Recognition: unknown
Robust Conditional Conformal Prediction via Branched Normalizing Flow
Pith reviewed 2026-05-10 16:25 UTC · model grok-4.3
The pith
Branched normalizing flow transports test inputs and prediction sets to preserve conditional coverage in conformal prediction under distribution shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We bound the conditional invalidity of CP under distribution shift in terms of the Wasserstein distance between the calibration and test distributions. This result highlights the role of invertible transport in mitigating conditional coverage degradation. Motivated by this insight, we introduce Branched Normalizing Flow (BNF), a two-branch architecture that normalizes a test input to the calibration distribution and transforms the prediction set of the normalized input back to the test distribution while preserving conditional guarantees.
What carries the argument
Branched Normalizing Flow (BNF), a two-branch architecture that normalizes a test input to the calibration distribution, applies conformal prediction there, and maps the resulting set back to the test distribution while preserving conditional guarantees.
If this is right
- Conditional coverage error scales with Wasserstein distance, so smaller shifts produce tighter guarantees.
- BNF maintains the original conditional coverage guarantees after transport rather than only marginal coverage.
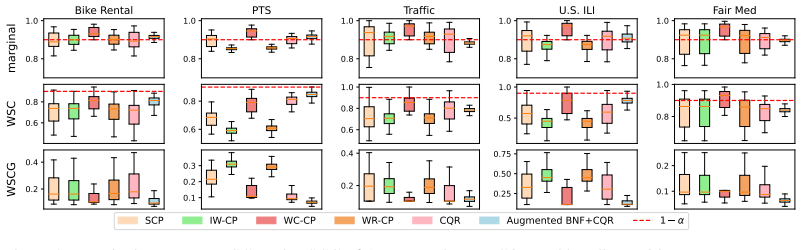
- The method yields measurable gains in conditional coverage robustness across nine datasets and a wide range of confidence levels.
- Marginal coverage remains intact while conditional reliability at individual test points improves.
Where Pith is reading between the lines
- The same transport principle could be applied to other uncertainty methods that currently guarantee only marginal rather than conditional coverage.
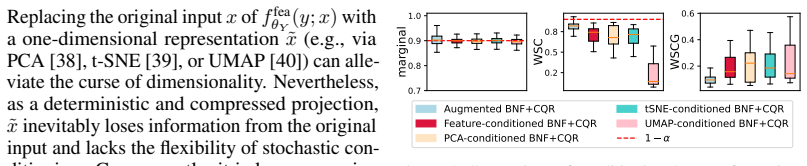
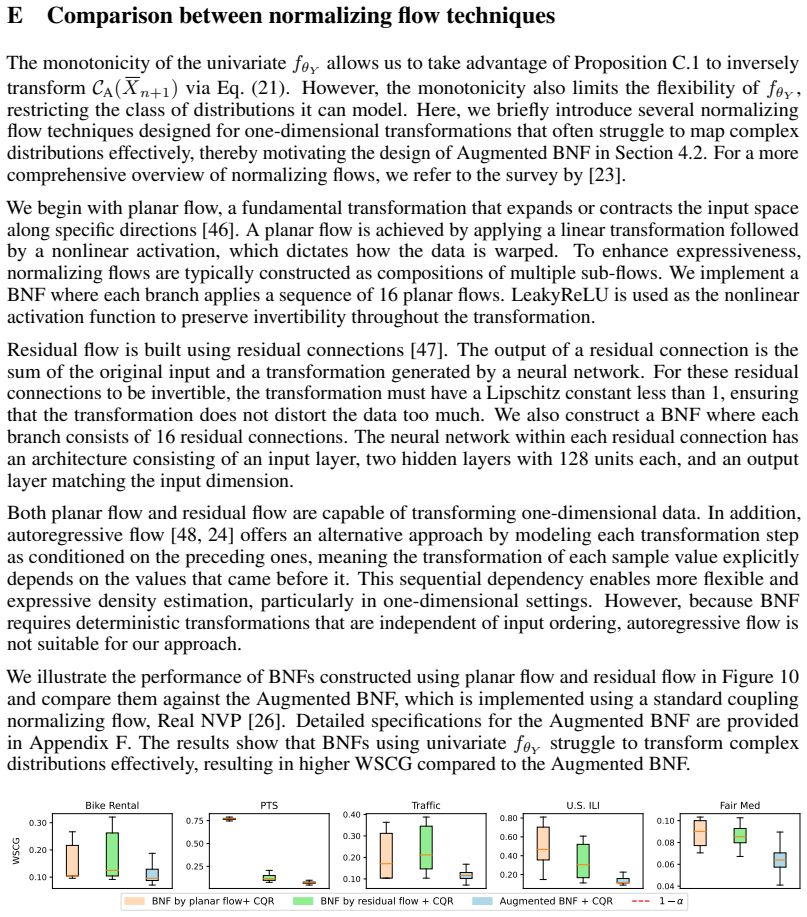
- When the learned flow is sufficiently accurate, the approach may extend to covariate shifts that are not purely location-scale.
