Recognition: unknown
Energy efficiency of a GPU-based computing system for High Energy Physics experiments
Pith reviewed 2026-05-07 08:40 UTC · model grok-4.3
The pith
A method computes energy efficiency of GPU systems for the LHCb experiment's HLT1 trigger by linking throughput to hardware specifications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
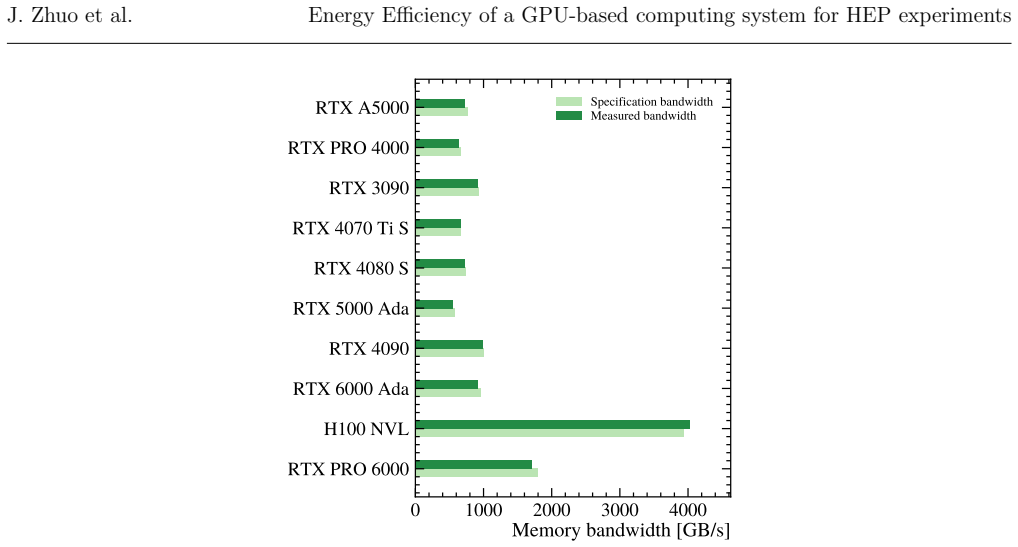
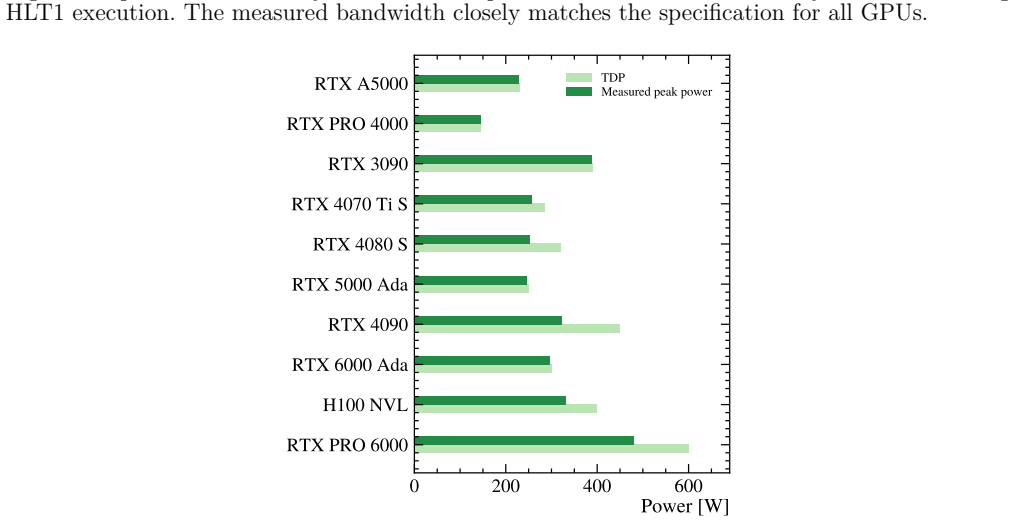
The central claim is that energy efficiency for the LHCb HLT1 can be computed from a relation between throughput and GPU specifications including the number of cores, clock frequency, memory bandwidth, and thermal design power. This provides a metric to evaluate both hardware platforms and optimizations, supporting decisions toward sustainable computing ecosystems in High Energy Physics.
What carries the argument
The energy efficiency model that relates throughput to GPU specifications including cores, clock frequency, memory bandwidth, and thermal design power.
If this is right
- Different GPU platforms can be compared based on their energy efficiency for trigger processing.
- Algorithm optimizations can be evaluated not just by speed but by energy consumption per event.
- Decisions on hardware procurement for future HEP experiments can incorporate energy sustainability metrics.
- The approach supports building more environmentally responsible computing infrastructures in particle physics.
Where Pith is reading between the lines
- Applying this model to non-HEP GPU workloads could reveal similar efficiency patterns in other scientific computing domains.
- Future refinements might include additional factors like cooling overhead or data transfer costs to improve accuracy.
- If validated broadly, the metric could influence design priorities for large-scale physics computing facilities.
