Recognition: unknown
Decision-Focused Learning via Tangent-Space Projection of Prediction Error
Pith reviewed 2026-05-09 14:14 UTC · model grok-4.3
The pith
The regret gradient equals the prediction error projected onto the tangent space of active constraints and scaled by local curvature.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under standard regularity with locally stable active constraints, the regret gradient is equivalent to the prediction error projected onto the tangent space of the active constraints and scaled by local curvature. This characterization shows that regret gradients arise by filtering decision-irrelevant components from the mean-squared-error gradient, yielding a closed-form expression that can be evaluated by solving a reduced linear system over the active constraints alone.
What carries the argument
The tangent-space projection of prediction error onto active constraints, which isolates the decision-relevant component of the gradient without requiring differentiation through the solver.
If this is right
- Regret gradients become computable from a single reduced linear system whose size depends only on the number of active constraints.
- No differentiation through iterative solver steps or extra optimization solves is required to obtain the gradient.
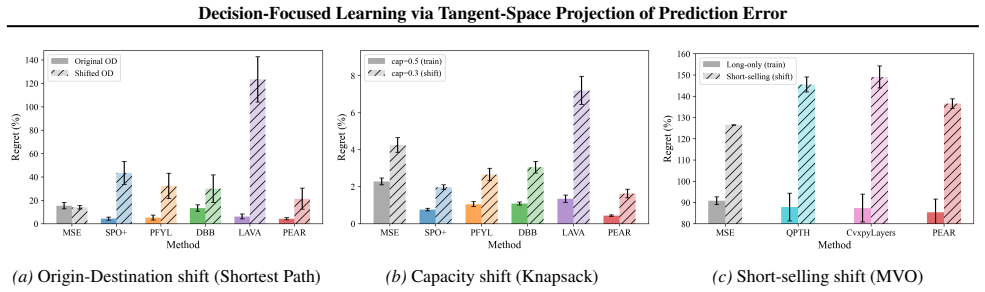
- The resulting training procedure improves downstream decision quality on linear and quadratic programs while using less compute than prior methods.
- Performance advantages remain when the constraint set shifts after the predictor has been trained.
Where Pith is reading between the lines
- The same projection view could supply cheap gradient estimates for any constrained decision problem whose active set can be identified reliably.
- Implementation in existing optimization libraries would require only the Jacobian of the active constraints and a single linear solve rather than custom autodiff rules.
- When predictions are noisy, the filtering step may also reduce the variance of the effective gradient seen by the predictor.
Load-bearing premise
The set of active constraints at the optimal decision stays locally stable under small changes to the predictions.
What would settle it
If finite-difference estimates of the true regret gradient on a problem with fixed active constraints diverge from the value produced by the projection formula, the claimed geometric characterization is false.
Figures



read the original abstract
Decision-Focused Learning (DFL) trains predictors to improve downstream decision quality, but computing regret gradients typically requires differentiating through solvers or relying on surrogate losses, which can be computationally expensive or deviate from the true objective. We show that, under standard regularity with locally stable active constraints, the regret gradient admits a closed-form geometric characterization, equivalent to the prediction error projected onto the tangent space of active constraints, scaled by local curvature. This reveals that regret gradients can be obtained by filtering decision-irrelevant components from the MSE gradient, providing a simpler and more direct alternative to existing approaches. Based on this, we propose PEAR (Projected Error As Regret-gradient), which computes regret gradients via a reduced linear system over active constraints, avoiding differentiation through solver iterations or additional optimization solves. Experiments on LP benchmarks and a real-world QP task show that PEAR achieves the best decision quality among all baselines while being the most computationally efficient, with gains that persist under constraint shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that, under standard regularity conditions with locally stable active constraints, the regret gradient in decision-focused learning admits a closed-form geometric characterization: it equals the prediction error projected onto the tangent space of the active constraints and scaled by local curvature. This insight yields the PEAR method, which obtains the gradient by solving a reduced linear system over the active constraints, avoiding differentiation through solvers or surrogate losses. Experiments on LP benchmarks and a real-world QP task report that PEAR achieves the best decision quality among baselines while being the most computationally efficient, with gains persisting under constraint shifts.