- The Wasserstein bound supplies a practical diagnostic: if the estimated distance is large, the user knows conditional coverage will degrade even with perfect transport.
Load-bearing premise
An accurate invertible transport map between calibration and test distributions can be learned by the branched flow without introducing errors that break the conditional coverage guarantee.
What would settle it
Empirical observation that the conditional coverage error after BNF transport exceeds the Wasserstein-derived bound on a dataset with known shift would falsify the central bound and the preservation claim.
Figures




















read the original abstract
Conformal prediction (CP) constructs prediction sets with marginal coverage guarantees under the assumption that the calibration and test distributions are identical. However, under distribution shift, existing approaches primarily align marginal conformal score distributions, which is sufficient to preserve marginal coverage but does not control the conditional coverage error at individual test inputs. As a consequence, CP can remain unreliable in regions where the conditional score distributions are mismatched. In this work, we bound the conditional invalidity of CP under distribution shift in terms of the Wasserstein distance between the calibration and test distributions. This result highlights the role of invertible transport in mitigating conditional coverage degradation. Motivated by this insight, we introduce Branched Normalizing Flow (BNF), a two-branch architecture that normalizes a test input to the calibration distribution and transforms the prediction set of the normalized input back to the test distribution while preserving conditional guarantees. Empirically, BNF consistently improves conditional coverage robustness on nine datasets across a wide range of confidence levels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to derive a bound on the conditional invalidity of conformal prediction (CP) under distribution shift in terms of the Wasserstein distance between the joint calibration and test distributions. It introduces Branched Normalizing Flow (BNF), a two-branch architecture that learns an invertible transport to normalize test inputs to the calibration distribution, constructs the conformal set there, and pushes the set forward via the inverse map to the test distribution while preserving conditional coverage. Empirical evaluation on nine datasets is reported to show consistent improvements in conditional coverage robustness across confidence levels.
Significance. If the Wasserstein bound is rigorously established and the BNF approximation errors are controlled so that they do not invalidate the conditional guarantees, the work would provide a principled mechanism for achieving conditional coverage under shift, going beyond marginal score alignment. The empirical gains on multiple datasets indicate potential practical value, and the use of normalizing flows for exact transport is a targeted architectural contribution. However, the absence of derivation details and error propagation analysis in the current form limits the immediate impact.
major comments (3)
- [Theoretical analysis (bound on conditional invalidity)] The central theoretical claim bounds conditional invalidity via Wasserstein distance between calibration and test distributions (presumably via optimal transport of score functions). No derivation steps or key lemmas are provided, making it impossible to verify whether the bound correctly controls conditional coverage error at individual test inputs rather than only marginally.
- [Branched Normalizing Flow architecture and guarantee preservation] The BNF construction assumes the learned branched flow realizes an exact invertible transport map T that normalizes test points, obtains the conformal set under the calibration measure, and pushes it back via T^{-1} while exactly preserving conditional coverage. Because flow parameters are fit on finite data, the learned map is only approximate; no error term propagates the approximation error of T_hat through the coverage statement or shows that the empirical Wasserstein bound remains valid under the surrogate map. This is load-bearing for the robustness claim.
