Recognition: unknown
Robust Linear Dueling Bandits with Post-serving Context under Unknown Delays and Adversarial Corruptions
Pith reviewed 2026-05-10 15:28 UTC · model grok-4.3
The pith
A linear dueling bandit algorithm achieves regret that adds the separate costs of delays and corruptions rather than multiplying them together.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under standard regularity conditions and a parametric post-serving mapping, the algorithm that learns to predict post-serving contexts and clips corrupted or delayed feature vectors is delay-regime-agnostic and attains regret of order d times (square root of T plus corruption budget C plus delay complexity D). The analysis reveals an additive cost structure between corruption and delay, in contrast to the multiplicative degradation of prior work. Lower bounds that nearly match the upper bounds up to a square-root-d factor are given for adversarial delays without post-serving contexts.
What carries the argument
A learned approximator that predicts post-serving contexts from pre-serving information, paired with an adaptive weighting strategy that clips feature vectors to mitigate the joint effect of corrupted and delayed observations.
If this is right
- The algorithm works equally well whether delays are stochastic or adversarial.
- Regret grows linearly with the total corruption budget and with the delay complexity measure, added to the usual square-root term.
- The combined effect of delays and corruptions does not produce the multiplicative blow-up reported in earlier bandit analyses.
- The upper bound is nearly tight, up to a square-root dimension factor, for adversarial delays in the simpler setting without post-serving context.
Where Pith is reading between the lines
- Real deployments that combine network delays with occasional corrupted labels may incur far smaller penalties than multiplicative bounds had suggested.
- The parametric mapping assumption indicates that even modest predictive models for context can unlock the additive guarantee in practice.
- Analogous additive cost structures may be discoverable in other sequential decision settings that face both timing uncertainty and data corruption.
- Controlled tests that vary delay distributions while keeping the parametric predictor fixed would directly test the claimed delay-regime independence.
Load-bearing premise
The relationship between pre-serving and post-serving contexts can be captured well by a parametric function that the algorithm can learn.
What would settle it
An experiment in which the observed regret grows faster than linearly with the sum of the corruption budget and delay measure, while the parametric mapping holds, would falsify the additive regret claim.
Figures


read the original abstract
We study linear dueling bandits in volatile environments characterized by the simultaneous presence of post-serving contexts, delayed feedback, and adversarial corruption. Feedback is subject to unknown stochastic or adversarial delays and a cumulative corruption budget $\mathcal{C}$. To address these challenges, we propose \term, which integrates a learned approximator that predicts post-serving contexts from pre-serving information. It further employs an adaptive weighting strategy that clips feature vectors to mitigate the impact of corrupted and delayed observations simultaneously. Under standard regularity conditions and a parametric post-serving mapping, we rigorously establish that our algorithm is delay-regime-agnostic, achieving a regret upper bound of $\widetilde{\mathcal{O}}(d(\sqrt{T} + \mathcal{C} + \mathcal{D}))$, where $d$ is the total feature dimension and $\mathcal{D}$ encapsulates the delay complexity. Crucially, our analysis reveals an additive cost structure between corruption and delay, avoiding the multiplicative degradation typical of prior works. We further establish lower bounds that nearly match our upper bounds up to a $\sqrt{d}$ factor for adversarial delays in the absence of post-serving contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an algorithm (denoted as [term] in the abstract) for linear dueling bandits operating under post-serving contexts, unknown stochastic or adversarial delays, and a cumulative adversarial corruption budget C. The approach combines a learned parametric approximator for post-serving contexts with an adaptive weighting strategy that clips feature vectors. Under standard regularity conditions, the paper claims the algorithm is delay-regime-agnostic and achieves a regret upper bound of O~(d(sqrt(T) + C + D)), where D captures delay complexity, with an additive (rather than multiplicative) interaction between corruption and delay costs. Nearly matching lower bounds (up to a sqrt(d) factor) are established for the adversarial-delay case without post-serving contexts.
