Recognition: unknown
Cross-lingual Comparison of Research Funding Projects with Multilingual Sentence-BERT: Evidence from KAKENHI, NIH, NSF, and UKRI
Pith reviewed 2026-05-07 09:48 UTC · model grok-4.3
The pith
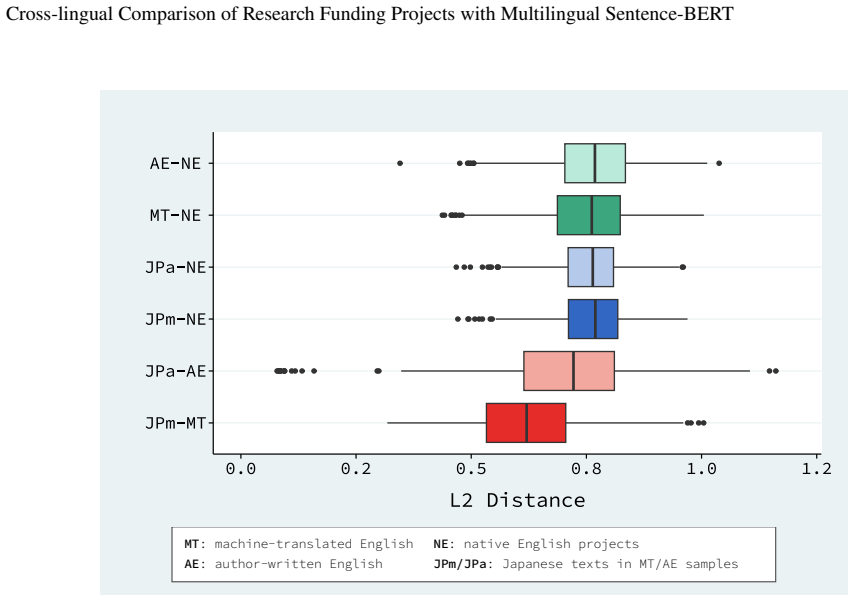
Multilingual embeddings place the Japanese and translated English versions of the same KAKENHI project closer together than either is to native English projects from NSF, NIH, or UKRI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For each KAKENHI project the Japanese text and its English translation are embedded with a multilingual Sentence-BERT model; the resulting pair lies closer in the shared space than either representation lies to projects from NSF, NIH, or UKRI. This indicates substantial cross-lingual alignment. At the same time the overlap between the ten nearest neighbors of the Japanese version and the ten nearest neighbors of the translated version averages only 2.9, showing that language and translation still shape the finer structure of the embedding space.
What carries the argument
Multilingual Sentence-BERT embeddings that map both original Japanese project descriptions and their machine-translated English versions into one vector space, enabling direct distance and nearest-neighbor comparisons.
If this is right
- Multilingual embeddings supply a workable basis for exploratory cross-country comparison of funding portfolios.
- Translating Japanese project texts into English for international analysis introduces detectable but limited semantic drift.
- Policy researchers can use the embeddings to surface comparable projects across agencies despite language differences.
- The modest nearest-neighbor overlap cautions against treating the embeddings as precise one-to-one matchers.
- The same method can be applied to other language pairs or additional funding agencies to test broader alignment.
Where Pith is reading between the lines
- The approach could extend to building global maps of research topics that cut across national funding systems.
- Agencies might use similar embeddings to identify potential international collaborators working on closely related problems.
- Testing whether fine-tuning the model on funding-specific text improves neighbor overlap would clarify how much domain adaptation helps.
- If description length or translation quality varies systematically, future checks could measure how strongly those factors distort distances.
Load-bearing premise
Distances and neighbor relations in the embedding space track genuine semantic similarity between projects rather than artifacts of translation quality, text length, or model training data.
What would settle it
Finding that the average distance between the Japanese and translated-English versions of the same project exceeds the average distance from either version to native English projects, or that nearest-neighbor overlap rises well above 2.9 out of 10, would contradict the reported alignment.
