Recognition: 3 theorem links
· Lean TheoremDR-SNE: Density-Regularized Stochastic Neighbor Embedding
Pith reviewed 2026-05-08 19:20 UTC · model grok-4.3
The pith
DR-SNE augments stochastic neighbor embedding with a density regularization term from normalized log-density estimates to preserve relative density variations in a scale-invariant way.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DR-SNE augments the stochastic neighbor embedding objective with a density regularization term derived from normalized log-density estimates, providing a simple and scale-invariant mechanism for preserving relative density variations.
What carries the argument
The density regularization term derived from normalized log-density estimates, which directly aligns relative density structure alongside conditional neighborhood probabilities in the embedding space.
If this is right
- Density preservation improves on standard SNE while neighborhood structure remains competitive.
- The method yields measurable gains on density-sensitive tasks such as anomaly detection.
- The regularization works across multiple datasets without requiring local scale consistency.
- Direct alignment of normalized densities offers a simpler alternative to scale-based density methods.
Where Pith is reading between the lines
- Similar density alignment could be added to other neighborhood-preserving embeddings to test broader applicability.
- Embeddings that retain density information may support more reliable clustering or visualization of density gradients.
- The approach implies that density statistics should be treated as a first-class objective alongside geometry in future dimensionality reduction work.
Load-bearing premise
Normalized log-density estimates can be aligned directly in the low-dimensional space without introducing distortions that outweigh the benefit of preserving relative densities.
What would settle it
A dataset with reliable density estimates where DR-SNE embeddings exhibit measurably worse local neighborhood preservation or no improvement in anomaly detection accuracy relative to standard t-SNE would refute the central claim.
Figures






read the original abstract
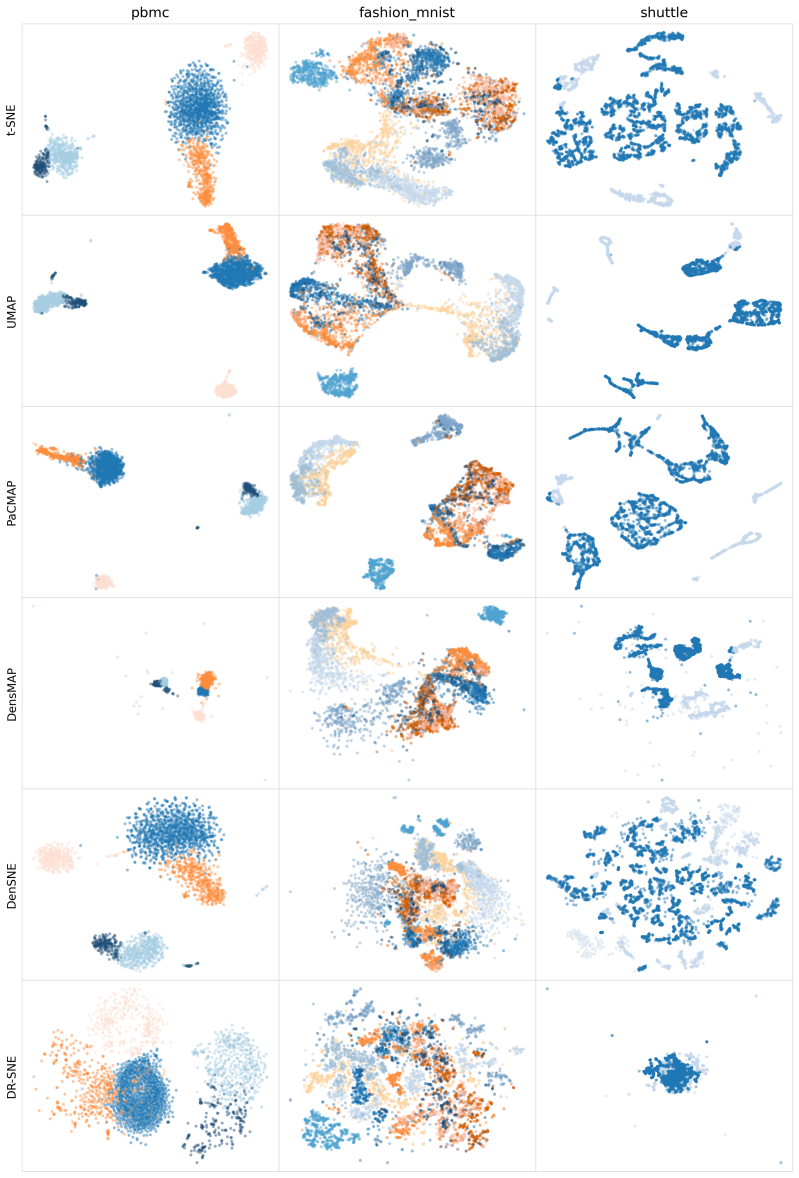
Dimensionality reduction methods such as t-SNE are designed to preserve local neighborhood structure but do not explicitly account for how probability mass is distributed, often leading to distortions of data density. We reformulate dimensionality reduction as the joint alignment of two components: (i) conditional structure, capturing local relationships, and (ii) relative density structure, captured via local density statistics. Based on this perspective, we introduce Density-Regularized SNE (DR-SNE), which augments the stochastic neighbor embedding objective with a density regularization term derived from normalized log-density estimates. Unlike prior approaches such as DensMAP and DenSNE, which rely on local scale consistency, DR-SNE directly aligns normalized density estimates, providing a simple and scale-invariant mechanism for preserving relative density variations. Empirically, DR-SNE improves density preservation while maintaining competitive neighborhood fidelity, and yields gains on density-sensitive tasks such as anomaly detection across multiple datasets. These results suggest that incorporating density information complements geometry-focused objectives in dimensionality reduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce DR-SNE, which augments the stochastic neighbor embedding (SNE) objective with a density regularization term based on normalized log-density estimates. This is presented as a joint alignment of conditional structure and relative density structure, leading to improved preservation of relative density variations while maintaining neighborhood fidelity, with empirical gains on anomaly detection tasks.
