Recognition: unknown
Skipping the Zeros in Diffusion Models for Sparse Data Generation
Pith reviewed 2026-05-10 14:53 UTC · model grok-4.3
The pith
Diffusion models can generate sparse data by modeling only non-zero values while handling zero locations separately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
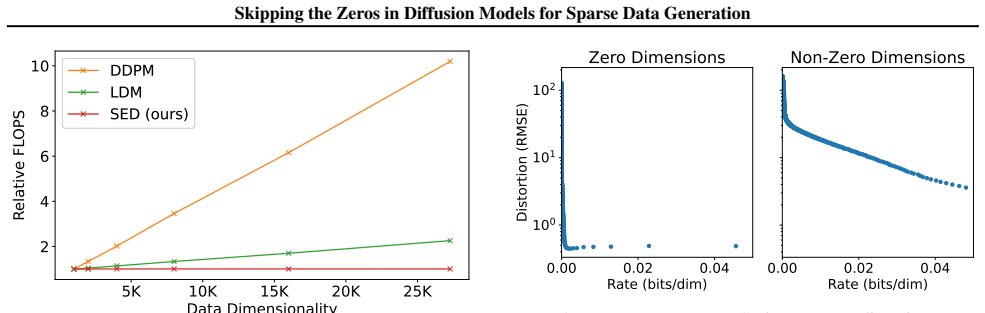
The paper establishes that by skipping zeros during both training and inference, and modeling only the non-zero values while preserving sparsity patterns independently, Sparsity-Exploiting Diffusion achieves lower computational cost without loss of generation quality. On physics and biology benchmarks it matches or exceeds conventional diffusion models and specialized baselines; vision experiments illustrate how dense models blur sparsity and how the new separation avoids that failure.
What carries the argument
Sparsity-Exploiting Diffusion (SED), the mechanism that restricts the diffusion process to non-zero entries and treats sparsity pattern modeling as a separate step.
Load-bearing premise
The locations of zeros can be handled independently from the values in the non-zero positions without losing essential distributional information.
What would settle it
If SED produces lower-quality samples or incorrect sparsity patterns than a standard diffusion model on a dataset where zero positions are strongly correlated with the non-zero values, the separation approach would be shown to fail.
Figures










read the original abstract
Diffusion models (DMs) excel on dense continuous data, but are not designed for sparse continuous data. They do not model exact zeros that represent the deliberate absence of a signal. As a result, they erase sparsity patterns and perform unnecessary computation on mostly zero entries. With Sparsity-Exploiting Diffusion (SED), we model only non-zero values, preserving sparsity. SED delivers computational savings while maintaining or improving generation quality by skipping zeros during training and inference. Across physics and biology benchmarks, SED matches or surpasses conventional DMs and domain-specific baselines, while vision experiments provide intuitive insights into the limitations of dense DMs and the benefits of SED.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sparsity-Exploiting Diffusion (SED), a modification to diffusion models for sparse continuous data. Standard DMs do not handle exact zeros (representing deliberate signal absence) and waste computation on zero entries while erasing sparsity patterns. SED models only non-zero values, skipping zeros during training and inference to preserve sparsity, deliver computational savings, and match or surpass conventional DMs and domain-specific baselines on physics, biology, and vision benchmarks.
Significance. If the results hold under scrutiny, SED addresses a practical limitation of dense diffusion models on sparse data common in physics simulations and biological signals, potentially enabling more efficient generation while maintaining distributional fidelity. The approach could be impactful for applications where sparsity is structurally important.
major comments (2)
- [Abstract / Method] The core modeling choice separates the sparsity pattern (zero locations) from non-zero magnitudes and treats them independently. This assumption is load-bearing for the claim of preserving the joint distribution and correct sparsity statistics, yet the manuscript provides no validation or discussion of cases where zero positions correlate with value ranges (e.g., thresholded fields).
- [Abstract / Experiments] The abstract asserts performance parity or gains across benchmarks, but the provided description contains no implementation details, error bars, ablation results on the mask/value separation, or quantitative comparison of sparsity statistics in generated samples. These omissions make it impossible to evaluate whether the reported improvements are robust or artifactual.
minor comments (1)
- [Abstract] Clarify in the abstract or introduction how the sparsity mask is generated or modeled at inference time, as this is central to the claimed computational savings.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions have been made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] The core modeling choice separates the sparsity pattern (zero locations) from non-zero magnitudes and treats them independently. This assumption is load-bearing for the claim of preserving the joint distribution and correct sparsity statistics, yet the manuscript provides no validation or discussion of cases where zero positions correlate with value ranges (e.g., thresholded fields).