Load-bearing premise
The assumption that the throughput-to-hardware-specification relation derived for the LHCb HLT1 will apply to other HEP experiments and different hardware without needing significant adjustments or additional constraints.
What would settle it
Measuring the actual energy consumption and throughput of a different GPU in another HEP experiment, such as a trigger system in CMS or ATLAS, and finding that the predicted efficiency from the model deviates substantially from the measured value without model modifications.
Figures





read the original abstract
In this paper we introduce the energy efficiency as a new metric for evaluating both hardware platforms based on Graphic Processor Units (GPU), and algorithm optimisations at High Energy Physics (HEP) experiments. We develop a method to compute the energy efficiency for the case of the first high level trigger (HLT1) of the LHCb experiment, relating the throughput with GPU specifications such as the number of cores, clock frequency, memory bandwidth and thermal design power. The model can be extended to other HEP experiments to make decisions and reach sustainable computing ecosystems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces energy efficiency as a new metric for evaluating GPU platforms and algorithm optimizations in High Energy Physics experiments. It develops a method to compute this metric for the LHCb HLT1 trigger by relating measured throughput to GPU hardware specifications (number of cores, clock frequency, memory bandwidth, and thermal design power). The authors claim the resulting model can be extended to other HEP experiments to support decisions toward sustainable computing ecosystems.
Significance. If the relation between throughput and hardware parameters proves robust and generalizable beyond the LHCb implementation, the metric could aid hardware selection and optimization in energy-intensive HEP computing, addressing sustainability concerns for future trigger systems. The work correctly identifies the need for such metrics but requires stronger evidence to realize this potential.
major comments (2)
- [§3] §3 (Method): The functional relation linking throughput to GPU specifications (cores, frequency, memory bandwidth, TDP) is introduced without an explicit equation, derivation steps, or fitting procedure. This prevents assessment of whether the form is driven by universal hardware constraints or by LHCb HLT1-specific bottlenecks such as tracking and selection kernels.
- [§4–5] §4–5 (Results and Extension): No cross-validation or test on a different HEP trigger algorithm (e.g., calorimeter clustering or alternative track-finding) is presented to support the claim that the same relation generalizes without re-fitting. The results are confined to the LHCb HLT1 case, leaving the weakest assumption untested.
minor comments (2)
- [Abstract] Abstract: The statement that the model 'can be extended' lacks any mention of scope, required re-calibration, or limitations, which should be clarified for readers.
- [§2] Notation: The definitions of energy efficiency and the throughput relation should be stated with consistent symbols and units in the main text to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the major comments point by point below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method): The functional relation linking throughput to GPU specifications (cores, frequency, memory bandwidth, TDP) is introduced without an explicit equation, derivation steps, or fitting procedure. This prevents assessment of whether the form is driven by universal hardware constraints or by LHCb HLT1-specific bottlenecks such as tracking and selection kernels.
Authors: We agree with the referee that the functional relation should be presented more explicitly. The relation was developed empirically from hardware specifications and measured throughput for the LHCb HLT1, but we will revise the manuscript to include the explicit equation, the derivation based on core count, frequency, bandwidth, and TDP, and the fitting method. This will help clarify the extent to which it reflects universal GPU constraints versus the specific kernels in HLT1. revision: yes
-
Referee: [§4–5] §4–5 (Results and Extension): No cross-validation or test on a different HEP trigger algorithm (e.g., calorimeter clustering or alternative track-finding) is presented to support the claim that the same relation generalizes without re-fitting. The results are confined to the LHCb HLT1 case, leaving the weakest assumption untested.
Authors: We acknowledge that the generalization to other HEP experiments is an assumption that has not been tested with cross-validation on different algorithms. Our study is focused on the LHCb HLT1 as a detailed case, and performing such tests would require additional benchmarking efforts not included in this work. We have revised §5 to temper the claims about extendability and to suggest how the model might be adapted for other systems, while noting the need for future validation. revision: partial
- Lack of cross-validation on alternative HEP trigger algorithms, as no such data or tests were performed in the current study.
Circularity Check
No circularity; derivation not shown and cannot reduce to inputs
full rationale
The abstract states that a method is developed to relate measured throughput of the LHCb HLT1 trigger to GPU hardware parameters (cores, frequency, bandwidth, TDP) in order to define energy efficiency, with the claim that the model can be extended to other HEP experiments. No equations, functional forms, fitting procedures, or self-citations are exhibited in the provided text. Without any derivation chain or explicit reduction (e.g., a throughput formula fitted to LHCb data then re-used as a prediction), no step can be shown to be self-definitional, a fitted input renamed as prediction, or dependent on a load-bearing self-citation. The derivation is therefore self-contained against external benchmarks in the sense that its internal logic cannot be inspected for circularity from the given material.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address annote author booktitle chapter doi edition editor eid howpublished institution journal key language month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := ...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter doi edition editor eid howpublished institution journal key language month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid...
-
[4]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in "" FUNCTION format.date year ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.