Recognition: unknown
Stability and Generalization for Decentralized Markov SGD
Pith reviewed 2026-05-10 15:49 UTC · model grok-4.3
The pith
Stability analysis produces non-asymptotic generalization bounds for decentralized SGD and SGDA under Markov chain sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
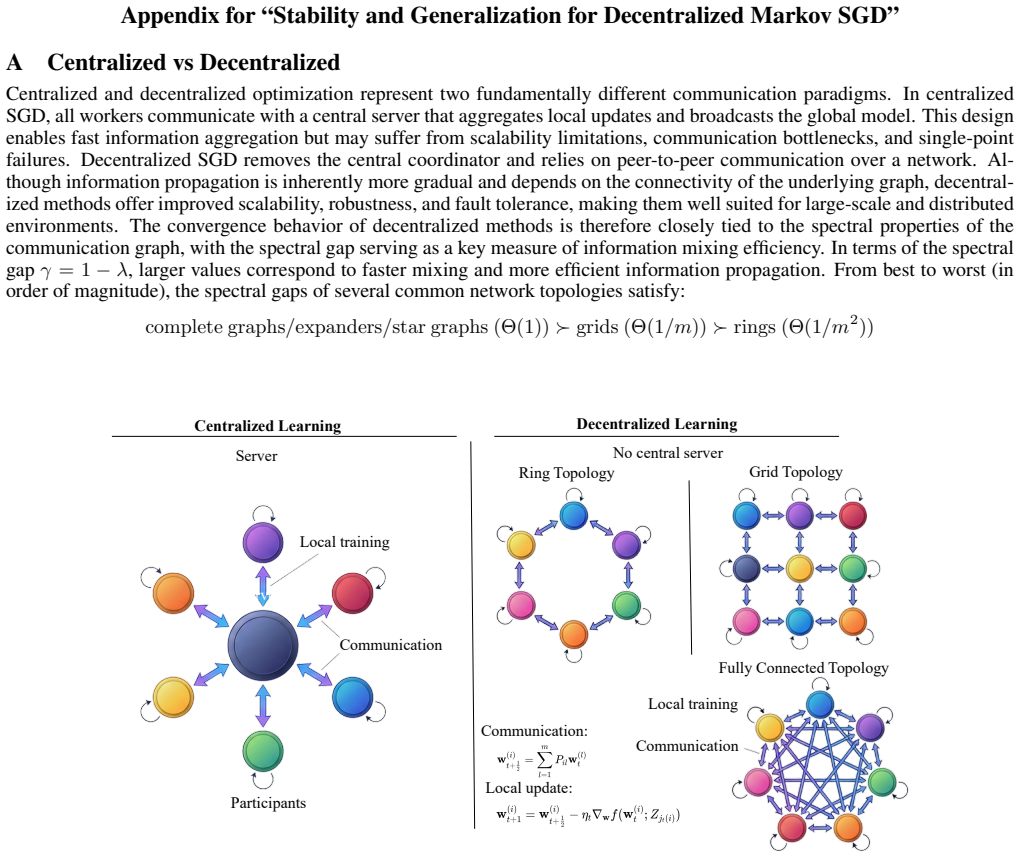
The authors establish non-asymptotic generalization bounds for decentralized stochastic gradient descent and stochastic gradient descent ascent when data arrives from a Markov chain. The bounds are obtained by extending the stability framework so that the effects of Markovian dependence and decentralized averaging enter through the chain's mixing rate and the network's topology; the resulting expressions recover prior centralized Markov SGD results as a special case.
What carries the argument
Stability-based framework that measures how Markov dependence and network averaging jointly control the generalization gap.
If this is right
- The same stability argument supplies bounds for both standard SGD and its minimax SGDA variant.
- Generalization error scales explicitly with the Markov chain's mixing time.
- Network topology enters the bound through its mixing or connectivity properties.
- The bounds reduce to existing centralized Markov SGD results when the network becomes fully connected.
Where Pith is reading between the lines
- The explicit dependence on mixing time and topology may guide how often to communicate in distributed systems that process temporally correlated streams.
- Varying the graph spectral gap while holding other factors fixed would test how tightly the bounds track practical performance.
- The framework could extend to asynchronous or delayed-update variants if stability can still be tracked under irregular communication.
Load-bearing premise
The iterates produced by the decentralized Markov updates remain sufficiently stable that their deviation from the population risk can be bounded by quantities involving the mixing time and graph connectivity.
What would settle it
A concrete counter-example would be a slowly mixing Markov chain on a sparsely connected graph for which the measured generalization gap on held-out data grows faster than the derived bound predicts once the training set size exceeds the mixing and communication scales.