- [Experiments and evaluation] The empirical section reports gains on nine datasets but provides no description of how conditional coverage error is measured at individual test inputs, which baselines are used, or any statistical tests. Without these, the data-to-claim link cannot be verified and the results cannot be interpreted as evidence that BNF delivers the promised robustness.
minor comments (2)
- [Method] Clarify the precise definition of the branched flow architecture (e.g., how the two branches share parameters or enforce invertibility) and any regularization used to promote measure preservation.
- [Discussion] Add a limitations paragraph discussing when the learned transport may fail to be sufficiently accurate (e.g., high-dimensional inputs or complex shifts) and how this affects the practical utility of the Wasserstein bound.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the manuscript. We will revise to include the full theoretical derivation, an error propagation analysis for the approximate transport map, and detailed experimental protocols with statistical tests. These changes directly address the concerns while preserving the core contributions.
read point-by-point responses
-
Referee: The central theoretical claim bounds conditional invalidity via Wasserstein distance between calibration and test distributions (presumably via optimal transport of score functions). No derivation steps or key lemmas are provided, making it impossible to verify whether the bound correctly controls conditional coverage error at individual test inputs rather than only marginally.
Authors: We agree that the derivation must be fully explicit. The bound follows from applying the Kantorovich-Rubinstein duality to the difference between conditional coverage probabilities under the calibration and test measures, using the Lipschitz continuity of the conformal score function with respect to the input. A key supporting lemma shows that the Wasserstein distance between the joint distributions induces a pointwise bound on the conditional coverage gap for each fixed test input x via integration against the conditional density. We will insert the complete proof, including all lemmas and the explicit dependence on the Wasserstein distance, as a new appendix section in the revision. revision: yes
-
Referee: The BNF construction assumes the learned branched flow realizes an exact invertible transport map T that normalizes test points, obtains the conformal set under the calibration measure, and pushes it back via T^{-1} while exactly preserving conditional coverage. Because flow parameters are fit on finite data, the learned map is only approximate; no error term propagates the approximation error of T_hat through the coverage statement or shows that the empirical Wasserstein bound remains valid under the surrogate map. This is load-bearing for the robustness claim.
Authors: This is a valid point. The current manuscript treats the learned flow as an approximation to the ideal transport without quantifying the residual. In revision we will add a theorem that decomposes the total conditional coverage error into the Wasserstein term plus an additive error controlled by the total variation distance between the learned pushforward and the true calibration measure. We further show that this additional term vanishes as the flow training loss (negative log-likelihood on the calibration data) approaches zero, and we include a brief empirical check of flow reconstruction error on held-out calibration points. revision: yes
-
Referee: The empirical section reports gains on nine datasets but provides no description of how conditional coverage error is measured at individual test inputs, which baselines are used, or any statistical tests. Without these, the data-to-claim link cannot be verified and the results cannot be interpreted as evidence that BNF delivers the promised robustness.
Authors: We will expand the experimental section with a dedicated subsection. Conditional coverage error is computed by binning test inputs according to a kernel density estimate of the calibration distribution and reporting the average absolute deviation from the target coverage level within each bin; results are averaged over 10 random train-calibration-test splits. Baselines comprise standard split conformal prediction, marginal score alignment via quantile regression, and two recent conditional conformal methods. We will report mean and standard deviation across splits together with paired Wilcoxon signed-rank tests (p-values) to establish statistical significance of the observed improvements. revision: yes
Circularity Check
No circularity: bound derived from external Wasserstein theory; BNF approximates transport without reducing guarantee to fitted input
full rationale
The paper first states a bound on conditional invalidity expressed in terms of the Wasserstein distance between calibration and test distributions. This bound is presented as a general result from optimal transport and does not depend on the BNF parameters or any fitted quantity defined inside the method. The BNF is then introduced as a practical architecture to realize an approximate invertible map that pushes the conformal set forward while aiming to preserve the conditional property. No equation equates the coverage guarantee to a self-defined score or renames a fitted residual as a prediction. No self-citation is used to justify a uniqueness claim or to smuggle an ansatz. The derivation therefore remains self-contained against external benchmarks (Wasserstein geometry and standard normalizing-flow invertibility) rather than collapsing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An invertible transport map between calibration and test distributions exists and can be approximated by a branched normalizing flow without destroying conditional coverage properties.
