Recognition: unknown
Efficient Incremental #SAT via Cross-Instance Knowledge Reuse
Pith reviewed 2026-05-09 18:22 UTC · model grok-4.3
The pith
A persistent cache of component data lets incremental #SAT solvers reuse work across similar formula sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In sequences of structurally similar formulas, retaining component data in a persistent cache across #SAT solver calls amortizes the computation by preventing redundant exploration of the search space, and adapted branching heuristics further improve efficiency in this setting.
What carries the argument
Persistent caching mechanism that retains component data across solver calls to avoid redundant search.
If this is right
- Performance improves on incremental instances from argumentation and soft core problems.
- Adapted branching heuristics enhance the effectiveness of the cache in dynamic settings.
- Structure-aware reuse proves useful for model counting in changing environments.
- Amortization reduces overall computation time for sequences of similar #SAT problems.
Where Pith is reading between the lines
- Similar caching could apply to other incremental constraint problems beyond #SAT.
- May enable real-time updates in probabilistic reasoning systems that rely on model counts.
- Could reduce resource use in applications with evolving knowledge bases.
Load-bearing premise
The input formulas must be structurally similar enough that cached component data stays valid and useful with low overhead from cache maintenance and infrequent invalidations.
What would settle it
Running the method on sequences of formulas with low structural similarity and observing no speedup or even slowdown compared to standard non-incremental model counters.
Figures
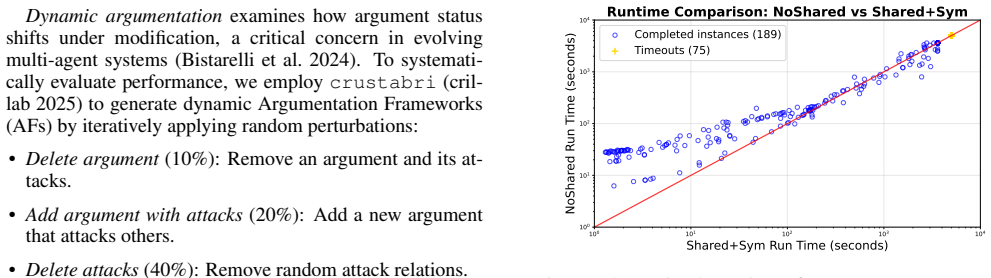


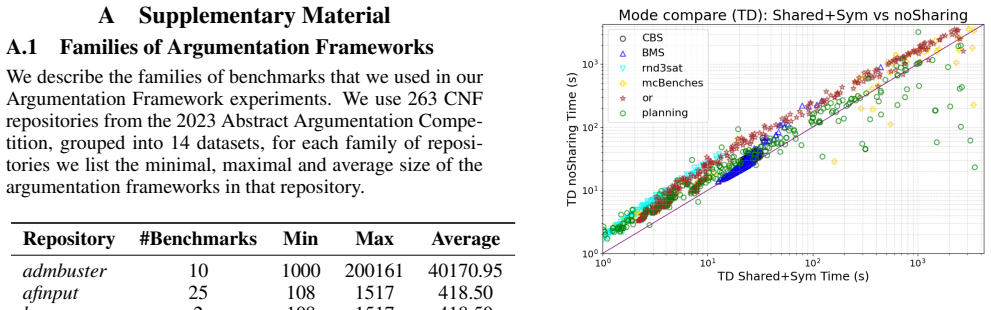
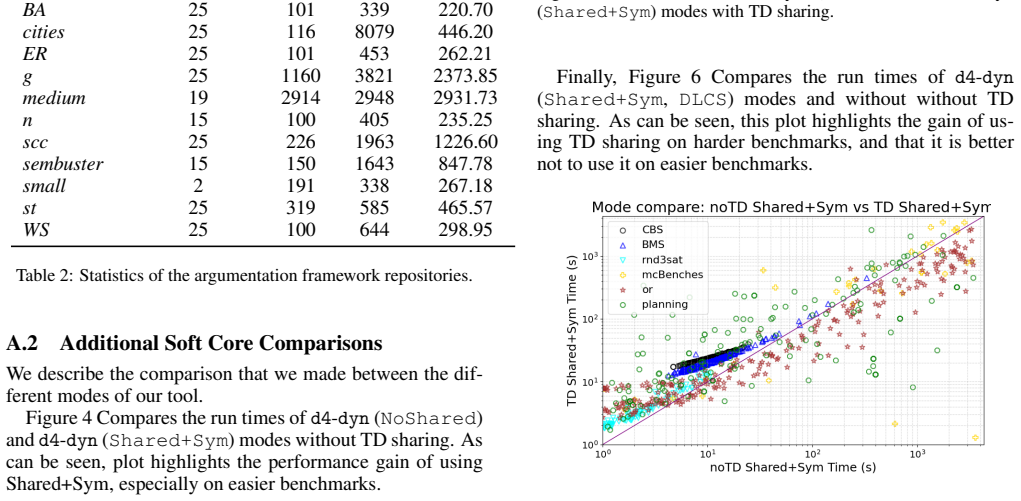
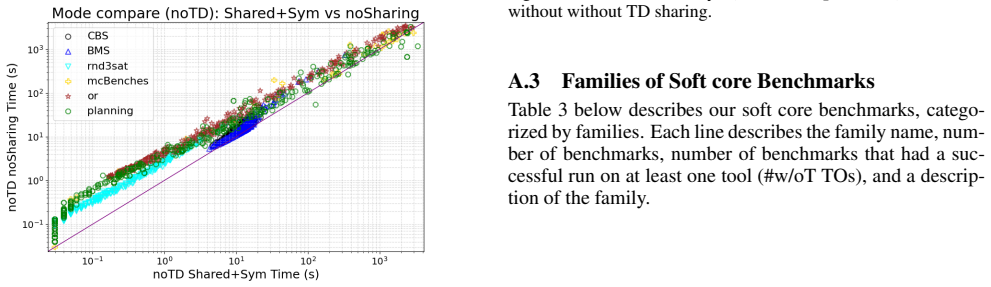
read the original abstract
Model counting ($\#\text{SAT}$) is a fundamental yet $\#\text{P}$-complete problem central to probabilistic reasoning. In this work, we address \textit{incremental model counting}, where sequences of structurally similar formulas must be counted. We propose an approach that amortizes computation via a persistent caching mechanism, retaining component data across solver calls to avoid redundant search. Additionally, we investigate branching heuristics adapted for this setting. We focus on the problems of argumentation and soft core, for which incremental model counting is natural. Experiments demonstrate that our method improves performance compared to current model counters, highlighting the capability of structure-aware reuse in dynamic environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to advance incremental #SAT by amortizing computation across sequences of structurally similar formulas through a persistent caching mechanism that retains component data between solver calls, combined with adapted branching heuristics. It targets applications in argumentation frameworks and soft-core constraints, reporting experimental performance gains over existing model counters.
