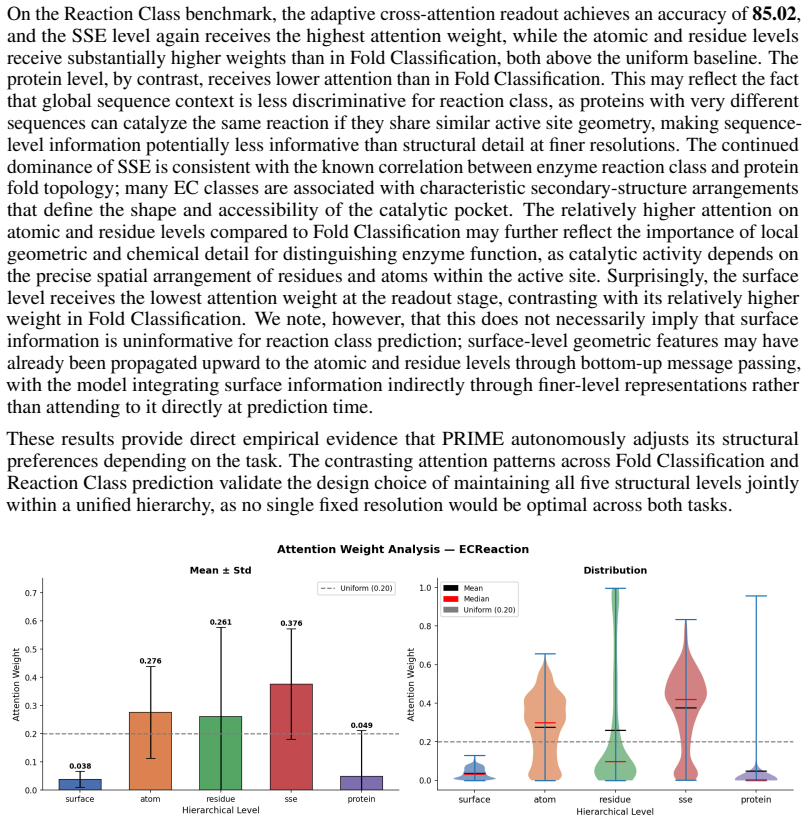
Recognition: 2 theorem links
· Lean TheoremPRIME: Protein Representation via Physics-Informed Multiscale Equivariant Hierarchies
Pith reviewed 2026-05-13 07:16 UTC · model grok-4.3
The pith
PRIME models proteins as five nested physics-grounded structural graphs linked by fixed physics-informed operators to enable multiscale representation learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Proteins are represented as a nested hierarchy of five physically grounded graphs whose adjacent levels exchange information through deterministic, physics-informed assignment operators; bottom-up aggregation and top-down contextual refinement across this fixed hierarchy yields protein representations that improve downstream prediction accuracy on structure and function tasks.
What carries the argument
Nested family of five structural graphs (surface to protein level) joined by deterministic physics-informed assignment operators that perform bidirectional message passing.
If this is right
- Outperforms the strongest geometric GNN baseline by 13.80 and 18.30 points on the Superfamily and Fold splits of fold classification.
- Achieves 84.10 percent accuracy on reaction-class prediction, surpassing all reported baselines including ESM.
- Each of the five structural levels contributes complementary, non-redundant information as shown by ablation studies.
- The model autonomously selects task-relevant structural resolutions through adaptive cross-attention at inference time.
Where Pith is reading between the lines
- The fixed-operator hierarchy could be tested on other multiscale physical systems such as materials or molecular dynamics trajectories.
- Performance gains may translate to improved generalization on low-data protein engineering tasks where explicit hierarchy reduces reliance on large pretraining corpora.
- If the deterministic connections prove robust, similar operator-based hierarchies could be defined for other biomolecules without retraining the inter-level mappings.
Load-bearing premise
The five structural levels are linked by fixed physics-informed assignment operators that correctly encode the true hierarchical relationships without task-specific biases.
What would settle it
Replace the deterministic assignment operators with either random mappings or fully learned parameters and measure whether the performance margins on the Superfamily and Fold splits disappear or reverse.
