Recognition: unknown
Towards Real-time Control of a CartPole System on a Quantum Computer
Pith reviewed 2026-05-10 15:42 UTC · model grok-4.3
The pith
A single-qubit quantum agent learns CartPole control more efficiently than classical networks while enabling lower latency on quantum hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors demonstrate that a single-qubit agent acts as an effective learning model, solving the environment in substantially fewer episodes than a comparable classical actor-critic network even when the training of the hybrid agent is restricted to use parameter-shift for its quantum circuit component. They map the inference-time trade-off between control-loop rate and measurement shot budget, finding that higher inference frequencies consistently improve performance and increasing the shot budget lowers the minimum inference frequency required to achieve near-maximal balancing. Direct command-table programming bypasses the standard high-level software stack to address the criticalbottlen
What carries the argument
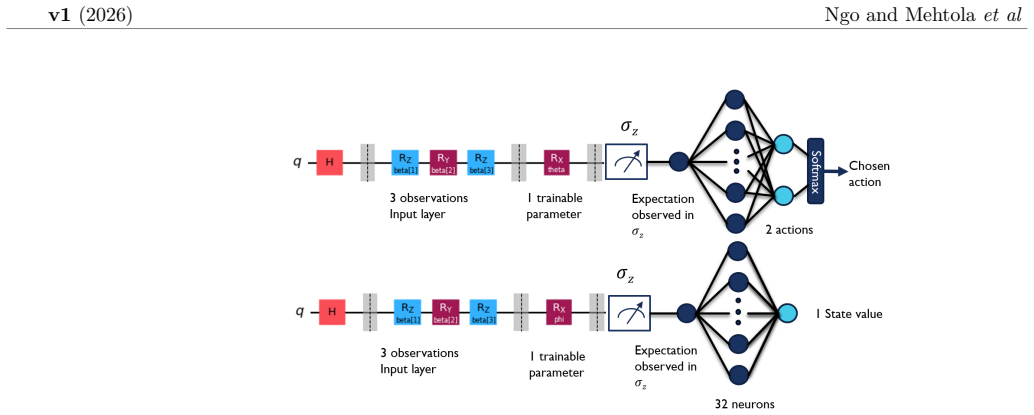
The hybrid quantum-classical reinforcement learning agent built around a single-qubit variational circuit trained with the parameter-shift rule, combined with direct hardware command table programming for low-latency inference.
If this is right
- The hybrid agent achieves better sample efficiency than classical actor-critic methods for the CartPole task.
- An optimal balance exists between shot count and inference frequency for maintaining balancing stability.
- Direct command-table programming is required to reach the control rates needed for real-time quantum-assisted control.
- These results define practical boundaries for quantum reinforcement learning in real-time hardware settings.
Where Pith is reading between the lines
- If the single-qubit efficiency holds beyond simulation, similar minimal quantum models could apply to other physical control tasks.
- Circuits designed to be invariant to initial states might further loosen the shot-frequency requirements for stable operation.
- Physical QPU deployment would test whether the observed efficiency survives real device noise and timing constraints.
- The latency-reduction technique could extend to other quantum algorithms that need frequent, fast measurements.
Load-bearing premise
The learning speed advantages observed in simulation and the latency reductions from direct programming will translate to stable real-time closed-loop performance on physical quantum processors without noise or software overheads dominating the control loop.
What would settle it
A closed-loop run on a physical superconducting QPU in which the single-qubit agent either sustains CartPole balancing for hundreds of steps at control frequencies of 10 Hz or higher with moderate shot counts or fails due to accumulated latency or noise.
