Recognition: 3 theorem links
· Lean TheoremCoAction: Cross-task Correlation-aware Pareto Set Learning
Pith reviewed 2026-05-08 19:28 UTC · model grok-4.3
The pith
One neural network can learn Pareto optimal solutions for multiple multi-objective tasks at once by capturing their correlations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
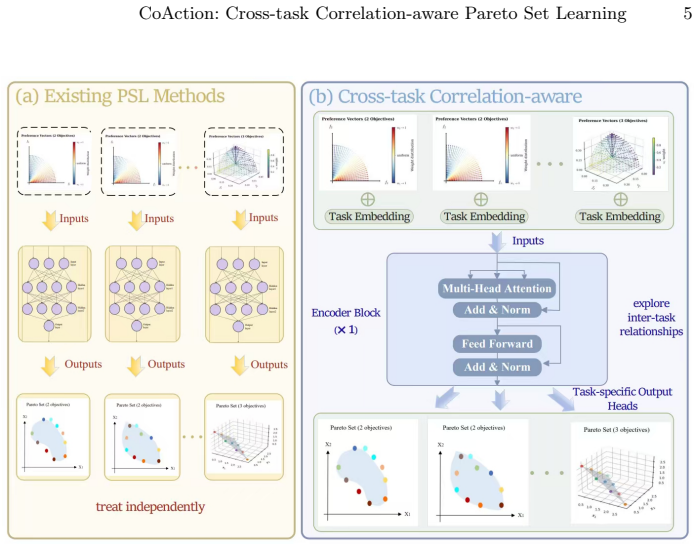
By giving each task a distinct embedding and routing all tasks through one transformer encoder, the model uses self-attention to extract cross-task dependencies while preserving task identity, allowing a single set of weights to produce Pareto sets for every task simultaneously.
What carries the argument
Task-aware transformer encoder that receives task-specific embedding vectors and uses self-attention to model inter-task correlations.
If this is right
- Only one model needs to be trained and stored instead of one per task.
- Solution quality on each individual task can rise because information from related tasks is reused.
- The same architecture works across synthetic benchmarks and practical problems without task-specific redesigns.
- Metrics of set quality (hypervolume, range, sparsity) improve under the joint training regime.
Where Pith is reading between the lines
- The method could be tested on sequences of tasks that arrive over time to check whether the transformer can incorporate new tasks without retraining from scratch.
- If some task pairs have conflicting objectives, adding a lightweight correlation gate before the attention layers might prevent negative transfer.
- The embedding-plus-transformer pattern may transfer to other multi-task settings where the output is a set rather than a single vector, such as multi-task reinforcement learning with vector rewards.
Load-bearing premise
Correlations between tasks exist and can be extracted by embeddings plus self-attention in a way that produces useful sharing rather than interference.
What would settle it
Run the same multi-task test suites with single-task baselines and CoAction; if CoAction does not improve hypervolume on at least half the tasks while keeping or reducing total parameters, the benefit of joint learning is refuted.
Figures




read the original abstract
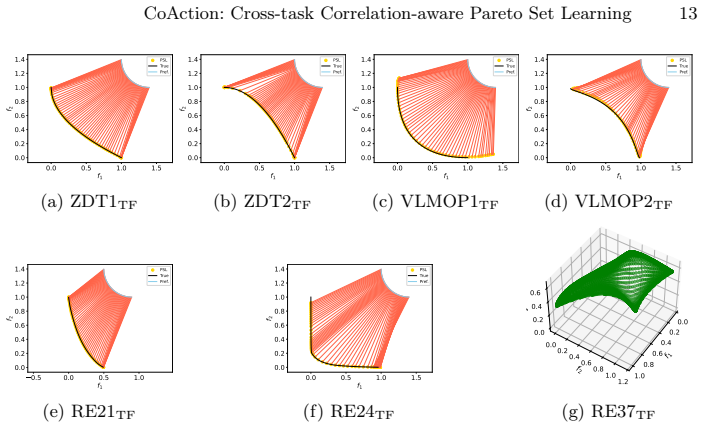
Pareto set learning (PSL) is an emerging paradigm in multi-objective optimization that trains neural networks to map preference vectors to Pareto optimal solutions. However, existing PSL methods primarily focus on solving a single multi-objective optimization problem at a time. This limitation not only increases computational costs in multi-objective multitask optimization scenarios by requiring a separate model for each task, but also fails to exploit the inter-task correlations across tasks. To address this, we propose a Cross-tAsk correlation-aware Pareto Set Learning (CoAction) framework, which leverages task-aware transformer to handle multiple tasks simultaneously. Specifically, by assigning task-specific embedding vectors to individual tasks, the model effectively distinguishes between tasks while facilitating knowledge sharing among them. We utilize a Transformer encoder as the backbone architecture to leverage its self-attention mechanism for capturing complex task dependencies. The proposed approach is evaluated on comprehensive multitask test suites covering both benchmark problems and real-world applications, demonstrating effectiveness and competitive performance in Hypervolume, Range, and Sparsity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoAction, a Cross-tAsk correlation-aware Pareto Set Learning framework for multi-task multi-objective optimization. It assigns task-specific embedding vectors to distinguish tasks while using a Transformer encoder backbone and self-attention to capture inter-task dependencies, enabling a single model to handle multiple PSL tasks simultaneously instead of training separate models. The approach is evaluated on multitask benchmark suites and real-world applications, with claims of competitive performance in Hypervolume, Range, and Sparsity metrics.
