Recognition: 3 theorem links
· Lean TheoremIs Complexity the Problem? Testing Random Choice with Heterogeneity
Pith reviewed 2026-05-08 19:24 UTC · model grok-4.3
The pith
Heterogeneity in preferences alone accounts for apparent violations of stochastic transitivity in aggregate choice data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The collective rationalizability framework characterizes whether observed violations of standard random-choice models in aggregate data can be rationalized by comparison difficulty alone, by preference heterogeneity alone, or by both. In two existing data sets, heterogeneity alone suffices to explain the documented failures of stochastic transitivity, so that no variation in comparison difficulty is required once differences across individuals are allowed.
What carries the argument
The collective rationalizability framework, which extends revealed-preference ideas to aggregate data by checking whether observed choice frequencies can be generated by a mixture of individuals each satisfying a fixed random-choice model.
If this is right
- Observed failures of stochastic transitivity in aggregate data do not by themselves indicate that subjects find the options hard to compare.
- Mixtures of standard random-utility agents can reproduce the same aggregate inconsistencies that researchers have previously attributed to varying complexity.
- Re-estimation of comparison difficulty using aggregate data should first rule out heterogeneity as the sole source of inconsistency.
- The framework supplies a finite-sample statistical test that can be applied directly to existing choice experiments.
Where Pith is reading between the lines
- Past laboratory studies that fitted representative-agent models to group data may have overstated the role of decision difficulty; re-analysis with the new test could revise those estimates downward.
- The method could be used to decide whether future experiments should collect repeated individual choices or can continue to rely on one-shot aggregate observations.
- If heterogeneity explains most inconsistencies, then policy interventions aimed at reducing choice complexity may have smaller effects than models calibrated on aggregates would predict.
Load-bearing premise
The framework can reliably separate the contribution of comparison difficulty from that of preference heterogeneity in aggregate data without imposing strong restrictions on the shape of the preference distribution or the functional form of difficulty.
What would settle it
Apply the test to a data set in which every subject faces the same menu many times and individual-level choices are known to be consistent with a single fixed random-utility model; the aggregate data should then be rationalized by heterogeneity alone and not require additional difficulty variation.
Figures
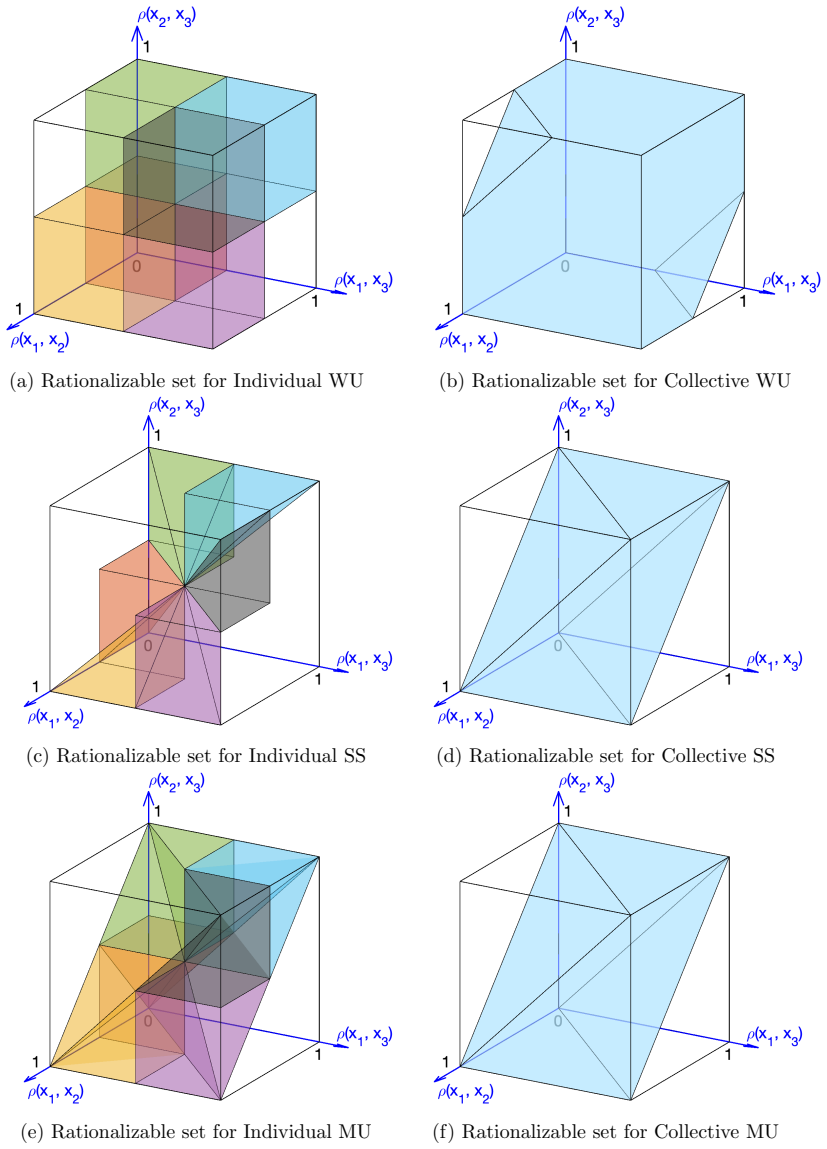




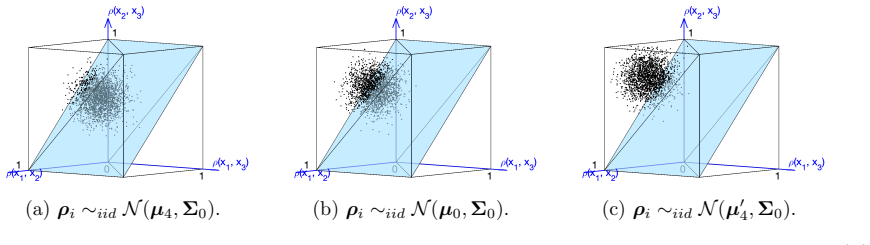


read the original abstract
Economic choices are often stochastic: the same person may make a different choice when facing the same alternatives repeatedly. Standard models assume that the degree of randomness reflects the size of utility differences, but choice inconsistencies could also reflect difficulty comparing alternatives. Recent studies estimate such comparison difficulty (or "complexity") by fitting functional forms to aggregate choice data under a representative agent assumption. However, aggregate data could violate standard models of random choice simply because of heterogeneity in preferences, even in the absence of variation in comparison difficulty. This paper develops a revealed preference framework, collective rationalizability, that tests for variation in comparison difficulty from aggregate data while explicitly