Figures
read the original abstract
Stochastic gradient methods are central to large-scale learning, yet their generalization theory typically relies on independent sampling assumptions. In many practical applications, data are generated by Markov chains and learning is performed in a decentralized manner, which introduces significant analytical challenges. In this work, we investigate the stability and generalization of decentralized stochastic gradient descent (SGD) and stochastic gradient descent ascent (SGDA) under Markov chain sampling. Leveraging a stability-based framework, we characterize how Markovian dependence and decentralized communication jointly influence generalization behavior. Our analysis captures the effects of network topology, Markov chain mixing properties, and primal-dual dynamics. We establish non-asymptotic generalization bounds for both algorithms, extending existing results on Markov stochastic gradient methods to decentralized and minimax settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a stability-based analysis for the generalization of decentralized SGD and SGDA when training data are generated by a Markov chain. It derives non-asymptotic bounds that incorporate the network topology (via the weight matrix), the Markov chain's mixing properties, and the primal-dual dynamics in the minimax case, extending prior results on Markov SGD to the joint decentralized setting.
Significance. If the claimed bounds are valid, the work provides a useful extension of stability arguments to realistic distributed learning scenarios with temporally dependent data. The explicit dependence on spectral gap and mixing time in the final expressions would be a concrete advance over separate treatments of Markovian or decentralized SGD.
major comments (1)
- [Main stability theorem and its proof] The central stability recursion must control the interaction between the Markov mixing window and the number of decentralized communication rounds performed inside that window. If the proof only adds the separate contraction factors from the transition kernel and the graph Laplacian without an explicit cross-term bound, the claimed non-asymptotic rates do not follow under standard assumptions on the kernel and weight matrix. This issue is load-bearing for the main generalization theorems.
minor comments (1)
- [Preliminaries] Notation for the consensus error and the stability parameter should be introduced with explicit dependence on the iteration index to make the recursion transparent.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for identifying a key technical point in the stability analysis. We address the major comment below and are prepared to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Main stability theorem and its proof] The central stability recursion must control the interaction between the Markov mixing window and the number of decentralized communication rounds performed inside that window. If the proof only adds the separate contraction factors from the transition kernel and the graph Laplacian without an explicit cross-term bound, the claimed non-asymptotic rates do not follow under standard assumptions on the kernel and weight matrix. This issue is load-bearing for the main generalization theorems.
Authors: We appreciate the referee highlighting this critical requirement. In the proof of the central stability result (Theorem 3.1 and its extension to SGDA in Theorem 4.1), the recursion is constructed by analyzing the parameter difference over a mixing window of length tau, where tau is selected proportionally to the mixing time of the Markov kernel. Within each such window, at most tau decentralized averaging steps occur. We do not merely add independent contraction factors; instead, we derive an explicit cross-term bound by applying the triangle inequality to the composed operator (Markov transition followed by weighted averaging). The cross term is controlled via the joint Lipschitz constant of the gradient and the fact that both the Markov kernel (contraction rho < 1) and the graph operator (spectral gap lambda) are contractive in expectation. This yields an additive error of order O(tau * max(rho, 1-lambda)^t) that is absorbed into the geometric series, producing the stated non-asymptotic rates under the standard assumptions (bounded gradients, Lipschitz continuity, and irreducible aperiodic kernel). The derivation appears in Appendix B, equations (B.12)-(B.19). We agree that making the cross-term handling more prominent would improve clarity and will add a dedicated remark and a short lemma isolating this bound in the revised version. revision: partial
Circularity Check
No significant circularity; derivation extends stability framework independently
full rationale
The paper applies a stability-based framework to derive non-asymptotic generalization bounds for decentralized Markov SGD and SGDA. The provided abstract and context describe characterizing joint effects of Markovian dependence, network topology, and primal-dual dynamics without any reduction of predictions to fitted inputs, self-definitional quantities, or load-bearing self-citations. No equations or steps are shown that rename known results or smuggle ansatzes via prior author work. The central claims appear derived from adapting existing stability arguments to the combined setting, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Markov chain possesses finite mixing time that can be quantified
