Recognition: unknown
Adversarial Imitation Learning with General Function Approximation: Theoretical Analysis and Practical Algorithms
Pith reviewed 2026-05-10 15:18 UTC · model grok-4.3
The pith
Optimization-based adversarial imitation learning achieves polynomial sample complexity under general function approximation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce optimization-based AIL (OPT-AIL), which performs online optimization for reward learning coupled with optimism-regularized optimization for policy learning. Within this framework we develop model-free OPT-AIL and model-based OPT-AIL. Our theoretical analysis demonstrates that both variants achieve polynomial expert sample complexity and interaction complexity for learning near-expert policies. To the best of our knowledge, they represent the first provably efficient AIL methods under general function approximation.
What carries the argument
The optimization-based AIL (OPT-AIL) framework that couples online reward optimization with optimism-regularized policy optimization and relies on approximate oracles for general function classes.
If this is right
- Both model-free and model-based OPT-AIL variants achieve polynomial expert sample complexity and interaction complexity.
- Implementation requires only the approximate optimization of two objectives.
- The methods are the first provably efficient AIL algorithms that apply to general function approximation rather than tabular or linear cases.
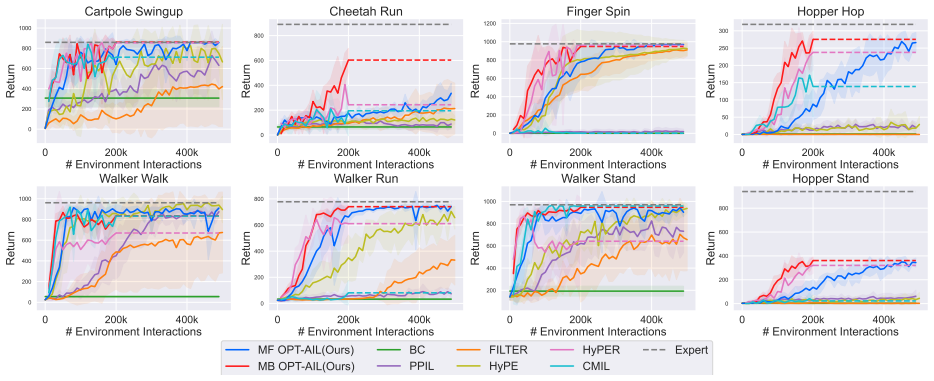
- Empirical performance exceeds that of prior state-of-the-art deep AIL methods on multiple tasks.
Where Pith is reading between the lines
- The same optimism-regularization pattern may stabilize training when the policy and reward networks are very deep or recurrent.
- The framework could be reused for other adversarial objectives in reinforcement learning that currently lack general-approximation guarantees.
- The polynomial degree might be further reduced by tighter oracle assumptions or by combining model-free and model-based elements.
Load-bearing premise
The function approximation class admits efficient approximate optimization oracles for the reward and policy objectives such that optimism-regularized updates produce polynomial regret bounds without exponential dependence on approximation error or dimension.
What would settle it
An explicit construction of a function class and oracle pair where the interaction complexity required to reach near-expert performance grows super-polynomially with the approximation error or with the dimension of the class.
Figures




read the original abstract
Adversarial imitation learning (AIL), a prominent approach in imitation learning, has achieved significant practical success powered by neural network approximation. However, existing theoretical analyses of AIL are primarily confined to simplified settings, such as tabular and linear function approximation, and involve complex algorithmic designs that impede practical implementation. This creates a substantial gap between theory and practice. This paper bridges this gap by exploring the theoretical underpinnings of online AIL with general function approximation. We introduce a novel framework called optimization-based AIL (OPT-AIL), which performs online optimization for reward learning coupled with optimism-regularized optimization for policy learning. Within this framework, we develop two concrete methods: model-free OPT-AIL and model-based OPT-AIL. Our theoretical analysis demonstrates that both variants achieve polynomial expert sample complexity and interaction complexity for learning near-expert policies. To the best of our knowledge, they represent the first provably efficient AIL methods under general function approximation. From a practical standpoint, OPT-AIL requires only the approximate optimization of two objectives, thereby facilitating practical implementation. Empirical studies demonstrate that OPT-AIL outperforms previous state-of-the-art deep AIL methods across several challenging tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the OPT-AIL framework for adversarial imitation learning under general function approximation. It combines online optimization for reward learning with optimism-regularized optimization for policy learning, yielding two concrete algorithms (model-free OPT-AIL and model-based OPT-AIL). The central claim is that both variants achieve polynomial expert-sample and interaction complexity for near-expert policies, constituting the first provably efficient AIL methods under general FA; the methods require only approximate optimization of two objectives and empirically outperform prior deep AIL baselines.