Figures



read the original abstract
Proteins are inherently multiscale physical systems whose functional properties emerge from coordinated structural organization across multiple spatial resolutions, ranging from atomic interactions to global fold topology. However, existing protein representation learning methods typically operate at a single structural level or treat different sources of structural information as parallel modalities, without explicitly modeling their hierarchical relationships. We introduce PRIME (Protein Representation via Physics-Informed Multiscale Equivariant Hierarchies), a unified framework that models proteins as a nested family of five physically grounded structural graphs spanning surface, atomic, residue, secondary-structure, and protein levels. Adjacent levels are connected through deterministic, physics-informed assignment operators, enabling bidirectional information exchange via bottom-up aggregation and top-down contextual refinement. Experiments on standard protein representation learning benchmarks demonstrate strong and competitive performance across diverse tasks, with particularly notable gains on the Fold Classification benchmark, where PRIME outperforms the strongest geometric GNN baseline by margins of 13.80 and 18.30 points on the harder Superfamily and Fold splits, and achieves a state-of-the-art accuracy of 84.10\% on Reaction Class prediction, surpassing all baseline methods, including ESM. Ablation studies confirm that each structural level contributes complementary and non-redundant information, and adaptive cross-attention analysis reveals that PRIME autonomously identifies the most task-relevant structural resolutions at prediction time. Our source code is publicly available at https://github.com/HySonLab/PRIME
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRIME, a unified framework for protein representation learning that models proteins as a nested hierarchy of five physically grounded graphs (surface, atomic, residue, secondary-structure, and protein levels) connected by deterministic physics-informed assignment operators. These operators enable bidirectional information flow via bottom-up aggregation and top-down refinement while preserving equivariance. The model is evaluated on standard benchmarks, reporting competitive performance with notable gains of 13.80 and 18.30 points on the Superfamily and Fold splits of fold classification, plus 84.10% accuracy on reaction class prediction that surpasses all baselines including ESM. Ablations confirm complementary contributions from each level, and adaptive cross-attention is used to identify task-relevant scales.
Significance. If the central claims hold, PRIME could advance protein representation learning by providing an explicit, physics-grounded mechanism for integrating multiscale structural information, addressing limitations of single-scale or parallel-modality approaches. The reported improvements on challenging fold classification splits and state-of-the-art reaction prediction suggest better capture of hierarchical relationships, with public code availability aiding reproducibility and extension. This could influence downstream applications in structural biology if the operators generalize beyond the evaluated benchmarks.
major comments (3)
- [Abstract] Abstract: The performance claims (outperformance by 13.80/18.30 points on Superfamily/Fold splits and 84.10% on reaction class) are presented without error bars, number of runs, statistical significance tests, or details on baseline reimplementations and training protocols, which is load-bearing for establishing that the gains are robust and attributable to the hierarchical design rather than experimental variance.
- [§3] §3 (Architecture): The deterministic physics-informed assignment operators are asserted to capture true hierarchical relationships without task-specific bias or learned parameters; however, the manuscript must provide explicit equations or pseudocode for each operator (e.g., surface-to-atomic projection and residue-to-secondary structure via DSSP-like rules) to allow verification that design choices do not embed implicit alignments with benchmark statistics.
- [§4.2] §4.2 (Ablations): While ablations show each structural level contributes non-redundant information, they do not include controls that replace the deterministic operators with random or fully learned alternatives; such tests are needed to confirm that the performance derives from the physics-informed hierarchy rather than the general multiscale structure.
minor comments (2)
- [Abstract] The manuscript should clarify the exact metric (e.g., accuracy) used for the fold classification results and specify the strongest geometric GNN baseline by name and citation.
- [§4.3] Figure captions and the adaptive cross-attention analysis would benefit from additional detail on how attention weights are aggregated across levels to identify task-relevant resolutions.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which have helped us identify areas to strengthen the manuscript. We address each major point below, with planned revisions to improve clarity, reproducibility, and experimental rigor.
read point-by-point responses
-
Referee: [Abstract] The performance claims (outperformance by 13.80/18.30 points on Superfamily/Fold splits and 84.10% on reaction class) are presented without error bars, number of runs, statistical significance tests, or details on baseline reimplementations and training protocols, which is load-bearing for establishing that the gains are robust and attributable to the hierarchical design rather than experimental variance.