- domain assumption Decentralized communication occurs over a fixed connected network whose topology affects convergence
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning (ICML) , pages=
Stability and generalization of stochastic gradient methods for minimax problems , author=. International Conference on Machine Learning (ICML) , pages=. 2021 , organization=
2021
-
[2]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Simple stochastic and online gradient descent algorithms for pairwise learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[3]
Generalization error analysis for Attack-Free and Byzantine-Resilient decentralized learning with data heterogeneity , author=. 2506.09438 , archivePrefix=
-
[4]
International Conference on World Wide Web (WWW) , pages=
A contextual-bandit approach to personalized news article recommendation , author=. International Conference on World Wide Web (WWW) , pages=
-
[5]
Advances in Neural Information Processing Systems , volume=
Generative adversarial nets , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Towards Deep Learning Models Resistant to Adversarial Attacks
Towards deep learning models resistant to adversarial attacks , author=. 1706.06083 , archivePrefix=
work page internal anchor Pith review arXiv
-
[7]
Convergence rates of accelerated markov gradient descent with applications in reinforcement learning , author=. 2002.02873 , archivePrefix=
-
[8]
IEEE Transactions on Signal Processing , volume=
Walkman: A communication-efficient random-walk algorithm for decentralized optimization , author=. IEEE Transactions on Signal Processing , volume=. 2020 , publisher=
2020
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Multi-agent reinforcement learning via double averaging primal-dual optimization , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[10]
IEEE Transactions on Signal Processing , volume=
Dictionary learning over distributed models , author=. IEEE Transactions on Signal Processing , volume=. 2014 , publisher=
2014
-
[11]
International Conference on Machine Learning , pages=
Adaptive random walk gradient descent for decentralized optimization , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[12]
IEEE Transactions on Automatic control , volume=
Dual averaging for distributed optimization: Convergence analysis and network scaling , author=. IEEE Transactions on Automatic control , volume=. 2011 , publisher=
2011
-
[13]
SIAM Journal on Optimization , volume=
A randomized incremental subgradient method for distributed optimization in networked systems , author=. SIAM Journal on Optimization , volume=. 2010 , publisher=
2010
-
[14]
SIAM Journal on Optimization , volume=
Incremental stochastic subgradient algorithms for convex optimization , author=. SIAM Journal on Optimization , volume=. 2009 , publisher=
2009
-
[15]
IEEE Conference on Decision and Control and European Control Conference , pages=
Asymptotic bias of stochastic gradient search , author=. IEEE Conference on Decision and Control and European Control Conference , pages=. 2011 , organization=
2011
-
[16]
SIAM Journal on Optimization , volume=
Ergodic mirror descent , author=. SIAM Journal on Optimization , volume=. 2012 , publisher=
2012
-
[17]
IEEE Transactions on Automatic Control , volume=
Finite-time analysis of markov gradient descent , author=. IEEE Transactions on Automatic Control , volume=. 2022 , publisher=
2022
-
[18]
Advances in Neural Information Processing Systems (NeuIPS) , volume=
What is a good metric to study generalization of minimax learners? , author=. Advances in Neural Information Processing Systems (NeuIPS) , volume=
-
[19]
IEEE Transactions on Signal Processing , volume=
Incremental adaptive strategies over distributed networks , author=. IEEE Transactions on Signal Processing , volume=. 2007 , publisher=
2007
-
[20]
Linearly convergent asynchronous distributed admm via markov sampling , author=. 1810.05067 , archivePrefix=
-
[21]
Unified optimal analysis of the (stochastic) gradient method , author=. 1907.04232 , archivePrefix=
-
[22]
International Conference on Machine Learning (ICML) , pages=
Train simultaneously, generalize better: Stability of gradient-based minimax learners , author=. International Conference on Machine Learning (ICML) , pages=. 2021 , organization=
2021
-
[23]
SIAM journal on control and optimization , volume=
Monotone operators and the proximal point algorithm , author=. SIAM journal on control and optimization , volume=. 1976 , publisher=
1976
-
[24]
International Conference on Machine Learning (ICML) , year=
Stability and generalization analysis of decentralized SGD: sharper bounds beyond lipschitzness and smoothness , author=. International Conference on Machine Learning (ICML) , year=
-
[25]
SIAM Journal on optimization , volume=
Robust stochastic approximation approach to stochastic programming , author=. SIAM Journal on optimization , volume=. 2009 , publisher=
2009
-
[26]
International Conference on Artificial Intelligence and Statistics , pages=
Generalization bounds of nonconvex-(strongly)-concave stochastic minimax optimization , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[27]