Significance. If the polynomial complexity guarantees hold without hidden exponential dependence on approximation error or covering numbers, the work would be significant: it would supply the first non-tabular, non-linear guarantees for AIL and directly address the theory-practice gap by reducing implementation to two optimization oracles. The empirical results on challenging tasks provide supporting evidence of practicality, though the theoretical contribution hinges on the oracle assumptions.
major comments (2)
- [Theoretical Analysis (main regret theorems)] The polynomial expert-sample and interaction complexity claims rest on the existence of approximate optimization oracles for the reward and policy objectives whose regret scales polynomially in the approximation error and function-class complexity. No explicit construction, regret bound, or reduction is supplied showing that such oracles can be realized for the specific non-convex objectives arising in the OPT-AIL updates; in general function approximation this leaves open the possibility of exponential dependence on 1/ε or on the covering number, rendering the overall polynomial bounds conditional rather than unconditional.
- [Policy optimization step and regret decomposition] The optimism-regularized policy update is presented as yielding polynomial regret under general FA, yet the analysis does not quantify how the optimism term interacts with the function-approximation error of the learned reward; without an explicit error-propagation lemma relating the two, it is unclear whether the claimed polynomial interaction complexity survives when the reward approximator is only ε-accurate.
minor comments (2)
- [Preliminaries] Notation for the function class and the approximate optimization oracles should be introduced with explicit dependence on the covering number or pseudo-dimension to make the polynomial bounds transparent.
- [Experiments] The empirical section would benefit from reporting the number of optimization oracle calls per iteration and wall-clock time, to substantiate the claim that only two approximate optimizations are needed in practice.
Simulated Author's Rebuttal
We thank the referee for their insightful comments and the recognition of our work's potential significance in bridging theory and practice for adversarial imitation learning under general function approximation. We address the major comments below.
read point-by-point responses
-
Referee: The polynomial expert-sample and interaction complexity claims rest on the existence of approximate optimization oracles for the reward and policy objectives whose regret scales polynomially in the approximation error and function-class complexity. No explicit construction, regret bound, or reduction is supplied showing that such oracles can be realized for the specific non-convex objectives arising in the OPT-AIL updates; in general function approximation this leaves open the possibility of exponential dependence on 1/ε or on the covering number, rendering the overall polynomial bounds conditional rather than unconditional.
Authors: We agree that our theoretical results are conditional on the existence of approximate optimization oracles that achieve regret scaling polynomially with the approximation error and function class complexity. The paper's main contribution is to show that, under such oracle assumptions, the OPT-AIL framework yields polynomial expert sample and interaction complexities for near-expert policies. We do not claim to construct such oracles for arbitrary non-convex objectives, as this would require advances in non-convex optimization that are beyond the scope of this work. Similar oracle-based analyses are standard in the literature on RL with general function approximation (e.g., in works on model-free RL). We will add a clearer statement in the introduction and conclusion to emphasize that the polynomial bounds hold assuming the oracles satisfy the polynomial regret property, to avoid any misunderstanding. revision: partial
-
Referee: The optimism-regularized policy update is presented as yielding polynomial regret under general FA, yet the analysis does not quantify how the optimism term interacts with the function-approximation error of the learned reward; without an explicit error-propagation lemma relating the two, it is unclear whether the claimed polynomial interaction complexity survives when the reward approximator is only ε-accurate.