accounting for heterogeneity. The framework characterizes whether violations of standard models can be explained by comparison difficulty alone, heterogeneity alone, or require both. I provide a statistical test with finite-sample inference and apply the method to two existing experiments. In both cases, heterogeneity alone explains observed failures of stochastic transitivity well, demonstrating that comparison difficulty can be not only theoretically but also empirically confused with heterogeneity in aggregate data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a revealed preference framework termed collective rationalizability to characterize whether violations of stochastic transitivity in aggregate choice data arise from preference heterogeneity alone, variation in comparison difficulty (complexity) alone, or both. It supplies a statistical test with finite-sample inference and applies the method to two existing experiments, concluding that heterogeneity alone accounts for the observed failures.
Significance. If the separation holds, the result cautions against attributing stochastic inconsistencies in aggregate data to complexity without first ruling out heterogeneity, with implications for interpreting random utility and random choice models. The provision of a statistical test with finite-sample inference is a strength, as is the explicit attempt to use revealed preference methods to decompose sources of violation.
major comments (2)
- [§3] §3 (Definition of collective rationalizability): The framework claims to isolate heterogeneity alone by checking membership in the convex hull of a fixed class of individual binary choice rules with constant comparison difficulty. However, without an explicit non-parametric characterization of that class (or a proof that it is strictly smaller than the set obtained when pair-specific difficulty parameters are admitted), the test cannot guarantee that data declared 'heterogeneity alone' would remain outside the larger set once difficulty variation is allowed.
- [§5] §5 (Empirical applications): The conclusion that heterogeneity alone explains the data in both experiments rests on the specific restrictions used to implement the test on aggregate frequencies. These restrictions must be stated explicitly (including the precise class of admissible individual rules and any maintained assumptions on preference distributions) so that readers can verify whether the separation is non-parametric or depends on functional-form choices.
minor comments (2)
- [Abstract] The abstract states that the test has 'finite-sample inference' but does not name the procedure; a brief description of the resampling or exact test method should appear in the main text near the first application.
- [§2] Notation for the aggregate choice probabilities and the individual rule class should be introduced once and used consistently; occasional shifts between p and P notation obscure the mapping from individual to collective objects.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the framework and its empirical implementation. We address each major point below and indicate the revisions planned.
read point-by-point responses
-
Referee: [§3] §3 (Definition of collective rationalizability): The framework claims to isolate heterogeneity alone by checking membership in the convex hull of a fixed class of individual binary choice rules with constant comparison difficulty. However, without an explicit non-parametric characterization of that class (or a proof that it is strictly smaller than the set obtained when pair-specific difficulty parameters are admitted), the test cannot guarantee that data declared 'heterogeneity alone' would remain outside the larger set once difficulty variation is allowed.