Figures








read the original abstract
The application of quantum reinforcement learning (QRL) to real-time control systems faces significant challenges regarding hardware latency, noise susceptibility, and learning convergence. This work presents an end-to-end investigation of a minimal hybrid quantum-classical agent applied to the CartPole benchmark, addressing the gap between idealized simulation and execution on a physical superconducting quantum processing unit (QPU). We demonstrate that a single-qubit agent acts as an effective learning model, solving the environment in substantially fewer episodes than a comparable classical actor-critic network even when the training of the hybrid agent is restricted to use parameter-shift for its quantum circuit component. To connect learning to deployment constraints, we map the inference-time trade-off between control-loop rate and measurement shot budget to provide guidance for an eventual real-time control demonstration. The resulting performance matrices show that both inference control frequency and shot count strongly affect balancing stability: higher inference frequencies consistently improve performance, and increasing the shot budget lowers the minimum inference frequency required to achieve near-maximal balancing. These results highlight the importance of finding an optimal medium between shot count and control frequency and developing circuits that are e.g. initial-state invariant. Lastly, we address the critical bottleneck of control latency on NISQ hardware by bypassing the standard high-level software stack and programming the Zurich Instruments readout electronics directly via command tables. These results quantify some of the current boundaries of quantum-assisted control and provide a start for achieving the tens-of-hertz throughput required for real-time closed-loop control feedback.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates a minimal hybrid quantum-classical reinforcement learning agent using a single-qubit variational circuit for the CartPole benchmark. It claims that this agent solves the task in substantially fewer episodes than a classical actor-critic baseline even when restricted to parameter-shift gradients for the quantum component. The work maps inference-time trade-offs between control-loop frequency and measurement shot budget via performance matrices, and demonstrates reduced control latency by direct command-table programming of Zurich Instruments readout electronics, providing guidance toward real-time closed-loop QPU control at tens of Hz.
Significance. If the central simulation results hold, the paper offers a concrete, end-to-end case study of QRL deployment constraints on NISQ hardware. It explicitly quantifies the shot-frequency trade-off and shows a practical latency-reduction technique via command tables. These elements provide falsifiable, hardware-grounded guidance that is currently rare in the QRL literature and could inform circuit design choices such as initial-state invariance.
major comments (3)
- [Results (learning performance)] Results section on agent training: the claim that the single-qubit agent solves the environment in substantially fewer episodes than the classical actor-critic network is load-bearing for the central contribution, yet no episode counts, standard deviations, number of independent runs, or statistical comparison are reported. Without these, the performance advantage cannot be verified or reproduced.
- [Inference trade-off analysis and Hardware latency section] Inference trade-off matrices and hardware implementation: the matrices show that higher frequencies and larger shot budgets improve balancing stability, but the text does not specify whether these matrices were obtained from ideal simulation, noisy simulation, or actual QPU measurements. This distinction is critical because the subsequent claim that command-table latency reduction enables stable real-time control at tens of Hz rests on the assumption that the reported trade-offs survive realistic decoherence and readout noise.
- [Hardware implementation and conclusion] Hardware section on command-table bypass: while direct programming of the readout electronics is a positive technical step, no closed-loop timing profiles, measured control-loop rates, or end-to-end experiments incorporating QPU noise (decoherence, readout errors) are provided. The weakest assumption—that simulated advantages translate to stable physical-QPU performance—therefore remains untested and directly affects the paper’s title claim of “towards real-time control.”
minor comments (2)
- [Abstract and Results] The abstract and main text refer to “performance matrices” without indicating whether they are tables or figures; consistent labeling and captioning would improve clarity.
- [Methods] Notation for the single-qubit circuit (e.g., parameterization, measurement basis) is introduced but not cross-referenced to the classical actor-critic architecture details, making direct comparison harder to follow.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. The comments have prompted us to strengthen the statistical reporting, clarify the simulation assumptions, and better delineate the scope of our hardware results. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: Results section on agent training: the claim that the single-qubit agent solves the environment in substantially fewer episodes than the classical actor-critic network is load-bearing for the central contribution, yet no episode counts, standard deviations, number of independent runs, or statistical comparison are reported. Without these, the performance advantage cannot be verified or reproduced.