invented entities (1)
-
Branched Normalizing Flow (BNF)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Springer, 2005
Vladimir V ovk, Alexander Gammerman, and Glenn Shafer.Algorithmic learning in a random world, volume 29. Springer, 2005
2005
-
[2]
A tutorial on conformal prediction, 2007
Glenn Shafer and Vladimir V ovk. A tutorial on conformal prediction, 2007
2007
-
[3]
Tibshirani, and Larry Wasserman
Jing Lei, Max G’Sell, Alessandro Rinaldo, Ryan J. Tibshirani, and Larry Wasserman. Distribution-free predictive inference for regression, 2017
2017
-
[4]
Regression conformal prediction with nearest neighbours.Journal of Artificial Intelligence Research, 40:815–840, 2011
Harris Papadopoulos, Vladimir V ovk, and Alex Gammerman. Regression conformal prediction with nearest neighbours.Journal of Artificial Intelligence Research, 40:815–840, 2011
2011
-
[5]
Conditional validity of inductive conformal predictors
Vladimir V ovk. Conditional validity of inductive conformal predictors. InAsian conference on machine learning, pages 475–490. PMLR, 2012
2012
-
[6]
Out-of-distribution generalization via risk ex- trapolation (rex)
David Krueger, Ethan Caballero, Joern-Henrik Jacobsen, Amy Zhang, Jonathan Binas, Dinghuai Zhang, Remi Le Priol, and Aaron Courville. Out-of-distribution generalization via risk ex- trapolation (rex). InInternational conference on machine learning, pages 5815–5826. PMLR, 2021
2021
-
[7]
Conformal prediction beyond exchangeability.The Annals of Statistics, 51(2):816–845, 2023
Rina Foygel Barber, Emmanuel J Candes, Aaditya Ramdas, and Ryan J Tibshirani. Conformal prediction beyond exchangeability.The Annals of Statistics, 51(2):816–845, 2023
2023
-
[8]
Wasserstein-regularized conformal prediction under general distribution shift
Rui Xu, Chao Chen, Yue Sun, Parvathinathan Venkitasubramaniam, and Sihong Xie. Wasserstein-regularized conformal prediction under general distribution shift. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[9]
Physicochemical properties of protein tertiary structure
Prashant Rana. Physicochemical Properties of Protein Tertiary Structure. UCI Machine Learning Repository, 2013. DOI: https://doi.org/10.24432/C5QW3H
-
[10]
Hadi Fanaee-T. Bike Sharing. UCI Machine Learning Repository, 2013. DOI: https://doi.org/10.24432/C5W894
-
[11]
Zhiyong Cui, Kristian Henrickson, Ruimin Ke, and Yinhai Wang. Traffic graph convolutional recurrent neural network: A deep learning framework for network-scale traffic learning and forecasting.IEEE Transactions on Intelligent Transportation Systems, 2019
2019
-
[12]
Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al. Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
2023
-
[13]
The eicu collaborative research database, a freely available multi-center database for critical care research.Scientific data, 5(1):1–13, 2018
Tom J Pollard, Alistair EW Johnson, Jesse D Raffa, Leo A Celi, Roger G Mark, and Omar Badawi. The eicu collaborative research database, a freely available multi-center database for critical care research.Scientific data, 5(1):1–13, 2018
2018
-
[14]
Cola-gnn: Cross-location attention based graph neural networks for long-term ili prediction
Songgaojun Deng, Shusen Wang, Huzefa Rangwala, Lijing Wang, and Yue Ning. Cola-gnn: Cross-location attention based graph neural networks for long-term ili prediction. InProceedings of the 29th ACM international conference on information & knowledge management, pages 245–254, 2020
2020
-
[15]
Inductive confidence machines for regression
Harris Papadopoulos, Kostas Proedrou, V olodya V ovk, and Alex Gammerman. Inductive confidence machines for regression. InMachine learning: ECML 2002: 13th European conference on machine learning Helsinki, Finland, August 19–23, 2002 proceedings 13, pages 345–356. Springer, 2002
2002
-
[16]
Conformal risk control.arXiv preprint arXiv:2208.02814,
