing that residual weighting error produces a non-vanishing bias floor, and synthetic experiments on federated logistic regression that illustrate objective mismatch and the benefit of enrollment correction.
Significance. If the derivation holds, the work supplies a principled, assumption-explicit correction for a practically common source of population mismatch in FL. The adaptation of inverse-probability weighting to the two-stage enrollment-plus-participation process, the limited-information extension, and the explicit bias-floor analysis under incomplete correction are useful contributions. The synthetic validation is consistent with the predicted mismatch and correction, though the absence of real-world datasets or large-scale experiments limits immediate deployability claims.
minor comments (3)
- The abstract and introduction would benefit from a brief explicit statement of the two-stage selection probabilities (enrollment probability and conditional participation probability) before introducing FedIPW.
- In the optimization analysis section, the non-vanishing bias floor is derived under residual error; a short remark on how this floor scales with the number of clients or rounds would clarify practical implications.
- The synthetic experiment description should include the exact generative process for the two-stage selection (e.g., logistic forms for enrollment and participation probabilities) and the precise metric used for target-population error.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our manuscript and the recommendation for minor revision. The referee's description accurately captures the paper's contributions on the two-stage selection model, FedIPW derivation, limited-information extension, bias-floor analysis, and synthetic experiments. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The central derivation applies standard inverse-probability weighting to a newly formalized two-stage enrollment-plus-participation selection model under explicitly stated ignorability and positivity assumptions. FedIPW is constructed directly from these external methods plus the paper's model definition; it does not reduce by the paper's own equations to a fitted parameter, self-referential quantity, or prior self-citation. The limited-information aggregate-calibration extension relies on external target-population summaries rather than internal fits, and the residual-error bias analysis is algorithm-agnostic and independent of the weighting derivation itself. No load-bearing self-citations, smuggled ansatzes, or renamings of known results appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Ignorability: selection into enrollment and participation is independent of potential updates given observed covariates
- domain assumption Positivity: every client has strictly positive probability of enrollment and participation
Reference graph
Works this paper leans on
-
[1]
doi: 10.1080/01621459.1992. 10475217. David J. Goetze, Dahlia J. Felten, Jeannie R. Albrecht, and R ohit Bhattacharya. FLOSS: Federated learning with opt-out and straggler support. arXiv preprint arXiv:2507.23115 ,
-
[2]
Federated Optimization: Distributed Machine Learning for On-Device Intelligence
Jakub Kone ˇcný, H. Brendan McMahan, Daniel Ramage, and Peter Richtárik . Federated optimiza- tion: Distributed machine learning for on-device intellig ence. arXiv preprint arXiv:1610.02527 ,
-
[3]
For each enrolled client i ∈ E := {i : Ei = 1}, suppose we observe Zi
This regime ap- plies when pre-enrollment covariates are observed only for enrolled clients, while aggregate target- population summaries are available. For each enrolled client i ∈ E := {i : Ei = 1}, suppose we observe Zi. Let b(Zi) ∈ Rq be a chosen balance map, and suppose an external source provides the tar get-population moment µ b = E[b(Zi)]. We cons...
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.