Authors: We thank the referee for this observation. Our analysis in the main text and appendix decomposes the policy regret but does not include a standalone lemma explicitly relating the optimism term to the reward approximation error ε. We agree this would strengthen the paper and clarify that the polynomial bound holds. We will add such an error-propagation lemma in the revised version. revision: yes
Circularity Check
No significant circularity; derivation independent under oracle assumptions
full rationale
The paper introduces the OPT-AIL framework performing online optimization for reward learning and optimism-regularized optimization for policy learning, then derives polynomial expert-sample and interaction complexity bounds for both model-free and model-based variants under general function approximation. These bounds are obtained from the stated algorithmic structure and the assumption that the function class admits efficient approximate optimization oracles yielding polynomial regret. No step reduces a claimed result to its own inputs by construction, renames a fitted quantity as a prediction, or relies on a load-bearing self-citation whose content is unverified. The analysis supplies independent content conditional on the oracle primitive; the oracle assumption itself is an external modeling choice rather than a definitional loop. This is the normal case of a self-contained theoretical construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption General function approximation admits efficient approximate optimization oracles that yield polynomial regret when combined with optimism regularization.
invented entities (1)
-
OPT-AIL framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction. MIT press, 2018
2018
-
[2]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovskiet al., “Human-level control through deep reinforcement learning,”Nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[3]
When to trust your model: Model-based policy optimization,
M. Janner, J. Fu, M. Zhang, and S. Levine, “When to trust your model: Model-based policy optimization,” inAdvances in Neural Information Processing Systems 32, 2019, pp. 12 498–12 509
2019
-
[4]
Generative adversarial user model for reinforcement learning based recommendation system,
X. Chen, S. Li, H. Li, S. Jiang, Y. Qi, and L. Song, “Generative adversarial user model for reinforcement learning based recommendation system,” inProceedings of the 36th International Conference on Machine Learning, 2019, pp. 1052–1061. 16
2019
-
[5]
Virtual-taobao: virtualizing real-world online retail envi- ronment for reinforcement learning,
J. Shi, Y. Yu, Q. Da, S. Chen, and A. Zeng, “Virtual-taobao: virtualizing real-world online retail envi- ronment for reinforcement learning,” inProceedings of the 33rd AAAI Conference on Artificial Intelligence, 2019, pp. 4902–4909
2019
-
[6]
OpenVLA: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P . Foster, P . R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P . Liang, and C. Finn, “OpenVLA: An open-source vision-language-action model,” inConference on Robot Learning, 2024
2024
-
[7]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter et al., “π0: A vision-language-action flow model for general robot control,”arXiv, vol. 2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Efficient training of artificial neural networks for autonomous navigation,
D. Pomerleau, “Efficient training of artificial neural networks for autonomous navigation,”Neural Computation, vol. 3, no. 1, pp. 88–97, 1991
1991
-
[9]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. J. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProceedings of the 14th International Conference on Artificial Intelligence and Statistics, 2011, pp. 627–635
2011
-
[10]
Disagreement-regularized imitation learning,
K. Brantley, W. Sun, and M. Henaff, “Disagreement-regularized imitation learning,” inProceedings of the 8th International Conference on Learning Representations, 2020
2020
-
[11]
Behavioral cloning from observation,
F. Torabi, G. Warnell, and P . Stone, “Behavioral cloning from observation,” inProceedings of the 27th International Joint Conference on Artificial Intelligence, 2018, pp. 4950–4957
2018
-
[12]
Discriminator-actor-critic: Ad- dressing sample inefficiency and reward bias in adversarial imitation learning,