Anastasios N Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. Confor- mal risk control.arXiv preprint arXiv:2208.02814, 2022
-
[17]
Robust validation: Confident predictions even when distributions shift.Journal of the American Statistical Association, pages 1–66, 2024
Maxime Cauchois, Suyash Gupta, Alnur Ali, and John C Duchi. Robust validation: Confident predictions even when distributions shift.Journal of the American Statistical Association, pages 1–66, 2024. 10
2024
-
[18]
Coverage-guaranteed prediction sets for out-of-distribution data
Xin Zou and Weiwei Liu. Coverage-guaranteed prediction sets for out-of-distribution data. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17263–17270, 2024
2024
-
[19]
Federated conformal predictors for distributed uncertainty quantification
Charles Lu, Yaodong Yu, Sai Praneeth Karimireddy, Michael Jordan, and Ramesh Raskar. Federated conformal predictors for distributed uncertainty quantification. InInternational Conference on Machine Learning, pages 22942–22964. PMLR, 2023
2023
-
[20]
Distributed conformal prediction via message passing, 2025
Haifeng Wen, Hong Xing, and Osvaldo Simeone. Distributed conformal prediction via message passing, 2025
2025
-
[21]
Statistical aspects of wasserstein distances.Annual review of statistics and its application, 6(1):405–431, 2019
Victor M Panaretos and Yoav Zemel. Statistical aspects of wasserstein distances.Annual review of statistics and its application, 6(1):405–431, 2019
2019
-
[22]
Fundamentals of stein’s method
Nathan Ross. Fundamentals of stein’s method. 2011
2011
-
[23]
Normalizing flows: An introduction and review of current methods.IEEE transactions on pattern analysis and machine intelligence, 43(11):3964–3979, 2020
Ivan Kobyzev, Simon JD Prince, and Marcus A Brubaker. Normalizing flows: An introduction and review of current methods.IEEE transactions on pattern analysis and machine intelligence, 43(11):3964–3979, 2020
2020
-
[24]
Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64, 2021
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64, 2021
2021
-
[25]
Augmented normalizing flows: Bridging the gap between generative flows and latent variable models, 2020
Chin-Wei Huang, Laurent Dinh, and Aaron Courville. Augmented normalizing flows: Bridging the gap between generative flows and latent variable models, 2020
2020
-
[26]
Density estimation using Real NVP
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real nvp. arXiv preprint arXiv:1605.08803, 2016
work page internal anchor Pith review arXiv 2016
-
[27]
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization.arXiv preprint arXiv:1911.08731, 2019
work page internal anchor Pith review arXiv 1911
-
[28]
The limits of distribution-free conditional predictive inference.Information and Inference: A Journal of the IMA, 10(2):455–482, 2021
Rina Foygel Barber, Emmanuel J Candes, Aaditya Ramdas, and Ryan J Tibshirani. The limits of distribution-free conditional predictive inference.Information and Inference: A Journal of the IMA, 10(2):455–482, 2021
2021
-
[29]
Conformalized quantile regression
Yaniv Romano, Evan Patterson, and Emmanuel Candes. Conformalized quantile regression. Advances in neural information processing systems, 32, 2019
2019
-
[30]
normflows: A pytorch package for normalizing flows.Journal of Open Source Software, 8(86):5361, 2023
Vincent Stimper, David Liu, Andrew Campbell, Vincent Berenz, Lukas Ryll, Bernhard Schölkopf, and José Miguel Hernández-Lobato. normflows: A pytorch package for normalizing flows.Journal of Open Source Software, 8(86):5361, 2023
2023
-
[31]
Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
2013
-
[32]
The sinkhorn–knopp algorithm: convergence and applications.SIAM Journal on Matrix Analysis and Applications, 30(1):261–275, 2008
Philip A Knight. The sinkhorn–knopp algorithm: convergence and applications.SIAM Journal on Matrix Analysis and Applications, 30(1):261–275, 2008
2008
-
[33]
Interpolating between optimal transport and mmd using sinkhorn divergences