Authors: We acknowledge that SED deliberately factors the sparsity mask and non-zero magnitudes as separate components to enable skipping zeros. This design choice is motivated by domains where sparsity patterns arise from structural or physical rules that are largely independent of magnitude values. However, the referee correctly notes that the manuscript contains no explicit validation or discussion of scenarios in which zero locations are correlated with value ranges, such as thresholded fields. We have added a dedicated paragraph in the Discussion section that states this modeling assumption, its scope of applicability, and outlines a possible extension using a joint mask-value model for strongly correlated cases. revision: yes
-
Referee: [Abstract / Experiments] The abstract asserts performance parity or gains across benchmarks, but the provided description contains no implementation details, error bars, ablation results on the mask/value separation, or quantitative comparison of sparsity statistics in generated samples. These omissions make it impossible to evaluate whether the reported improvements are robust or artifactual.
Authors: The referee is right that the abstract itself omits these elements due to length limits. The full manuscript already reports implementation details in Section 3, error bars from repeated runs in Tables 1–3, and an ablation on the mask/value separation in Section 4.3. To directly address the concern about sparsity statistics, we have added a new quantitative analysis (new Table 4 and Figure 5) that compares zero ratios, spatial distributions of non-zero entries, and non-zero value histograms between real and generated samples on all benchmarks. These additions allow readers to verify that sparsity patterns are preserved and that performance gains are not artifactual. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces Sparsity-Exploiting Diffusion (SED) as a direct algorithmic modification to standard diffusion models, skipping zero entries during training and inference while modeling only non-zero values. No derivation step reduces a claimed prediction to a fitted parameter by construction, invokes a self-citation as a uniqueness theorem, or renames an existing result; the central claims rest on explicit changes to the forward/reverse processes and are validated empirically on external benchmarks rather than internally forced. The separation of sparsity mask from value magnitudes is presented as an explicit modeling assumption, not derived from prior equations within the paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models can be adapted by selectively processing non-zero entries without altering the underlying noise schedule or score matching objective.
invented entities (1)
-
Sparsity-Exploiting Diffusion (SED)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hinton , title =
Ting Chen and Ruixiang Zhang and Geoffrey E. Hinton , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[2]
Neural Information Processing Systems, Machine Learning and the Physical Sciences Workshop , year=
Sparse image generation with decoupled generative models , author=. Neural Information Processing Systems, Machine Learning and the Physical Sciences Workshop , year=
-
[3]
Physical Review D , volume=
Sparse autoregressive models for scalable generation of sparse images in particle physics , author=. Physical Review D , volume=. 2021 , publisher=
2021
-
[4]
Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Bj. High-Resolution Image Synthesis with Latent Diffusion Models , booktitle =. 2022 , url =. doi:10.1109/CVPR52688.2022.01042 , timestamp =
-
[5]
Genome biology , volume=
Eleven grand challenges in single-cell data science , author=. Genome biology , volume=. 2020 , publisher=
2020
-
[6]
Deep unsupervised learning using nonequilibrium thermodynamics , booktitle =
Jascha Sohl. Deep unsupervised learning using nonequilibrium thermodynamics , booktitle =. 2015 , url =
2015
-
[7]
Denoising diffusion probabilistic models , booktitle =
Jonathan Ho and Ajay Jain and Pieter Abbeel , editor =. Denoising diffusion probabilistic models , booktitle =. 2020 , url =
2020
-
[8]
Improved techniques for training score-based generative models , booktitle =
Yang Song and Stefano Ermon , editor =. Improved techniques for training score-based generative models , booktitle =. 2020 , url =
2020
-
[9]
Score-based generative modeling through stochastic differential equations , booktitle =