Mathematics of Operations Research , volume=
Graphical convergence of subgradients in nonconvex optimization and learning , author=. Mathematics of Operations Research , volume=
-
[28]
The Twelfth International Conference on Learning Representations , year=
General stability analysis for zeroth-order optimization algorithms , author=. The Twelfth International Conference on Learning Representations , year=
-
[29]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Stability and Generalization of Zeroth-Order Decentralized Stochastic Gradient Descent with Changing Topology , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[30]
Advances in Neural Information Processing Systems (NeuIPS) , volume=
On the loss landscape of adversarial training: Identifying challenges and how to overcome them , author=. Advances in Neural Information Processing Systems (NeuIPS) , volume=
-
[31]
Neural Networks , volume=
Data-dependent stability analysis of adversarial training , author=. Neural Networks , volume=. 2025 , publisher=
2025
-
[32]
Advances in Neural Information Processing Systems (NeuIPS) , volume=
Stability analysis and generalization bounds of adversarial training , author=. Advances in Neural Information Processing Systems (NeuIPS) , volume=
-
[33]
arXiv preprint arXiv:1808.07217 , year=
Don't use large mini-batches, use local sgd , author=. arXiv preprint arXiv:1808.07217 , year=
-
[34]
2024 , journal=
On the generalization of stochastic gradient descent with momentum , author=. 2024 , journal=
2024
-
[35]
The Eleventh International Conference on Learning Representations (ICLR) , year=
Exponential generalization bounds with near-optimal rates for L_q -stable algorithms , author=. The Eleventh International Conference on Learning Representations (ICLR) , year=
-
[36]
Advances in Neural Information Processing Systems (NeuIPS) , volume=
L_2 -Uniform stability of randomized learning algorithms: Sharper generalization bounds and confidence boosting , author=. Advances in Neural Information Processing Systems (NeuIPS) , volume=
-
[37]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[38]
SIAM Journal on Optimization , volume=
Stochastic first-and zeroth-order methods for nonconvex stochastic programming , author=. SIAM Journal on Optimization , volume=. 2013 , publisher=
2013
-
[39]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Learning rates for stochastic gradient descent with nonconvex objectives , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2021 , publisher=
2021
-
[40]
Advances in Neural Information Processing Systems (NeuIPS) , volume=
Uniform convergence of gradients for non-convex learning and optimization , author=. Advances in Neural Information Processing Systems (NeuIPS) , volume=
-
[41]
International Conference on Machine Learning (ICML) , pages=
Stability and generalization of learning algorithms that converge to global optima , author=. International Conference on Machine Learning (ICML) , pages=. 2018 , organization=
2018
-
[42]
The collected works of Wassily Hoeffding , pages=
Probability inequalities for sums of bounded random variables , author=. The collected works of Wassily Hoeffding , pages=. 1994 , publisher=
1994
-
[43]
SIAM Journal on Optimization , volume=
Achieving geometric convergence for distributed optimization over time-varying graphs , author=. SIAM Journal on Optimization , volume=. 2017 , publisher=
2017
-
[44]
Linear convergence of gradient and proximal-gradient methods under the polyak-
Karimi, Hamed and Nutini, Julie and Schmidt, Mark , booktitle=. Linear convergence of gradient and proximal-gradient methods under the polyak-. 2016 , organization=
2016
-
[45]
International Conference on Machine Learning (ICML) , pages=
A unified theory of decentralized sgd with changing topology and local updates , author=. International Conference on Machine Learning (ICML) , pages=. 2020 , organization=
2020
-
[46]
International Conference on Artificial Intelligence and Statistics , pages=
Refined convergence and topology learning for decentralized sgd with heterogeneous data , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
2023
-
[47]
Journal of Machine Learning Research , volume=
Removing data heterogeneity influence enhances network topology dependence of decentralized sgd , author=. Journal of Machine Learning Research , volume=
-
[48]
SIAM Journal on Optimization , volume=
Extra: An exact first-order algorithm for decentralized consensus optimization , author=. SIAM Journal on Optimization , volume=. 2015 , publisher=
2015
-
[49]
SIAM Journal on Optimization , volume=
On the convergence of decentralized gradient descent , author=. SIAM Journal on Optimization , volume=. 2016 , publisher=
2016
-
[50]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Towards stability and generalization bounds in decentralized minibatch stochastic gradient descent , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[51]
Advances in Neural Information Processing Systems (NeuIPS) , volume=
Stability and generalization of the decentralized stochastic gradient descent ascent algorithm , author=. Advances in Neural Information Processing Systems (NeuIPS) , volume=
-
[52]
Applied and Computational Harmonic Analysis , volume=
