Recognition: unknown
Local Hessian Spectral Filtering for Robust Intrinsic Dimension Estimation
Pith reviewed 2026-05-09 14:06 UTC · model grok-4.3
The pith
Spectral filtering on the log-density Hessian counts only tangent directions to estimate local intrinsic dimension even when noise fills most of high-dimensional space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
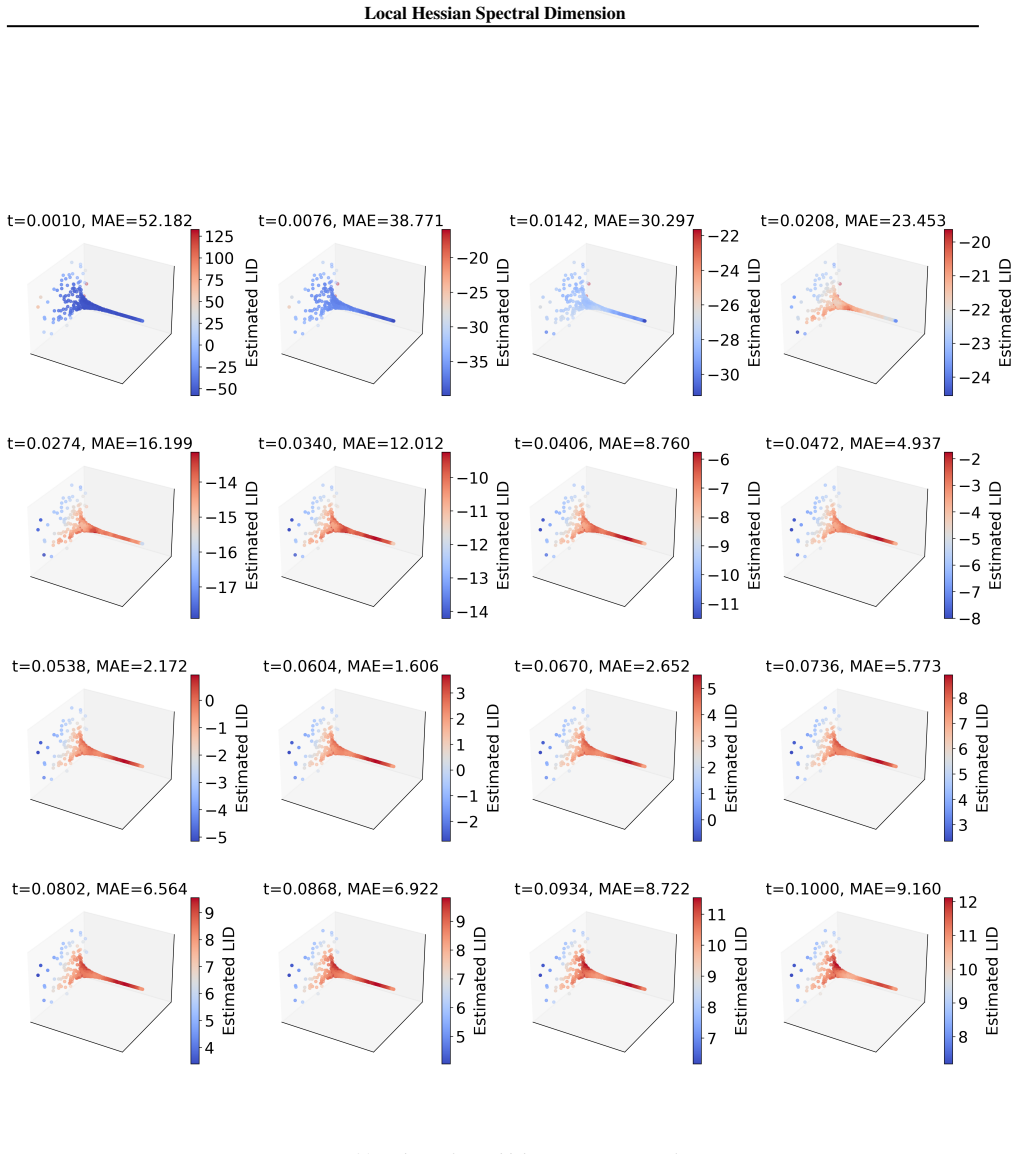
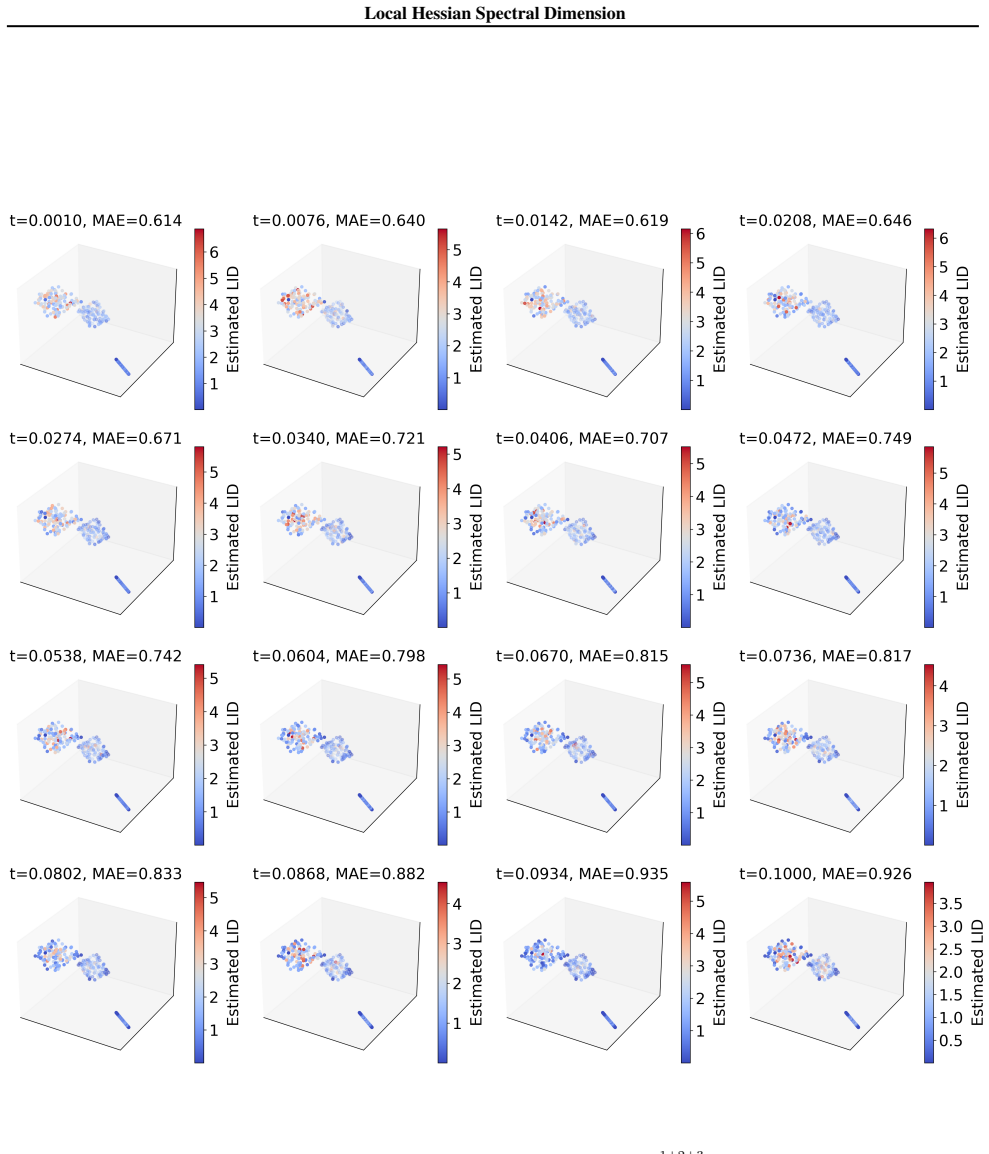
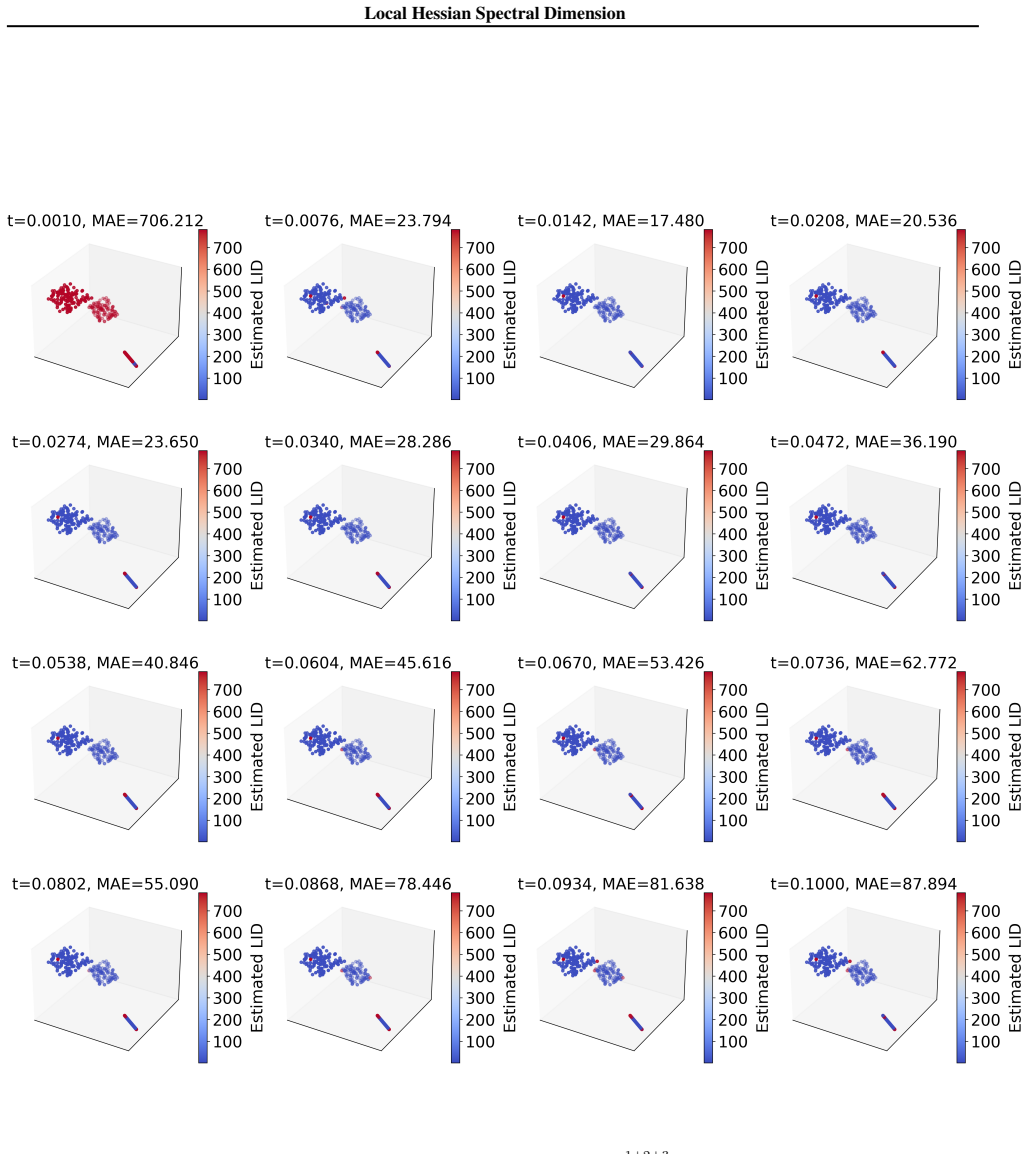
Local Hessian Spectral Dimension is computed by applying a cutoff to the eigenvalues of the log-density Hessian at each point, discarding the large values associated with normal directions and retaining only the near-zero values that mark the tangent space, all without building the full Hessian matrix.
What carries the argument
Spectral filtering of the log-density Hessian, which isolates the near-zero eigenvalues corresponding to zero-curvature tangent directions by removing large eigenvalues from normal directions.
If this is right
- The estimator remains stable in ambient dimensions where previous local intrinsic dimension methods degrade due to noise.
- Tracking the filtered dimension during training reveals when diffusion models begin to memorize specific samples rather than learn the underlying distribution.
- Linear scaling with dimension allows the method to run on large-scale models without computing or storing full Hessian matrices.
- Experiments on both synthetic manifolds and real diffusion training data show improved robustness compared to unfiltered approaches.
Where Pith is reading between the lines
- If the spectral gap persists across different data modalities, the same filtering idea could be applied to other Hessian-based tasks such as identifying flat regions in loss landscapes.
