Recognition: unknown
Learning in the Fisher Subspace: A Guided Initialization for LoRA Fine-Tuning
Pith reviewed 2026-05-09 19:30 UTC · model grok-4.3
The pith
Using Fisher curvature from downstream data to initialize LoRA subspaces improves fine-tuning performance over weight-only methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LoRA initialization can be reformulated as identifying parameter directions with high impact on predictions under the downstream data distribution. By leveraging the Fisher information to quantify the curvature of the loss landscape with respect to these directions, the method selects subspaces that align adaptation more closely with the target objective, leading to better downstream performance.
What carries the argument
The Fisher information matrix computed from the downstream data, which measures the sensitivity of model predictions to parameter perturbations and guides the selection of LoRA adaptation directions.
If this is right
- LoRA fine-tuning with Fisher-guided initialization achieves higher performance on diverse tasks and modalities compared to existing weight-based initializations.
- The approach provides a task-dependent criterion for subspace selection without relying on assumptions about weight geometry alone.
- Data-aware sensitivity governs better allocation of adaptation capacity in low-rank updates.
- Empirical improvements hold across multiple modalities and tasks, suggesting broad applicability.
Where Pith is reading between the lines
- This could imply that similar curvature-based initialization might benefit other parameter-efficient fine-tuning methods like adapters or prefix tuning.
- Exploring how to efficiently approximate the Fisher matrix for very large models could extend the practicality of this method.
- Connections to natural gradient descent suggest that this initialization might reduce the number of training steps needed for convergence.
Load-bearing premise
The curvature information from the downstream data distribution accurately reflects which parameter directions most strongly influence the model's performance on the target task.
What would settle it
Observing that on a range of standard benchmarks the Fisher-guided LoRA performs similarly or worse than random or SVD-based initialization would falsify the central claim.
Figures




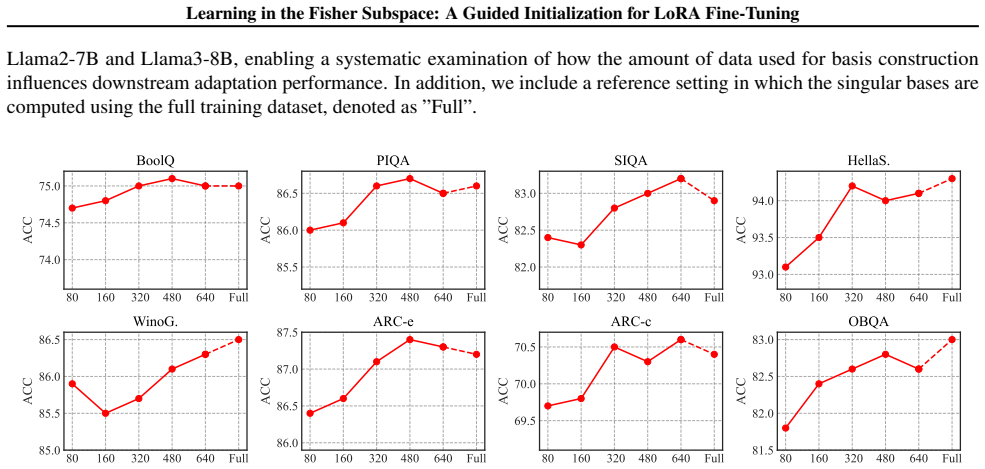


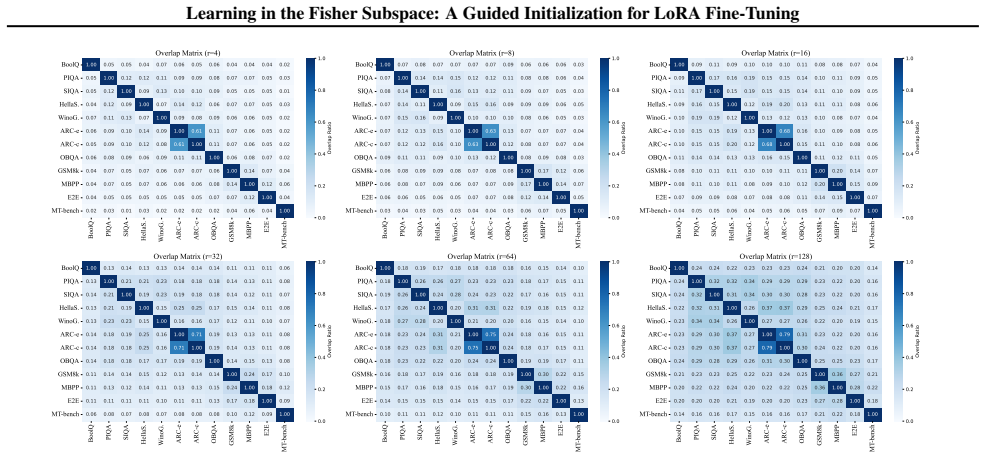
read the original abstract
LoRA adapts large language models (LLMs) by restricting updates to low-rank subspaces of pre-trained weights. While this substantially reduces training cost, the effectiveness of adaptation critically depends on which subspace is chosen at initialization: a poor initialization that allocates capacity to task-irrelevant directions can severely hinder downstream performance. Existing initialization strategies primarily rely on the intrinsic properties of pre-trained weights, implicitly assuming that weight geometry alone reflects task relevance. However, such criteria overlook how the model interacts with the downstream data distribution. In this work, we formulate LoRA initialization as identifying the degree of impact of directions in parameter space under the target data distribution. We argue that data-aware sensitivity, rather than weight-only magnitude, should govern the choice of adaptation subspaces. Building on this perspective, we propose a Fisher-guided framework that leverages curvature information induced by downstream data to characterize how parameter perturbations influence model predictions. This perspective yields a principled, task-dependent criterion for selecting LoRA directions that better align adaptation with the target objective. Empirical results across diverse