Significance. If the results hold after addressing validation gaps, the work could reduce computational overhead in multi-task MO settings and demonstrate a practical way to leverage positive correlations via shared attention. The transformer-based design for simultaneous task handling is a natural extension of recent PSL methods and the inclusion of real-world applications strengthens applicability. However, without isolating the contribution of cross-task correlation capture, the significance for the broader field remains provisional.
major comments (2)
- [§4] §4 (Experiments): No ablation is reported that trains independent per-task PSL models on the same multitask suites and compares them directly to CoAction. This comparison is required to establish that performance gains in HV/Range/Sparsity derive from the task-aware embeddings and self-attention mechanism rather than from increased capacity or optimization differences.
- [§3.2] §3.2 (Method, task embeddings and Transformer encoder): The manuscript asserts that task-specific embeddings plus shared self-attention capture useful inter-task correlations without negative transfer, yet provides no quantification of task similarity in the chosen benchmarks, no attention-weight analysis, and no per-task performance breakdown showing absence of negative transfer on any task.
minor comments (2)
- The abstract states competitive performance but supplies no numerical values, baseline names, or error bars; adding one or two representative numbers would improve clarity.
- Notation for the task embedding vectors and the precise form of the multi-task loss should be defined earlier and used consistently in the method section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects that will strengthen the presentation of our contributions. We agree that additional experiments and analyses are warranted to better isolate the benefits of cross-task correlation capture. We will revise the paper to incorporate the suggested ablations and supporting analyses. Below we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): No ablation is reported that trains independent per-task PSL models on the same multitask suites and compares them directly to CoAction. This comparison is required to establish that performance gains in HV/Range/Sparsity derive from the task-aware embeddings and self-attention mechanism rather than from increased capacity or optimization differences.
Authors: We agree that a direct comparison to independently trained per-task models on the same multitask suites would more clearly isolate the contribution of the shared Transformer encoder and task embeddings. In the revised manuscript we will add this ablation study: separate PSL models (using the identical backbone architecture) will be trained for each task on the exact same benchmark suites, and we will report side-by-side Hypervolume, Range, and Sparsity results against CoAction. This will clarify whether observed gains arise from cross-task knowledge sharing rather than capacity or optimization differences. revision: yes
-
Referee: [§3.2] §3.2 (Method, task embeddings and Transformer encoder): The manuscript asserts that task-specific embeddings plus shared self-attention capture useful inter-task correlations without negative transfer, yet provides no quantification of task similarity in the chosen benchmarks, no attention-weight analysis, and no per-task performance breakdown showing absence of negative transfer on any task.