Authors: We agree that the learning-performance comparison requires explicit statistical support. In the revised manuscript we now report the mean number of episodes to solve the task for both agents, the standard deviation across 20 independent training runs, and the result of a two-sample t-test (p < 0.01). These quantities appear in the Results section and in a new summary table. revision: yes
-
Referee: Inference trade-off analysis and Hardware latency section: the matrices show that higher frequencies and larger shot budgets improve balancing stability, but the text does not specify whether these matrices were obtained from ideal simulation, noisy simulation, or actual QPU measurements. This distinction is critical because the subsequent claim that command-table latency reduction enables stable real-time control at tens of Hz rests on the assumption that the reported trade-offs survive realistic decoherence and readout noise.
Authors: The matrices were generated from ideal simulation to isolate the shot-count versus frequency trade-off. We have added an explicit statement to this effect in the revised text together with a short discussion of how realistic noise would be expected to shift the numerical thresholds while preserving the qualitative trends. The command-table latency measurements are separate hardware timings and do not rely on the simulation matrices. revision: yes
-
Referee: Hardware section on command-table bypass: while direct programming of the readout electronics is a positive technical step, no closed-loop timing profiles, measured control-loop rates, or end-to-end experiments incorporating QPU noise (decoherence, readout errors) are provided. The weakest assumption—that simulated advantages translate to stable physical-QPU performance—therefore remains untested and directly affects the paper’s title claim of “towards real-time control.”
Authors: We have inserted measured timing profiles and the achieved control-loop rate (approximately 50 Hz) obtained with the command-table implementation. A full end-to-end closed-loop demonstration on the physical QPU that includes decoherence and readout noise has not yet been performed; such an experiment requires additional integration work that lies beyond the present study. We have revised the Hardware and Conclusion sections to make this scope explicit while retaining the “towards” framing of the title. revision: partial
- Full end-to-end closed-loop control on the physical QPU that incorporates realistic decoherence and readout noise (this experiment has not been executed in the current work).
Circularity Check
No circularity: empirical demonstrations rest on direct simulation and hardware measurements
full rationale
The paper reports experimental outcomes for a hybrid single-qubit agent on CartPole, including episode counts to solve the environment under parameter-shift training, inference trade-off matrices obtained by varying control frequency and shot budget, and latency reductions from direct command-table programming on Zurich Instruments hardware. These quantities are measured or simulated explicitly rather than derived from equations that loop back to fitted parameters or self-citations. No self-definitional steps, renamed known results, or load-bearing uniqueness theorems appear; the central claims remain independently testable via replication and do not reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An introduction to quantum machine learning
Maria Schuld, Ilya Sinayskiy, and Francesco Petruccione. “An introduction to quantum machine learning”. In:Contemporary Physics56.2 (2015), pp. 172–185
2015
-
[2]
The theory of variational hybrid quantum-classical algorithms
Jarrod R McClean et al. “The theory of variational hybrid quantum-classical algorithms”. In: New Journal of Physics18.2 (2016), p. 023023
2016
-
[3]
Quantum machine learning
Jacob Biamonte et al. “Quantum machine learning”. In:Nature549.7671 (2017), pp. 195–202