tasks and modalities demonstrate that data-aware initialization consistently and significantly improves downstream performance over existing approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Fisher-guided initialization for LoRA fine-tuning of large models. It computes an approximation to the Fisher information matrix on downstream task data, extracts leading eigenvectors to define task-relevant parameter directions, and initializes the low-rank LoRA factors along those directions rather than using magnitude-based or random criteria derived only from pre-trained weights. The central claim is that this data-aware curvature criterion yields consistently better downstream performance across tasks and modalities.
Significance. If the reported gains are robust and the Fisher directions demonstrably align with loss reduction on the target objective, the method supplies a principled, task-dependent alternative to heuristic LoRA initializations. This could improve sample efficiency and final accuracy in parameter-efficient adaptation of large models while remaining computationally lightweight.
major comments (2)
- [§3.2] §3.2, Eq. (7): the claim that the top eigenvectors of the (Monte-Carlo approximated) Fisher matrix identify directions whose perturbations most reduce the fine-tuning loss is not directly tested; the manuscript should add a controlled measurement of loss sensitivity (e.g., directional derivatives or finite-difference loss change) along Fisher vs. random vs. gradient-magnitude directions on held-out target data.
- [Table 3] Table 3 (main results): the reported improvements over baselines are presented without per-task standard deviations across random seeds or statistical significance tests; this weakens the assertion of 'consistent and significant' gains, especially given that LoRA performance is known to be sensitive to initialization variance.
minor comments (2)
- The distinction between the 'empirical Fisher' and the 'true Fisher' (model predictive distribution) is mentioned only briefly; an explicit equation for the Monte-Carlo estimator used in practice would improve reproducibility.
- Figure 2 caption should state the exact number of samples and the random seed used for the Fisher approximation so that the curvature estimate can be replicated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical support and statistical rigor of our claims.
read point-by-point responses
-
Referee: [§3.2] §3.2, Eq. (7): the claim that the top eigenvectors of the (Monte-Carlo approximated) Fisher matrix identify directions whose perturbations most reduce the fine-tuning loss is not directly tested; the manuscript should add a controlled measurement of loss sensitivity (e.g., directional derivatives or finite-difference loss change) along Fisher vs. random vs. gradient-magnitude directions on held-out target data.
Authors: We agree that a direct empirical verification of loss sensitivity would provide stronger support for the interpretation of Eq. (7). In the revised version we will add a controlled experiment on held-out target data that computes both finite-difference loss changes and directional derivatives along the top Fisher eigenvectors, compared against random directions and gradient-magnitude directions. This addition will directly test whether Fisher directions exhibit greater loss reduction under small perturbations. revision: yes
-
Referee: [Table 3] Table 3 (main results): the reported improvements over baselines are presented without per-task standard deviations across random seeds or statistical significance tests; this weakens the assertion of 'consistent and significant' gains, especially given that LoRA performance is known to be sensitive to initialization variance.