Significance. If the characterization holds, the work offers a computationally lighter and geometrically interpretable route to regret gradients in DFL, potentially making optimization-aware training more scalable. The parameter-free derivation from tangent-space geometry and active-set stability is a clear strength, as is the emphasis on efficiency without additional optimization solves. The reported outperformance on LP and QP tasks suggests practical value, provided the stability assumption is verified.
major comments (2)
- [Abstract] Abstract: the claim that 'performance gains persist under constraint shifts' is presented without any reported diagnostic (e.g., active-set monitoring or basis-change counts) confirming that the active constraints remained locally stable during those shifts or during the finite-difference validations of the closed-form expression.
- [Experiments] Experimental section (LP benchmarks): the central equivalence requires locally stable active sets, yet the manuscript provides no evidence that basis changes were absent under the small parameter perturbations used in the benchmarks; polyhedral LPs are known to be sensitive to such flips, which would invalidate the tangent-space projection.
minor comments (1)
- The regularity conditions (e.g., strict complementarity or non-degeneracy) invoked for the projection formula could be stated more explicitly with a short list of required assumptions.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for emphasizing the need to verify local stability of active constraints, which underpins the tangent-space characterization of regret gradients. We address each major comment below and will incorporate the suggested diagnostics in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'performance gains persist under constraint shifts' is presented without any reported diagnostic (e.g., active-set monitoring or basis-change counts) confirming that the active constraints remained locally stable during those shifts or during the finite-difference validations of the closed-form expression.
Authors: We appreciate this point. The manuscript's theoretical results are derived under the explicit assumption of locally stable active constraints (as stated in the introduction and method sections). The abstract claim regarding persistence under constraint shifts was intended as an empirical observation, but we agree that it should be supported by diagnostics. In revision, we will add active-set monitoring (including basis-change counts) for the constraint-shift experiments and finite-difference validations, and we will revise the abstract to qualify the claim accordingly. This will confirm that the tangent-space projection remains applicable in the reported regimes. revision: yes
-
Referee: [Experiments] Experimental section (LP benchmarks): the central equivalence requires locally stable active sets, yet the manuscript provides no evidence that basis changes were absent under the small parameter perturbations used in the benchmarks; polyhedral LPs are known to be sensitive to such flips, which would invalidate the tangent-space projection.
Authors: We agree that the sensitivity of polyhedral LPs to basis flips is a valid concern and that explicit verification is needed to support the central equivalence. In the revised experimental section, we will include new analysis reporting the frequency of basis changes (or their absence) under the small perturbations used for both the LP benchmarks and the finite-difference gradient validations. This will directly address whether the active sets remained locally stable, thereby validating the applicability of the projected-error characterization. If any flips are observed, their impact will be discussed. revision: yes
Circularity Check
No significant circularity; derivation rests on geometric assumptions rather than self-reference or fitted inputs
full rationale
The abstract presents the regret gradient as a closed-form geometric characterization (prediction error projected onto tangent space of active constraints, scaled by local curvature) derived under standard regularity and locally stable active constraints. No equations or steps in the provided text reduce the claimed result to a fitted parameter renamed as prediction, a self-definitional loop, or a load-bearing self-citation chain. The derivation is framed as following from properties of the feasible set and active-set stability, which are external to the paper's own outputs. This matches the default expectation of a self-contained derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption standard regularity with locally stable active constraints
Reference graph
Works this paper leans on
-
[1]
1983 , publisher=
Introduction to sensitivity and stability analysis in non linear programming , author=. 1983 , publisher=
1983
-
[2]
2013 , publisher=
Perturbation analysis of optimization problems , author=. 2013 , publisher=
2013
-
[3]
Traces and emergence of nonlinear programming , pages=
Minima of functions of several variables with inequalities as side conditions , author=. Traces and emergence of nonlinear programming , pages=. 2013 , publisher=
2013
-
[4]
Traces and emergence of nonlinear programming , pages=