2017
-
[4]
A rigorous and robust quantum speed-up in supervised machine learning
Yunchao Liu, Srinivasan Arunachalam, and Kristan Temme. “A rigorous and robust quantum speed-up in supervised machine learning”. In:Nature Physics17.9 (2021), pp. 1013–1017
2021
-
[5]
Exponential separations between classical and quantum learners
Casper Gyurik and Vedran Dunjko. “Exponential separations between classical and quantum learners”. In:arXiv preprint arXiv:2306.16028(2023)
-
[6]
Quantum computing in the NISQ era and beyond
John Preskill. “Quantum computing in the NISQ era and beyond”. In:Quantum2 (2018), p. 79
2018
-
[7]
Variational quantum algorithms
Marco Cerezo et al. “Variational quantum algorithms”. In:Nature Reviews Physics3.9 (2021), pp. 625–644
2021
-
[8]
Hybrid quantum-classical algorithms in the noisy intermediate-scale quantum era and beyond
Adam Callison and Nicholas Chancellor. “Hybrid quantum-classical algorithms in the noisy intermediate-scale quantum era and beyond”. In:Physical Review A106.1 (2022), p. 010101
2022
-
[9]
Parameterized quantum circuits as machine learning models
Marcello Benedetti et al. “Parameterized quantum circuits as machine learning models”. In: Quantum science and technology4.4 (2019), p. 043001
2019
-
[10]
Quantum machine learning in feature Hilbert spaces
Maria Schuld and Nathan Killoran. “Quantum machine learning in feature Hilbert spaces”. In:Physical review letters122.4 (2019), p. 040504
2019
-
[11]
Learning agile and dynamic motor skills for legged robots
Jemin Hwangbo et al. “Learning agile and dynamic motor skills for legged robots”. In: Science Robotics4.26 (2019), eaau5872
2019
-
[12]
Sim-to-Real: Learning Agile Locomotion For Quadruped Robots
Jie Tan et al. “Sim-to-real: Learning agile locomotion for quadruped robots”. In:arXiv preprint arXiv:1804.10332(2018)
work page Pith review arXiv 2018
-
[13]
Champion-level drone racing using deep reinforcement learning
Elia Kaufmann et al. “Champion-level drone racing using deep reinforcement learning”. In: Nature620.7976 (2023), pp. 982–987
2023
-
[14]
Learning agile robotic locomotion skills by imitating animals
Xue Bin Peng et al. “Learning agile robotic locomotion skills by imitating animals”. In:arXiv preprint arXiv:2004.00784(2020)
-
[15]
Policy gradient reinforcement learning for fast quadrupedal locomotion
Nate Kohl and Peter Stone. “Policy gradient reinforcement learning for fast quadrupedal locomotion”. In:IEEE International Conference on Robotics and Automation, 2004. Proceedings. ICRA’04. 2004. Vol. 3. IEEE. 2004, pp. 2619–2624
2004
-
[16]
David Silver et al. “A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play”. In:Science362.6419 (2018), pp. 1140–1144.doi: 10.1126/science.aar6404
-
[17]
Grandmaster level in StarCraft II using multi-agent reinforcement learning
Oriol Vinyals et al. “Grandmaster level in StarCraft II using multi-agent reinforcement learning”. en. In:Nature575.7782 (Nov. 2019), pp. 350–354
2019
-
[18]
In: 2023 IEEE/RSJ Interna- tionalConferenceonIntelligentRobotsandSystems(IROS).pp.7742–7749(2023)
Tingguang Li et al. “Learning Terrain-Adaptive Locomotion with Agile Behaviors by Imitating Animals”. In:2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 2023, pp. 339–345.doi:10.1109/IROS55552.2023.10342271
-
[19]
Quantum Reinforcement Learning
Daoyi Dong et al. “Quantum Reinforcement Learning”. In:IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics)38.5 (2008), pp. 1207–1220.doi: 10.1109/TSMCB.2008.925743
-
[20]
Quantum-enhanced machine learning
Vedran Dunjko, Jacob M Taylor, and Hans J Briegel. “Quantum-enhanced machine learning”. In:Physical review letters117.13 (2016), p. 130501
2016
-
[21]
Experimental quantum speed-up in reinforcement learning agents
Valeria Saggio et al. “Experimental quantum speed-up in reinforcement learning agents”. In: Nature591.7849 (2021), pp. 229–233
2021
-
[22]