Jean Feydy, Thibault Séjourné, François-Xavier Vialard, Shun-ichi Amari, Alain Trouve, and Gabriel Peyré. Interpolating between optimal transport and mmd using sinkhorn divergences. InThe 22nd International Conference on Artificial Intelligence and Statistics, pages 2681–2690, 2019
2019
-
[34]
Conformal prediction under covariate shift.Advances in neural information processing systems, 32, 2019
Ryan J Tibshirani, Rina Foygel Barber, Emmanuel Candes, and Aaditya Ramdas. Conformal prediction under covariate shift.Advances in neural information processing systems, 32, 2019
2019
-
[35]
Adversarially robust conformal prediction
Asaf Gendler, Tsui-Wei Weng, Luca Daniel, and Yaniv Romano. Adversarially robust conformal prediction. InInternational Conference on Learning Representations, 2021
2021
-
[36]
Adaptive graph convolutional recurrent network for traffic forecasting.Advances in neural information processing systems, 33:17804–17815, 2020
Lei Bai, Lina Yao, Can Li, Xianzhi Wang, and Can Wang. Adaptive graph convolutional recurrent network for traffic forecasting.Advances in neural information processing systems, 33:17804–17815, 2020. 11
2020
-
[37]
Knowing what you know: valid and validated confidence sets in multiclass and multilabel prediction.Journal of machine learning research, 22(81):1–42, 2021
Maxime Cauchois, Suyash Gupta, and John C Duchi. Knowing what you know: valid and validated confidence sets in multiclass and multilabel prediction.Journal of machine learning research, 22(81):1–42, 2021
2021
-
[38]
Principal component analysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010
Hervé Abdi and Lynne J Williams. Principal component analysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010
2010
-
[39]
Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
2008
-
[40]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review arXiv 2018
-
[41]
Adaptive conformal classification with noisy labels
Matteo Sesia, YX Wang, and Xin Tong. Adaptive conformal classification with noisy labels. arXiv preprint arXiv:2309.05092, 2023
-
[42]
Conformal prediction is robust to label noise.arXiv preprint arXiv:2209.14295, 2, 2022
Bat-Sheva Einbinder, Stephen Bates, Anastasios N Angelopoulos, Asaf Gendler, and Yaniv Romano. Conformal prediction is robust to label noise.arXiv preprint arXiv:2209.14295, 2, 2022
-
[43]
The speed of mean glivenko-cantelli convergence.The Annals of Mathematical Statistics, 40(1):40–50, 1969
Richard Mansfield Dudley. The speed of mean glivenko-cantelli convergence.The Annals of Mathematical Statistics, 40(1):40–50, 1969
1969
-
[44]
Sharp asymptotic and finite-sample rates of convergence of empirical measures in wasserstein distance
Jonathan Weed and Francis Bach. Sharp asymptotic and finite-sample rates of convergence of empirical measures in wasserstein distance. 2019
2019
-
[45]
Springer Science & Business Media, 2007
Irene Fonseca and Giovanni Leoni.Modern methods in the calculus of variations: Lˆ p spaces. Springer Science & Business Media, 2007
2007
-
[46]
Variational inference with normalizing flows, 2016
Danilo Jimenez Rezende and Shakir Mohamed. Variational inference with normalizing flows, 2016
2016
-
[47]
Deep residual learning for image recognition, 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015
2015
-
[48]
Improved variational inference with inverse autoregressive flow.Advances in neural information processing systems, 29, 2016
Durk P Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, and Max Welling. Improved variational inference with inverse autoregressive flow.Advances in neural information processing systems, 29, 2016
2016
-
[49]
Mondrian conformal predictive distri- butions
Henrik Boström, Ulf Johansson, and Tuwe Löfström. Mondrian conformal predictive distri- butions. InConformal and Probabilistic Prediction and Applications, pages 24–38. PMLR, 2021
2021
-
[50]