Authors: We agree that an explicit characterization strengthens the paper. The class of individual binary choice rules with constant comparison difficulty is defined non-parametrically as the set of all binary choice probabilities that satisfy the axioms of a random choice model with a single difficulty parameter applying uniformly across all pairs. In the revision we will state this characterization directly in §3 and add a short appendix proof that the convex hull under constant difficulty is strictly contained in the hull obtained when pair-specific difficulties are permitted (via a simple three-alternative example in which varying difficulty rationalizes a stochastic transitivity violation that constant difficulty cannot). This ensures the test isolates heterogeneity under the maintained constant-difficulty restriction. revision: yes
-
Referee: [§5] §5 (Empirical applications): The conclusion that heterogeneity alone explains the data in both experiments rests on the specific restrictions used to implement the test on aggregate frequencies. These restrictions must be stated explicitly (including the precise class of admissible individual rules and any maintained assumptions on preference distributions) so that readers can verify whether the separation is non-parametric or depends on functional-form choices.
Authors: We accept that greater transparency is needed. In the revised §5 we will explicitly list (i) the precise class of admissible individual rules (binary choice probabilities satisfying the constant-difficulty random choice axioms, with no further parametric restrictions on the form of the choice probabilities beyond the revealed-preference inequalities), and (ii) the maintained assumptions on the preference distribution (finite support over a fixed set of strict preference orders, with the mixing weights left completely unrestricted). This makes clear that the separation between heterogeneity alone and the other cases is non-parametric and does not rely on functional-form assumptions beyond the collective-rationalizability definition itself. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a revealed preference framework termed collective rationalizability to characterize whether aggregate violations of stochastic transitivity arise from comparison difficulty alone, heterogeneity alone, or both, while providing a statistical test with finite-sample inference. This framework is applied to two existing experiments, yielding the finding that heterogeneity alone accounts for the observed failures. No equations, definitions, or steps in the provided abstract or description reduce any central claim to a fitted input, self-definition, or self-citation chain by construction; the separation of factors is presented as an independent revealed-preference test rather than a tautological renaming or ansatz. The derivation chain remains self-contained against external data applications.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard random choice models (e.g., those implying stochastic transitivity) hold as the null against which violations are tested.
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.LogicAsFunctionalEquationwashburn_uniqueness_aczel unclearρ(x,y) = F((u(x)−u(y))/c(x,y)) ... distance metric / semimetric c : Z² → R₊
Reference graph
Works this paper leans on
-
[1]
I n(n−1) 2 · · ·I n(n−1) 2 1T n! # ,b ′ =
The following inequality holds for anyγ∈R n(n−1) 2 : (ρ− 1 21)T γ≥ − 1 2 X j: sgn(γ j)=sgn(ρ∗ k− 1 2 ) |γj|(43) wherek∈ {1, . . . , n!}is such that k= arg min k′ X j: sgn(ρ ∗ k′j − 1 2 )̸=sgn(γj) |γj|.(44) Proof.This Lemma provides an additional characterization for Collective WU, aimed at deriving its exact facet-defining inequalities. This is currently ...
-
[2]
= sgn(γj) 0 otherwise (61) We can eliminateβ k by plugging this maximizer into (59), and get −1 2 X J ++ k γj + 1 2 X J −− k γj + X J −+ k γj + X J ++ k ∪J −− k ρ∗ kj γj > X j ρjγj,∀1≤k≤n! (62) where we define index subsets J s1s2 k = 1≤j≤ n(n−1) 2 sgn(γj) =s 1,sgn(ρ ∗ kj − 1
-
[3]
=s 2 , s 1, s2 ∈ {+,−}.(63) Becauseρ ∗ kj ∈ {0,1}are known given the index subsetJ s1s2 k (determined by the signs 2), (62) can further be organized into X j∈J ++ k ( 1 2 −ρ j)γj + X j∈J −− k ( 1 2 −ρ j)γj + X j∈J +− k (−ρj)γj + X j∈J −+ k (1−ρ j)γj >0,∀1≤k≤n! (64) Up to now, we have shown that a vectorρ∈R n(n−1) 2 lies in conv(S) (i.e. is population-WST)...