- The linear-time implementation opens the possibility of using local dimension estimates as a routine diagnostic during the training of any high-dimensional generative model.
- Applying the cutoff adaptively rather than with a fixed threshold might reduce sensitivity to the precise choice of spectral separation point.
Load-bearing premise
The log-density Hessian shows a clear gap that separates large eigenvalues of normal directions from near-zero eigenvalues of tangent directions, so a simple cutoff can be applied without losing signal.
What would settle it
A dataset or model where the eigenvalues of the log-density Hessian lack any consistent gap between large and near-zero values, so that different cutoff choices produce wildly varying dimension estimates on the same points.
Figures















read the original abstract
While diffusion models enable new approaches for estimating Local Intrinsic Dimension (LID), existing methods fail in high-dimensional spaces where noise from vast normal directions overwhelms the tangent signal. We propose Local Hessian Spectral Dimension (LHSD), which resolves this by applying spectral filtering to the log-density Hessian, explicitly cutting off large eigenvalues associated with normal directions to count zero-curvature tangent directions. Implemented using Stochastic Lanczos Quadrature (SLQ), LHSD avoids full Hessian construction, achieving linear scalability with dimension $D$. Experiments on synthetic and real data confirm LHSD's superior robustness and its utility in detecting memorization in large-scale diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Local Hessian Spectral Dimension (LHSD) to estimate local intrinsic dimension (LID) in high-dimensional spaces, particularly for diffusion models where noise from normal directions overwhelms tangent signals. LHSD applies spectral filtering to the log-density Hessian, cutting off large eigenvalues associated with normal directions to count near-zero eigenvalues corresponding to tangent directions. It is implemented using Stochastic Lanczos Quadrature (SLQ) to achieve linear scalability with dimension D without constructing the full Hessian. Experiments on synthetic and real data are presented to show superior robustness and utility in detecting memorization in large-scale diffusion models.
Significance. If the central claims hold, LHSD could provide a robust and scalable tool for LID estimation in challenging high-D regimes. The avoidance of full Hessian via SLQ is a practical strength for high dimensions. The application to memorization detection in diffusion models suggests broader impact in machine learning model analysis. Credit is due for addressing scalability explicitly.
major comments (2)
- [§3] §3 (LHSD construction): The central construction filters the Hessian spectrum by cutting off large eigenvalues (normal directions) to count near-zero ones (tangent space). This requires a detectable gap between the two clusters, but no derivation shows the gap is guaranteed or how to locate the cutoff without supervision. In practice, finite-sample Hessian estimates from diffusion models or high-D data can have overlapping or noisy spectra due to curvature, sampling variance, or manifold non-flatness; a fixed or heuristic cutoff then either undercounts tangent directions or leaks normal noise.
- [§4] §4 (Experiments): The abstract claims superior robustness and utility in detecting memorization, but supplies no derivations, cutoff selection details, error analysis, or quantitative results. This makes it difficult to verify whether the math and experiments support the claims, particularly under the weakest assumption that a simple cutoff can be applied without bias.
minor comments (1)
- [Abstract] Abstract: The claim of 'linear scalability with dimension D' would be strengthened by an explicit complexity statement or comparison to baseline runtimes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point by point below, acknowledging where clarifications and expansions are needed. We propose targeted revisions to strengthen the presentation of the method and experiments.
read point-by-point responses
-
Referee: [§3] §3 (LHSD construction): The central construction filters the Hessian spectrum by cutting off large eigenvalues (normal directions) to count near-zero ones (tangent space). This requires a detectable gap between the two clusters, but no derivation shows the gap is guaranteed or how to locate the cutoff without supervision. In practice, finite-sample Hessian estimates from diffusion models or high-D data can have overlapping or noisy spectra due to curvature, sampling variance, or manifold non-flatness; a fixed or heuristic cutoff then either undercounts tangent directions or leaks normal noise.