Authors: We agree that reporting error bars, run counts, and experimental details is essential for robust claims. In the revised manuscript, we will add standard deviations from 5 independent runs with different random seeds, full details on baseline reimplementations (including hyperparameters and training protocols), and statistical significance tests (e.g., paired t-tests) comparing PRIME to baselines. These additions will be incorporated into the abstract, results tables, and experimental section. revision: yes
-
Referee: [§3] The deterministic physics-informed assignment operators are asserted to capture true hierarchical relationships without task-specific bias or learned parameters; however, the manuscript must provide explicit equations or pseudocode for each operator (e.g., surface-to-atomic projection and residue-to-secondary structure via DSSP-like rules) to allow verification that design choices do not embed implicit alignments with benchmark statistics.
Authors: We acknowledge that the current description of the operators is at a conceptual level. To enable full verification, we will expand Section 3 with explicit mathematical equations and pseudocode for all five assignment operators (surface-to-atomic, atomic-to-residue, residue-to-secondary-structure via DSSP rules, secondary-structure-to-protein, and the bidirectional flows). This will include precise definitions of the physics-informed rules without learned parameters. revision: yes
-
Referee: [§4.2] While ablations show each structural level contributes non-redundant information, they do not include controls that replace the deterministic operators with random or fully learned alternatives; such tests are needed to confirm that the performance derives from the physics-informed hierarchy rather than the general multiscale structure.
Authors: This is a fair point to isolate the specific benefit of the physics-informed deterministic operators. We will add new ablation experiments in Section 4.2, including variants that replace the deterministic operators with (i) random assignments and (ii) fully learned (parameterized) alternatives while keeping the multiscale hierarchy intact. Results will be reported to demonstrate that the gains are attributable to the physics-informed design. revision: yes
Circularity Check
No circularity: model defined architecturally with deterministic operators and evaluated on external benchmarks
full rationale
The paper defines PRIME as a nested hierarchy of five structural graphs linked by deterministic, physics-informed assignment operators for bottom-up aggregation and top-down refinement. No equations, derivations, or self-citations reduce the claimed performance gains (e.g., 13.80/18.30 points on Fold splits or 84.10% on Reaction Class) to fitted parameters, self-referential inputs, or renamed known results. The operators are asserted as parameter-free and physics-grounded without task-specific learning, and results are reported via standard external benchmarks plus ablations. This constitutes a self-contained architectural proposal with independent empirical validation rather than any load-bearing circular step.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Proteins are inherently multiscale physical systems whose functional properties emerge from coordinated structural organization across multiple spatial resolutions.
- domain assumption Adjacent structural levels can be connected through deterministic, physics-informed assignment operators.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_of_bare_distinguishability echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Adjacent levels are connected through deterministic, physics-informed assignment maps π(ℓ) : V(ℓ−1) → V(ℓ), derived from known biochemical and geometric relationships rather than learned from data... A(ℓ) = (Π(ℓ))⊤ A(ℓ−1) Π(ℓ)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
PRIME... models proteins as a nested family of five physically grounded structural graphs... enabling bidirectional information exchange via bottom-up aggregation and top-down contextual refinement