Significance. If the claimed bounds and additive structure hold, the work is significant for simultaneously addressing multiple practical challenges in volatile bandit environments. The delay-regime-agnostic property and additive corruption-delay cost (avoiding the multiplicative blow-up seen in prior work) would be a meaningful theoretical and practical advance. The provision of lower bounds that nearly match the upper bounds strengthens the contribution, though the sqrt(d) gap remains to be interpreted.
minor comments (4)
- The abstract and introduction should explicitly expand the algorithm name denoted as [term] and provide a one-sentence high-level description of its two core components (learned approximator and clipping strategy) for readers who skip the technical sections.
- Section 3 (or wherever the parametric post-serving mapping is introduced): the precise form of the mapping and the regularity conditions (e.g., boundedness, Lipschitzness, or realizability assumptions) should be stated as a numbered assumption block to make the dependence of the regret bound on these conditions transparent.
- The lower-bound section: clarify whether the sqrt(d) gap between upper and lower bounds arises from the linear structure, the dueling feedback model, or the absence of post-serving contexts, and whether the authors believe the gap is removable.
- Notation: the symbol D (delay complexity) is used in the bound but its precise definition (e.g., sum of delays, maximum delay, or a more refined measure) should be given immediately after the regret statement for clarity.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, recognition of its significance in addressing multiple challenges in volatile bandit settings, and recommendation for minor revision. We appreciate the acknowledgment of the delay-regime-agnostic property and the additive corruption-delay cost structure.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes an algorithm integrating a learned approximator for post-serving contexts and adaptive clipping of feature vectors, then derives a delay-regime-agnostic regret bound of O~(d(sqrt(T) + C + D)) under standard regularity conditions and a parametric post-serving mapping. This bound and the revealed additive corruption-delay cost structure are presented as results of the analysis applied to the algorithm design. No load-bearing step reduces by construction to its own inputs, no self-definitional relations appear, and no self-citations are invoked to justify core premises. The derivation is self-contained against the stated assumptions and external benchmarks for regret analysis.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption standard regularity conditions
- domain assumption parametric post-serving mapping
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Di, Q., He, J., and Gu, Q. Nearly optimal algorithms for con- textual dueling bandits from adversarial feedback.arXiv preprint arXiv:2404.10776,
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Kingma, D. P. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Feel-good thompson sam- pling for contextual dueling bandits.arXiv preprint arXiv:2404.06013,
Li, X., Zhao, H., and Gu, Q. Feel-good thompson sam- pling for contextual dueling bandits.arXiv preprint arXiv:2404.06013,
-
[6]
Zhu, R. and Kveton, B. Robust contextual linear bandits. arXiv preprint arXiv:2210.14483,
-
[7]
We then provide the complete proof for the regret upper bound of Theorem 5.2 in Section B, followed by the proof of the lower bound (Theorem 5.3) in Section C
10 Robust Linear Dueling Bandits with Post-serving Context under Unknown Delays and Adversarial Corruptions Supplementary Material: Robust Linear Dueling Bandits with Post-serving Context under Unknown Delays and Adversarial Corruptions In Section A, we derive the concentration bound for parameter estimation error under the dual challenges of adversarial ...
2011
-
[8]
withλ >0.Since˙g(·)≥κ >0by Assumption 4.1, we have the matrix dominationH t(Θ)⪰ eVt−1, where: eVt−1 :=λI+κ t−1X s=1 ωs∆zs∆z⊤ s
=H t(Θ)(Θ1 −Θ 2), where the Hessian matrixH t(Θ)is given by: Ht(Θ) :=λI+ t−1X s=1 ωs ˙g(Θ ⊤ ∆zs)∆zs∆z⊤ s . withλ >0.Since˙g(·)≥κ >0by Assumption 4.1, we have the matrix dominationH t(Θ)⪰ eVt−1, where: eVt−1 :=λI+κ t−1X s=1 ωs∆zs∆z⊤ s . as in Equation (1). Utilizing the identity ∥Ax∥A−1 =∥x∥ A for any positive definite matrix A, we obtain the following mon...