Authors: We acknowledge that the original submission does not provide explicit quantification or diagnostic analyses to support the claims of beneficial inter-task correlation capture and absence of negative transfer. In the revision we will add: (1) quantitative measures of task similarity (e.g., pairwise correlations of objective values or Pareto-front distributions across the chosen benchmarks), (2) attention-weight heatmaps and summary statistics from the Transformer encoder to illustrate learned inter-task dependencies, and (3) per-task metric breakdowns (HV, Range, Sparsity) to demonstrate that no task suffers performance degradation relative to its single-task counterpart. These additions will substantiate the design choices. revision: yes
Circularity Check
No circularity: new architecture evaluated on external benchmarks
full rationale
The paper proposes CoAction as a novel task-aware transformer architecture for multi-task Pareto set learning, using task-specific embeddings and self-attention to capture correlations. This design is not defined in terms of its own outputs or fitted parameters; the method is presented as an independent proposal and evaluated on separate benchmark suites and real-world applications for metrics like Hypervolume. No derivation step reduces to self-definition, renamed predictions, or load-bearing self-citations. The central claims rest on architectural choices and external empirical results rather than tautological reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-objective optimization using evolutionary algorithms
Kalyanmoy Deb. Multi-objective optimization using evolutionary algorithms. In Wiley-Interscience series in systems and optimization, 2001
2001
-
[2]
Mardle and K
S. Mardle and K. M. Miettinen. Nonlinear multiobjective optimization.Journal of the Operational Research Society, 51(2):246, 1999
1999
-
[3]
Comparison of multiobjective evolutionary algorithms: Empirical results.Evolutionary Computation, 8(2):173– 195, 2000
Eckart Zitzler, Kalyanmoy Deb, and Lothar Thiele. Comparison of multiobjective evolutionary algorithms: Empirical results.Evolutionary Computation, 8(2):173– 195, 2000
2000
-
[4]
Meyarivan
Kalyanmoy Deb, Samir Agrawal, Amrit Pratap, and T. Meyarivan. A fast and elitist multiobjective genetic algorithm: NSGA-II.IEEE Trans. Evol. Comput., 6:182–197, 2002. 20 X. Chen et al
2002
-
[5]
Igel, Nikolaus Hansen, and Stefan Roth
C. Igel, Nikolaus Hansen, and Stefan Roth. Covariance matrix adaptation for multi-objective optimization.Evolutionary Computation, 15:1–28, 2007
2007
-
[6]
Sms-emoa: Multiobjec- tive selection based on dominated hypervolume.European Journal of Operational Research, 181(3):1653–1669, 2007
Nicola Beume, Boris Naujoks, and Michael Emmerich. Sms-emoa: Multiobjec- tive selection based on dominated hypervolume.European Journal of Operational Research, 181(3):1653–1669, 2007
2007
-
[7]
Moea/d: A multiobjective evolutionary algorithm based on decomposition.IEEE Transactions on Evolutionary Computation, 11:712–731, 2007
Qingfu Zhang and Hui Li. Moea/d: A multiobjective evolutionary algorithm based on decomposition.IEEE Transactions on Evolutionary Computation, 11:712–731, 2007
2007
-
[8]
Controllable pareto multi-task learning.ArXiv, abs/2010.06313, 2020
Xi Lin, Zhiyuan Yang, Qingfu Zhang, and Sam Tak Wu Kwong. Controllable pareto multi-task learning.ArXiv, abs/2010.06313, 2020
-
[9]
Multitask learning.Machine Learning, 1997
R Caruana. Multitask learning.Machine Learning, 1997
1997
-
[10]
A survey on multi-task learning.IEEE Transactions on Knowledge and Data Engineering, 34(12):5586–5609, 2022
Yu Zhang and Qiang Yang. A survey on multi-task learning.IEEE Transactions on Knowledge and Data Engineering, 34(12):5586–5609, 2022
2022
-
[11]
Multi-task learning as multi-objective optimiza- tion
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimiza- tion. InNeural Information Processing Systems, 2018
2018
-
[12]
Hypervolume maximization: A geometric view of pareto set learning.Advances in Neural Infor- mation Processing Systems 36, 2023
Xiao-Yan Zhang, Xi Lin, Bo Xue, Yifan Chen, and Qingfu Zhang. Hypervolume maximization: A geometric view of pareto set learning.Advances in Neural Infor- mation Processing Systems 36, 2023
2023
-
[13]
Pareto set learning for expensive multi-objective optimization
Xi Lin, Zhiyuan Yang, Xiaoyuan Zhang, and Qingfu Zhang. Pareto set learning for expensive multi-objective optimization. InAdvances in Neural Information Processing Systems, volume 35, pages 19231–19247, 2022