Authors: We agree that the spectral gap is a key assumption and that a general guarantee cannot be derived without additional conditions on the data. Section 3 of the manuscript motivates the separation from the geometry of a manifold embedded in high dimensions, where normal directions produce large positive eigenvalues of the log-density Hessian while tangent directions yield near-zero eigenvalues. In the revision we will explicitly state the required assumptions (locally approximately flat manifold, sufficient sampling density relative to curvature, and bounded noise) and add a formal discussion of when the gap is expected to exist. For cutoff location we will describe the practical heuristic employed (sorting eigenvalues and selecting the threshold at the largest gap in the log-eigenvalue spectrum, or via a simple percentile rule calibrated on synthetic data) and include a sensitivity analysis showing robustness to moderate overlap. We will also discuss failure modes when the gap is absent. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract claims superior robustness and utility in detecting memorization, but supplies no derivations, cutoff selection details, error analysis, or quantitative results. This makes it difficult to verify whether the math and experiments support the claims, particularly under the weakest assumption that a simple cutoff can be applied without bias.
Authors: Section 4 and the appendix already contain quantitative results: error rates on synthetic manifolds with known ground-truth dimensions, comparisons against MLE and PCA baselines, and metrics for memorization detection on diffusion models. Derivations for the Hessian filtering and SLQ estimator appear in Section 3 and the supplementary material. Nevertheless, we accept that the cutoff procedure and error analysis are not presented with sufficient prominence or detail. In the revision we will add an explicit subsection on cutoff selection, include bounds on the SLQ approximation error, and report additional quantitative experiments on cutoff sensitivity and bias under controlled spectral overlap. These additions will make the empirical support easier to verify. revision: yes
Circularity Check
No circularity: LHSD introduces independent spectral filtering mechanism via SLQ
full rationale
The paper's core contribution is a new estimator LHSD that applies explicit spectral cutoff to the log-density Hessian eigenvalues to isolate tangent-space directions. This filtering step is presented as a novel construction, not derived from or equivalent to any fitted parameter, prior self-result, or input data by definition. Implementation via Stochastic Lanczos Quadrature is a computational technique for avoiding full Hessian construction, with no indication that the dimension count reduces to a self-referential fit or renamed known result. Experiments on synthetic/real data serve as external validation rather than internal tautology. No load-bearing self-citations or uniqueness theorems from the same authors are invoked to force the method. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Hessian of the log-density has large eigenvalues associated with normal directions overwhelmed by noise and near-zero eigenvalues for tangent directions.
invented entities (1)
-
Local Hessian Spectral Dimension (LHSD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Pizzi, Ed and Roy, Sreya Dutta and Ravindra, Sugosh Nagavara and Goyal, Priya and Douze, Matthijs , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
-
[2]
SIAM Journal on Matrix Analysis and Applications , volume =
Ubaru, Shashanka and Chen, Jie and Saad, Yousef , title =. SIAM Journal on Matrix Analysis and Applications , volume =. 2017 , doi =
2017
-
[3]
Extracting training data from diffusion models , year =
Carlini, Nicholas and Hayes, Jamie and Nasr, Milad and Jagielski, Matthew and Sehwag, Vikash and Tram\`. Extracting training data from diffusion models , year =. Proceedings of the 32nd USENIX Conference on Security Symposium , articleno =
-
[4]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Understanding and Mitigating Memorization in Generative Models via Sharpness of Probability Landscapes , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[5]
The Thirteenth International Conference on Learning Representations , year=
A Geometric Framework for Understanding Memorization in Generative Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[6]
and Loaiza-Ganem, Gabriel , booktitle =
Kamkari, Hamidreza and Ross, Brendan Leigh and Hosseinzadeh, Rasa and Cresswell, Jesse C. and Loaiza-Ganem, Gabriel , booktitle =. A Geometric View of Data Complexity: Efficient Local Intrinsic Dimension Estimation with Diffusion Models , volume =