Yang Song and Jascha Sohl. Score-based generative modeling through stochastic differential equations , booktitle =. 2021 , url =
2021
-
[10]
Johnson and Jonathan Ho and Daniel Tarlow and Rianne van den Berg , editor =
Jacob Austin and Daniel D. Johnson and Jonathan Ho and Daniel Tarlow and Rianne van den Berg , editor =. Structured denoising diffusion models in discrete state-spaces , booktitle =. 2021 , url =
2021
-
[11]
Kingma , title =
Tim Salimans and Andrej Karpathy and Xi Chen and Diederik P. Kingma , title =. 5th International Conference on Learning Representations,. 2017 , url =
2017
-
[12]
Communications of the ACM , volume=
Generative adversarial networks , author=. Communications of the ACM , volume=. 2020 , publisher=
2020
-
[13]
Nature , volume=
Single-cell transcriptomics of 20 mouse organs creates a Tabula Muris: The Tabula Muris Consortium , author=. Nature , volume=. 2018 , publisher=
2018
-
[14]
Science advances , volume=
Single-cell RNA sequencing reveals profibrotic roles of distinct epithelial and mesenchymal lineages in pulmonary fibrosis , author=. Science advances , volume=. 2020 , publisher=
2020
-
[15]
http://yann.lecun.com/exdb/mnist/ , year=
The MNIST database of handwritten digits , author=. http://yann.lecun.com/exdb/mnist/ , year=
-
[16]
2017 , eprint=
Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms , author=. 2017 , eprint=
2017
-
[17]
Advances in Neural Information Processing Systems , volume=
Poisson-gamma dynamical systems , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Augment-and-Conquer Negative Binomial Processes , booktitle =
Mingyuan Zhou and Lawrence Carin , editor =. Augment-and-Conquer Negative Binomial Processes , booktitle =. 2012 , url =
2012
-
[19]
Deep dynamic
Gong, Chengyue and others , journal=. Deep dynamic
-
[20]
Advances in Neural Information Processing Systems , volume=
Deep Poisson gamma dynamical systems , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Linderman and Mingyuan Zhou and David M
Aaron Schein and Scott W. Linderman and Mingyuan Zhou and David M. Blei and Hanna M. Wallach , editor =. Poisson-randomized gamma dynamical systems , booktitle =. 2019 , url =
2019
-
[22]
Score-based Generative Modeling in Latent Space , booktitle =
Arash Vahdat and Karsten Kreis and Jan Kautz , editor =. Score-based Generative Modeling in Latent Space , booktitle =. 2021 , url =
2021
-
[23]
xTrimoGene: An Efficient and Scalable Representation Learner for Single-Cell RNA-Seq Data , booktitle =
Jing Gong and Minsheng Hao and Xingyi Cheng and Xin Zeng and Chiming Liu and Jianzhu Ma and Xuegong Zhang and Taifeng Wang and Le Song , editor =. xTrimoGene: An Efficient and Scalable Representation Learner for Single-Cell RNA-Seq Data , booktitle =. 2023 , url =
2023
-
[24]
Advances in Neural Information Processing Systems , editor=
On Density Estimation with Diffusion Models , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
2021
-
[25]
Gomez and Lukasz Kaiser and Illia Polosukhin , editor =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , editor =. Attention is All you Need , booktitle =. 2017 , url =
2017
-
[26]
U-Net: convolutional networks for biomedical image segmentation , booktitle =
Olaf Ronneberger and Philipp Fischer and Thomas Brox , editor =. U-Net: convolutional networks for biomedical image segmentation , booktitle =. 2015 , url =. doi:10.1007/978-3-319-24574-4\_28 , timestamp =
-
[27]
beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework , booktitle =
Irina Higgins and Lo. beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework , booktitle =. 2017 , url =
2017
-
[28]
Kingma and Max Welling , editor =
Diederik P. Kingma and Max Welling , editor =. Auto-Encoding Variational Bayes , booktitle =. 2014 , url =
2014
-
[29]
Weinberger , editor =
Justin Lovelace and Varsha Kishore and Chao Wan and Eliot Shekhtman and Kilian Q. Weinberger , editor =. Latent Diffusion for Language Generation , booktitle =. 2023 , url =
2023
-
[30]
Nature methods , volume=
Large-scale foundation model on single-cell transcriptomics , author=. Nature methods , volume=. 2024 , publisher=
2024
-
[31]
Nature Machine Intelligence , volume=
scBERT as a large-scale pretrained deep language model for cell type annotation of single-cell RNA-seq data , author=. Nature Machine Intelligence , volume=. 2022 , publisher=
2022
-
[32]
ACM computing surveys , volume=
Diffusion models: A comprehensive survey of methods and applications , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[33]
Dauphin , editor =