2024
-
[9]
eXt is defined as follows: eXt =X 0 + tX s=1 (xs +ϵ s)(xs +ϵ s)⊤ ∈R d×d. Then, for anyp∈[0,1], the following inequality holds with probability at least1−δ, TX t=1 1∧ ∥x t∥2 eX −1 t−1 p ≤2 pT 1−p logp detX T detX 0 + 8L2 ϵ(Lϵ +L x)2 σ4ϵ log 32dL2 ϵ(Lϵ +L x)2 δσ4ϵ wherea∧b= min{a, b}. For clarity, we define the key quantities used throughout the proof. For ...
2020
-
[10]
Therefore, the expected per-round regret is E[Regrett] = 2u(a∗)−E[u(a t)]−E[u(b t)] = 2 √ d∆−0−0 = 2 √ d∆.(C.25) Aggregating over allMrounds in the blind phase yields E[Regret]≥ MX t=1 E[Regrett] =M·2 √ d∆ = Ω( √ Λ· √ d) = Ω( √ dΛ),(C.26) which completes the proof. 19 Robust Linear Dueling Bandits with Post-serving Context under Unknown Delays and Adversa...
2024
-
[11]
promising
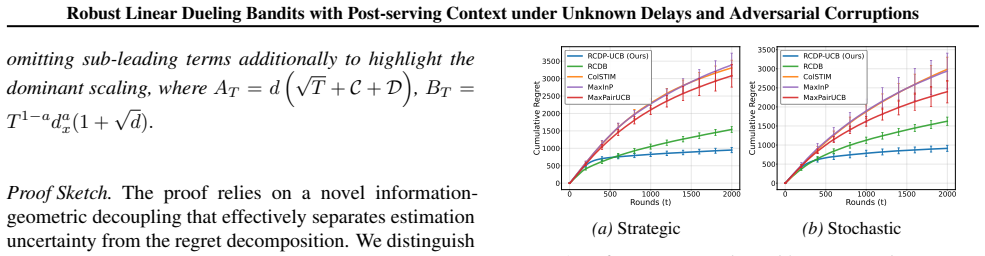
with a learning rate of η= 10 −3 and a regularization coefficient of λ= 1.0 . The experiments were conducted over a time horizon of T= 2,000 rounds, and all reported results were averaged over 5 independent runs with different random seeds to ensure statistical reliability. The network was optimized using Adam with a learning rate of 10−3 and trained for ...
2024
-
[12]
Additional Experiments E.1
Weighted Gradient Step mu_val = torch.sigmoid(torch.dot(self.theta_hat, delta_z)) # Gradient direction weighted by omega_t * W_inv step = self.W_inv @ (omega_t * (outcome - mu_val) * delta_z) self.theta_hat += step Listing 1.PyTorch Implementation of RCDP-UCB (Simplified) E. Additional Experiments E.1. Experiments on Real-world Datasets We validate the ro...
2000
-
[13]
As the corruption budget increases, the bias introduced by the adversary becomes more significant
Empirical Analysis.Figure E.10 shows the cumulative regret for the linear problem with context dimensions d= 10 and d= 20 . As the corruption budget increases, the bias introduced by the adversary becomes more significant. However, RCDP-UCB consistently maintains lower regret and faster convergence compared to both robust and non-robust baselines. This is...
2000
-
[14]
As the delay budget or mean delay increases, the learner receives feedback less frequently, leading to slower parameter convergence
Sensitivity without Baseline Post-Serving Learning.Figure E.11 summarizes the cumulative regret for the linear task. As the delay budget or mean delay increases, the learner receives feedback less frequently, leading to slower parameter convergence. RCDP-UCB demonstrates superior robustness compared to robust baselines like RCDB, maintaining lower regret ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.