I. Kostrikov, K. K. Agrawal, D. Dwibedi, S. Levine, and J. Tompson, “Discriminator-actor-critic: Ad- dressing sample inefficiency and reward bias in adversarial imitation learning,” inProceedings of the 7th International Conference on Learning Representations, 2019
2019
-
[13]
Offline imitation learning with a misspecified simulator,
S. Jiang, J. Pang, and Y. Yu, “Offline imitation learning with a misspecified simulator,”Advances in Neural Information Processing Systems 33, 2020
2020
-
[14]
Imitation Learning as $f$-Divergence Minimization, May 2020
L. Ke, M. Barnes, W. Sun, G. Lee, S. Choudhury, and S. S. Srinivasa, “Imitation learning as f-divergence minimization,”arXiv, vol. 1905.12888, 2019
-
[15]
A divergence minimization perspective on imitation learning methods,
S. K. S. Ghasemipour, R. S. Zemel, and S. Gu, “A divergence minimization perspective on imitation learning methods,” inProceedings of the 3rd Annual Conference on Robot Learning, 2019, pp. 1259–1277
2019
-
[16]
Iq-learn: Inverse soft-q learning for imitation,
D. Garg, S. Chakraborty, C. Cundy, J. Song, and S. Ermon, “Iq-learn: Inverse soft-q learning for imitation,” inAdvances in Neural Information Processing Systems 34, 2021, pp. 4028–4039
2021
-
[17]
Transferable reward learning by dynamics-agnostic discrimina- tor ensemble,
F.-M. Luo, X. Cao, R.-J. Qin, and Y. Yu, “Transferable reward learning by dynamics-agnostic discrimina- tor ensemble,”arXiv, vol. 2206.00238, 2022
-
[18]
Imitation learning from imperfection: Theoretical justifications and algorithms,
Z. Li, T. Xu, Z. Qin, Y. Yu, and Z.-Q. Luo, “Imitation learning from imperfection: Theoretical justifications and algorithms,”Advances in Neural Information Processing Systems 37, 2023
2023
-
[19]
D. J. Foster, A. Block, and D. Misra, “Is behavior cloning all you need? understanding horizon in imitation learning,”arXiv, vol. 2407.15007, 2024
-
[20]
Online apprenticeship learning.arXiv:2102.06924, 2021
L. Shani, T. Zahavy, and S. Mannor, “Online apprenticeship learning,”arXiv, vol. 2102.06924, 2021
-
[21]
Provably efficient adversarial imitation learning with unknown transitions,
T. Xu, Z. Li, Y. Yu, and Z.-Q. Luo, “Provably efficient adversarial imitation learning with unknown transitions,” inProceedings of the 39th Conference on Uncertainty in Artificial Intelligence, 2023, pp. 2367– 2378
2023
-
[22]
Z. Liu, Y. Zhang, Z. Fu, Z. Yang, and Z. Wang, “Provably efficient generative adversarial imitation learning for online and offline setting with linear function approximation,”arXiv, vol. 2108.08765, 2021. 17
-
[23]
Imitation learning in discounted linear MDPs without exploration assumptions,
L. Viano, S. Skoulakis, and V . Cevher, “Imitation learning in discounted linear MDPs without exploration assumptions,” inProceedings of the 41st International Conference on Machine Learning, 2024, pp. 49 471– 49 505
2024
-
[24]
Error bounds of imitating policies and environments,
T. Xu, Z. Li, and Y. Yu, “Error bounds of imitating policies and environments,” inAdvances in Neural Information Processing Systems 33, 2020, pp. 15 737–15 749
2020
-
[25]
Understanding Adversarial Imitation Learning in Small Sample Regime: A Stage-coupled Analysis
T. Xu, Z. Li, Y. Yu, and Z.-Q. Luo, “Understanding adversarial imitation learning in small sample regime: A stage-coupled analysis,”arXiv, vol. 2208.01899, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Toward the fundamental limits of imitation learning,
N. Rajaraman, L. F. Yang, J. Jiao, and K. Ramchandran, “Toward the fundamental limits of imitation learning,” inAdvances in Neural Information Processing Systems 33, 2020, pp. 2914–2924
2020
-
[27]
Exploration in deep reinforcement learning: a comprehensive survey,
T. Yang, H. Tang, C. Bai, J. Liu, J. Hao, Z. Meng, P . Liu, and Z. Wang, “Exploration in deep reinforcement learning: a comprehensive survey,”arXiv, vol. 2109.06668, 2021
-
[28]
From dirichlet to rubin: Optimistic exploration in rl without bonuses,
D. Tiapkin, D. Belomestny, É. Moulines, A. Naumov, S. Samsonov, Y. Tang, M. Valko, and P . Ménard, “From dirichlet to rubin: Optimistic exploration in rl without bonuses,” inProceedings of the 39th International Conference on Machine Learning, 2022, pp. 21 380–21 431
2022
-
[29]
Maximize to explore: One objective function fusing estimation, planning, and exploration,