Significance. The proposed method offers a simple alternative to existing density-aware dimensionality reduction techniques like DensMAP and DenSNE by directly aligning normalized densities rather than relying on local scale consistency. If the empirical results hold under rigorous validation, it could provide a useful tool for density-sensitive applications in machine learning and data visualization.
major comments (3)
- §3 (DR-SNE formulation): The density regularization term aligns normalized log-density estimates, but there is no analysis or derivation demonstrating that this alignment does not amplify noise from high-dimensional density estimation, which is known to be sensitive to bandwidth and sample size.
- Experimental section: The abstract reports empirical gains on density preservation and anomaly detection, but the manuscript lacks details on implementation, hyperparameter selection, statistical significance testing, and controls for confounding factors, undermining verification of the central claim.
- §4.2 (Comparison with prior work): The claim of scale-invariance is asserted via normalization, but without a specific equation or proof showing the term remains well-behaved under fluctuating density estimates, the advantage over prior approaches is not fully established.
minor comments (2)
- Abstract: The abstract could specify the datasets used and provide quantitative metrics for the claimed improvements rather than qualitative statements.
- Notation: The notation for the density estimates and the regularization weight should be clearly defined early in the paper for readability.
Simulated Author's Rebuttal
Thank you for your thoughtful review of our paper on DR-SNE. We have carefully considered your comments and provide point-by-point responses below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: §3 (DR-SNE formulation): The density regularization term aligns normalized log-density estimates, but there is no analysis or derivation demonstrating that this alignment does not amplify noise from high-dimensional density estimation, which is known to be sensitive to bandwidth and sample size.
Authors: We agree that a more rigorous treatment of potential noise amplification is warranted. In the revised manuscript, we will include an analysis in Section 3 discussing the properties of the normalized log-density regularization term. Specifically, we will derive that the normalization step (dividing by the sum of densities) provides a degree of robustness to uniform scaling, and we will reference literature on stable density estimation techniques. Additionally, we will present empirical results showing the sensitivity to bandwidth choices and how our method performs under different settings. revision: yes
-
Referee: Experimental section: The abstract reports empirical gains on density preservation and anomaly detection, but the manuscript lacks details on implementation, hyperparameter selection, statistical significance testing, and controls for confounding factors, undermining verification of the central claim.