Locally valid and discriminative prediction intervals for deep learning models.Advances in Neural Information Processing Systems, 34:8378–8391, 2021
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Locally valid and discriminative prediction intervals for deep learning models.Advances in Neural Information Processing Systems, 34:8378–8391, 2021
2021
-
[51]
Localized conformal prediction: A generalized inference framework for confor- mal prediction.Biometrika, 110(1):33–50, 2023
Leying Guan. Localized conformal prediction: A generalized inference framework for confor- mal prediction.Biometrika, 110(1):33–50, 2023
2023
-
[52]
arXiv preprint arXiv:2305.12616 , year=
Isaac Gibbs, John J Cherian, and Emmanuel J Candès. Conformal prediction with conditional guarantees.arXiv preprint arXiv:2305.12616, 2023
-
[53]
An information theoretic perspective on conformal prediction.Advances in Neural Information Processing Systems, 37:101000–101041, 2024
Alvaro Correia, Fabio Valerio Massoli, Christos Louizos, and Arash Behboodi. An information theoretic perspective on conformal prediction.Advances in Neural Information Processing Systems, 37:101000–101041, 2024
2024
-
[54]
Learning optimal conformal classifiers, 2022
David Stutz, Ali Taylan Cemgil, Arnaud Doucet, et al. Learning optimal conformal classifiers. arXiv preprint arXiv:2110.09192, 2021
-
[55]
On volume minimization in conformal regression, 2025
Batiste Le Bars and Pierre Humbert. On volume minimization in conformal regression, 2025
2025
-
[56]
Improving conditional coverage via orthog- onal quantile regression.Advances in neural information processing systems, 34:2060–2071, 2021
Shai Feldman, Stephen Bates, and Yaniv Romano. Improving conditional coverage via orthog- onal quantile regression.Advances in neural information processing systems, 34:2060–2071, 2021. 12
2060
-
[57]
Normalizing flows for conformal regression.arXiv preprint arXiv:2406.03346, 2024
Nicolo Colombo. Normalizing flows for conformal regression.arXiv preprint arXiv:2406.03346, 2024
-
[58]
Contra: Conformal prediction region via normalizing flow transformation
Zhenhan Fang, Aixin Tan, and Jian Huang. Contra: Conformal prediction region via normalizing flow transformation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[59]
Multivariate conformal prediction using optimal transport, 2025
Michal Klein, Louis Bethune, Eugene Ndiaye, and Marco Cuturi. Multivariate conformal prediction using optimal transport, 2025
2025
-
[60]
Optimal transport-based conformal predic- tion, 2025
Gauthier Thurin, Kimia Nadjahi, and Claire Boyer. Optimal transport-based conformal predic- tion, 2025
2025
-
[61]
Estimating conditional quantiles with the help of the pinball loss
Ingo Steinwart and Andreas Christmann. Estimating conditional quantiles with the help of the pinball loss. 2011
2011
-
[62]
Johnson, and Hannes Leeb
Danijel Kivaranovic, Kory D. Johnson, and Hannes Leeb. Adaptive, distribution-free prediction intervals for deep networks, 2020
2020
-
[63]
Matteo Sesia and Emmanuel J. Candès. A comparison of some conformal quantile regression methods.Stat, 9(1), January 2020
2020
-
[64]
PhD thesis, Université Paris-Saclay, 2020
Jean Feydy.Analyse de données géométriques, au delà des convolutions. PhD thesis, Université Paris-Saclay, 2020
2020
-
[65]
Domain adaptation for time series forecasting via attention sharing
Xiaoyong Jin, Youngsuk Park, Danielle Maddix, Hao Wang, and Yuyang Wang. Domain adaptation for time series forecasting via attention sharing. InInternational Conference on Machine Learning, pages 10280–10297. PMLR, 2022
2022
-
[66]
Reaction-diffusion graph ordinary differential equation networks: Traffic-law-informed speed prediction under mismatched data
Yue Sun, Chao Chen, Yuesheng Xu, Sihong Xie, Rick S Blum, and Parv Venkitasubramaniam. Reaction-diffusion graph ordinary differential equation networks: Traffic-law-informed speed prediction under mismatched data. The 12th International Workshop on Urban Computing, held in conjunction with . . . , 2023