Authors: We acknowledge that the absence of per-task variability measures and significance testing limits the strength of our claims. We will rerun all experiments with at least five independent random seeds, report per-task standard deviations in the revised Table 3, and include paired statistical significance tests (e.g., Wilcoxon signed-rank or t-tests with appropriate correction) against the strongest baseline. These additions will quantify robustness to initialization variance and substantiate the reported gains. revision: yes
Circularity Check
No significant circularity; Fisher-guided initialization applies standard curvature without reducing claims to fitted inputs
full rationale
The paper defines LoRA subspace selection via the Fisher information matrix computed on downstream data, using the standard definition E[∇log p(y|x;θ) ∇log p(y|x;θ)^T] to rank parameter directions by sensitivity. No equation or step equates the claimed performance gains to a quantity fitted from the same evaluation data by construction, nor does any self-citation chain justify the core criterion. Empirical results on diverse tasks serve as external validation rather than tautological confirmation. The derivation remains self-contained against the pre-trained weights and target distribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Fisher information matrix induced by the downstream data distribution characterizes the impact of parameter perturbations on model predictions.
Reference graph
Works this paper leans on
-
[1]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[2]
Fanxu Meng and Zhaohui Wang and Muhan Zhang , booktitle=. Pi. 2024 , url=
2024
-
[3]
doi: 10.18653/v1/2025.naacl-long.248
Wang, Hanqing and Li, Yixia and Wang, Shuo and Chen, Guanhua and Chen, Yun. M i L o RA : Harnessing Minor Singular Components for Parameter-Efficient LLM Finetuning. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.1...
-
[4]
2025 , eprint=
NEAT: Nonlinear Parameter-efficient Adaptation of Pre-trained Models , author=. 2025 , eprint=
2025
-
[5]
The Thirteenth International Conference on Learning Representations , year=
Unleashing the Power of Task-Specific Directions in Parameter Efficient Fine-tuning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[6]
Fan Wang and Juyong Jiang and Chansung Park and Sunghun Kim and Jing Tang , booktitle=. Ka. 2025 , url=
2025
-
[7]
Shihyang Liu and Chienyi Wang and Hongxu Yin and Pavlo Molchanov and Yu-Chiang Frank Wang and Kwang-Ting Cheng and Min-Hung Chen , booktitle=. Do. 2024 , url=
2024
-
[8]
2025 , eprint=
GoRA: Gradient-driven Adaptive Low Rank Adaptation , author=. 2025 , eprint=
2025
-
[9]
Chenghao Fan and Zhenyi Lu and Sichen Liu and Chengfeng Gu and Xiaoye Qu and Wei Wei and Yu Cheng , booktitle=. Make Lo. 2025 , url=
2025
-
[10]
The Twelfth International Conference on Learning Representations , year=
Pushing Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning , author=. The Twelfth International Conference on Learning Representations , year=
-
[11]
Zhang, Xueyan and Zhao, Jinman and Yang, Zhifei and Zhong, Yibo and Guan, Shuhao and Cao, Linbo and Wang, Yining. UORA : Uniform Orthogonal Reinitialization Adaptation in Parameter Efficient Fine-Tuning of Large Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/20...
-
[12]
Dawid Jan Kopiczko and Tijmen Blankevoort and Yuki M Asano , booktitle=. Ve. 2024 , url=
2024
-
[13]
The Eleventh International Conference on Learning Representations , year=
Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning , author=. The Eleventh International Conference on Learning Representations , year=
-
[14]
Yibo Yang and Xiaojie Li and Zhongzhu Zhou and Shuaiwen Leon Song and Jianlong Wu and Liqiang Nie and Bernard Ghanem , booktitle=. Cor. 2024 , url=
2024
-
[15]
Shaowen Wang and Linxi Yu and Jian Li , booktitle=. Lo. 2024 , url=
2024
-
[16]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Parameter Efficient Fine-tuning via Explained Variance Adaptation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[17]
2024 , eprint=
SARA: Singular-Value Based Adaptive Low-Rank Adaption , author=. 2024 , eprint=
2024
-
[18]
The Thirteenth International Conference on Learning Representations , year=
Efficient Learning with Sine-Activated Low-Rank Matrices , author=. The Thirteenth International Conference on Learning Representations , year=
-
[19]
Juzheng Zhang and Jiacheng You and Ashwinee Panda and Tom Goldstein , booktitle=. Lo. 2025 , url=
2025
-
[20]
MTL-LoRA: Low-Rank Adaptation for Multi-Task Learning , booktitle =
MTL-LoRA: Low-Rank Adaptation for Multi-Task Learning , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i20.35509 , abstractNote=
-
[21]
Chunlin Tian and Zhan Shi and Zhijiang Guo and Li Li and Cheng-zhong Xu , booktitle=. HydraLo. 2024 , url=
2024
-
[22]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina. B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long ...
