Recognition: no theorem link
From Euler to Dormand-Prince: ODE Solvers for Flow Matching Generative Models
Pith reviewed 2026-05-13 18:14 UTC · model grok-4.3
The pith
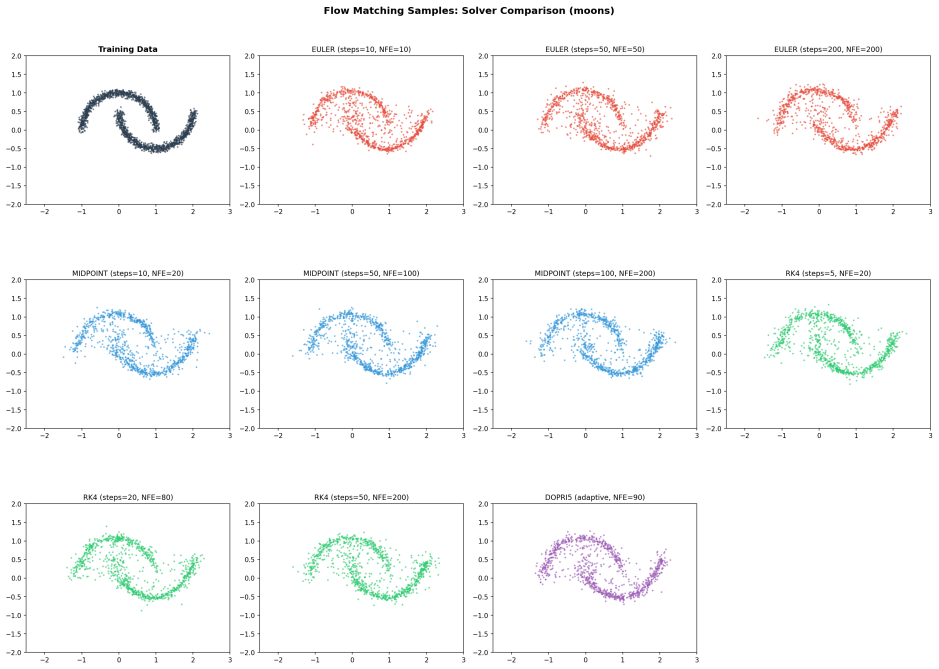
RK4 achieves comparable sample quality to Euler using only 80 function evaluations instead of 200 on flow matching tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By deriving Euler, explicit midpoint, classical Runge-Kutta (RK4), and Dormand-Prince 5(4) methods from first principles and applying them to the learned velocity field, the authors show that RK4 at 80 function evaluations achieves sample quality comparable to Euler at 200 on Conditional Flow Matching tasks measured by sliced Wasserstein distance.
What carries the argument
Classical Runge-Kutta ODE integrators applied directly to the neural velocity field of the flow-matching probability ODE.
If this is right
- Higher-order solvers reduce the dominant cost of sampling, which is the number of neural network forward passes.
- The performance gap between low-order and high-order solvers grows as model capacity or training quality decreases.
- Adaptive step-size methods automatically allocate more evaluations where the velocity field's Jacobian eigenvalues become large near t=1.
- Re-deriving the solvers from Taylor series makes the truncation-order assumptions explicit and controllable in code.
Where Pith is reading between the lines
- Standard flow-matching libraries could adopt RK4 or Dormand-Prince as default samplers to cut inference cost by roughly half on typical tasks.
- The observed stiffness near t=1 suggests that step-size schedules learned jointly with the velocity field might yield further gains.
- The same classical solvers are likely to produce similar efficiency improvements in other neural-ODE generative frameworks that rely on smooth velocity fields.
Load-bearing premise
The learned velocity field is smooth enough that the Taylor-derived local error bounds of the classical solvers remain valid without extra regularization near the final time.
What would settle it
On a new conditional flow matching task, if sliced Wasserstein distance for RK4 samples generated with 80 evaluations exceeds the distance for Euler samples generated with 200 evaluations, the efficiency claim is falsified.
Figures












read the original abstract
Sampling from Flow Matching generative models requires solving an ordinary differential equation (ODE) whose computational cost is dominated by neural network forward passes. We derive four classical ODE solvers -- Euler, Explicit Midpoint, Classical Runge-Kutta (RK4), and Dormand-Prince 5(4) -- from first principles via Taylor expansion, implement them from scratch in PyTorch, and systematically benchmark their efficiency on Conditional Flow Matching tasks ranging from 2D toy distributions to MNIST digits. On the quantitative side, we use sliced Wasserstein distance to construct NFE-quality Pareto frontiers,finding that RK4 at 80 function evaluations achieves sample quality comparable to Euler at 200. Beyond reproducing known convergence rates, we report two empirical observations: (1) the Jacobian eigenvalue spectrum of the learned velocity field stiffens sharply near t=1, explaining why the adaptive Dormand-Prince solver automatically concentrates its step budget at the end of the trajectory; (2) the quality gap between low-order and high-order solvers widens for undertrained and smaller models, indicating that solver choice matters most when the model is imperfect. Code and all experiment scripts are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives the Euler, Explicit Midpoint, RK4, and Dormand-Prince ODE solvers from Taylor expansions, implements them from scratch in PyTorch, and benchmarks their sampling efficiency on Conditional Flow Matching tasks ranging from 2D toys to MNIST. Using sliced Wasserstein distance, it reports that RK4 at 80 function evaluations achieves sample quality comparable to Euler at 200 evaluations, reproduces classical convergence rates, and observes that the learned velocity field's Jacobian stiffens sharply near t=1 while quality gaps between solvers widen for undertrained models. Full code and experiment scripts are released.