Nonlinear programming , author=. Traces and emergence of nonlinear programming , pages=. 2013 , publisher=
2013
-
[5]
Mathematical programming , volume=
Sensitivity analysis for nonlinear programming using penalty methods , author=. Mathematical programming , volume=. 1976 , publisher=
1976
-
[6]
2006 , edition=
Numerical Optimization , author=. 2006 , edition=
2006
-
[7]
Mathematics of Operations Research , volume=
Strongly regular generalized equations , author=. Mathematics of Operations Research , volume=. 1980 , publisher=
1980
-
[8]
2009 , publisher=
Implicit functions and solution mappings , author=. 2009 , publisher=
2009
-
[9]
Artificial Intelligence and Statistics , pages=
Generic methods for optimization-based modeling , author=. Artificial Intelligence and Statistics , pages=. 2012 , organization=
2012
-
[10]
International conference on machine learning , pages=
Gradient-based hyperparameter optimization through reversible learning , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[11]
Unrolled generative adversarial networks
Unrolled generative adversarial networks , author=. arXiv preprint arXiv:1611.02163 , year=
-
[12]
On differentiating parameterized argmin and argmax problems with application to bi-level optimization , author=. arXiv preprint arXiv:1607.05447 , year=
-
[13]
International conference on machine learning , pages=
Input convex neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[14]
International conference on machine learning , pages=
Optnet: Differentiable optimization as a layer in neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[15]
Advances in neural information processing systems , volume=
Task-based end-to-end model learning in stochastic optimization , author=. Advances in neural information processing systems , volume=
-
[16]
Dif- ferentiating through a cone program,
Differentiating through a cone program , author=. arXiv preprint arXiv:1904.09043 , year=
-
[17]
Advances in neural information processing systems , volume=
Differentiable convex optimization layers , author=. Advances in neural information processing systems , volume=
-
[18]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Deep declarative networks , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2021 , publisher=
2021
-
[19]
Advances in Neural Information Processing Systems , volume=
Interior point solving for lp-based prediction+ optimisation , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Proceedings of the AAAI conference on artificial intelligence , volume=
Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[21]
arXiv preprint arXiv:2508.11365 , year=
Minimizing Surrogate Losses for Decision-Focused Learning using Differentiable Optimization , author=. arXiv preprint arXiv:2508.11365 , year=
-
[22]
predict, then optimize
Smart “predict, then optimize” , author=. Management Science , volume=. 2022 , publisher=
2022
-
[23]
arXiv preprint arXiv:2011.05354 , year=
Contrastive losses and solution caching for predict-and-optimize , author=. arXiv preprint arXiv:2011.05354 , year=
-
[24]
International conference on machine learning , pages=
Decision-focused learning: Through the lens of learning to rank , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[25]
Advances in Neural Information Processing Systems , volume=
Decision-focused learning without decision-making: Learning locally optimized decision losses , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Advances in neural information processing systems , volume=
Learning with differentiable pertubed optimizers , author=. Advances in neural information processing systems , volume=
-
[27]
Advances in Neural Information Processing Systems , volume=
Implicit MLE: backpropagating through discrete exponential family distributions , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
International Conference on Learning Representations , year=
Differentiation of blackbox combinatorial solvers , author=. International Conference on Learning Representations , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Decision-focused learning with directional gradients , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
arXiv preprint arXiv:2505.22224 , year=
Solver-Free Decision-Focused Learning for Linear Optimization Problems , author=. arXiv preprint arXiv:2505.22224 , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
BPQP: A Differentiable Convex Optimization Framework for Efficient End-to-End Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Advances in neural information processing systems , volume=
Efficient and modular implicit differentiation , author=. Advances in neural information processing systems , volume=
-
[33]
Proceedings of the AAAI conference on artificial intelligence , volume=
Smart predict-and-optimize for hard combinatorial optimization problems , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[34]
Advances in Neural Information Processing Systems , volume=
Taskmet: Task-driven metric learning for model learning , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
33rd International Joint Conference on Artificial Intelligence , pages=
Robust Losses for Decision-Focused Learning , author=. 33rd International Joint Conference on Artificial Intelligence , pages=