Significance. If the caching is both sound and effective with low overhead, the work could meaningfully improve scalability for dynamic #SAT instances in probabilistic reasoning, where incremental updates are common. The emphasis on cross-instance reuse and structure-aware methods addresses a practical gap, though its impact hinges on the frequency of reusable components in real workloads.
major comments (2)
- [Abstract and approach section] The soundness and efficiency of the persistent caching mechanism are load-bearing for the central claim, yet the manuscript provides no description of component identification, change detection between formulas, or the invalidation policy (see Abstract and the approach description). If updates in argumentation or soft-core instances frequently alter clauses or dependencies, retained data risks becoming invalid or the maintenance overhead could erase reported gains.
- [Experiments] Table or experimental results section: the reported improvements lack details on experimental setup, choice of baselines, statistical significance testing, or controls for confounds such as cache size and invalidation frequency, leaving the data support for the performance claims only partially verifiable.
minor comments (1)
- Clarify assumptions about formula similarity and any formal guarantees on when cached components remain valid.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating planned revisions where appropriate to strengthen the description of our persistent caching approach and the supporting experimental evidence.
read point-by-point responses
-
Referee: [Abstract and approach section] The soundness and efficiency of the persistent caching mechanism are load-bearing for the central claim, yet the manuscript provides no description of component identification, change detection between formulas, or the invalidation policy (see Abstract and the approach description). If updates in argumentation or soft-core instances frequently alter clauses or dependencies, retained data risks becoming invalid or the maintenance overhead could erase reported gains.
Authors: We agree that the soundness of the persistent caching mechanism requires explicit treatment of component identification, change detection, and invalidation. The current manuscript presents the high-level idea of retaining component data across calls but does not detail the mechanisms for detecting reusable components, identifying formula changes, or safely invalidating stale entries. In the revised manuscript we will add a dedicated subsection to the approach description that specifies these policies, including the criteria used to identify components, the detection of clause or dependency changes between consecutive formulas, and the invalidation rules applied to preserve correctness. We will also include a brief overhead analysis tailored to the argumentation and soft-core benchmarks, where structural similarity is expected to keep maintenance costs modest relative to the reported gains. revision: yes
-
Referee: [Experiments] Table or experimental results section: the reported improvements lack details on experimental setup, choice of baselines, statistical significance testing, or controls for confounds such as cache size and invalidation frequency, leaving the data support for the performance claims only partially verifiable.