Authors: We acknowledge the need for greater transparency in the experimental setup. The revised version will expand the experimental section to include: (1) detailed implementation code references or pseudocode, (2) the procedure for hyperparameter selection (e.g., grid search on validation sets), (3) statistical significance tests such as t-tests comparing DR-SNE to baselines with p-values reported, and (4) additional experiments controlling for factors like dataset size and density estimation parameters to isolate the effect of the regularization term. revision: yes
-
Referee: §4.2 (Comparison with prior work): The claim of scale-invariance is asserted via normalization, but without a specific equation or proof showing the term remains well-behaved under fluctuating density estimates, the advantage over prior approaches is not fully established.
Authors: The scale-invariance is achieved through the use of normalized densities in the regularization term, as defined in Equation (X) of the paper. We will add an explicit equation and a short derivation in Section 4.2 demonstrating that the term is invariant to multiplicative scaling of the density estimates. Regarding fluctuating (noisy) estimates, we will clarify that while normalization helps, it does not eliminate all sensitivity, and we will compare it more explicitly to DensMAP and DenSNE under such conditions. This will better establish the advantages. revision: partial
Circularity Check
No circularity: DR-SNE augments SNE with externally derived density term
full rationale
The paper's core construction augments the standard SNE objective with a regularization term based on normalized log-density estimates computed from the input data. This term is defined from independent density statistics rather than being fitted to the embedding or defined in terms of the target quantity itself. No equations reduce a claimed prediction to a fitted parameter by construction, no self-citation chains justify uniqueness or ansatzes, and the reformulation as joint alignment of structure and density is presented as an additive extension rather than a renaming or self-referential definition. The derivation remains self-contained against external benchmarks such as standard SNE and prior density-aware methods.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Conditional probabilities in high-dimensional space can be modeled by Gaussian kernels as in standard SNE
- domain assumption Normalized log-density estimates accurately reflect relative density variations that should be preserved
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Cost.Jcostwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L_dens = (1/n) Σ (log ρ̃_i^(X) − log ρ̃_i^(Z))²
-
Foundation (zero-parameter forcing chain)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
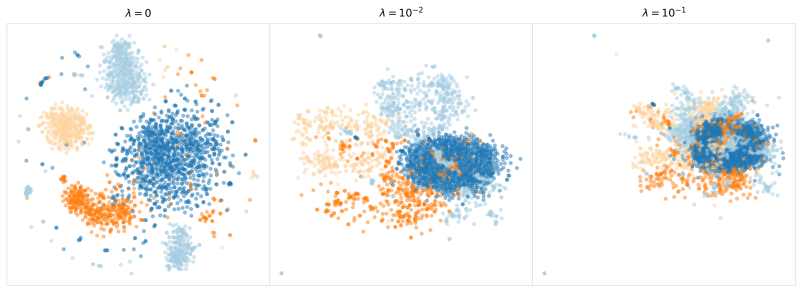
λ ∈ {10⁻⁴, ..., 10⁻¹} ... ablation over density regularization strength λ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
How to use t-sne effectively.Distill, 2016
Martin Wattenberg, Fernanda Vi ´egas, and Ian Johnson. How to use t-sne effectively.Distill, 2016
2016
-
[2]
Clustering with t-sne.arXiv preprint arXiv:1706.02582, 2019
George Linderman and Stefan Steinerberger. Clustering with t-sne.arXiv preprint arXiv:1706.02582, 2019
-
[3]
Jolliffe.Principal Component Analysis
Ian T. Jolliffe.Principal Component Analysis. Springer, 2002
2002
-
[4]
A global geometric framework for nonlinear dimensionality reduction.Science, 290(5500):2319–2323, 2000
Joshua B Tenenbaum, Vin de Silva, and John C Langford. A global geometric framework for nonlinear dimensionality reduction.Science, 290(5500):2319–2323, 2000
2000
-
[5]
Roweis and Lawrence K
Sam T. Roweis and Lawrence K. Saul. Nonlinear dimensionality reduction by locally linear embedding.Science, 290(5500):2323–2326, 2000
2000
-
[6]
Visualizing data using t-sne.Journal of Machine Learning Research, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of Machine Learning Research, 2008
2008
-
[7]
Linderman, Manas Rachh, Jeremy G