-
[7]
Transactions on Machine Learning Research , issn=
On Convolutions, Intrinsic Dimension, and Diffusion Models , author=. Transactions on Machine Learning Research , issn=. 2025 , note=
2025
-
[8]
and Caterini, Anthony L
Kamkari, Hamidreza and Ross, Brendan Leigh and Cresswell, Jesse C. and Caterini, Anthony L. and Krishnan, Rahul and Loaiza-Ganem, Gabriel , booktitle =. A Geometric Explanation of the Likelihood. 2024 , editor =
2024
-
[9]
and Loaiza-Ganem, Gabriel , booktitle =
Caterini, Anthony L. and Loaiza-Ganem, Gabriel , booktitle =. Entropic Issues in Likelihood-Based. 2022 , editor =
2022
-
[10]
Proceedings of the 39th International Conference on Machine Learning , pages =
Tempczyk, Piotr and Michaluk, Rafa. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
A Wiener Process Perspective on Local Intrinsic Dimension Estimation Methods , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i19.34299 , number=
-
[12]
The Fourteenth International Conference on Learning Representations , year=
Why We Need New Benchmarks for Local Intrinsic Dimension Estimation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[13]
Proceedings of the 41st International Conference on Machine Learning , pages =
Diffusion Models Encode the Intrinsic Dimension of Data Manifolds , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[14]
Intrinsic dimensionality estimation using Normalizing Flows , volume =
Horvat, Christian and Pfister, Jean-Pascal , booktitle =. Intrinsic dimensionality estimation using Normalizing Flows , volume =
-
[15]
The Twelfth International Conference on Learning Representations , year=
On gauge freedom, conservativity and intrinsic dimensionality estimation in diffusion models , author=. The Twelfth International Conference on Learning Representations , year=
-
[16]
Denoising Normalizing Flow , volume =
Horvat, Christian and Pfister, Jean-Pascal , booktitle =. Denoising Normalizing Flow , volume =
-
[17]
Low Bias Local Intrinsic Dimension Estimation from Expected Simplex Skewness , year=
Johnsson, Kerstin and Soneson, Charlotte and Fontes, Magnus , journal=. Low Bias Local Intrinsic Dimension Estimation from Expected Simplex Skewness , year=
-
[18]
and Olsen, D.R
Fukunaga, K. and Olsen, D.R. , journal=. An Algorithm for Finding Intrinsic Dimensionality of Data , year=
-
[19]
Maximum Likelihood Estimation of Intrinsic Dimension , volume =
Levina, Elizaveta and Bickel, Peter , booktitle =. Maximum Likelihood Estimation of Intrinsic Dimension , volume =
-
[20]
Scientific Reports , year=
Facco, Elena and d'Errico, Maria and Rodriguez, Alex and Laio, Alessandro , title=. Scientific Reports , year=
-
[21]
Intrinsic dimension of data representations in deep neural networks , volume =
Ansuini, Alessio and Laio, Alessandro and Macke, Jakob H and Zoccolan, Davide , booktitle =. Intrinsic dimension of data representations in deep neural networks , volume =
-
[22]
Bayesian PCA , volume =
Bishop, Christopher , booktitle =. Bayesian PCA , volume =
-
[23]
The Thirteenth International Conference on Learning Representations , year=
Diffusion Models as Cartoonists: The Curious Case of High Density Regions , author=. The Thirteenth International Conference on Learning Representations , year=
-
[24]
2025 , eprint=
Devil is in the Details: Density Guidance for Detail-Aware Generation with Flow Models , author=. 2025 , eprint=
2025
-
[25]
Proceedings of the 38th International Conference on Machine Learning , pages =
Autoencoding Under Normalization Constraints , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[26]
Chen, Ricky T. Q. and Rubanova, Yulia and Bettencourt, Jesse and Duvenaud, David K , booktitle =. Neural Ordinary Differential Equations , volume =
-
[27]
International Conference on Learning Representations , year=
Scalable Reversible Generative Models with Free-form Continuous Dynamics , author=. International Conference on Learning Representations , year=
-
[28]
The Eleventh International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. The Eleventh International Conference on Learning Representations , year=
-
[29]
The Eleventh International Conference on Learning Representations , year=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. The Eleventh International Conference on Learning Representations , year=
-
[30]
The Thirteenth International Conference on Learning Representations , year=
Manifolds, Random Matrices and Spectral Gaps: The geometric phases of generative diffusion , author=. The Thirteenth International Conference on Learning Representations , year=
-
[31]
The Annals of Statistics , volume=
Nonparametric ridge estimation , author=. The Annals of Statistics , volume=. 2014 , publisher=
2014
-
[32]