-
[4]
Now we return to the actual scenario whereρ ∗ is only allowed to take a more restricted set of values P ∗ ={ρ ∗ k}n! k=1 ⊊{0,1} n(n−1) 2
=−sgn(γ j) whenever γj ̸= 0. Now we return to the actual scenario whereρ ∗ is only allowed to take a more restricted set of values P ∗ ={ρ ∗ k}n! k=1 ⊊{0,1} n(n−1) 2 . For a givenρ ∗ k, for eachjwhere sgn(ρ ∗ kj − 1
-
[5]
reverse ordering
and−sgn(γ j) differ, LHS of (65) increases by 1 2 |γj|. The optimalkis one that minimizes this total increase, which is k∗ = arg min k X j: sgn(ρ ∗ kj − 1 2 )=sgn(γj) |γj|.(66) We know thatρ ∗ ∈P ∗ ⇐ ⇒1−ρ ∗ ∈P ∗, and can let bkbe such thatρ ∗ bk =1−ρ ∗ k∗, namely the “reverse ordering” ofk ∗. Then we have bk= arg min k X j: sgn(ρ ∗ kj − 1 2 )̸=sgn(γj) |γj...
1972
-
[6]
Hence (73) can be rewritten as X j∈J + cjG(µj) = X j′∈J − cj′G(µj′),(74) whereGcan be any strictly increasing function withG(0) = 0
= 0 and|F −1(x)| ≥ |F −1(y)| ⇐ ⇒ |x− 1 2 | ≥ |y− 1 2 |. Hence (73) can be rewritten as X j∈J + cjG(µj) = X j′∈J − cj′G(µj′),(74) whereGcan be any strictly increasing function withG(0) = 0. We first prove part 1 of the result. BecauseJ + andJ − do not ranking-dominate each other, it follows that either strict inequality in (19) in both directions holds for...
-
[7]
CaseI.µ∈int(Q)∩int(C)
Interestingly, the following analysis relates closely to Fang and Santos (2019)’s discussion on convex set projections. CaseI.µ∈int(Q)∩int(C). AsN→ ∞, we have Pr[ ˆρ∈Q]→1. Because ˆρ∈Qimpliesπ Q( ˆρ) = ˆρ and thusT N = 0, this means Pr[ ˆρ= 0]→1 and thusT N converges to 0 in probability. CaseII.µ∈∂Q∩int(C). In this case, the distribution ofT N is more com...
2019
-
[8]
the limiting distributionTis a degenerate distribution equals 0 with probability 1
Under someµ∈Q,G N(x) converges in distribution toG(x) =1{x≥0}, i.e. the limiting distributionTis a degenerate distribution equals 0 with probability 1. Sinceg N,b(1−α)≥0, lim N→∞ Pr{TN ≤g N,b(1−α)}= 1.(95)
-
[9]
The validity of this subsampling test process is established in Politis et al
Under someµ∈Q,G n(x) converges in distribution toG(x), a mixture between a point mass at 0 and chi-squared distributions, with the point mass at 0 having weight no greater than 1 2. The validity of this subsampling test process is established in Politis et al. (1999), Theorem 2.2.1 and Theorem 2.6.1. Since the weight of the point mass 0 never exceeds 1 2,...
1999
-
[10]
pj(1−p j)µ2 j + ¯v2 j +p j(Σ0)jj pj(1−p j)µj pj(1−p j)µj pj(1−p j) #
In practice, we usually chooseα= 0.05. Therefore gN,b(1−α)− →g(1−α),(96) and lim N→∞ Pr[TN ≤g N,b(1−α)] = 1−α.(97) Combine Case (a) and (b), inf µ∈Q lim N→∞ Pr[TN ≤g N,b(1−α)] = 1−α.(98) A.7.5 Remarks on Testing Without Individual Data The numerical delta method with bootstrap procedure described above requires knowing which responses come from the same i...
2018
-
[11]
most favorable
= sgn(ρi′j − 1 2) for allj. 24 Let ˆρ(k) ij be participanti’sk-th repetition response to binary menuj, and denote ¯ρ ij = 1 10 P10 k=1 ˆρ(k) ij . To test this null hypothesis, first notice that it can be decomposed into a total of 2 17 individual hypotheses, each corresponding to one fixed sign pattern of sgn(ρi − 1 2). For each individual hypoth- esis, w...
-
[12]
= 1 and when sgn(ρ ij − 1
-
[13]
79 With this dataset, we getλ LR = 3363.02, and hence reject the null hypothesis withp <0.001
= 1. 79 With this dataset, we getλ LR = 3363.02, and hence reject the null hypothesis withp <0.001. Therefore, the test provides overwhelming evidence against the null hypothesis that all individuals share the same taste, further supporting the Collective SS model. 80
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.