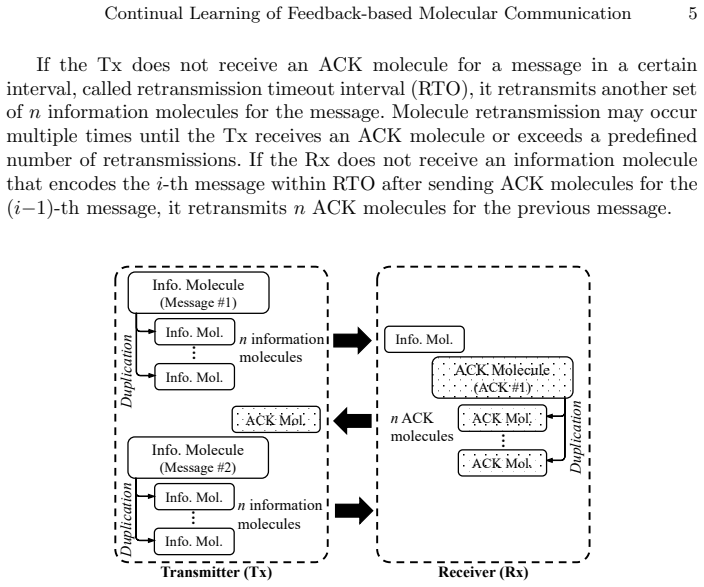
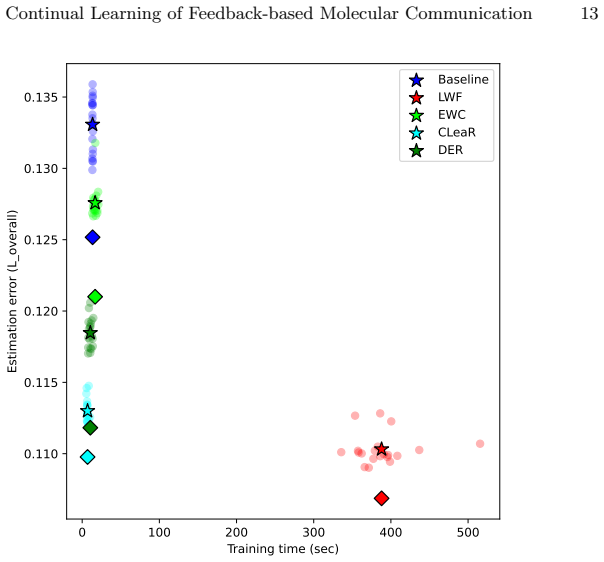
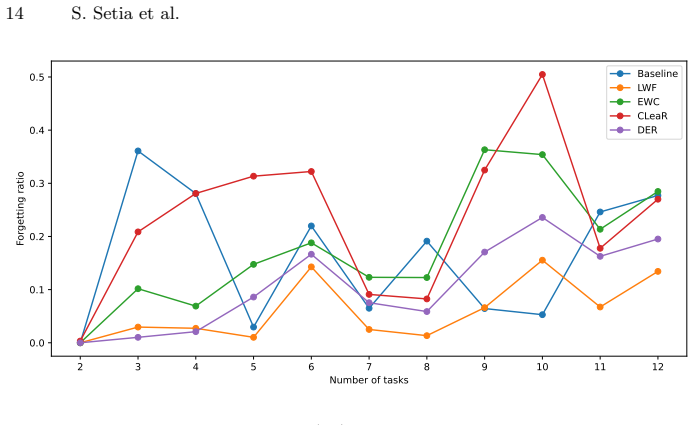
Continual Learning of Feedback-based Molecular Communication
Pith reviewed 2026-05-09 19:37 UTC · model grok-4.3
The pith
Continual learning lets neural networks estimate molecular communication performance across sequential experiments without forgetting prior tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that continual learning estimators, built by adapting regularization and replay in the loss function of a neural network, can incrementally learn unexperienced performance estimation tasks from a continuous stream of simulation results for a feedback-based molecular communication protocol while preserving performance on previously learned tasks and improving overall accuracy relative to a standard neural network baseline.
What carries the argument
Continual learning estimators that customize regularization and replay strategies in the loss function of a standard neural network to support incremental learning of molecular communication performance estimation tasks.
If this is right
- The estimators can process a continuous stream of simulation results while handling sequential changes in experimental settings.
- Estimation accuracy improves over a baseline neural network across different computational costs.
- The method supports incremental learning of new tasks without retraining from scratch each time.
- This establishes a way to apply continual learning ideas to performance analysis in molecular communication protocols.
Where Pith is reading between the lines
- The same regularization and replay customization could be tested on other simulation-based estimation problems in communications or biology modeling.
- Ongoing learned estimators might allow faster adaptation when protocol parameters or channel conditions change in practice.