Proceedings of the 36th International Conference on Machine Learning , pages =
An Investigation into Neural Net Optimization via Hessian Eigenvalue Density , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[33]
2019 , eprint=
The Full Spectrum of Deepnet Hessians at Scale: Dynamics with SGD Training and Sample Size , author=. 2019 , eprint=
2019
-
[34]
Identifying and attacking the saddle point problem in high-dimensional non-convex optimization , volume =
Dauphin, Yann N and Pascanu, Razvan and Gulcehre, Caglar and Cho, Kyunghyun and Ganguli, Surya and Bengio, Yoshua , booktitle =. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization , volume =
-
[35]
2017 , eprint=
Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond , author=. 2017 , eprint=
2017
-
[36]
Hutchinson , title =
M.F. Hutchinson , title =. Communications in Statistics - Simulation and Computation , volume =. 1989 , publisher =
1989
-
[37]
Meyer and Cameron Musco and Christopher Musco and David P
Raphael A. Meyer and Cameron Musco and Christopher Musco and David P. Woodruff , title =. 2021 Symposium on Simplicity in Algorithms (SOSA) , chapter =
2021
-
[38]
International Conference on Learning Representations , year=
Gradient Estimators for Implicit Models , author=. International Conference on Learning Representations , year=
-
[39]
Measuring Sample Quality with Stein s Method , volume =
Gorham, Jackson and Mackey, Lester , booktitle =. Measuring Sample Quality with Stein s Method , volume =
-
[40]
Proceedings of The 33rd International Conference on Machine Learning , pages =
A Kernelized Stein Discrepancy for Goodness-of-fit Tests , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , editor =
2016
-
[41]
Proceedings of the 35th International Conference on Machine Learning , pages =
A Spectral Approach to Gradient Estimation for Implicit Distributions , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[42]
Estimation of Non-Normalized Statistical Models by Score Matching , journal =
Aapo Hyv. Estimation of Non-Normalized Statistical Models by Score Matching , journal =. 2005 , volume =
2005
-
[43]
Regularized estimation of image statistics by Score Matching , volume =
Kingma, Durk P and LeCun, Yann , booktitle =. Regularized estimation of image statistics by Score Matching , volume =
-
[44]
Proceedings of the Thirty-Fifth Conference on Uncertainty in Artificial Intelligence,
Yang Song and Sahaj Garg and Jiaxin Shi and Stefano Ermon , title =. Proceedings of the Thirty-Fifth Conference on Uncertainty in Artificial Intelligence,
-
[45]
Efficient Learning of Generative Models via Finite-Difference Score Matching , volume =
Pang, Tianyu and Xu, Kun and LI, Chongxuan and Song, Yang and Ermon, Stefano and Zhu, Jun , booktitle =. Efficient Learning of Generative Models via Finite-Difference Score Matching , volume =
-
[46]
Neural computation , volume=
A connection between score matching and denoising autoencoders , author=. Neural computation , volume=. 2011 , publisher=
2011
-
[47]
Generative Modeling by Estimating Gradients of the Data Distribution , volume =
Song, Yang and Ermon, Stefano , booktitle =. Generative Modeling by Estimating Gradients of the Data Distribution , volume =
-
[48]
Improved Techniques for Training Score-Based Generative Models , volume =
Song, Yang and Ermon, Stefano , booktitle =. Improved Techniques for Training Score-Based Generative Models , volume =
-
[49]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Lim, Jae Hyun and Courville, Aaron and Pal, Christopher and Huang, Chin-Wei , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
2020
-
[50]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Deep Unsupervised Learning using Nonequilibrium Thermodynamics , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
2015
-
[51]
Denoising Diffusion Probabilistic Models , volume =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , booktitle =. Denoising Diffusion Probabilistic Models , volume =
-
[52]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[53]
Stochastic Processes and their Applications , volume=
Reverse-time diffusion equation models , author=. Stochastic Processes and their Applications , volume=
-
[54]
Maximum Likelihood Training of Score-Based Diffusion Models , volume =
Song, Yang and Durkan, Conor and Murray, Iain and Ermon, Stefano , booktitle =. Maximum Likelihood Training of Score-Based Diffusion Models , volume =
-
[55]
Elucidating the Design Space of Diffusion-Based Generative Models , volume =
Karras, Tero and Aittala, Miika and Aila, Timo and Laine, Samuli , booktitle =. Elucidating the Design Space of Diffusion-Based Generative Models , volume =
-