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mace: Higher order equivariant message passing neural networks for fast and accurate force fields
Ilyes Batatia, David P Kovacs, Gregor Simm, Christoph Ortner, and Gábor Csányi. Mace: Higher order equivariant message passing neural networks for fast and accurate force fields. Advances in neural information processing systems, 35:11423–11436, 2022
work page 2022
-
[2]
Meshnet: Mesh neural network for 3d shape representation
Yutong Feng, Yifan Feng, Haoxuan You, Xibin Zhao, and Yue Gao. Meshnet: Mesh neural network for 3d shape representation. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 8279–8286, 2019
work page 2019
-
[3]
Jennifer Fleming, Paulyna Magana, Sreenath Nair, Maxim Tsenkov, Damian Bertoni, Ivanna Pidruchna, Marcelo Querino Lima Afonso, Adam Midlik, Urmila Paramval, Augustin Žídek, et al. Alphafold protein structure database and 3d-beacons: new data and capabilities.Journal of Molecular Biology, 437(15):168967, 2025
work page 2025
-
[4]
Pablo Gainza, Freyr Sverrisson, Frederico Monti, Emanuele Rodola, Davide Boscaini, Michael M Bronstein, and Bruno E Correia. Deciphering interaction fingerprints from protein molecular surfaces using geometric deep learning.Nature methods, 17(2):184–192, 2020
work page 2020
-
[5]
Vladimir Gligorijevi´c, P Douglas Renfrew, Tomasz Kosciolek, Julia Koehler Leman, Daniel Berenberg, Tommi Vatanen, Chris Chandler, Bryn C Taylor, Ian M Fisk, Hera Vlamakis, et al. Structure-based protein function prediction using graph convolutional networks.Nature communications, 12(1):3168, 2021
work page 2021
-
[6]
Self-supervised pre-training for protein embeddings using tertiary structures
Yuzhi Guo, Jiaxiang Wu, Hehuan Ma, and Junzhou Huang. Self-supervised pre-training for protein embeddings using tertiary structures. InProceedings of the AAAI conference on artificial intelligence, volume 36, pages 6801–6809, 2022
work page 2022
-
[7]
Simulating 500 million years of evolution with a language model.Science, 387(6736):850–858, 2025
Thomas Hayes, Roshan Rao, Halil Akin, Nicholas J Sofroniew, Deniz Oktay, Zeming Lin, Robert Verkuil, Vincent Q Tran, Jonathan Deaton, Marius Wiggert, et al. Simulating 500 million years of evolution with a language model.Science, 387(6736):850–858, 2025
work page 2025
-
[8]
Intrinsic-extrinsic convolution and pooling for learning on 3d protein structures
Pedro Hermosilla, Marco Schäfer, Matej Lang, Gloria Fackelmann, Pere-Pau Vázquez, Barbora Kozlikova, Michael Krone, Tobias Ritschel, and Timo Ropinski. Intrinsic-extrinsic convolution and pooling for learning on 3d protein structures. InInternational Conference on Learning Representations, 2021
work page 2021
-
[9]
Jie Hou, Badri Adhikari, and Jianlin Cheng. Deepsf: deep convolutional neural network for mapping protein sequences to folds.Bioinformatics, 34(8):1295–1303, 2018
work page 2018
-
[10]
Multiresolution equivariant graph variational autoencoder
Truong Son Hy and Risi Kondor. Multiresolution equivariant graph variational autoencoder. Machine Learning: Science and Technology, 4(1):015031, 2023
work page 2023
-
[11]
Arian Rokkum Jamasb, Alex Morehead, Chaitanya K. Joshi, Zuobai Zhang, Kieran Didi, Simon V Mathis, Charles Harris, Jian Tang, Jianlin Cheng, Pietro Lio, and Tom Leon Blundell. Evaluating representation learning on the protein structure universe. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[12]
Wolfgang Kabsch and Christian Sander. Dictionary of protein secondary structure: pattern recognition of hydrogen-bonded and geometrical features.Biopolymers: Original Research on Biomolecules, 22(12):2577–2637, 1983. 10
work page 1983
-
[13]
Youhan Lee, Hasun Yu, Jaemyung Lee, and Jaehoon Kim. Pre-training sequence, structure, and surface features for comprehensive protein representation learning. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[14]
Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, Robert Verkuil, Ori Kabeli, Yaniv Shmueli, et al. Evolutionary-scale prediction of atomic-level protein structure with a language model.Science, 379(6637):1123–1130, 2023