- If successful, this pattern could lower the total simulation budget needed to maintain accurate performance models over time.
Load-bearing premise
Customizing regularization and replay strategies in the loss function of a standard neural network architecture will enable incremental learning of unexperienced estimation tasks for feedback-based molecular communication without compromising previously learned tasks.
What would settle it
A new sequence of simulation experiments in which the estimators show clear drops in accuracy on earlier tasks or fail to exceed baseline neural network accuracy on new tasks would falsify the central claim.
Figures


read the original abstract
This paper proposes and evaluates a new performance estimation method that leverages continual learning (CL) algorithms to carry out sequential simulation experiments for a feedback-based molecular communication protocol. As the protocol is sequentially examined in various experimental settings, the proposed CL-based performance estimators incrementally learn a series of unexperienced estimation tasks without compromising those that have been learned in the past. They are designed to work on a standard neural network architecture by customizing regularization and replay strategies in the loss function. Experimental results demonstrate that the proposed estimators can effectively learn on a continuous stream of simulation results and enhance the baseline neural network by improving estimation accuracy at a variety of computational costs. This paper's contribution is to establish the implications of CL in the field of molecular communication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes continual learning (CL) algorithms for sequential performance estimation in feedback-based molecular communication protocols. It applies customized regularization and replay strategies within the loss function of a standard neural network architecture to enable incremental learning from streams of simulation results across different experimental settings, without catastrophic forgetting of prior tasks. The central claim is that experimental results demonstrate these CL-based estimators improve estimation accuracy over a baseline neural network at varying computational costs, establishing implications of CL for molecular communication.
Significance. If the empirical results hold with proper validation, the work has moderate significance as an early application of CL techniques to molecular communication, potentially enabling more efficient handling of sequential simulation experiments. It provides a practical demonstration on standard NN architectures and reports performance at different costs, which is a strength. However, the lack of detailed experimental protocols limits assessment of broader impact or reproducibility in the field.
major comments (2)
- [Experimental Results] Experimental Results section: The manuscript asserts that experiments demonstrate improved accuracy and effective learning on continuous simulation streams, but provides no details on simulation setups, chosen baselines, specific CL customizations (e.g., exact regularization terms or replay buffer mechanisms), error metrics used, or statistical significance testing. This is load-bearing for the central empirical claim.
- [Method] Method section: The description of how the loss function is customized for regularization and replay lacks sufficient mathematical or algorithmic specification (e.g., no equations for the modified loss or pseudocode for the sequential task handling), making it difficult to assess whether the approach truly avoids forgetting while improving accuracy.
minor comments (1)
- [Abstract and Introduction] The abstract and introduction could more clearly define the sequence of 'unexperienced estimation tasks' and the molecular communication protocol parameters being varied across simulations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will revise the manuscript to improve clarity, reproducibility, and the rigor of the presentation.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: The manuscript asserts that experiments demonstrate improved accuracy and effective learning on continuous simulation streams, but provides no details on simulation setups, chosen baselines, specific CL customizations (e.g., exact regularization terms or replay buffer mechanisms), error metrics used, or statistical significance testing. This is load-bearing for the central empirical claim.
Authors: We agree that the Experimental Results section requires substantially more detail to support the central claims and enable assessment of reproducibility. In the revised manuscript, we will expand this section to provide: complete descriptions of the simulation setups (including molecular channel parameters, feedback protocol configurations, and the sequence of experimental settings); specification of the baseline neural network architecture and the particular continual learning methods applied; explicit definitions of the regularization terms and replay buffer mechanisms (including buffer size, sampling strategy, and integration into training); the precise error metrics (e.g., mean squared error or normalized estimation error); and results of statistical significance testing (including p-values from paired t-tests or similar methods comparing the CL estimators against the baseline across multiple runs). These additions will directly substantiate the reported accuracy improvements at varying computational costs. revision: yes
-
Referee: [Method] Method section: The description of how the loss function is customized for regularization and replay lacks sufficient mathematical or algorithmic specification (e.g., no equations for the modified loss or pseudocode for the sequential task handling), making it difficult to assess whether the approach truly avoids forgetting while improving accuracy.
