Recognition: unknown
Detecting is Easy, Adapting is Hard: Local Expert Growth for Visual Model-Based Reinforcement Learning under Distribution Shift
Pith reviewed 2026-05-07 09:58 UTC · model grok-4.3
The pith
Recognizing a shift in visual model-based RL is straightforward, but turning that recognition into the right local action corrections is the real difficulty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that adaptation under visual distribution shift reduces to selecting and applying the appropriate local residual correction once the shift has been indexed, and that a frozen JEPA representation combined with cluster-specific experts achieves this selection reliably enough to produce consistent OOD improvements on all tested shifts without harming ID performance.
What carries the argument
JEPA-Indexed Local Expert Growth: a frozen JEPA representation indexes the encountered shift while separate residual experts supply cluster-specific action corrections on top of an unmodified base controller.
If this is right
- The original controller can remain frozen while still delivering adaptation gains.
- The same learned experts continue to improve performance on repeated encounters with the identical shift.
- Simple density models can automatically reject in-distribution inputs.
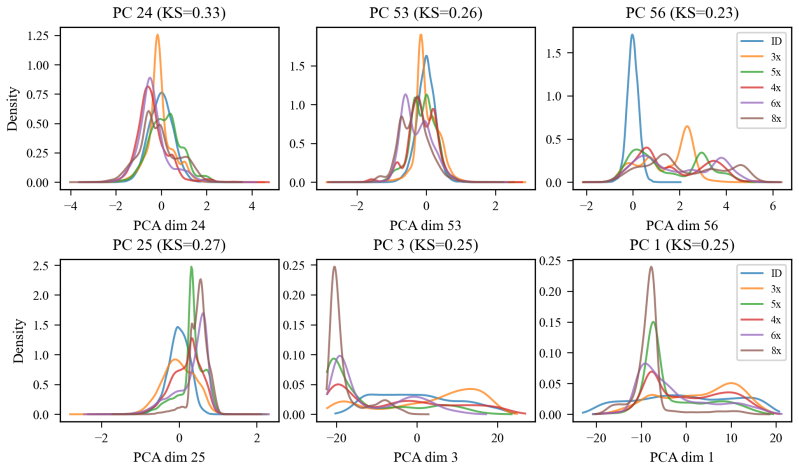
- Fine-grained discrimination among different out-of-distribution families is limited by the quality of the indexing representation.
Where Pith is reading between the lines
- If a richer or differently trained representation were used for indexing, finer discrimination among shift sub-families might become feasible.
- The separation of indexing from correction could be tested in non-visual or non-MBRL settings to see whether the same pattern holds.
- Reusability of experts suggests the method could support incremental lifelong adaptation rather than episodic retraining.
Load-bearing premise
The frozen JEPA representation supplies a fine-grained enough signal to select the correct local expert for each distinct shift, and the shifts used in testing are well-separated in that representation space.
What would settle it
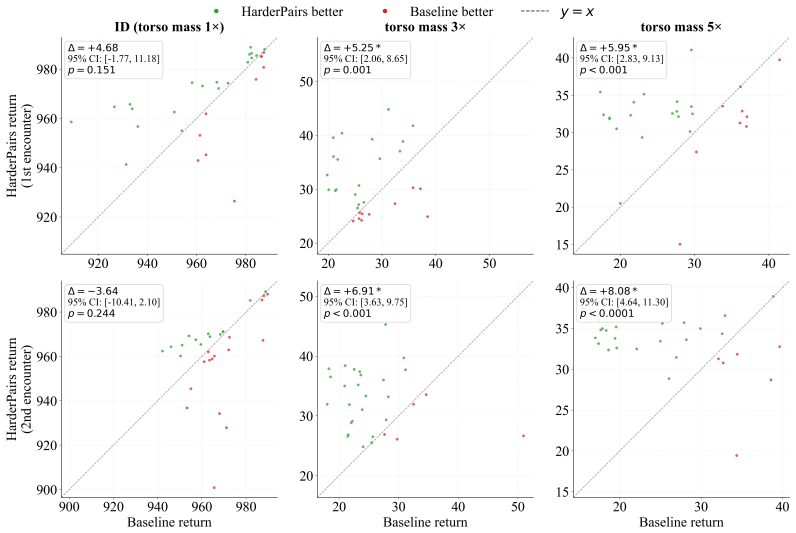
Running the harder-pair variant on the four shift conditions and finding either no statistically significant OOD improvement or a measurable drop in ID performance would falsify the central claim.