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
DFF: Decision-Focused Fine-Tuning for Smarter Predict-Then-Optimize with Limited Data , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[37]
arXiv preprint arXiv:2502.00828 , year=
Decision-informed neural networks with large language model integration for portfolio optimization , author=. arXiv preprint arXiv:2502.00828 , year=
-
[38]
Journal of Artificial Intelligence Research , volume=
Decision-focused learning: Foundations, state of the art, benchmark and future opportunities , author=. Journal of Artificial Intelligence Research , volume=
-
[39]
European Journal of Operational Research , volume=
A survey of contextual optimization methods for decision-making under uncertainty , author=. European Journal of Operational Research , volume=. 2025 , publisher=
2025
-
[40]
Springer Science , volume=
Numerical optimization , author=. Springer Science , volume=
-
[41]
Automatica , volume=
The explicit linear quadratic regulator for constrained systems , author=. Automatica , volume=. 2002 , publisher=
2002
-
[42]
International Conference on Machine Learning (ICML) , pages=
Differentiating through optimization problems , author=. International Conference on Machine Learning (ICML) , pages=
-
[43]
2004 , publisher=
Convex optimization , author=. 2004 , publisher=
2004
-
[44]
Mathematical Programming Computation , volume=
OSQP: An operator splitting solver for quadratic programs , author=. Mathematical Programming Computation , volume=. 2020 , publisher=
2020
-
[45]
arXiv preprint arXiv:2210.01802 , year=
Alternating differentiation for optimization layers , author=. arXiv preprint arXiv:2210.01802 , year=
-
[46]
Proceedings of the AAAI conference on artificial intelligence , volume=
Mipaal: Mixed integer program as a layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[47]
PyEPO: A PyTorch-based End-to-End Predict-then-Optimize Library for Linear and Integer Programming
Pyepo: A pytorch-based end-to-end predict-then-optimize library for linear and integer programming , author=. arXiv preprint arXiv:2206.14234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
International journal of neural systems , volume=
Using a financial training criterion rather than a prediction criterion , author=. International journal of neural systems , volume=. 1997 , publisher=
1997
-
[49]
Backpropagation through combinatorial algorithms: Identity with projection works , author=. arXiv preprint arXiv:2205.15213 , year=
-
[50]
Neural computation , volume=
Fast exact multiplication by the Hessian , author=. Neural computation , volume=. 1994 , publisher=
1994
-
[51]
Proceedings of the 6th ACM International Conference on AI in Finance , pages=
Return Prediction for Mean-Variance Portfolio Selection: How Decision-Focused Learning Shapes Forecasting Models , author=. Proceedings of the 6th ACM International Conference on AI in Finance , pages=
-
[52]
Proceedings of the AAAI conference on artificial intelligence , volume=
Are transformers effective for time series forecasting? , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[53]
Magoon and Fengyu Yang and Noam Aigerman and Shahar Z
Connor W. Magoon and Fengyu Yang and Noam Aigerman and Shahar Z. Kovalsky , title =. Advances in Neural Information Processing Systems , year =
-
[54]
Mathematics of operations research , volume=
Sensitivity analysis for nonlinear programs and variational inequalities with nonunique multipliers , author=. Mathematics of operations research , volume=. 1990 , publisher=
1990
-
[55]
Advances in Neural Information Processing Systems , volume=
Landscape surrogate: Learning decision losses for mathematical optimization under partial information , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
ICLR 2024-The Twelfth International Conference on Learning Representations , year=
Leveraging augmented-Lagrangian techniques for differentiating over infeasible quadratic programs in machine learning , author=. ICLR 2024-The Twelfth International Conference on Learning Representations , year=
2024
-
[57]
Quantitative Finance , volume=
Distributionally robust end-to-end portfolio construction , author=. Quantitative Finance , volume=. 2023 , publisher=
2023
-
[58]
Electric Power Systems Research , volume=
Decision-focused learning under decision dependent uncertainty for power systems with price-responsive demand , author=. Electric Power Systems Research , volume=. 2024 , publisher=
2024
-
[59]
Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems , pages=
Restless multi-armed bandits for maternal and child health: Results from decision-focused learning , author=. Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems , pages=
2023
-
[60]
International conference on learning representations , year=
Reversible instance normalization for accurate time-series forecasting against distribution shift , author=. International conference on learning representations , year=
-
[61]
SIAM Journal on Optimization , volume=
Active set identification in nonlinear programming , author=. SIAM Journal on Optimization , volume=. 2006 , publisher=
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.