Authors: We acknowledge that the experimental section would be strengthened by additional details on setup, baselines, statistical methods, and controls for potential confounds. The original presentation reports comparative performance but omits a full account of the hardware environment, precise benchmark selection criteria, baseline justifications, and any statistical testing. In the revision we will expand the experimental section to include these elements: a complete description of the evaluation platform and instance sets; explicit rationale for the chosen model counters; reporting of statistical significance where applicable; and supplementary experiments or analysis that vary cache size and invalidation frequency to demonstrate robustness of the observed improvements. revision: yes
Circularity Check
No circularity: algorithmic caching proposal rests on external experiments, not self-referential definitions or fitted inputs
full rationale
The paper presents an incremental #SAT algorithm that caches component data across similar instances and adapts branching heuristics, with performance claims supported by experiments on argumentation and soft-core instances. No equations, uniqueness theorems, or first-principles derivations are invoked that reduce to the method's own inputs by construction. No self-citations appear as load-bearing premises, no parameters are fitted then renamed as predictions, and no ansatz or renaming of known results is used to justify the core approach. The central amortization claim is an engineering extension whose validity is tested externally rather than derived tautologically from the caching mechanism itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Johannes Klaus Fichte and Markus Hecher and Florim Hamiti , title =
-
[2]
Proceedings of the 21st International Conference on Principles of Knowledge Representation and Reasoning,
Jean. Proceedings of the 21st International Conference on Principles of Knowledge Representation and Reasoning,
-
[3]
The Thirty-Third Conference on Artificial Intelligence,
Jean. The Thirty-Third Conference on Artificial Intelligence,
-
[4]
Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems,
Jean. Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems,
-
[5]
Proceedings of 10th International Conference on Formal Methods in Computer-Aided Design,
Alexander Nadel , title =. Proceedings of 10th International Conference on Formal Methods in Computer-Aided Design,
-
[6]
Littman and Judy Goldsmith and Martin Mundhenk , title =
Michael L. Littman and Judy Goldsmith and Martin Mundhenk , title =. J. Artif. Intell. Res. , volume =
-
[7]
Theory and Applications of Satisfiability Testing,
Alexander Nadel and Vadim Ryvchin , title =. Theory and Applications of Satisfiability Testing,
-
[8]
Meel , editor =
Suwei Yang and Yong Lai and Kuldeep S. Meel , editor =. On Top-Down Pseudo-Boolean Model Counting , booktitle =
-
[9]
Meel , editor =
Mate Soos and Kuldeep S. Meel , editor =. Engineering an Efficient Probabilistic Exact Model Counter , booktitle =
-
[10]
Checking the acceptability of a set of arguments , booktitle =
Philippe Besnard and Sylvie Doutre , editor =. Checking the acceptability of a set of arguments , booktitle =
-
[11]
Adnan Darwiche and Judea Pearl , title =. Artif. Intell. , volume =. 1997 , url =. doi:10.1016/S0004-3702(96)00038-0 , timestamp =
-
[12]
Computational Models of Argument,
Nicol. Computational Models of Argument,
-
[13]
Proceedings of the 23rd International Joint Conference on Artificial Intelligence,
Fr. Proceedings of the 23rd International Joint Conference on Artificial Intelligence,
-
[14]
Muise and Sheila A
Christian J. Muise and Sheila A. McIlraith and J. Christopher Beck and Eric I. Hsu , title =. Advances in Artificial Intelligence - 25th Canadian Conference on Artificial Intelligence,
-
[15]
Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence,
Umut Oztok and Adnan Darwiche , title =. Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence,
-
[16]
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence,
Jean. Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence,
-
[17]
Proceedings of the 16th Eureopean Conference on Artificial Intelligence,
Adnan Darwiche , title =. Proceedings of the 16th Eureopean Conference on Artificial Intelligence,
-
[18]
Meel , title =
Shubham Sharma and Subhajit Roy and Mate Soos and Kuldeep S. Meel , title =. Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence,
-
[19]
27th International Conference on Principles and Practice of Constraint Programming,
Tuukka Korhonen and Matti J. 27th International Conference on Principles and Practice of Constraint Programming,
-
[20]
Theory and Applications of Satisfiability Testing,
Marc Thurley , title =. Theory and Applications of Satisfiability Testing,
-
[21]
Kautz and Toniann Pitassi , title =