-
[23]
2018 , eprint=
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author=. 2018 , eprint=
2018
-
[24]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Mihaylov, Todor and Clark, Peter and Khot, Tushar and Sabharwal, Ashish. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1260
-
[25]
H ella S wag: Can a Machine Really Finish Your Sentence?
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin. H ella S wag: Can a Machine Really Finish Your Sentence?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1472
-
[26]
2019 , eprint=
PIQA: Reasoning about Physical Commonsense in Natural Language , author=. 2019 , eprint=
2019
-
[27]
Social IQa: Commonsense Reasoning about Social Interactions
Sap, Maarten and Rashkin, Hannah and Chen, Derek and Le Bras, Ronan and Choi, Yejin. Social IQ a: Commonsense Reasoning about Social Interactions. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1454
-
[28]
2019 , eprint=
WinoGrande: An Adversarial Winograd Schema Challenge at Scale , author=. 2019 , eprint=
2019
-
[29]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[30]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[31]
3D Object Representations for Fine-Grained Categorization , year=
Krause, Jonathan and Stark, Michael and Deng, Jia and Fei-Fei, Li , booktitle=. 3D Object Representations for Fine-Grained Categorization , year=
-
[32]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Cimpoi, Mircea and Maji, Subhransu and Kokkinos, Iasonas and Mohamed, Sammy and Vedaldi, Andrea , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[33]
Introducing Eurosat: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification , year=
Helber, Patrick and Bischke, Benjamin and Dengel, Andreas and Borth, Damian , booktitle=. Introducing Eurosat: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification , year=
-
[34]
2016 , eprint=
Traffic Sign Classification Using Deep Inception Based Convolutional Networks , author=. 2016 , eprint=
2016
-
[35]
Remote Sensing Image Scene Classification: Benchmark and State of the Art , year=
Cheng, Gong and Han, Junwei and Lu, Xiaoqiang , journal=. Remote Sensing Image Scene Classification: Benchmark and State of the Art , year=
-
[36]
and Oliva, Aude and Torralba, Antonio , booktitle=
Xiao, Jianxiong and Hays, James and Ehinger, Krista A. and Oliva, Aude and Torralba, Antonio , booktitle=. SUN database: Large-scale scene recognition from abbey to zoo , year=
-
[37]
Reading digits in natural images with unsupervised feature learning , author=
-
[38]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[39]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[40]
2021 , eprint=
Program Synthesis with Large Language Models , author=. 2021 , eprint=
2021
-
[41]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[42]
The E 2 E dataset: New challenges for end-to-end generation
Novikova, Jekaterina and Du s ek, Ond r ej and Rieser, Verena. The E 2 E Dataset: New Challenges For End-to-End Generation. Proceedings of the 18th Annual SIG dial Meeting on Discourse and Dialogue. 2017. doi:10.18653/v1/W17-5525
-
[43]
Weyssow, Martin and Kamanda, Aton and Zhou, Xin and Sahraoui, Houari , title =. ACM Trans. Softw. Eng. Methodol. , month = may, keywords =. 2025 , publisher =. doi:10.1145/3736407 , abstract =
-
[44]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[45]
2024 , eprint=
Gemma: Open Models Based on Gemini Research and Technology , author=. 2024 , eprint=
2024
-
[46]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[47]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Optimizing Neural Networks with Kronecker-factored Approximate Curvature , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
2015
-
[48]
2014 , eprint=
Revisiting Natural Gradient for Deep Networks , author=. 2014 , eprint=
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.