Quantum speedup for active learning agents
Giuseppe Davide Paparo et al. “Quantum speedup for active learning agents”. In:Physical Review X4.3 (2014), p. 031002
2014
-
[23]
Quantum-accessible reinforcement learning beyond strictly epochal environments
Arne Hamann, Vedran Dunjko, and Sabine W¨ olk. “Quantum-accessible reinforcement learning beyond strictly epochal environments”. In:Quantum Machine Intelligence3.2 (2021), p. 22. 15 v1(2026) Ngo and Mehtolaet al
2021
-
[24]
Robust quantum-inspired reinforcement learning for robot navigation
Daoyi Dong et al. “Robust quantum-inspired reinforcement learning for robot navigation”. In:IEEE/ASME transactions on mechatronics17.1 (2010), pp. 86–97
2010
-
[25]
Variational quantum circuits for deep reinforcement learning
Samuel Yen-Chi Chen et al. “Variational quantum circuits for deep reinforcement learning”. In:IEEE access8 (2020), pp. 141007–141024
2020
-
[26]
Reinforcement learning with quantum variational circuit
Owen Lockwood and Mei Si. “Reinforcement learning with quantum variational circuit”. In: Proceedings of the AAAI conference on artificial intelligence and interactive digital entertainment. Vol. 16. 1. 2020, pp. 245–251
2020
-
[27]
Parametrized quantum policies for reinforcement learning
Sofiene Jerbi et al. “Parametrized quantum policies for reinforcement learning”. In:Advances in Neural Information Processing Systems34 (2021), pp. 28362–28375
2021
-
[28]
Quantum agents in the gym: a variational quantum algorithm for deep q-learning
Andrea Skolik, Sofiene Jerbi, and Vedran Dunjko. “Quantum agents in the gym: a variational quantum algorithm for deep q-learning”. In:Quantum6 (2022), p. 720
2022
-
[29]
Variational quantum soft actor-critic
Qingfeng Lan. “Variational quantum soft actor-critic”. In:arXiv preprint arXiv:2112.11921 (2021)
-
[30]
Variational quantum reinforcement learning via evolutionary optimization
Samuel Yen-Chi Chen et al. “Variational quantum reinforcement learning via evolutionary optimization”. In:Machine Learning: Science and Technology3.1 (2022), p. 015025
2022
-
[31]
Quantum multi-agent reinforcement learning via variational quantum circuit design
Won Joon Yun et al. “Quantum multi-agent reinforcement learning via variational quantum circuit design”. In:2022 IEEE 42nd International Conference on Distributed Computing Systems (ICDCS). IEEE. 2022, pp. 1332–1335
2022
-
[32]
Neural Fitted Q Iteration – First Experiences with a Data Efficient Neural Reinforcement Learning Method
Martin Riedmiller. “Neural Fitted Q Iteration – First Experiences with a Data Efficient Neural Reinforcement Learning Method”. In:Proceedings of the Sixteenth European Conference on Machine Learning. Vol. 3720. Lecture Notes in Computer Science. Springer, 2005, pp. 317–328
2005
-
[33]
A Cartpole Experiment Benchmark for Trainable Controllers
Shlomo Geva and Joaqu´ ın Sitte. “A Cartpole Experiment Benchmark for Trainable Controllers”. In:IEEE Control Systems Magazine13.5 (1993), pp. 40–51.doi: 10.1109/37.236324
-
[34]
Reinforcement Learning with Quantum Variational Circuits
Owen Lockwood and Mei Si. “Reinforcement Learning with Quantum Variational Circuits”. In:Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE). 2020
2020
-
[35]
Playing Atari with Deep Reinforcement Learning
Volodymyr Mnih et al. “Playing atari with deep reinforcement learning”. In:arXiv preprint arXiv:1312.5602(2013)
work page internal anchor Pith review arXiv 2013
-
[36]
A Comparative Study on Quantum and Classical Reinforcement Learning for the CartPole Task
Hong-Chang Hsu, Yi-Hsiang Lin, and Yu-Jen Wang. “A Comparative Study on Quantum and Classical Reinforcement Learning for the CartPole Task”. In:IFToMM International Conference on Mechanisms, Transmissions and Applications. Springer. 2025, pp. 261–269
2025
-
[37]
Unentangled quantum reinforcement learning agents in the OpenAI Gym