Tian Sang and Fahiem Bacchus and Paul Beame and Henry A. Kautz and Toniann Pitassi , title =. The Seventh International Conference on Theory and Applications of Satisfiability Testing,
-
[22]
PP is as Hard as the Polynomial-Time Hierarchy
Seinosuke Toda , title =. 1991 , url =. doi:10.1137/0220053 , timestamp =
-
[23]
Chico Sundermann and Heiko Raab and Tobias He
-
[24]
Argument & Computation , pages =
Stefano Bistarelli and Lars Kotthoff and Jean-Marie Lagniez and Emmanuel Lonca and Jean-Guy Mailly and Julien Rossit and Francesco Santini and Carlo Taticchi , title =. Argument & Computation , pages =
-
[25]
Proceedings of the 13th International Joint Conference on Artificial Intelligence
Phan Minh Dung , title =. Proceedings of the 13th International Joint Conference on Artificial Intelligence. , pages =
-
[26]
Algorithms for computing minimal equivalent subformulas , journal =
Anton Belov and Mikol. Algorithms for computing minimal equivalent subformulas , journal =. 2014 , url =. doi:10.1016/J.ARTINT.2014.07.011 , timestamp =
-
[27]
Proceedings of the 14th International Conference on Agents and Artificial Intelligence,
Gilles Audemard and Jean. Proceedings of the 14th International Conference on Agents and Artificial Intelligence,
-
[28]
Renato Bruni and Antonio Sassano , title =. Electron. Notes Discret. Math. , volume =. 2001 , url =. doi:10.1016/S1571-0653(04)00320-8 , timestamp =
-
[29]
Johannes Klaus Fichte and Markus Hecher , title =. CoRR , volume =. 2025 , url =. 2504.13842 , timestamp =
-
[30]
Corneil and Andrzej Proskurowski , title =
Stefan Anborg and Derek G. Corneil and Andrzej Proskurowski , title =. SIAM Journal on Matrix Analysis and Applications , year =
-
[31]
Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence,
Jean. Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence,
-
[32]
Valiant , title =
Leslie G. Valiant , title =
-
[33]
Proceedings of the Fifteenth International Conference on Automated Planning and Scheduling,
H. Proceedings of the Fifteenth International Conference on Automated Planning and Scheduling,
-
[34]
Proceedings of the Sixteenth International Conference on Automated Planning and Scheduling,
Carmel Domshlak and J. Proceedings of the Sixteenth International Conference on Automated Planning and Scheduling,
-
[35]
Cooper and Jo
Yacine Izza and Xuanxiang Huang and Alexey Ignatiev and Nina Narodytska and Martin C. Cooper and Jo. Int. J. Approx. Reason. , year =
-
[36]
Gomes and Ashish Sabharwal and Bart Selman , title =
Carla P. Gomes and Ashish Sabharwal and Bart Selman , title =. Handbook of Satisfiability - Second Edition , volume =
-
[37]
Kautz , editor =
Tian Sang and Paul Beame and Henry A. Kautz , editor =. Heuristics for Fast Exact Model Counting , booktitle =
-
[38]
Bodlaender , editor =
Hans L. Bodlaender , editor =. Discovering Treewidth , booktitle =
-
[39]
Seymour , title =
Neil Robertson and Paul D. Seymour , title =. J. Algorithms , volume =
-
[40]
Moskewicz and Conor F
Matthew W. Moskewicz and Conor F. Madigan and Ying Zhao and Lintao Zhang and Sharad Malik , title =. Proceedings of the 38th Design Automation Conference,
-
[41]
Jeroslow and Jinchang Wang , title =
Robert G. Jeroslow and Jinchang Wang , title =. Ann. Math. Artif. Intell. , volume =
-
[42]
Cliques, Coloring, and Satisfiability, Proceedings of a
Olivier Dubois and Pascal Andr. Cliques, Coloring, and Satisfiability, Proceedings of a
-
[43]
, title =
Turing, Alan M. , title =. Mind , volume =
-
[44]
Nature , volume =
Learning Representations by Back-Propagating Errors , author =. Nature , volume =
-
[45]
Proceedings of the 10th European Conference on Artificial Intelligence (ECAI) , pages =
Planning as Satisfiability , author =. Proceedings of the 10th European Conference on Artificial Intelligence (ECAI) , pages =
-
[46]
Artificial Intelligence , volume =
Collaborative Plans for Complex Group Action , author =. Artificial Intelligence , volume =
-
[47]
The Entropy Formula for the
Grisha Perelman , howpublished =. The Entropy Formula for the
-
[48]
Causality , author =
-
[49]
Korhonen, Tuukka and J\". 27th International Conference on Principles and Practice of Constraint Programming (CP 2021) , pages =. 2021 , volume =. doi:10.4230/LIPIcs.CP.2021.8 , annote =
-
[50]
Thurley, Marc , booktitle=
-
[51]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Towards Projected and Incremental Pseudo-Boolean Model Counting , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i11.33240 , number=
-
[52]
Algebraic Decision Diagrams and Their Application , journal =
Bahar, R.Iris and Frohm, Erica and Gaona, Charles and Hachtel, Gary and Macii, Enrico and Pardo, Abelardo and Somenzi, Fabio , year =. Algebraic Decision Diagrams and Their Application , journal =
-
[53]
New Compilation Languages Based on Restricted Weak Decomposability , volume=
Illner, Petr , year=. New Compilation Languages Based on Restricted Weak Decomposability , volume=. doi:10.1609/aaai.v39i14.33643 , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.