Jonas Gehring and Michael Auli and David Grangier and Denis Yarats and Yann N. Dauphin , editor =. Convolutional Sequence to Sequence Learning , booktitle =. 2017 , url =
2017
-
[34]
Vision transformers are parameter- efficient audio-visual learners
Zhaoyang Lyu and Jinyi Wang and Yuwei An and Ya Zhang and Dahua Lin and Bo Dai , title =. 2023 , url =. doi:10.1109/CVPR52729.2023.00034 , timestamp =
-
[35]
9th International Conference on Learning Representations,
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. 9th International Conference on Learning Representations,. 2021 , url =
2021
-
[36]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Point transformer , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[37]
Advances in Neural Information Processing Systems , volume=
Point transformer v2: Grouped vector attention and partition-based pooling , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Point transformer v3: Simpler faster stronger , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[39]
Xiaohui Zeng and Arash Vahdat and Francis Williams and Zan Gojcic and Or Litany and Sanja Fidler and Karsten Kreis , editor =. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022 , year =
2022
-
[40]
Linqi Zhou and Yilun Du and Jiajun Wu , title =. 2021. 2021 , url =. doi:10.1109/ICCV48922.2021.00577 , timestamp =
-
[41]
Shitong Luo and Wei Hu , title =. 2021 , url =. doi:10.1109/CVPR46437.2021.00286 , timestamp =
-
[42]
Macke , editor =
Jaivardhan Kapoor and Auguste Schulz and Julius Vetter and Felix Pei and Richard Gao and Jakob H. Macke , editor =. Latent Diffusion for Neural Spiking Data , booktitle =. 2024 , url =
2024
-
[43]
The Journal of Machine Learning Research , volume=
A kernel two-sample test , author=. The Journal of Machine Learning Research , volume=. 2012 , publisher=
2012
-
[44]
Nature biotechnology , volume=
Batch effects in single-cell RNA-sequencing data are corrected by matching mutual nearest neighbors , author=. Nature biotechnology , volume=. 2018 , publisher=
2018
-
[45]
Bioinformatics , volume=
scDiffusion: conditional generation of high-quality single-cell data using diffusion model , author=. Bioinformatics , volume=. 2024 , publisher=
2024
-
[46]
Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA,
Martin Heusel and Hubert Ramsauer and Thomas Unterthiner and Bernhard Nessler and Sepp Hochreiter , editor =. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA,. 2017 , url =
2017
-
[47]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[48]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:. 3rd International Conference on Learning Representations,. 2015 , url =
2015
-
[49]
Sculley and Gary Holt and Daniel Golovin and Eugene Davydov and Todd Phillips and Dietmar Ebner and Vinay Chaudhary and Michael Young and Jean
D. Sculley and Gary Holt and Daniel Golovin and Eugene Davydov and Todd Phillips and Dietmar Ebner and Vinay Chaudhary and Michael Young and Jean. Hidden Technical Debt in Machine Learning Systems , booktitle =. 2015 , url =
2015
-
[50]
BERT: Pre-training of deep bidi- rectional transformers for language understanding
Jacob Devlin and Ming. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,. 2019 , url =. doi:10.18653/V1/N19-1423 , timestamp =
-
[51]
Buntine and Dinh Phung and Mingyuan Zhou , editor =
He Zhao and Piyush Rai and Lan Du and Wray L. Buntine and Dinh Phung and Mingyuan Zhou , editor =. Variational Autoencoders for Sparse and Overdispersed Discrete Data , booktitle =. 2020 , url =
2020
-
[52]
On The Computational Complexity of Self-Attention , booktitle =
Feyza Duman Keles and Pruthuvi Mahesakya Wijewardena and Chinmay Hegde , editor =. On The Computational Complexity of Self-Attention , booktitle =. 2023 , url =
2023
-
[53]
Nature communications , volume=
Embracing the dropouts in single-cell RNA-seq analysis , author=. Nature communications , volume=. 2020 , publisher=
2020
-
[54]
Shuyang Gu and Dong Chen and Jianmin Bao and Fang Wen and Bo Zhang and Dongdong Chen and Lu Yuan and Baining Guo , title =. 2022 , url =. doi:10.1109/CVPR52688.2022.01043 , timestamp =
-
[55]
(No Title) , year=
Statistics for experimenters: an introduction to design, data analysis, and model building , author=. (No Title) , year=
-
[56]
IEEE Transactions on information theory , volume=
Compressed sensing , author=. IEEE Transactions on information theory , volume=. 2006 , publisher=
2006
-
[57]
2025 , url=
Sparse Data Diffusion for Scientific Simulations in Biology and Physics , author=. 2025 , url=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.