High-probability generalization bounds for pointwise uniformly stable algorithms , author=. Applied and Computational Harmonic Analysis , volume=
-
[53]
International Conference on Learning Representations (ICLR) , year=
Minibatch vs local SGD with shuffling: Tight convergence bounds and beyond , author=. International Conference on Learning Representations (ICLR) , year=
-
[54]
International Conference on Machine Learning (ICML) , pages=
Data-dependent stability of stochastic gradient descent , author=. International Conference on Machine Learning (ICML) , pages=
-
[55]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Zeroth-order method for distributed optimization with approximate projections , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=
-
[56]
International Conference on Wireless Communications and Signal Processing (WCSP) , pages=
Communication-efficient decentralized zeroth-order method on heterogeneous data , author=. International Conference on Wireless Communications and Signal Processing (WCSP) , pages=
-
[57]
IEEE Transactions on Signal Processing , volume=
Communication-efficient stochastic zeroth-order optimization for federated learning , author=. IEEE Transactions on Signal Processing , volume=
-
[58]
Foundations of Computational Mathematics , volume=
Random gradient-free minimization of convex functions , author=. Foundations of Computational Mathematics , volume=
-
[59]
IEEE Transactions on Information Theory , volume=
Optimal rates for zero-order convex optimization: The power of two function evaluations , author=. IEEE Transactions on Information Theory , volume=
-
[60]
Journal of Machine Learning Research , volume=
An optimal algorithm for bandit and zero-order convex optimization with two-point feedback , author=. Journal of Machine Learning Research , volume=
-
[61]
Conference on Learning Theory (COLT) , pages=
Highly-smooth zero-th order online optimization , author=. Conference on Learning Theory (COLT) , pages=
-
[62]
The Annals of Mathematical Statistics , volume=
A relationship between arbitrary positive matrices and doubly stochastic matrices , author=. The Annals of Mathematical Statistics , volume=
-
[63]
Pacific Journal of Mathematics , volume=
Concerning nonnegative matrices and doubly stochastic matrices , author=. Pacific Journal of Mathematics , volume=
-
[64]
Stability and Generalization for Minibatch SGD and Local SGD , author=. 2310.01139 , archivePrefix=
-
[65]
Decentralized stochastic gradient tracking for non-convex empirical risk minimization , author=. 1909.02712 , archivePrefix=
-
[66]
IEEE Transactions on Signal Processing , volume=
An improved convergence analysis for decentralized online stochastic non-convex optimization , author=. IEEE Transactions on Signal Processing , volume=
-
[67]
Communication-efficient local decentralized SGD methods , author=. 1910.09126 , archivePrefix=
-
[68]
Decentralized SGD with asynchronous, local and quantized updates , author=
-
[69]
International Conference on Machine Learning (ICML) , pages=
Decentralized training over decentralized data , author=. International Conference on Machine Learning (ICML) , pages=
-
[70]
Advances in Neural Information Processing Systems (NeurIPS) , pages=
Relaysum for decentralized deep learning on heterogeneous data , author=. Advances in Neural Information Processing Systems (NeurIPS) , pages=
-
[71]
Advances in Neural Information Processing Systems (NeurIPS) , pages=
Random reshuffling: Simple analysis with vast improvements , author=. Advances in Neural Information Processing Systems (NeurIPS) , pages=
-
[72]
IEEE International Conference on Big Data , pages=
Consensus optimization with delayed and stochastic gradients on decentralized networks , author=. IEEE International Conference on Big Data , pages=
-
[73]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
A (DP)2 SGD: Asynchronous decentralized parallel stochastic gradient descent With differential privacy , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[74]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Asynchronous decentralized SGD with quantized and local updates , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[75]
Select without fear: almost all mini-batch schedules generalize optimally , author=. 2305.02247 , archivePrefix=
-
[76]
Advances in Neural Information Processing Systems(NeurIPS) , year=
Convergence rates of inexact proximal-gradient methods for convex optimization , author=. Advances in Neural Information Processing Systems(NeurIPS) , year=
-
[77]
Advances in Neural Information Processing Systems(NeurIPS) , pages=
Better mini-batch algorithms via accelerated gradient methods , author=. Advances in Neural Information Processing Systems(NeurIPS) , pages=
-
[78]
, author=
Optimal Distributed Online Prediction Using Mini-Batches. , author=. Journal of Machine Learning Research , volume=
-
[79]
International Conference on Knowledge Discovery and Data Mining , pages=
Efficient mini-batch training for stochastic optimization , author=. International Conference on Knowledge Discovery and Data Mining , pages=
-
[80]
Annual Allerton Conference on Communication, Control, and Computing , pages=
Distributed stochastic optimization and learning , author=. Annual Allerton Conference on Communication, Control, and Computing , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.