Figures


read the original abstract
Cross-national comparison of research funding projects is increasingly important for science policy and strategic planning, but language differences remain a major obstacle. In particular, KAKENHI project descriptions are written primarily in Japanese, whereas projects from major overseas funding agencies, such as NSF, NIH, and UKRI, are documented in English. This study investigates whether multilingual sentence embeddings can support meaningful cross-lingual comparison of research funding projects, with particular attention to the semantic effects of translating Japanese texts into English. For each KAKENHI project, we construct two representations: the original Japanese text and its machine-translated English version, both embedded in a shared semantic space using a multilingual Sentence-BERT model. We then compare their distances and nearest-neighbor relationships with respect to projects from English-language funding agencies. The results show that the Japanese and translated English representations of the same KAKENHI project are, on average, located closer to one another than to native English projects, indicating substantial cross-lingual alignment. However, the overlap of nearest neighbors between the two representations is limited, averaging 2.9 out of 10. This suggests that multilingual embeddings capture semantic similarity across languages to a meaningful extent, while language differences and translation still affect the local structure of the embedding space. These findings suggest that multilingual embeddings provide a useful basis for large-scale exploratory comparison of funding projects across countries and agencies. At the same time, they offer an empirical reference for assessing semantic drift when Japanese research project data are translated into English for international analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper examines the use of multilingual Sentence-BERT embeddings to compare research funding projects across languages, focusing on KAKENHI projects written in Japanese versus projects from NSF, NIH, and UKRI documented in English. For each KAKENHI project, the authors embed both the original Japanese text and its machine-translated English version in a shared space, then measure average distances and nearest-neighbor overlap (reported as 2.9 out of 10) relative to the native English projects. The central claim is that the Japanese and translated-English representations of the same KAKENHI project lie closer together than either does to native English projects, indicating substantial cross-lingual semantic alignment, while the modest neighbor overlap shows that language and translation still influence local structure.
Significance. If the distance and neighbor measurements can be shown to reflect semantic content rather than translation or model artifacts, the work supplies a concrete empirical baseline for applying multilingual embeddings to large-scale cross-national analysis of research funding. This would be directly useful for science-policy studies that require quantitative comparison of project themes across agencies and languages, and the reported overlap figure offers a practical reference point for assessing when translation-induced drift becomes problematic.
major comments (3)
- Abstract: the reported results state average closeness and 2.9/10 neighbor overlap but supply no dataset sizes, statistical tests, controls for description length, or validation of the embedding model on this domain, leaving the central claim without sufficient supporting detail.
- Methods/Results: the claim that smaller intra-project distances demonstrate semantic alignment is undermined by the absence of controls that isolate machine-translation effects; no comparisons against human translations, back-translations, or length- and topic-matched monolingual English baselines are described, so it remains possible that the observed reduction is driven by MT lexical or structural regularities rather than deeper equivalence.
- Results: the low nearest-neighbor overlap (2.9/10) is presented as evidence of residual language-specific structure, yet no further analysis quantifies how this overlap varies with project topic, length, or agency, which is needed to assess whether the embeddings are practically usable for cross-lingual retrieval or clustering.
minor comments (1)
- Abstract: the exact multilingual Sentence-BERT variant, the number of projects per agency, and the distance metric employed should be stated explicitly to allow immediate replication.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript examining multilingual Sentence-BERT for cross-lingual comparison of KAKENHI, NSF, NIH, and UKRI projects. The feedback highlights opportunities to strengthen the presentation of results and controls. We address each major comment below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: Abstract: the reported results state average closeness and 2.9/10 neighbor overlap but supply no dataset sizes, statistical tests, controls for description length, or validation of the embedding model on this domain, leaving the central claim without sufficient supporting detail.