George C. Linderman, Manas Rachh, Jeremy G. Hoskins, Stefan Steinerberger, and Yuval Kluger. Fast interpolation-based t-sne for improved visualization of single-cell rna-seq data. Nature Methods, 16(3):243–245, 2019
2019
-
[8]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review arXiv 2018
-
[9]
Ehsan Amid and Manfred K. Warmuth. Trimap: Large-scale dimensionality reduction using triplets. InAdvances in Neural Information Processing Systems (NeurIPS), volume 32, 2019
2019
-
[10]
Pacmap: Pairwise controlled manifold approximation projection
Yingfan Wang, Haifeng Huang, Cynthia Rudin, and Yaron Shaposhnik. Pacmap: Pairwise controlled manifold approximation projection. InProceedings of the 38th International Con- ference on Machine Learning (ICML), pages 11109–11118, 2021
2021
-
[11]
Ashwin et al. Narayan. Density-preserving data visualization unveils dynamic patterns.Nature Biotechnology, 2021
2021
-
[12]
Now Publishers, 2019
Gabriel Peyr ´e and Marco Cuturi.Computational Optimal Transport. Now Publishers, 2019
2019
-
[13]
Gromov-wasserstein averaging of kernel and distance matrices
Gabriel Peyr ´e, Marco Cuturi, and Justin Solomon. Gromov-wasserstein averaging of kernel and distance matrices. InInternational Conference on Machine Learning (ICML), 2016
2016
-
[14]
Prior distribution and model confidence.arXiv preprint arXiv:2509.05485, 2025
Maksim Kazanskii and Artem Kasianov. Prior distribution and model confidence.arXiv preprint arXiv:2509.05485, 2025
-
[15]
Visualizing large-scale and high- dimensional data
Jian Tang, Jingdong Liu, Ming Zhang, and Qiaozhu Mei. Visualizing large-scale and high- dimensional data. InProceedings of the 25th International Conference on World Wide Web (WWW), pages 287–297, 2016
2016
-
[16]
Neighborhood preservation in nonlinear projection methods: An experimental study.Artificial Neural Networks, 2001
Jarkko Venna and Samuel Kaski. Neighborhood preservation in nonlinear projection methods: An experimental study.Artificial Neural Networks, 2001
2001
-
[17]
Local multidimensional scaling.Neural Networks, 2006
Jarkko Venna and Samuel Kaski. Local multidimensional scaling.Neural Networks, 2006
2006
-
[18]
Rousseeuw
Peter J. Rousseeuw. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis.Journal of Computational and Applied Mathematics, 1987
1987
-
[19]
Joseph B. Kruskal. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis.Psychometrika, 29(1):1–27, 1964
1964
-
[20]
Pedregosa
Fabian et al. Pedregosa. Scikit-learn: Machine learning in python.Journal of Machine Learn- ing Research, 2011
2011
-
[21]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for bench- marking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017. 10
work page internal anchor Pith review arXiv 2017
-
[22]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, L ´eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[23]
Grace XY et al. Zheng. Massively parallel digital transcriptional profiling of single cells. Nature Communications, 2017
2017
-
[24]
Uci machine learning repository, 2007
Arthur Asuncion and David Newman. Uci machine learning repository, 2007. URLhttp: //archive.ics.uci.edu/ml
2007
-
[25]
Lee.Introduction to Smooth Manifolds
John M. Lee.Introduction to Smooth Manifolds. 2013
2013
-
[26]
Loftsgaarden and Charles P
Dean O. Loftsgaarden and Charles P. Quesenberry. A nonparametric estimate of a multivariate density function.The Annals of Mathematical Statistics, 36(3):1049–1051, 1965
1965
-
[27]
Scott.Multivariate Density Estimation: Theory, Practice, and Visualization
David W. Scott.Multivariate Density Estimation: Theory, Practice, and Visualization. Wiley, 2015
2015
-
[28]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[29]
Accelerating t-sne using tree-based algorithms.Journal of Machine Learning Research, 15(93):3221–3245, 2014
Laurens van der Maaten. Accelerating t-sne using tree-based algorithms.Journal of Machine Learning Research, 15(93):3221–3245, 2014. Code availability.The implementation of DR-SNE and all experimental pipelines are available at https://github.com/maksimkazanskii/DR-SNE. Use of AI tools.AI-assisted tools (ChatGPT, OpenAI GPT-5.3) were used exclusively for ...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.