Jen-Yueh Hsiao et al. “Unentangled quantum reinforcement learning agents in the OpenAI Gym”. In: (Mar. 2022). arXiv:2203.14348 [quant-ph]
-
[38]
First Experience with Real-Time Control Using Simulated VQC-Based Quantum Policies
Yize Sun et al. “First Experience with Real-Time Control Using Simulated VQC-Based Quantum Policies”. In:arXiv preprint arXiv:2508.01690(2025)
-
[39]
Greg Brockman et al. “OpenAI Gym”. In: (June 2016). arXiv:1606.01540 [cs.LG]
work page internal anchor Pith review arXiv 2016
-
[40]
Policy gradient methods for reinforcement learning with function approximation
Richard S Sutton et al. “Policy gradient methods for reinforcement learning with function approximation”. In:Advances in neural information processing systems12 (1999)
1999
-
[41]
Richard S Sutton and Andrew G Barto.Reinforcement Learning. en. Adaptive Computation and Machine Learning series. Cambridge, MA: Bradford Books, Feb. 1998
1998
-
[42]
Reinforcement learning approach to control an inverted pendulum: A general framework for educational purposes
Sardor Israilov et al. “Reinforcement learning approach to control an inverted pendulum: A general framework for educational purposes”. en. In:PLoS One18.2 (Feb. 2023), e0280071
2023
-
[43]
Variational quantum algorithms
M Cerezo et al. “Variational quantum algorithms”. en. In:Nat. Rev. Phys.3.9 (Aug. 2021), pp. 625–644
2021
-
[44]
Barren plateaus in variational quantum computing
Martin Larocca et al. “Barren plateaus in variational quantum computing”. In:Nature Reviews Physics(2025), pp. 1–16
2025
-
[45]
Evaluating analytic gradients on quantum hardware
Maria Schuld et al. “Evaluating analytic gradients on quantum hardware”. In:Physical Review A99.3 (2019), p. 032331
2019
-
[46]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. “Adam: A method for stochastic optimization”. In: (Dec. 2014). arXiv:1412.6980 [cs.LG]. 16 v1(2026) Ngo and Mehtolaet al
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[47]
Efficient Z gates for quantum computing
David C. McKay et al. “Efficient Z gates for quantum computing”. In:Physical Review A96 (2016), p. 022330.url:https://api.semanticscholar.org/CorpusID:119339298
2016
-
[48]
Simple Pulses for Elimination of Leakage in Weakly Nonlinear Qubits
F. Motzoi et al. “Simple Pulses for Elimination of Leakage in Weakly Nonlinear Qubits”. In: Phys. Rev. Lett.103 (11 2009), p. 110501.doi:10.1103/PhysRevLett.103.110501.url: https://link.aps.org/doi/10.1103/PhysRevLett.103.110501
-
[49]
M. Werninghaus, D.J. Egger, and S. Filipp. “High-Speed Calibration and Characterization of Superconducting Quantum Processors without Qubit Reset”. In:PRX Quantum2.2 (May 2021).issn: 2691-3399.doi:10.1103/prxquantum.2.020324.url: http://dx.doi.org/10.1103/PRXQuantum.2.020324
-
[50]
Learning representations by back-propagating errors
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. “Learning representations by back-propagating errors”. In:nature323.6088 (1986), pp. 533–536
1986
-
[51]
Ali Javadi-Abhari et al. “Quantum computing with Qiskit”. In:arXiv preprint arXiv:2405.08810(2024)
work page internal anchor Pith review arXiv 2024
-
[52]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
Ville Bergholm et al. “Pennylane: Automatic differentiation of hybrid quantum-classical computations”. In:arXiv preprint arXiv:1811.04968(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke et al. “Pytorch: An imperative style, high-performance deep learning library”. In:Advances in neural information processing systems32 (2019)
2019
-
[54]
General parameter-shift rules for quantum gradients
David Wierichs et al. “General parameter-shift rules for quantum gradients”. In:Quantum6 (2022), p. 677. Acknowledgments J.Q.Q. and P.W. acknowledges the financial support of the Quantum Technology Future Science Platform - CSIRO. Author contributions N.T.T.N.: Conceptualization, Methodology (lead on hybrid quantum-classical architecture and single-qubit ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.