2022
-
[14]
Pareto set learning for neural multi- objective combinatorial optimization
Xi Lin, Zhiyuan Yang, and Qingfu Zhang. Pareto set learning for neural multi- objective combinatorial optimization. InInternational Conference on Learning Representations, 2022
2022
-
[15]
Bert: Pre- training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre- training of deep bidirectional transformers for language understanding. InNorth American Chapter of the Association for Computational Linguistics, 2019
2019
-
[16]
Gomez, Lukasz Kaiser, and I
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and I. Polosukhin. Attention is all you need. Neural Information Processing Systems, 30, 2017
2017
-
[17]
Multi-task learning for dense prediction tasks: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3614–3633, 2022
Simon Vandenhende, Stamatios Georgoulis, Wouter Van Gansbeke, Marc Proes- mans, Dengxin Dai, and Luc Van Gool. Multi-task learning for dense prediction tasks: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3614–3633, 2022
2022
-
[18]
A model of inductive bias learning.Journal of Artificial Intelli- gence Research, 12:149–198, 2000
Jonathan Baxter. A model of inductive bias learning.Journal of Artificial Intelli- gence Research, 12:149–198, 2000
2000
-
[19]
Cross- stitch networks for multi-task learning
Ishan Misra, Abhinav Shrivastava, Abhinav Gupta, and Martial Hebert. Cross- stitch networks for multi-task learning. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3994–4003, 2016
2016
-
[20]
Learning the pareto front with hypernetworks
Aviv Navon, Aviv Shamsian, Ethan Fetaya, and Gal Chechik. Learning the pareto front with hypernetworks. InInternational Conference on Learning Representa- tions, 2021
2021
-
[21]
Conflict-averse gradient descent for multi-task learning.ArXiv, abs/2110.14048, 2021
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-averse gradient descent for multi-task learning.ArXiv, abs/2110.14048, 2021
-
[22]
Multi-task deep neural networks for natural language understanding
Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jianfeng Gao. Multi-task deep neural networks for natural language understanding. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4487– 4496, 2019
2019
-
[23]
Taskprompter: Spatial-channel multi-task prompting for dense scene understanding
Hanrong Ye and Dan Xu. Taskprompter: Spatial-channel multi-task prompting for dense scene understanding. InInternational Conference on Learning Representa- tions, 2023. CoAction: Cross-task Correlation-aware Pareto Set Learning 21
2023
-
[24]
Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A
James Kirkpatrick, Razvan Pascanu, Neil C. Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114:3521 –...
2016
-
[25]
Baniata, Sangwoo Kang, and Isaac
Laith H. Baniata, Sangwoo Kang, and Isaac. K. E. Ampomah. A reverse positional encoding multi-head attention-based neural machine translation model for arabic dialects.Mathematics, 2022
2022
-
[26]
On layer normal- ization in the transformer architecture
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. On layer normal- ization in the transformer architecture. InProceedings of the 37th International Conference on Machine Learning, volume 119, pages 10524–10533, 2020
2020
-
[27]
The road less scheduled.arXiv [cs.LG], 2024
Aaron Defazio, Xingyu Yang, Harsh Mehta, Konstantin Mishchenko, Ahmed Khaled, and Ashok Cutkosky. The road less scheduled.ArXiv, abs/2405.15682, 2024
-
[28]
Tea Tušar, Dimo Brockhoff, Nikolaus Hansen, and Anne Auger. Coco: The bi- objective black box optimization benchmarking (bbob-biobj) test suite.ArXiv, abs/1604.00359, 2016
-
[29]
Using well- understood single-objective functions in multiobjective black-box optimization test suites.Evolutionary Computation, 30(2):165–193, 2022
Dimo Brockhoff, Anne Auger, Nikolaus Hansen, and Tea Tušar. Using well- understood single-objective functions in multiobjective black-box optimization test suites.Evolutionary Computation, 30(2):165–193, 2022
2022
-
[30]
Wilcoxon
Frank. Wilcoxon. Individual comparisons by ranking methods.Biometrics, 1:196– 202, 1945
1945
-
[31]
Joaquín Derrac, Salvador García, Daniel Molina, and Francisco Herrera. A prac- tical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms.Swarm and Evolution- ary Computation, 1(1):3–18, 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.