Z. Liu, M. Lu, W. Xiong, H. Zhong, H. Hu, S. Zhang, S. Zheng, Z. Yang, and Z. Wang, “Maximize to explore: One objective function fusing estimation, planning, and exploration,”Advances in Neural Information Processing Systems 36, 2024
2024
-
[30]
A posterior sampling framework for interactive decision making,
H. Zhong, W. Xiong, S. Zheng, L. Wang, Z. Wang, Z. Yang, and T. Zhang, “A posterior sampling framework for interactive decision making,”arXiv, vol. 2211.01962, 2022
-
[31]
Apprenticeship learning via inverse reinforcement learning,
P . Abbeel and A. Y. Ng, “Apprenticeship learning via inverse reinforcement learning,” inProceedings of the 21st International Conference on Machine Learning, 2004, pp. 1–8
2004
-
[32]
A game-theoretic approach to apprenticeship learning,
U. Syed and R. E. Schapire, “A game-theoretic approach to apprenticeship learning,” inAdvances in Neural Information Processing Systems 20, 2007, pp. 1449–1456
2007
-
[33]
Provably efficient imitation learning from observation alone,
W. Sun, A. Vemula, B. Boots, and D. Bagnell, “Provably efficient imitation learning from observation alone,” inProceedings of the 36th International Conference on Machine Learning, 2019, pp. 6036–6045
2019
-
[34]
On the value of interaction and function approximation in imitation learning,
N. Rajaraman, Y. Han, L. Yang, J. Liu, J. Jiao, and K. Ramchandran, “On the value of interaction and function approximation in imitation learning,” inAdvances in Neural Information Processing Systems 34, 2021, pp. 1325–1336
2021
-
[35]
Minimax optimal online imitation learning via replay estimation,
G. Swamy, N. Rajaraman, M. Peng, S. Choudhury, J. Bagnell, S. Z. Wu, J. Jiao, and K. Ramchandran, “Minimax optimal online imitation learning via replay estimation,”Advances in Neural Information Processing Systems 35, pp. 7077–7088, 2022
2022
-
[36]
Proximal point imitation learning,
L. Viano, A. Kamoutsi, G. Neu, I. Krawczuk, and V . Cevher, “Proximal point imitation learning,” Advances in Neural Information Processing Systems, vol. 35, pp. 24 309–24 326, 2022
2022
-
[37]
Error bounds of imitating policies and environments for reinforcement learning,
T. Xu, Z. Li, and Y. Yu, “Error bounds of imitating policies and environments for reinforcement learning,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
2021
-
[38]
Generative adversarial imitation learning,
J. Ho and S. Ermon, “Generative adversarial imitation learning,” inAdvances in Neural Information Processing Systems 29, 2016, pp. 4565–4573
2016
-
[39]
Imitation learning via off-policy distribution matching,
I. Kostrikov, O. Nachum, and J. Tompson, “Imitation learning via off-policy distribution matching,” in Proceedings of the 8th International Conference on Learning Representations, 2020
2020
-
[40]
End-to-end differentiable adversarial imitation learning,
N. Baram, O. Anschel, I. Caspi, and S. Mannor, “End-to-end differentiable adversarial imitation learning,” inProceedings of the 34th International Conference on Machine Learning, 2017, pp. 390–399. 18
2017
-
[41]
Efficient imitation learning with conservative world models,
V . Kolev, R. Rafailov, K. Hatch, J. Wu, and C. Finn, “Efficient imitation learning with conservative world models,” in6th Annual Learning for Dynamics & Control Conference, 2024, pp. 1777–1790
2024
-
[42]
Hybrid inverse reinforcement learning,
J. Ren, G. Swamy, Z. S. Wu, J. A. Bagnell, and S. Choudhury, “Hybrid inverse reinforcement learning,” Proceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[43]
Model-based reinforcement learning and the eluder dimension,
I. Osband and B. V . Roy, “Model-based reinforcement learning and the eluder dimension,” inAdvances in Neural Information Processing Systems 27, 2014, pp. 1466–1474
2014
-
[44]
Bellman eluder dimension: New rich classes of rl problems, and sample-efficient algorithms,
C. Jin, Q. Liu, and S. Miryoosefi, “Bellman eluder dimension: New rich classes of rl problems, and sample-efficient algorithms,” inAdvances in Neural Information Processing Systems 34, 2021, pp. 13 406– 13 418
2021
-
[45]
Efficient reductions for imitation learning,
S. Ross and D. Bagnell, “Efficient reductions for imitation learning,” inProceedings of the 13rd International Conference on Artificial Intelligence and Statistics, 2010, pp. 661–668
2010
-
[46]
M. J. Wainwright,High-dimensional statistics: A non-asymptotic viewpoint. Cambridge University Press, 2019
2019
-
[47]