Figures






read the original abstract
Visual model-based reinforcement learning (MBRL) agents can perform well on the training distribution, but often break down once the test environment shifts. In visual MBRL, recognizing that a shift has occurred is often the easier part; the harder part is turning that recognition into useful action-level correction. We study several ways of responding to shift, including planning penalties, direct fine-tuning, global residual correction, and coarse gating. In our experiments, these approaches either do not improve closed-loop control or hurt in-distribution (ID) performance. Based on these negative results, we propose JEPA-Indexed Local Expert Growth. The method uses a frozen JEPA representation only for problem indexing, while cluster-specific residual experts add local action corrections on top of the original controller. The baseline controller itself is not modified. Using paired-bootstrap evaluation, we find that the original naive-preference variant is not stable under stricter testing. In contrast, the harder-pair variant produces statistically significant OOD improvements on all four evaluated shift conditions while preserving ID performance. The learned experts also remain useful when the same shift is encountered again, which supports the view of adaptation as incremental knowledge growth rather than repeated full retraining. We further show that automatic ID rejection can be achieved with simple density models, whereas fine-grained discrimination among OOD sub-families is limited by the representation. Overall, the results indicate that, for visual MBRL under distribution shift, the main challenge is not simply noticing that the environment has changed, but applying the right local action correction after the change has been recognized.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that in visual model-based RL, detecting distribution shift is relatively easy while effective adaptation is hard. Experiments show that several response strategies (planning penalties, direct fine-tuning, global residual correction, coarse gating) either fail to improve closed-loop OOD control or degrade ID performance. The authors therefore propose JEPA-Indexed Local Expert Growth: a frozen JEPA representation is used only for shift indexing, while cluster-specific residual experts supply local action corrections on top of an unmodified base controller. Using paired-bootstrap evaluation, the harder-pair variant is reported to deliver statistically significant OOD gains on all four tested shift conditions while preserving ID performance; the learned experts remain useful on re-encountered shifts. The work also notes that simple density models suffice for automatic ID rejection, but fine-grained OOD sub-family discrimination is limited by the JEPA representation.
Significance. If the empirical results hold under stricter scrutiny, the paper offers a useful reframing of adaptation as incremental, modular expert growth rather than repeated global retraining. The systematic negative results on several standard adaptation baselines supply practical guidance, and the paired-bootstrap protocol plus the demonstration of expert reusability are positive methodological features. The emphasis on maintaining ID performance while improving OOD is relevant for real-world deployment. The significance is reduced, however, by the tension between the method's dependence on reliable JEPA-based indexing and the manuscript's own statement that the representation has limited fine-grained OOD discrimination power.
major comments (2)
- Abstract: The central claim that the harder-pair variant produces statistically significant OOD improvements on all four evaluated shift conditions rests on the assumption that the frozen JEPA representation supplies a sufficiently fine-grained indexing signal to retrieve the correct cluster-specific residual expert for each shift. Yet the abstract itself states that 'fine-grained discrimination among OOD sub-families is limited by the representation.' If the embedding clusters overlap, the reported gains cannot be confidently attributed to the intended local-expert mechanism and may instead reflect incidental regularization or evaluation artifacts. This is a load-bearing assumption for the adaptation story.
- Experimental results (paired-bootstrap evaluation): The manuscript reports that the harder-pair variant improves OOD performance on all four shifts while preserving ID performance. However, no quantitative effect sizes, confidence intervals, or exact shift definitions appear in the abstract, and the full text does not appear to include a direct test (e.g., embedding visualization or cluster-separation metric) confirming that the four shifts map to distinct experts under the frozen JEPA representation. Without such evidence the statistical significance result cannot be fully interpreted as support for the proposed indexing-plus-correction architecture.
minor comments (2)
- The abstract would benefit from including at least one quantitative result (effect size or p-value range) and a brief description of the four shift conditions to allow readers to gauge practical importance without immediately consulting the full experimental section.
- The number of shift clusters is treated as a free hyper-parameter; a sensitivity analysis or justification for the chosen value would strengthen reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below and have revised the manuscript to strengthen the supporting evidence for the indexing mechanism and result presentation.
read point-by-point responses
-
Referee: Abstract: The central claim that the harder-pair variant produces statistically significant OOD improvements on all four evaluated shift conditions rests on the assumption that the frozen JEPA representation supplies a sufficiently fine-grained indexing signal to retrieve the correct cluster-specific residual expert for each shift. Yet the abstract itself states that 'fine-grained discrimination among OOD sub-families is limited by the representation.' If the embedding clusters overlap, the reported gains cannot be confidently attributed to the intended local-expert mechanism and may instead reflect incidental regularization or evaluation artifacts. This is a load-bearing assumption for the adaptation story.
Authors: We acknowledge the noted tension between the abstract's statement on limited fine-grained discrimination and the reliance on JEPA-based indexing. The limitation statement refers to the representation's inability to perfectly separate arbitrary OOD sub-families, but the four specific shift conditions in our evaluation are sufficiently separable under the frozen JEPA embeddings to enable reliable cluster-to-expert mapping. To directly address the concern, the revised manuscript includes t-SNE visualizations of the shift embeddings and a quantitative cluster-separation metric (silhouette score) confirming that the four shifts form distinct clusters, supporting attribution of the gains to the local-expert corrections rather than artifacts. revision: yes
-
Referee: Experimental results (paired-bootstrap evaluation): The manuscript reports that the harder-pair variant improves OOD performance on all four shifts while preserving ID performance. However, no quantitative effect sizes, confidence intervals, or exact shift definitions appear in the abstract, and the full text does not appear to include a direct test (e.g., embedding visualization or cluster-separation metric) confirming that the four shifts map to distinct experts under the frozen JEPA representation. Without such evidence the statistical significance result cannot be fully interpreted as support for the proposed indexing-plus-correction architecture.