2023
-
[67]
Multicenter studies: relevance, design and implementation.Indian pediatrics, 59(7):571–579, 2022
Manoja Kumar Das. Multicenter studies: relevance, design and implementation.Indian pediatrics, 59(7):571–579, 2022
2022
-
[68]
Estimating diagnostic uncertainty in artificial intelligence assisted pathology using conformal prediction.Nature communications, 13(1):7761, 2022
Henrik Olsson, Kimmo Kartasalo, Nita Mulliqi, Marco Capuccini, Pekka Ruusuvuori, Hema- mali Samaratunga, Brett Delahunt, Cecilia Lindskog, Emiel AM Janssen, Anders Blilie, et al. Estimating diagnostic uncertainty in artificial intelligence assisted pathology using conformal prediction.Nature communications, 13(1):7761, 2022
2022
-
[69]
Pandemic Intervals Framework (PIF) — cdc.gov
CDC. Pandemic Intervals Framework (PIF) — cdc.gov. https://www.cdc.gov/ pandemic-flu/php/national-strategy/intervals-framework.html?CDC_AAref_ Val=https://www.cdc.gov/flu/pandemic-resources/national-strategy/ intervals-framework.html. [Accessed 28-04-2025]
2025
-
[70]
Tiberiu Harko, Francisco SN Lobo, and Man Kwong Mak. Exact analytical solutions of the susceptible-infected-recovered (sir) epidemic model and of the sir model with equal death and birth rates.Applied Mathematics and Computation, 236:184–194, 2014
2014
-
[71]
Analysis of sir epidemic model with information spreading of awareness.Chaos, Solitons & Fractals, 119:118–125, 2019
KM Ariful Kabir, Kazuki Kuga, and Jun Tanimoto. Analysis of sir epidemic model with information spreading of awareness.Chaos, Solitons & Fractals, 119:118–125, 2019
2019
-
[72]
A restricted epidemic sir model with elementary solutions.Physica A: Statistical Mechanics and its Applications, 600:127570, 2022
Mustafa Turkyilmazoglu. A restricted epidemic sir model with elementary solutions.Physica A: Statistical Mechanics and its Applications, 600:127570, 2022
2022
-
[73]
Classification with valid and adaptive coverage.Advances in Neural Information Processing Systems, 33:3581–3591, 2020
Yaniv Romano, Matteo Sesia, and Emmanuel Candes. Classification with valid and adaptive coverage.Advances in Neural Information Processing Systems, 33:3581–3591, 2020
2020
-
[74]
The expressive power of a class of normalizing flow models, 2020
Zhifeng Kong and Kamalika Chaudhuri. The expressive power of a class of normalizing flow models, 2020. 13
2020
-
[75]
Why and when can deep-but not shallow-networks avoid the curse of dimensionality: a review
Tomaso Poggio, Hrushikesh Mhaskar, Lorenzo Rosasco, Brando Miranda, and Qianli Liao. Why and when can deep-but not shallow-networks avoid the curse of dimensionality: a review. International Journal of Automation and Computing, 14(5):503–519, 2017
2017
-
[76]
Distribution-free prediction bands for non-parametric regression
Jing Lei and Larry Wasserman. Distribution-free prediction bands for non-parametric regression. Journal of the Royal Statistical Society Series B: Statistical Methodology, 76(1):71–96, 2014
2014
-
[77]
Uncertainty sets for image classifiers using conformal prediction.arXiv:2009.14193,
Anastasios Angelopoulos, Stephen Bates, Jitendra Malik, and Michael I Jordan. Uncertainty sets for image classifiers using conformal prediction.arXiv preprint arXiv:2009.14193, 2020
-
[78]
On temperature scaling and conformal prediction of deep classifiers, 2025
Lahav Dabah and Tom Tirer. On temperature scaling and conformal prediction of deep classifiers, 2025
2025
-
[79]
Does confidence calibration improve conformal prediction?, 2024
Huajun Xi, Jianguo Huang, Kangdao Liu, Lei Feng, and Hongxin Wei. Does confidence calibration improve conformal prediction?, 2024
2024
-
[80]
Selection and aggregation of conformal prediction sets, 2024
Yachong Yang and Arun Kumar Kuchibhotla. Selection and aggregation of conformal prediction sets, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.