Authors: We agree the abstract would benefit from additional context to support the claims. In the revised version, we will include the dataset sizes (number of KAKENHI projects analyzed along with the English corpora from NSF, NIH, and UKRI), note that statistical tests (e.g., paired comparisons with significance levels) confirm the distance differences, and briefly reference the model's established cross-lingual performance on scientific text while acknowledging that domain-specific validation is an area for future work. Length controls are described in the methods via normalization and will be highlighted in the abstract. revision: yes
-
Referee: Methods/Results: the claim that smaller intra-project distances demonstrate semantic alignment is undermined by the absence of controls that isolate machine-translation effects; no comparisons against human translations, back-translations, or length- and topic-matched monolingual English baselines are described, so it remains possible that the observed reduction is driven by MT lexical or structural regularities rather than deeper equivalence.
Authors: This concern is valid and we will strengthen the manuscript accordingly. Large-scale human translations are not feasible due to resource constraints, representing a genuine limitation we will explicitly discuss. However, we will add a supplementary back-translation analysis on a sample of projects demonstrating that the intra-project closeness pattern holds. We will also incorporate length- and topic-matched English baselines by selecting comparable projects from the English-language agencies using text length bins and keyword-based topic matching, with results reported in the revised methods and results sections. revision: partial
-
Referee: Results: the low nearest-neighbor overlap (2.9/10) is presented as evidence of residual language-specific structure, yet no further analysis quantifies how this overlap varies with project topic, length, or agency, which is needed to assess whether the embeddings are practically usable for cross-lingual retrieval or clustering.
Authors: We agree that stratified analysis is necessary to evaluate practical usability. The revised results will include new tables and figures breaking down the nearest-neighbor overlap by project length (quartiles), by individual agency (NSF, NIH, UKRI), and by broad topic categories (e.g., life sciences, engineering, social sciences) derived from project metadata or content. These additions will directly address how language effects interact with these factors. revision: yes
Circularity Check
No circularity: direct empirical measurements in fixed embedding space
full rationale
The paper's central analysis consists of embedding KAKENHI Japanese texts and their machine translations into a pre-trained multilingual Sentence-BERT model, then computing average distances and nearest-neighbor overlaps against native English projects from NSF/NIH/UKRI. These are straightforward statistical observations on the resulting vectors with no fitted parameters, self-referential equations, ansatzes, or derivations that reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the reported quantities (intra-project distances, 2.9/10 neighbor overlap) are independent measurements rather than renamed fits or definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multilingual sentence embeddings capture semantic similarity across languages
- domain assumption Machine translation preserves sufficient semantic content for meaningful embedding comparison
Reference graph
Works this paper leans on
-
[1]
XOR QA : Cross-lingual Open-Retrieval Question Answering
Akari Asai et al. `` XOR QA : Cross-lingual open-retrieval question answering''. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 547--564, Online, 6 2021. Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.naacl-main.46
-
[2]
``Cross-lingual transfer or machine translation? on data augmentation for monolingual semantic textual similarity''
Sho Hoshino et al. ``Cross-lingual transfer or machine translation? on data augmentation for monolingual semantic textual similarity''. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages 4164--4173, Torino, Italia, 5 2024. ELRA and ICCL. https://aclanthology....
2024
-
[3]
Masajiro Iwasaki and Daisuke Miyazaki. ``Optimization of indexing based on k-nearest neighbor graph for proximity search in high-dimensional data''. arXiv Preprint , 10 2018. https://doi.org/10.48550/arXiv.1810.07355
-
[4]
FastText.zip: Compressing text classification models
Armand Joulin et al. ``Fasttext.zip: Compressing text classification models''. arXiv Preprint , 12 2016. https://doi.org/10.48550/arXiv.1612.03651
-
[5]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. ``Umap: Uniform manifold approximation and projection for dimension reduction''. arXiv Preprint , 2 2018. https://doi.org/10.48550/arXiv.1802.03426
work page internal anchor Pith review doi:10.48550/arxiv.1802.03426 2018
-
[6]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. ``Sentence-bert: Sentence embeddings using siamese bert-networks''. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing . Association for Computational Linguistics, 11 2019. http://arxiv.org/abs/1908.10084
work page internal anchor Pith review arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.