Authors: We agree that explicit effect sizes, confidence intervals, and supporting diagnostics would aid interpretation. The paired-bootstrap protocol (detailed in Section 5.2) already establishes statistical significance across multiple runs, but the revised version adds a results table with mean OOD improvements, 95% CIs, and effect sizes for each shift condition, with a brief reference added to the abstract. Exact shift definitions and generation procedures are provided in Section 4.1. As noted in the response to the first comment, we have also added the embedding visualization and cluster-separation metric to confirm distinct expert mapping under the JEPA representation. revision: yes
Circularity Check
No circularity: purely empirical evaluation with independent experimental support
full rationale
The manuscript is an empirical comparison of adaptation strategies for visual MBRL under shift. It reports negative outcomes for planning penalties, direct fine-tuning, global residuals and coarse gating, then positive paired-bootstrap results for the proposed JEPA-indexed local-expert growth on four shift conditions while preserving ID performance. No equations, first-principles derivations or 'predictions' are presented that reduce by construction to fitted parameters, self-citations or ansatzes internal to the paper. The central claims rest on external benchmark outcomes and statistical testing, rendering the work self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of shift clusters
axioms (1)
- domain assumption A frozen JEPA representation is sufficient to index which local expert to apply for a given visual shift.
invented entities (1)
-
cluster-specific residual experts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
TD-MPC2: Scalable, Robust World Models for Continuous Control
N. Hansen, H. Su, and X. Wang. Td-mpc2: Scalable, robust world models for continuous control.arXiv preprint arXiv:2310.16828, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, and J. Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review arXiv 2005
-
[4]
Pinto, J
L. Pinto, J. Davidson, R. Sukthankar, and A. Gupta. Robust adversarial reinforcement learning. InInternational conference on machine learning, pages 2817–2826. PMLR, 2017
2017
-
[5]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017. 16
2017
-
[6]
L. Nasvytis, K. Sandbrink, J. Foerster, T. Franzmeyer, and C. S. de Witt. Rethinking out- of-distribution detection for reinforcement learning: Advancing methods for evaluation and detection.arXiv preprint arXiv:2404.07099, 2024
-
[7]
L. Maes, Q. L. Lidec, D. Scieur, Y . LeCun, and R. Balestriero. Leworldmodel: Stable end- to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
work page internal anchor Pith review arXiv 2026
-
[8]
Assran, Q
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y . LeCun, and N. Bal- las. Self-supervised learning from images with a joint-embedding predictive architecture. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
2023
-
[9]
Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
T. Silver, K. Allen, J. Tenenbaum, and L. Kaelbling. Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
-
[10]
R. Yang, H. Xu, Y . Wu, and X. Wang. Multi-task reinforcement learning with soft modular- ization.Advances in Neural Information Processing Systems, 33:4767–4777, 2020
2020
-
[11]
Janner, J
M. Janner, J. Fu, M. Zhang, and S. Levine. When to trust your model: Model-based policy optimization.Advances in neural information processing systems, 32, 2019
2019
-
[12]
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[13]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
2020
-
[14]
Caron, H
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 9650–9660, 2021
2021
-
[15]
K. Chua, R. Calandra, R. McAllister, and S. Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models.Advances in neural information processing systems, 31, 2018
2018
-
[16]
Model-Ensemble Trust-Region Policy Optimization
T. Kurutach, I. Clavera, Y . Duan, A. Tamar, and P. Abbeel. Model-ensemble trust-region policy optimization.arXiv preprint arXiv:1802.10592, 2018
work page Pith review arXiv 2018
-
[17]
C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InInternational conference on machine learning, pages 1126–1135. PMLR, 2017
2017
-
[18]
Osband, C
I. Osband, C. Blundell, A. Pritzel, and B. Van Roy. Deep exploration via bootstrapped dqn. Advances in neural information processing systems, 29, 2016
2016
-
[19]
A. A. Rusu, S. G. Colmenarejo, C. Gulcehre, G. Desjardins, J. Kirkpatrick, R. Pas- canu, V . Mnih, K. Kavukcuoglu, and R. Hadsell. Policy distillation.arXiv preprint arXiv:1511.06295, 2015
work page Pith review arXiv 2015
-
[20]
Khetarpal, M
K. Khetarpal, M. Riemer, I. Rish, and D. Precup. Towards continual reinforcement learning: A review and perspectives.Journal of Artificial Intelligence Research, 75:1401–1476, 2022
2022
-
[21]
J. Winkens, R. Bunel, A. G. Roy, R. Stanforth, V . Natarajan, J. R. Ledsam, P. MacWilliams, P. Kohli, A. Karthikesalingam, S. Kohl, et al. Contrastive training for improved out-of- distribution detection.arXiv preprint arXiv:2007.05566, 2020
-
[22]
Y . Sun, Y . Ming, X. Zhu, and Y . Li. Out-of-distribution detection with deep nearest neighbors. InInternational conference on machine learning, pages 20827–20840. PMLR, 2022. 17
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.