Significance. If the empirical findings hold, the work supplies concrete, reproducible guidance on selecting ODE solvers to lower the dominant cost (neural-network evaluations) in flow-matching sampling while preserving quality. The direct measurement of Pareto frontiers, the reproduction of known rates, the public code release, and the additional observations on Jacobian behavior and model-dependence constitute a solid, practical contribution to generative modeling.
minor comments (3)
- The Dormand-Prince solver introduction would be strengthened by citing the original reference (Dormand and Prince, 1980) alongside the Taylor derivation.
- A plot of the Jacobian eigenvalue spectrum versus t would make the reported stiffening observation more concrete and directly verifiable.
- The definition of 'undertrained' models should be stated explicitly (e.g., fraction of total training steps or epochs) in the main text or a table caption.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the practical contribution, and recommendation for minor revision. No major comments were raised in the report, so we interpret this as an invitation to proceed with publication after any editorial polishing.
Circularity Check
No significant circularity
full rationale
The paper derives the four ODE solvers (Euler, Midpoint, RK4, Dormand-Prince) directly from Taylor expansions presented as first-principles derivations with no dependence on prior results from the same authors. The central empirical claim—that RK4 at 80 NFEs matches Euler at 200 NFEs in sliced Wasserstein distance—is obtained by direct measurement on trained velocity fields and plotted as Pareto frontiers; no parameters are fitted to a subset and then relabeled as predictions, and no self-citation chain is invoked to justify uniqueness or force the result. The reported observations on Jacobian stiffening and model-size effects are likewise post-hoc measurements rather than premises required for the efficiency comparison.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Taylor expansion with remainder applies to the velocity field along solution trajectories
Reference graph
Works this paper leans on
-
[1]
M. S. Albergo and E. Vanden-Eijnden. Building normalizing flows with stochastic interpolants. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[2]
J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
J. C. Butcher.Numerical Methods for Ordinary Differential Equations. John Wiley & Sons, 3rd edition, 2016
work page 2016
-
[4]
R. T. Q. Chen, Y . Rubanova, J. Bettencourt, and D. Duvenaud. Neural ordinary differential equations. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
work page 2018
-
[5]
J. R. Dormand and P. J. Prince. A family of embedded Runge–Kutta formulae.Journal of Computa- tional and Applied Mathematics, 6(1):19–26, 1980
work page 1980
-
[6]
S. Elfwing, E. Uchibe, and K. Doya. Sigmoid-weighted linear units for neural network function ap- proximation in reinforcement learning.Neural Networks, 107:3–11, 2018. 10
work page 2018
- [7]
-
[8]
W. Grathwohl, R. T. Q. Chen, J. Bettencourt, M. Finzi, and D. Duvenaud. FFJORD: Free-form con- tinuous dynamics for scalable reversible generative models. InInternational Conference on Learning Representations (ICLR), 2019
work page 2019
- [9]
-
[10]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
- [11]
-
[12]
P. Kidger, R. T. Q. Chen, and T. Lyons. “Hey, that’s not an ODE”: Faster ODE adjoints via seminorms. International Conference on Machine Learning (ICML), 2021
work page 2021
- [13]
-
[14]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[15]
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu. DPM-Solver: A fast ODE solver for diffusion prob- abilistic model sampling in around 10 steps. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
- [16]
-
[17]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[18]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Repre- sentations (ICLR), 2021
work page 2021
-
[19]
A. Tong, K. Fatras, N. Malkin, G. Huguet, Y . Zhang, G. Wolf, and Y . Bengio. Improving and gener- alizing flow-based generative models with minibatch optimal transport. InTransactions on Machine Learning Research (TMLR), 2024
work page 2024
-
[20]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[21]
Q. Zhang and Y . Chen. Fast sampling of diffusion models with exponential integrator. InInternational Conference on Learning Representations (ICLR), 2023. 11 A Dormand–Prince Butcher Tableau 0 1 5 1 53 10 3 40 9 404 5 44 45 − 56 15 32 98 9 19372 6561 − 25360 2187 64448 6561 − 212 729 1 9017 3168 − 355 33 46732 5247 49 176 − 5103 18656 1 35 384 0 500 1113 ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.