Authors: We acknowledge that the Method section would benefit from greater mathematical and algorithmic precision. We will revise the manuscript to include: explicit equations for the customized loss function, showing the standard prediction loss augmented by a regularization term (e.g., elastic weight consolidation-style penalty on parameter importance from prior tasks) and a replay term (e.g., loss computed on a memory buffer of past simulation samples); pseudocode or a detailed algorithmic outline for sequential task handling, including how new simulation data streams are processed while replaying and regularizing to mitigate forgetting; and a clear explanation of the design choices that enable incremental learning without catastrophic forgetting. These specifications will allow readers to evaluate the technical validity of the approach. revision: yes
Circularity Check
No significant circularity
full rationale
The paper applies known continual learning techniques (regularization and replay in a standard NN loss function) to sequential simulation-based estimation tasks in molecular communication. It reports experimental accuracy gains on a stream of results without presenting any derivations, equations, or first-principles predictions. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear. The contribution is framed as an empirical demonstration of CL implications in a new domain, with no chain that reduces claims to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, C., Leeson et al., M.S.: Performance of SW-ARQ in bacterial quorum com- munications. Nano Commun. Netw.6(1)(2015)
work page 2015
-
[2]
Burton, H.O., Sullivan, D.D.: Errors and error control. Proc. of the IEE60(11) (1972)
work page 1972
- [3]
-
[4]
IEEE Access12, 192539– 192553 (2024)
Casaleiro, D., Souto, N.M.B., Silva, J.C.: Synchronization and detection in molecu- lar communication using a deep-learning-based approach. IEEE Access12, 192539– 192553 (2024)
work page 2024
- [5]
-
[6]
Cheng, Z., Liu, H., Xu, Z., Li, J., Chi, K.: Deep learning-based estimation of emission time and arrival time in diffusive multi-receiver molecular communication. IEEE Trans. Mol. Biol. Multi-Scale Commun. p. early access (2025)
work page 2025
-
[7]
IEEE Sensors Journal25(7), 10583–10593 (2025)
Cheng, Z., Liu, H., Zheng, J., Gong, W., Chi, K.: Localizing and tracking the transmitter bionanosensor in mobile molecular communication by deep learning. IEEE Sensors Journal25(7), 10583–10593 (2025)
work page 2025
-
[8]
Felicetti, L., Femminella, M., Reali, G., Nakano, T., Vasilakos, A.V.: TCP-like molecular communications. IEEE J. Sel. Area Comm.32(12), 2354–2367 (2014)
work page 2014
-
[9]
He, Y., Sick, B.: CLeaR: An adaptive continual learning framework for regression tasks. AI Perspect3(2) (2021)
work page 2021
- [10]
-
[11]
Nano Communication Networks34, 100420 (2022)
Kara, O., Yaylali, G., Pusane, A., Tugcu, T.: Molecular index modulation using convolutional neural networks. Nano Communication Networks34, 100420 (2022)
work page 2022
-
[12]
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., et al.: Overcoming catastrophic for- getting in neural networks. Proc. Natl. Acad. Sci. USA114(13), 3521–3526 (2017)
work page 2017
- [13]
-
[14]
Li, Z., Hoiem, D.: Learning without forgetting. IEEE Trans. Pattern Anal. Mach. 40(12), 2935–2947 (2018)
work page 2018
-
[15]
Psychology of Learning and Motivation24, 109– 165 (1989)
McCloskey, M., Cohen, N.: Catastrophic interference in connectionist networks: The sequential learning problem. Psychology of Learning and Motivation24, 109– 165 (1989)
work page 1989
-
[16]
In: 17th IEEE Int’l Conference on E-health Networking Applications and Services (2015)
Mitzman, J.S., Morgan, B., Soro, T.M., Suzuki, J., Nakano, T.: A feedback-based molecular communication protocol for noisy intrabody environments. In: 17th IEEE Int’l Conference on E-health Networking Applications and Services (2015)
work page 2015
-
[17]
Nakano, T., Okaie, Y., Vasilakos, A.V.: Transmission rate control for molecular communication among biological nanomachines. IEEE J. Sel. Area Comm.31(12), 835–846 (2013)
work page 2013
-
[18]
Singh, S.P., Rai, R., Awasthi, S., Singh, D.K., Lakshmanan, M.: VLSI implemen- tation of error correction codes for molecular communication. Wirel. Personal. Commun.130, 2697–2713 (2023)
work page 2023
-
[19]
Vale, R.D., Funatsu, T., Pierce, D.W., Romberg, L., Harada, Y., Yanagida, T.: Direct observation of single kinesin molecules moving along microtubules. Nature 380(1996) 16 S. Setia et al
work page 1996
-
[20]
van de Ven, G., Tuytelaars, T., Tolias, A.: Three types of incremental learning. Nat. Mach. Intell.4, 1185–1197 (2022)
work page 2022
-
[21]
Wang, L., Zhang, X., Su, H., Zhu, J.: A comprehensive survey of continual learning: Theory, method and application. IEEE Trans. Pattern Anal. Mach. Intell.46(8), 5362–5383 (2024)
work page 2024
-
[22]
Simulation Modelling Practice and Theory42(2014)
Wang, X., Higgins, M.D., Leeson, M.S.: Simulating the performance of SW-ARQ schemes within molecular communications. Simulation Modelling Practice and Theory42(2014)
work page 2014
- [23]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.