Introduction to online convex optimization,
E. Hazan, “Introduction to online convex optimization,”Foundations and Trends in Optimization, vol. 2, no. 3-4, pp. 157–325, 2016
2016
-
[48]
Online non-convex learning: Following the perturbed leader is optimal,
A. S. Suggala and P . Netrapalli, “Online non-convex learning: Following the perturbed leader is optimal,” inProceedings of the 31st International Conference on Algorithmic Learning Theory, 2020, pp. 845–861
2020
-
[49]
Learning near-optimal policies with bellman-residual mini- mization based fitted policy iteration and a single sample path,
A. Antos, C. Szepesvári, and R. Munos, “Learning near-optimal policies with bellman-residual mini- mization based fitted policy iteration and a single sample path,”Machine Learning, vol. 71, pp. 89–129, 2008
2008
-
[50]
Provably efficient reinforcement learning with linear function approximation,
C. Jin, Z. Yang, Z. Wang, and M. I. Jordan, “Provably efficient reinforcement learning with linear function approximation,” inProceedings of the 33rd Annual Conference on Learning Theory, 2020, pp. 2137–2143
2020
-
[51]
Wasserstein generative adversarial networks,
M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein generative adversarial networks,” inProceedings of the 34th International Conference on Machine Learning, 2017, pp. 214–223
2017
-
[52]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P . Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” inProceedings of the 35th International Conference on Machine Learning, 2018, pp. 1856–1865
2018
-
[53]
Adversarially trained actor critic for offline rein- forcement learning,
C.-A. Cheng, T. Xie, N. Jiang, and A. Agarwal, “Adversarially trained actor critic for offline rein- forcement learning,” inProceedings of the 39th International Conference on Machine Learning, 2022, pp. 3852–3878
2022
-
[54]
Adversarial model for offline reinforcement learning,
M. Bhardwaj, T. Xie, B. Boots, N. Jiang, and C.-A. Cheng, “Adversarial model for offline reinforcement learning,”Advances in Neural Information Processing Systems 37, vol. 36, 2024
2024
-
[55]
A note on target q-learning for solving finite mdps with a generative oracle,
Z. Li, T. Xu, and Y. Yu, “A note on target q-learning for solving finite mdps with a generative oracle,” arXiv, vol. 2203.11489, 2022
-
[56]
Rambo-rl: Robust adversarial model-based offline reinforcement learning,
M. Rigter, B. Lacerda, and N. Hawes, “Rambo-rl: Robust adversarial model-based offline reinforcement learning,” inAdvances in neural information processing systems 35, 2022, pp. 16 082–16 097
2022
-
[57]
Y. Tassa, Y. Doron, A. Muldal, T. Erez, Y. Li, D. d. L. Casas, D. Budden, A. Abdolmaleki, J. Merel, A. Lefrancqet al., “Deepmind control suite,”arXiv preprint arXiv:1801.00690, 2018
work page internal anchor Pith review arXiv 2018
-
[58]
Mastering visual continuous control: Improved data- augmented reinforcement learning,
D. Yarats, R. Fergus, A. Lazaric, and L. Pinto, “Mastering visual continuous control: Improved data- augmented reinforcement learning,” inInternational Conference on Learning Representations, 2021. 19
2021
-
[59]
Inverse reinforcement learning without reinforcement learning,
G. Swamy, D. Wu, S. Choudhury, D. Bagnell, and S. Wu, “Inverse reinforcement learning without reinforcement learning,” inProceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[60]
Taming the monster: A fast and simple algorithm for contextual bandits,
A. Agarwal, D. Hsu, S. Kale, J. Langford, L. Li, and R. Schapire, “Taming the monster: A fast and simple algorithm for contextual bandits,” inProceedings of the 31st International Conference on Machine Learning, 2014, pp. 1638–1646
2014
-
[61]
arXiv preprint arXiv:2112.13487 , year=
D. J. Foster, S. M. Kakade, J. Qian, and A. Rakhlin, “The statistical complexity of interactive decision making,”arXiv, vol. 2112.13487, 2021
-
[62]
Conservative q-learning for offline reinforcement learning,
A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Conservative q-learning for offline reinforcement learning,”Advances in Neural Information Processing Systems, vol. 33, pp. 1179–1191, 2020. 20 A Omitted Proof A.1 Proof of Lemma 1 Lemma 1 presents an error decomposition theory in adversarial imitation learning. According to the definition of sπ, we have that ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.