work page 2023
-
[15]
Geometry-complete perceptron networks for 3d molecular graphs.Bioinformatics, 40(2):btae087, 2024
Alex Morehead and Jianlin Cheng. Geometry-complete perceptron networks for 3d molecular graphs.Bioinformatics, 40(2):btae087, 2024
work page 2024
-
[16]
Nhat Khang Ngo, Truong Son Hy, and Risi Kondor. Multiresolution graph transformers and wavelet positional encoding for learning long-range and hierarchical structures.The Journal of Chemical Physics, 159(3), 2023
work page 2023
-
[17]
Viet Thanh Duy Nguyen and Truong Son Hy. Multimodal pretraining for unsupervised protein representation learning.Biology Methods and Protocols, 9(1):bpae043, 2024
work page 2024
-
[18]
E (n) equivariant graph neural networks
Vıctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E (n) equivariant graph neural networks. InInternational conference on machine learning, pages 9323–9332. PMLR, 2021
work page 2021
-
[19]
The PyMOL molecular graphics system, version 1.8
Schrödinger, LLC. The PyMOL molecular graphics system, version 1.8. November 2015
work page 2015
-
[20]
Kristof T Schütt, Huziel E Sauceda, P-J Kindermans, Alexandre Tkatchenko, and K-R Müller. Schnet–a deep learning architecture for molecules and materials.The Journal of chemical physics, 148(24), 2018
work page 2018
-
[21]
Meshnet++: A network with a face
Vinit Veerendraveer Singh, Shivanand Venkanna Sheshappanavar, and Chandra Kambhamettu. Meshnet++: A network with a face. InACM multimedia, pages 4883–4891, 2021
work page 2021
-
[22]
Fast end-to-end learning on protein surfaces
Freyr Sverrisson, Jean Feydy, Bruno E Correia, and Michael M Bronstein. Fast end-to-end learning on protein surfaces. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15272–15281, 2021
work page 2021
-
[23]
Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds
Nathaniel Thomas, Tess Smidt, Steven Kearnes, Lusann Yang, Li Li, Kai Kohlhoff, and Patrick Riley. Tensor field networks: Rotation-and translation-equivariant neural networks for 3d point clouds.arXiv preprint arXiv:1802.08219, 2018
work page Pith review arXiv 2018
-
[24]
E(3)-equivariant mesh neural networks
Thuan Anh Trang, Nhat Khang Ngo, Daniel T Levy, Thieu Ngoc V o, Siamak Ravanbakhsh, and Truong Son Hy. E(3)-equivariant mesh neural networks. InInternational Conference on Artificial Intelligence and Statistics, pages 748–756. PMLR, 2024
work page 2024
-
[25]
Thuan Nguyen Anh Trang, Khang Nhat Ngo, Hugo Sonnery, Thieu V o, Siamak Ravanbakhsh, and Truong Son Hy. Scalable hierarchical self-attention with learnable hierarchy for long-range interactions.Transactions on Machine Learning Research, 2024
work page 2024
-
[26]
Yeji Wang, Shuo Wu, Yanwen Duan, and Yong Huang. A point cloud-based deep learning strat- egy for protein–ligand binding affinity prediction.Briefings in bioinformatics, 23(1):bbab474, 2022
work page 2022
-
[27]
Surface-based multimodal protein–ligand binding affinity prediction
Shiyu Xu, Lian Shen, Menglong Zhang, Changzhi Jiang, Xinyi Zhang, Yanni Xu, Juan Liu, and Xiangrong Liu. Surface-based multimodal protein–ligand binding affinity prediction. Bioinformatics, 40(7):btae413, 2024
work page 2024
-
[28]
Protein representation learning by geometric structure pretraining
Zuobai Zhang, Minghao Xu, Arian Rokkum Jamasb, Vijil Chenthamarakshan, Aurelie Lozano, Payel Das, and Jian Tang. Protein representation learning by geometric structure pretraining. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[29]
Open3D: A Modern Library for 3D Data Processing
Qian-Yi Zhou, Jaesik Park, and Vladlen Koltun. Open3d: A modern library for 3d data processing.arXiv preprint arXiv:1801.09847, 2018. 11 A Implementation Details Model Architecture.PRIME is implemented in PyTorch. All levels are projected to a shared hidden dimension of d= 128 via level-specific linear transformations, and the hierarchical GNN consists of...
work page internal anchor Pith review arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.