[56]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Karras, Tero and Aittala, Miika and Lehtinen, Jaakko and Hellsten, Janne and Aila, Timo and Laine, Samuli , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[57]
Maximum Likelihood Training of Implicit Nonlinear Diffusion Model , volume =
Kim, Dongjun and Na, Byeonghu and Kwon, Se Jung and Lee, Dongsoo and Kang, Wanmo and Moon, Il-chul , booktitle =. Maximum Likelihood Training of Implicit Nonlinear Diffusion Model , volume =
-
[58]
Proceedings of the 40th International Conference on Machine Learning , year =
FP-Diffusion: Improving Score-based Diffusion Models by Enforcing the Underlying Score Fokker-Planck Equation , author=. Proceedings of the 40th International Conference on Machine Learning , year =
-
[59]
2023 , eprint=
Closing the ODE-SDE gap in score-based diffusion models through the Fokker-Planck equation , author=. 2023 , eprint=
2023
-
[60]
Maximum Likelihood Training for Score-based Diffusion
Lu, Cheng and Zheng, Kaiwen and Bao, Fan and Chen, Jianfei and Li, Chongxuan and Zhu, Jun , booktitle =. Maximum Likelihood Training for Score-based Diffusion. 2022 , editor =
2022
-
[61]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
-
[62]
2023 , eprint=
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis , author=. 2023 , eprint=
2023
-
[63]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding , volume =
Saharia, Chitwan and Chan, William and Saxena, Saurabh and Li, Lala and Whang, Jay and Denton, Emily L and Ghasemipour, Kamyar and Gontijo Lopes, Raphael and Karagol Ayan, Burcu and Salimans, Tim and Ho, Jonathan and Fleet, David J and Norouzi, Mohammad , booktitle =. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding , volume =
-
[64]
2022 , eprint=
Hierarchical Text-Conditional Image Generation with CLIP Latents , author=. 2022 , eprint=
2022
-
[65]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Understanding Likelihood of Normalizing Flow and Image Complexity through the Lens of Out-of-Distribution Detection , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2024 , month=. doi:10.1609/aaai.v38i19.30146 , number=
-
[66]
International Conference on Learning Representations , year=
Improved Autoregressive Modeling with Distribution Smoothing , author=. International Conference on Learning Representations , year=
-
[67]
ICML Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models , year=
On the expressivity of bi-Lipschitz normalizing flows , author=. ICML Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models , year=
-
[68]
ICML Workshop on Uncertainty & Robustness in Deep Learning , year=
No True State-of-the-Art? OOD Detection Methods are Inconsistent across Datasets , author=. ICML Workshop on Uncertainty & Robustness in Deep Learning , year=
-
[69]
Learning disconnected manifolds: a no
Tanielian, Ugo and Issenhuth, Thibaut and Dohmatob, Elvis and Mary, Jeremie , booktitle =. Learning disconnected manifolds: a no. 2020 , editor =
2020
-
[70]
Proceedings of the 37th International Conference on Machine Learning , pages =
Relaxing Bijectivity Constraints with Continuously Indexed Normalising Flows , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[71]
Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =
Understanding and Mitigating Exploding Inverses in Invertible Neural Networks , author =. Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =. 2021 , volume =
2021
-
[72]
Flows for simultaneous manifold learning and density estimation , volume =
Brehmer, Johann and Cranmer, Kyle , booktitle =. Flows for simultaneous manifold learning and density estimation , volume =
- [73]
-
[74]
International Conference on Learning Representations , year=
Implicit Normalizing Flows , author=. International Conference on Learning Representations , year=
-
[75]
Lipschitz regularity of deep neural networks: analysis and efficient estimation , volume =
Virmaux, Aladin and Scaman, Kevin , booktitle =. Lipschitz regularity of deep neural networks: analysis and efficient estimation , volume =
-
[76]
Sajjadi, Mehdi S. M. and Bachem, Olivier and Lucic, Mario and Bousquet, Olivier and Gelly, Sylvain , booktitle =. Assessing Generative Models via Precision and Recall , volume =
-
[77]
2014 , publisher=
Geometric measure theory , author=. 2014 , publisher=
2014
-
[78]
An implementation of the GLOW paper and simple normalizing flows lib
Krzysztof Kolasinski. An implementation of the GLOW paper and simple normalizing flows lib. 2018
2018
-
[79]
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Li, Yijun and Liu, Sifei and Yang, Jimei and Yang, Ming-Hsuan , title =. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[80]
2008 , publisher=
An introduction to Kolmogorov complexity and its applications , author=. 2008 , publisher=
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.